基于文献特征提取网页信息的算法研究
2019-03-02郭培铭
郭培铭
(1.上海理工大学光电信息与计算机工程学院,上海 200093;2.上海理工大学图书馆,上海 200093)
0 引言
社会经济快速发展的同时互联网也随之快速发展起来,而Web页面上的信息资源正在以一种爆炸式的速度增长着,因此,在面对如此海量的信息资源面前,该如何快速地提取及发现有价值的信息已经成为最为重要的任务。而Web的研究内容主要是关于信息检索、过滤以及抽取等,而其主要研究对象也是网页信息。但是在网页当中除了与主题相关的内容还有较多的广告信息和比较多的无关紧要的信息,因此,如何有效快速地清除在网页信息当中的噪音,及时提取有效的正文信息,并提升Web程序处理结果的准确性,已经成为研究Web的信息系统一项必不可少的工作项目[1]。
网页信息提取已经在很多领域中被应用,而在图书文献服务中应用得并不十分广泛。最为常用的就是百度搜索引擎中对文献的检索功能。对于检索到需要的文献时,如何快速地提取文献信息,始终无法有一个较为可行的方法。而这一点在图书馆文献传递工作中越来越显得十分必要。
1 图书馆文献传递系统在图书馆工作中的应用
以上海理工大学图书馆为例,图书馆使用PHP7+MySQL5.5+Apache2.4的系统组合,搭建并自行开发了网络版文献传递服务系统,大大方便了用户对文献传递服务的使用,但是用户如果需要请求文献时需要将文献详细信息自行输入系统,也由此可知,某一用户某次的文献申请数量与文献申请的积极性也就成了反比。而且还有可能造成文献申请的信息不完整,给文献传递工作带来不必要的麻烦。
在现有的系统基础上,为文献传递系统引入网页信息提取技术,能够极大地提高文献传递工作的效率,同时也可以吸引更多的潜在用户使用图书馆文献传递服务,建立系统的图书馆文献传递数据库,提升资源使用效率也有极大的帮助。
目前由第三方公司在上海理工大学范围内提供的QQ文献服务群中,大量的文献需求由用户在QQ群中直接提出。据统计,在开始提供服务的近一年时间中,大约有近千个文献服务申请被提出,而用户选择在QQ平台上申请服务的原因很简单,就是十分方便,只需提供一个文献标题或文献链接即可。而这种方式对于资源的再利用及规范使用都会有一定的弊端,而图书馆在文献传递工作中补上这一短板也更为刻不容缓了。
2 文献信息的网页提取
这里的文献网页所指的是特定某篇文献的页面,即用户所需要的文献的所在数据库页面,在此页面上对所需的文献信息进行自动提取。整个算法由PHP语言进行编写实现,对HTML的网页结构进行提取所需要的结构值,并进行筛选、整理,在提取文献信息的基础上,算法还将对所收集的信息进行特征分析判断,对该文献的具体性质做出准确的判断,使信息提取走出只是获得所需信息,起到向综合利用信息结合的桥梁作用。
算法过程:
(1)对网页信息进行去噪处理,舍弃不需要的标识内容;
(2)提取网页信息中标识字段;
(3)保留需要的字段内容,组成数据数组;
(4)对数据数组进行再去噪,保留有效内容;
(5)通过筛选,提取所需文献信息;
(6)通过文献信息对文献类别进行判断。
2.1 对网页信息的去噪
要提取网页内容就需要先对网页信息进行去噪。网页由功能数据与网页信息共同组成。而网页HTML文本是自动描述的半结构数据,数据的结构与内容与网页功能模块混在一起,无明显的特征区分。并且在一般情况下,HTML元素是相互交叉嵌套的[1]。因此,需要先对所获得的网页信息进行去噪,也就是将HTML文档转换为DOM树的过程,将HTML文档中的元素映射成DOM树中的节点[2]。将需要的标识字段提取出来,对于文献数据库来说,与文献信息相关的标识字段一般是<title>,<h2>,<a>,<li>等,将这些信息从繁杂的网页内容中提取并作结点处理,有助于提高文献信息提取的准确性。其用PHP编写的关键代码为:
Gethtml()
{
for(对提取的网页信息进行筛选)
{
if(是在<>中的标识字段名)
{
提取完整的标识字段名;
}
if(如果是所需的标识字段)
{
$substring1=$substring1.substr($data,$s1,1);
//$substring1为保存标识字段内容变量
//$data为提取的网页信息
//$s1为当前字符所在位置
}
if(指定标识字段内容提取完成)
{
将所需内容存入指定数组内;
}
}
}
2.2 对提取的信息进行分类判断
(1)相应的标识字段内容筛选
在提取完成所有需要的标识字段中的内容后,对所提取的信息进行再次去噪,以提高信息提取的准确率及效率,从不同的文献数据库的提取过程中,发现虽然不同的网站在编写网页时会有所不同,但也有一些共同的规律可以被找到。每一篇文献的页面信息中,所需要的信息通常位于提取信息的前50%内容内,后50%的内容为网页其他信息,故可以将匹配范围缩小至50%。再从剩余内容中,将一些特别字符组成的无实际意义的修饰符及空格内容剔除,以提升提取准确率与提高效率。则在计算文献信息初始提取时,其正确提取概率为:
设:原提取概率,数据量为n(n ≥1,n∈N+),则信息的提取概率P为公式(1):

经筛选后,信息提取概率P0成为公式(2):
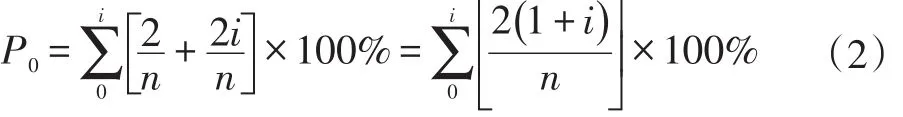
(2)以文献特征提取文献信息
对于体现文献特征属性的内容描述,一般由文献标题、所属出版物、页码、卷期号、责任者、出版时间等几个主要的特性来组成,而它们之间各自又具有一定的区别于对方的明显特征。
以责任者为例,中文姓名,其表现为特定的字符长度与其他网页文字内容相区别,汉字组成可将非汉字字符内容排除,重复出现的字符可视为网页的特定内容而去除,再将所提取的信息前端内容与系统内保留的中文姓氏字库进行匹配来提取所需的信息,获得了较好的提取效果。
对于英文字符的姓名,除应用基本的英文姓氏及中文拼音姓氏字库进行匹配外,英文姓名中往往还包含特殊字符“.”,可以以此特征来进一步判断是否为责任者信息。同时,在提取时也要注意电子邮箱名称中具有与姓名类似的特征,所以要将邮箱的特殊符号“@”加以考虑,以过滤掉邮箱地址。
通过不断细化总结文献各类信息的不同特征,使所需要的文献信息能够较为准确地得到提取。分类判断关键代码:
Getmessage()
{
for(检索整个提取的内容集合)
{
条件性质细化判断处理过程;
if(符合特征项0的条件)
{
$arr[0]=$sub1;//将文献信息保存入指定数组字段
$sub1="";//清空变量,准备保存下一个信息
}
i(f符合特征项n的条件)
{
$arr[n]=$sub1;
$sub1=””;
}
}
完成处理过程后输出结果至指定位置;
}
2.3 文献类型的判断
所谓文献类型的判断,就是要判断所选定的这篇文献是期刊文献、会议文献还是其他类型的文献。一般网页信息提取过程中不会有明确的类型提示,而对从单一信息中提取的内容来进行判断也无法保证其正确性。基于这些情况,可以从所提取的文献信息出发,对多个特征的结合分析来进行判断。各类文献的特征可见表1所示。

表1 各类文献的特征
从表1可知,期刊与其他文献的最大区别为有卷期号、页码的表示方法以及刊名的独特性;会议文献则是其会议名称和页码表示方法是其最大的特点。从总结文献的特征性信息,就可以判断出所获得的文献信息是哪一种,较为容易做出准确的结论。也可以看出,对文献特征属性的准确提取是对文献类型进行精确判断的最为关键的保证。
3 结语
结合对HTML结构抽取的方法通过对文献特征的分析来对其信息进行网页提取,能够取得较好的提取准确率。由于不同文献数据库的表达形式以及网页标识字段可能会有所不同,但是形式不会过于多样,因此,通过对更多数据库的提取实践,可以使文献信息的提取准确性和效率不断提高,使算法的适用性不断增强。
同时,让信息提取技术用于图书馆对计算机及互联网技术的深度应用上,也能够起到促进其他技术在图书馆工作中的应用与实践,使之成为图书馆工作不断深入发展的催化剂。
