基于CDPM的东巴象形文字预处理算法∗
2019-02-27杨玉婷康厚良
杨玉婷 康厚良
(1.昆明理工大学津桥学院电气与信息工程学院 昆明 650000)(2.云南经济管理学院人文艺术学院 昆明 650000)
1 引言
东巴文是一种十分原始的图画象形文字,纳西语称“森究鲁究”,直译为“留在木石上的印迹”[1],由于这种文字主要是由纳西族祭祀——东巴用来书写传递民族文化典籍的东巴经,所以也称为东巴文[2]。纳西东巴象形文字作为人类早期的一种图画文字向象形文字、标音文字过度的文字形式,具有字符类型多,字体结构复杂和字形变化多等特点[3~5]。特别是其中所包含的变形字和缀加字[6],虽然与基本构字元素同属一类文字,具有相同或相似的文字形态,但是却有着各不相同的含义,这给东巴字的特征提取、检索和识别带来巨大干扰,如表1所示。

表1 基本字素及其同形字素、变形字素和加缀字素举例
对东巴文字的检索和识别的研究较多[7~11],并且从不同角度应用各类不同的算法来实现,但是在预处理阶段大多都一笔带过,或者是使用常见的灰度化、二值化、直方图等方法来完成[12~15]。显然,不充分的预处理不但会增加文字特征提取的复杂度,也会影响文字检索和识别的准确度。因此,通过分析东巴象形文字的造字方法,给出了基于CDPM的东巴字预处理算法,该算法不但能快速去除东巴字中的部分形变和离散的缀加元素,同时也能去除字符轮廓中具有粘连性的缀加元素,使得到的轮廓曲线能准确反映东巴字的本质特征。
2 基于链码的连通域优先级标记算法(CDPM)
基于链码的连通域优先级标记算法(ConnectedDomainPriorityMarkingAlgorithm,CDPM)[16]可准确提取东巴字符的特征轮廓,其核心思想是:设给定的字符为G,Pi(i∈{1,2,…,n})为G中所包含的特征点,即Pi∈G。从G上的第一个特征点P1出发,按逆时针方向遍历。若已知特征点Pi(i≥2)的前一个已知点为Pi-1,后一个待测点为Pi+1,且由Pi-1和Pi组成的方向向量为那么,当向量满足v.x≠0且v.y≠0时,以点Pi为核心的8邻域点优先级权值在局部满足顺时针排列的方式,且优先级最低的邻接点是向量反方向所指向的点,而优先级值最大的点即为待测点Pi+1。然后,将Pi+1作为已知特征点,重复执行上述过程,直到得到完整的字符特征轮廓曲线为止。
需要说明的是,为了保证字符轮廓的连续性和闭合性,当字符中包含由单个像素点组成的线条时,CDPM会重复存储组成单像素线条的特征点,以保证字符轮廓的连续性和完整性。
3 基于CDPM的预处理算法
东巴象形文字预处理算法的目的是去除文字中的干扰成分,包括文字中的噪音、缀加的文字成份及文字的形变成份,降低字符特征提取阶段的复杂度,使相同类型的东巴字能够得到相同或相似的特征曲线,而不同类型文字的特征曲线又具有较大的差异性,具体包括三个阶段的内容。首先,去除文字中具有非粘连性的加缀点、线和字块;其次,确定字符轮廓提取的起点,确保不同字符所提取的特征曲线的一致性;最后,使用CDPM算法提取文字的特征轮廓,并结合CDPM算法重复存储单像素线条的特性去除轮廓中具有粘连性的加缀点和线,使得到的特征曲线能够反映文字的本质。
3.1 去除离散缀加元素
3.1.1 东巴文字的细化
由于东巴文字一般使用竹笔(属于硬笔)书写,文字的线条宽度基本一致[3]。细化文字线条有利于降低复杂度。但是,在东巴字中,有的文字通过填充或局部填充的方法表示贬义或反义词,例如:(花)、(剧毒)和(毒草),若直接细化可能得到的是字符的骨架,而非笔划。因此,在细化前应判断字符是否被填充过,判断条件如下:

其 中 ,GlyphPixeloriginal为 原 始 字 符 ,而GlyphPixelFilled表示填充后的字符。那么,当字符填充前后的像素点数比例小于80%,说明原字符未被填充过,可以细化;否则,不能细化。
3.1.2 离散元素的判断与去除
另外,结合东巴文字的造字特点可知,东巴文字中的缀加成份一般只起到丰富文字含义的作用,作为文字的辅助元素,它的大小一定小于该文字的基本构字元素。因此,对于由n个离散子字块组成的任意东巴字G,各子字块用GPi(i∈{1,2,…,n})表示,子字块对应的外接矩形面积用RectAreai表示,则面积最大的子字块即为G的基本构字元素,即
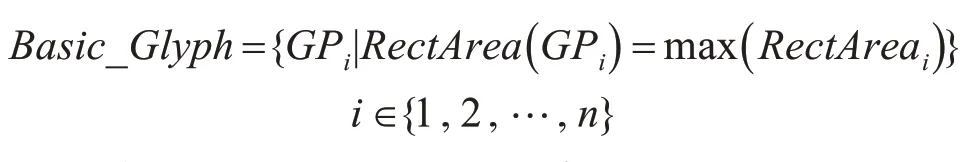
3.2 东巴文字结构分析及轮廓起点确定
东巴文字的结构一般可分为三种,即完全闭合 全、闭半合闭的合轮及廓非线闭,例合 如。:完全闭(合房指屋)的 、是文字(具手)有等完;半字楼)闭局等合部;指是也的闭有是合的文的是字,半没例包有如围完的全,闭(例厨合如房的)轮 、廓(线贫,困有(户竹的)文墙、(轮人廓)(、特压 征) ,等(特 蹲; 别非)、是闭以合人(指形拔的)为是和基文础字的(本文吹身字笛没子,有例)明等如显。的与前两种类型相比,非闭合型文字是以文字线条来表示含义,处理相对简单,因此,仅着重讨论前两种文字的处理方法。
对于完全闭合及半闭合型文字,在使用CDPM提取轮廓时,一般选取字符x/y轴最小值点或字符的终端点作为起点。但是,由于文字结构的多样性,有的终端点未在轮廓上,若采用终端点作为起点,则无法得到正确的轮廓,如图1(上)所示;而有的文字是半闭合的,若采用x/y轴最小值作为起点,则无法获得完整的轮廓,如图1(下)所示。由于无法判断终端点或x/y轴最小值点是否是潜在的有效起点,而选择不当将会导致文字轮廓提取不全或提取错误。

图1 选取不同的起点可能得到不同的文字轮廓
为了获得正确的字符轮廓,选择两种不同的起点分别计算字符的轮廓,并将其中较大的轮廓作为文字的最终轮廓,即
以终端点和y轴的最小值点作为起点,使用CDPM算法提取字符的轮廓,分别使用Contourendpoint和Contourmin(y)表示字符轮廓,BoundRectendpoint和BoundRectmin()y表示轮廓的绑定矩形。基于字符轮廓最大原则,如果Contourendpoint的外接矩阵面积较大,则将Contourendpoint作为最终的字符轮廓,否则,将Contourmin(y)作为最终的字符轮廓,从而保证使用CDPM算法字符轮廓提取的正确性,判断条件如下:
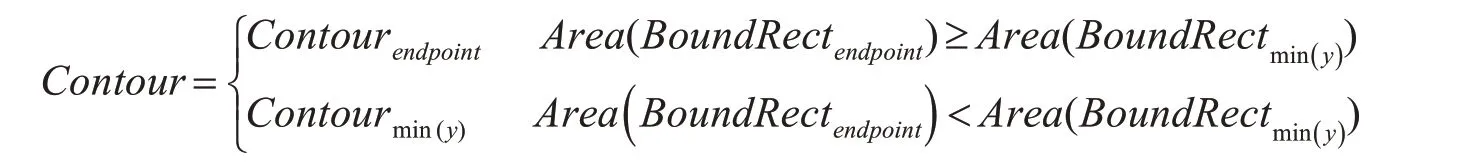
3.3 去除粘连的缀加元素
在CDPM算法中,为了保证字符轮廓的连续性和完整性,当字符中包含单像素组成的线条时,会重复存储组成轮廓的特征点。虽然会产生一些干扰,但是,却为判断字符中是否存在粘连缀加元素提供了帮助。例如,图2所示字符中包含了一条单像素粘连的缀加线条,为了保证字符轮廓的连续性,CDPM算法重复存储了P5→P8的多个连续特征点。值得注意的是,这些被重复存储的点是具有规律性的。
因此,对于任意具有连续性且由n个点组成的字符轮廓C,若最初发生重复的点为Pi(i∈{1,2,…,n})且 重 复 的 位 置 为i和j,即Pi→Contour(i) Pi→Contour(j),其中i,j∈{1,2,…,n},使得轮廓C被分为两个连续的曲线段Ci→(j-1)和 C(j→end)∪(1→(i-1)),若 下 一 个 重 复 点Pk(k∈{i+1,i+2,…,n})的重复位置为i+1和j-1,即Pk→Contour(i +1) Pk→Contour( j-1),则曲线段Ci→(j-1)是轮廓中重复存储的缀加线条;否则,C(j→end)∪(1→(i-1))是轮廓中重复存储的缀加线条。

图2 字符中粘连的缀加线条的去除
因此,在轮廓中循环查找重复存储的特征点时,对于Pi→Contour(i) Pi→Contour(j)可能存在i>j的情况,为了保证所有重复存储的特征点能被全部找出,使用count统计重复点的数量,在完成一遍所有轮廓点的遍历后,还需再次遍历,直到轮廓中的所有重复点都被去除(count=0)为止。
4 实验
东巴文字预处理算法的目的包括三个方面:1)去除字符中离散的缀加点、线或字块;2)确定CDPM算法的有效起点,保证提取的特征轮廓的完整性和正确性;3)去除字符轮廓中粘连的缀加点或缀加线条,最终得到字符的特征曲线。因此,着重从差异性、通用性性、准确性及一致性等几个方面对预处理算法进行评估。
4.1 差异性评估
差异性评估的目的是对于不同类型的东巴文字,预处理算法是否都能得到预期的效果。因此,分别选取半闭合字符、半包围字符及包含离散和粘连缀加元素的作为测试样例,测试结果如图3所示。其中,图3(a)为不同东巴字的二值图;图3(b)为字符线条细化及去除了离散的缀加点、线和字块后的效果;图3(c)为使用CDPM提取的字符轮廓;图3(d)为字符轮廓去除粘连缀加元素后得到的最终字符特征曲线。

图3 待测字符的二值图及三个处理阶段的效果图
4.2 通用性和一致性评估
为了进一步验证算法的通用性,从东巴象形文字中选取包括鱼虫、鸟、花、手、山、(闭合的)房屋、水、东巴祭祀、牲畜和(半闭合的房屋)等10类具有相似特征的字符,并且每种类别中都包括数目不等的东巴字。这10类东巴字在文字结构上包括完全闭合型、半闭合型两种。而在缀加元素方面,包括缀加点、缀加线、缀加字块、缀加点和线、缀加点和字块、缀加线和字块、缀加点和线及字块等7种,具体如表2所示。

表2 具有相似特征的10组东巴字符
在10类东巴字中任意提取其中的5个字符进行预处理操作,如图4所示。图4中每幅图片的奇数行为原字符,而偶数行为该字符对应的特征曲线。分析图4可知,所有文字中所包含的缀加成份(离散的和粘连的)和形变都得到了较好的去除。另外,图4中,相同类型的东巴字符得到的字符轮廓基本相同,而不同类型的东巴字的字符轮廓具有明显的差异性。说明,对于同类型的东巴文字及不同类型的东巴文字,预处理算法都能提取体现它们本质的特征曲线,具有较好的通用性。

图4 各类东巴字符及对应的特征轮廓曲线
4.3 准确性
为了进一步验证预处理算法的准确性,对表2中的所有字符以类别为单位分别比较CDPM算法和预处理算法两种不同方法获得的字符特征曲线,并对同类型字符中具有相似特征曲线的个数进行统计,统计结果如图5所示。显然,由于预处理算法去除了字符本身包含的形变和缀加元素,因此,同类型东巴字的特征曲线相似度较高,并且10种类型的东巴字特征曲线的相似个数均高于直接使用CDPM算法得到的结果。说明,预处理算法能够提取显著反映东巴文字本质的特征曲线。

图5 同类型东巴字中具有相似的轮廓曲线和特征曲线的个数比较
5 结语
基于CDPM的东巴文字预处理算法能够快速去除东巴字中的部分形变、离散的缀加元素及粘连的缀加元素,使最终得到的特征曲线能够更好地反映文字的本质,一方面加大了不同类型文字之间的差异性,另一方面也提高了同类型文字间查找的准确性,降低文字检索和识别的复杂度,为实现东巴文字的快速检索和识别奠定坚实的基础,也为其他象形文字的预处理研究提供有益参考。
