编程能力评估模型研究进展
2019-03-02杨宇霞
杨宇霞
(四川大学计算机学院,成都 610065)
0 引言
在教学领域中,无论是在线教育还是传统教育,计算机编程能力都是计算机科学和软件工程课程要培养的核心能力[1],而教育者/考核者评判编程能力水平的方式是以学生课程期末考核表现为依据,即总结性评估。目前,总结性评估方法主要分为两大类:线下笔试和线上测验,如图1所示。
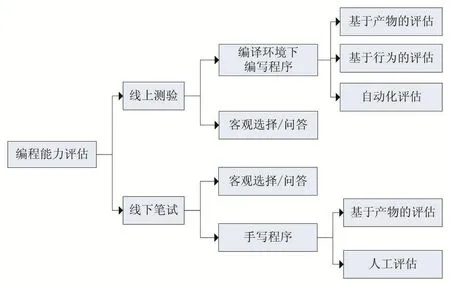
图1 编程能力评估方法
线下笔试大多是以理论知识为主,代码编写为辅。通过多项选择、填空及问答等方式考核学生的知识点覆盖广度和深度,对学生实际操作关注较少。这种按图索骥的测验存在诸多不合理性:
首先,计算机编程是一门以理论为指导,以解决实际问题为目的的实践学科。其本质在于对计算机的实际应用,而上述评估方法未能充分体现其核心思想;其次,这种不以实践为中心的考核模式会导致错误的学习思维,学生在学习过程中舍本逐末,重理论轻实践,最终与学习的初衷背道而驰;最后,这种评估方式费时费力,而且评价标准因人而异,难以达到评估的一致性。
Bennedsen和Caspersen提出[2],程序实际上是学生使用计算机上标准的开发环境生成的,在这种开发环境中,学生可以反复提交程序,并且立即获得反馈,根据测试出现的错误(trial-and-error)来调试程序。根据建设性调准(Constructive Alignment)理论[3],学生的学习活动会影响最终的学习结果,因此布置的评估任务应与学习活动保持一致。
因此线上测验以及自动化评估的必要性对编程能力的评估而言则显得尤为重要。由图1可知,线上测验评估方法可以分为两种,基于编程产物(源码)的评估和基于编程行为的评估。本文对现有研究中线上测验自动化评估的评价指标进行分析总结,并针对其存在的问题提出改进思路。
1 基于编程产物的研究
目前以在线开发环境为背景,实现学生编程能力自动化评估的研究已有40多年了,如牛客网、Leetcode等在线平台。这些研究/工具大多以产物评估为主,即分析学生提交的代码。其设计思想分为两类:
(1)动态分析方法(Dynamic Analysis),评分系统首先根据编程问题的需求生成一个测试集,然后将学生提交的程序在该测试集上运行,最后程序的评分标准以运行的程序在该测试集上通过的测试用例数量为依据[4-6]。早期的自动化评估研究,如TRY[7]、CourseMarker[8]、Online Judge[9]等,大部分都采用动态分析的方法对待测程序的功能完整性。近年来,动态分析的研究重点主要在测试用例构造的改进[10],和针对程序的子功能或结构的局部测试上[11]。
(2)静态分析方法(Static Analysis),将提交的源码用抽象的表达方式表示,计算学生的源程序与正确答案的程序代码之间的相似性,从而实现对程序的评分。如文献[12]中作者基于程序的语义结构相似性,针对给定编程任务生成一个标准解空间,采用SDG作为中间表示形式,采用语义保留(Semantic Preserving)转化法对形同依赖图进行标准化处理,根据标准化后的学生程序与模板程序系统依赖图的匹配结果评分。文献[13]中作者提出了基于控制流的抽象语法树(CFAST)来表示源程序,通过控制结构的数目,计算与正确程序之间的距离。文献[14]中作者结合词法、语法和语义分析源程序,采用模式匹配理解程序,抽象语法树(AST)判断语义相似性,通过设定不同的权值获得最终的评分结果。此外,Shashank和Gursirman等人提出采用机器学习的方法,通过对待测代码的CFG和PDG进行特征提取,训练单层的神经网络回归模型,用以对人工评分进行预测[15-16]。
采用动态分析方法的好处在于其易于实现,并且适用于解空间开放的问题。但是动态分析要求待测程序通过编译,无法解决无限循环的问题,会造成分析过程中断,更重要的是,动态分析无法判断程序是否真正实现了任务需求,也很难为学习者提供有效的支持。而静态方法可以支持对错误程序的评估,且可以检测出剽窃和投机取巧的现象。然而,这种评估方法也存在局限性,除了需要更多的专业知识以外,其评估结果依赖于模板程序和分析方法的选择。当程序越复杂,解空间越大的时候,模板程序的设计难度越高,相似性比较难度也随之激增。
因此许多研究考虑动态与静态分析相结合,通过静态分析解决编译和运行失败以及可解释性问题,通过动态分析弥补解空间庞大导致的模板程序设计不全面的问题。
2 基于编程行为的研究
现有研究主要是通过分析学生编程产生的日志文件,或者通过一定粒度的代码快照,分析学生在编程过程中的某些编程行为,从这些编程行为中提取可量化的特征指标,建立模型,来预测学生的表现或者根据某一属性对学生进行分类。其编程行为主要分为两类:
(1)基于击键(Keystroke)的编程行为研究。Thomas[17]表明,编程者会将注意力集中于思考解决方法上,从敲击一个单词的角度出发,编程者的打字模式是不受影响的。所以许多研究都在基于单词水平研究击键行为于编程能力之间的关系,如文献[18]中作者通过细粒度的代码快照的方式记录学生的两个键敲击的延迟时间,将字符类型分为5个类,如表1所示;将两字符(Bigraph)之间的关系分为三大类,如表2所示。

表1 按键类型

表2 字符之间的关系分类
目前基于击键的研究大多止于底层行为,即主要是基于键敲击延迟、强度、持续时间、Bigraph、Trigraph等原始数据的特征。但编程能力更多是体现在各种底层行为的组合运用中,因此仅仅研究底层的编程行为是远远不够的,其能够反映的编程能力的信息十分有限,应从这些底层行为中挖掘出高阶的编程行为来进行建模。
(2)基于日志(Log Data)的编程行为研究。编程者在编程过程中反复进行的代码编译和编辑操作。大量实证研究也表明,日志文件可以十分准确地表达编程者编译和调试的熟练度,而编译和调试能力的强弱会影响编程者编译错误的个数和类型,从而影响最终的考核结果[19-20]。
如文献[21]中作者通过日志文件收集学生在编程过程中产生的四种数据:编译、运行、代码编辑以及提示使用,根据编译和使用提示的次数以及先后顺序,给学生在该编程任务上的表现评分,根据一段时间多次任务的表现评分轨迹,预测学生是否能够顺利通过课程;文献[22]中作者通过日志文件中的对同一文件的连续编译的行为,根据编译是否成功,错误信息,错误类型,错误行以及编辑时间等特征预测学生的编程能力;文献[23]中作者选择基于Web的开源编辑器Cloud-Coder作为开发平台,通过日志文件收集学生的编程过程中产生的三种数据:编译、运行和代码编辑。研究学生编译产生的错误数量,错误类型,错误位置以及编辑位置等特征与编程结果的关系。
基于日志的研究在某种程度上确实可以很好地反映学生的编译调试行为与编程能力之间的关系,包含了很多高阶的编程行为,与编程能力的相关性也更强。但是,它依然只是编程过程中的一部分,不能代表编程过程中的所有行为,因而也无法准确表示编程能力的强弱;此外,基于日志的编译调试行为是广义上的编程行为,只知道最后一次的编辑结果,而两次编译之间的其他行为无法记录。因此准确地说,基于日志的方法不能记录完整的编译调试行为。
3 总结与展望
通过对现有研究的总结分析,目前对编程能力的评估仍然存在以下几点问题值得深入研究和改进:
(1)基于理论以及实证研究提出一种标准的编程能力结构,对学生编程能力的全面定义,以促进编程能力自动化评估的发展。无论是基于产物还是基于行为的编程能力评估,研究者并未对编程能力进行标准化定义,这造成评估人员对能力的主观因素直接影响实验结果,此外,由于缺乏统一的能力结构定义,自动化评估方面的研究依然具有主观性。
(2)建立一个编程行为集合,记录编程过程中产生的所有编程行为,通过集合评估学生的编程能力,如图2所示。现有研究中,基于产物的评估模型丢失了未能传播到代码中的行为,基于击键的编程行为特征选取大多基于底层,如键敲击延迟、强度、持续时间等,会丢失部分语义信息;基于日志的编程行为直接记录上层行为,如编译、运行、调试等,丢失了部分底层数据。上述方法均存在行为丢失的现象,所以建立一个编程行为集合是有必要的。
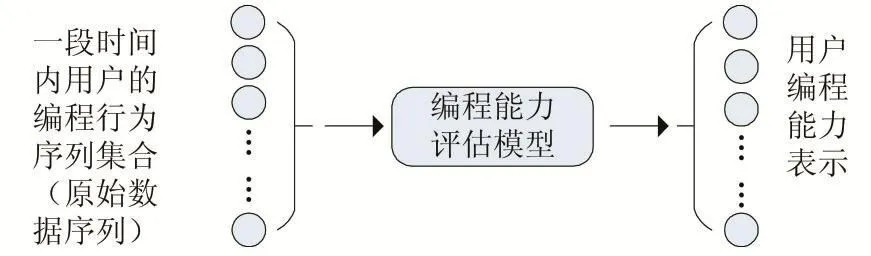
图2 基于编程行为的理想能力框架
(3)对底层编程行为集合进行抽象,获得高层的行为模式,建立编程行为与编程能力之间的映射关系模型,如图2所示。基于编程行为的研究中,高层行为特征包含更丰富的语义信息,其实验结果更具有价值。
