基于Nutch的就业垂直搜索引擎研究
2019-02-25肖红玉黄灼东蔡昭阳
肖红玉,贺 辉,黄灼东,蔡昭阳
(北京师范大学珠海分校 信息技术学院,广东 珠海 519087)
0 引 言
随着高校不断扩张,毕业生人数屡创新高,2016年高校毕业生765万[1],2017年795万[2],2018年将达820万[3]。在线求职是毕业生就业环节的重要部分,目前国内求职招聘相关的网站已经发展到近千家,大学生们比较熟悉的有智联招聘、前程无忧、58同城招聘、赶集网招聘等。各大招聘网站网罗的用人单位和发布的招聘职位众多,但是各自为政,数据无法共享,使用百度、搜狗等通用搜索引擎搜索招聘信息时,搜索结果有大量的无效信息。为了帮助毕业生快速、准确地检索招聘信息,就业领域垂直搜索引擎应运而生,其主要目标是为提高毕业生检索招聘信息的查准率。
Nutch是一个Java实现的开源搜索引擎[4],主要包括Web Crawler(网页爬虫)和索引技术Lucene两部分。文中基于Nutch开源搜索引擎开发就业垂直搜索引擎,鉴于Nutch本身没有中文分词器、缺少主题相关性判断、内置网页排序算法简单化、用户检索接口单一化等情形,基于Nutch进行二次开发,完成就业垂直搜索引擎。
1 系统框架
以Nutch为基础,借鉴了TUCUXI(intelligent hunter agent for concept understanding and LeXical chaining)[5]和SHOE(simple HTML ontology language)[6]的本体构建思路、元搜索引擎(meta-search engine)和ifWeb原型系统[7]以及LinkRank[8]排序算法的设计思想,在基于Nutch的就业垂直搜索引擎设计上引入就业领域本体网页爬取和过滤,采用就业领域本体计算网页的就业相关性并改进Nutch自带的LinkRank网页评分算法,并结合Spring boot、Spring-data-jpa、Shiro等Java开发框架开发了系统管理后台,为用户提供高级检索、关键词定义、搜索词高亮显示等辅助查询接口。就业垂直搜索引擎体系结构如图1所示。
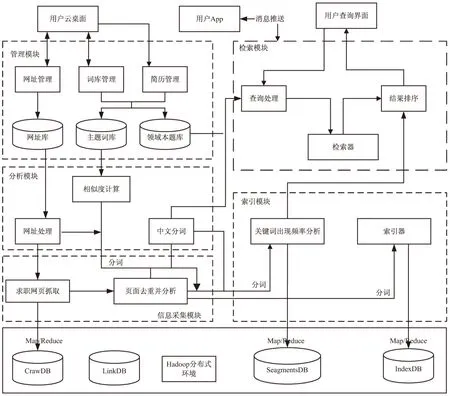
图1 就业垂直搜索引擎体系结构
从业务逻辑流程分析,基于Nutch的就业垂直搜索引擎的工作流程分为10个阶段:
(1)创建WebDb;
(2)将抓取初始URLs写入WebDb;
(3)根据WebDb生成抓取列表(fetchlist)并写入相应的segment;
(4)读取fetchlist中的URL信息,启动爬虫爬取网页;
(5)网页爬取结束后更新WebDB;
(6)根据系统预设的爬取深度,循环第3~5步;
(7)采用LinkRank网页评分算法给爬取的网页打分,更新segments;
(8)采用Lucene建立索引;
(9)把索引中重复的网页和URL丢弃;
(10)将segments中的索引进行合并并生成用于检索的最终索引。
2 系统关键技术
2.1 中文分词
中文分词是中文搜索引擎的关键技术,分词结果会明显地影响检索结果。Nutch本身针对英文检索,没有自带的中文分词器,因此需要基于Nutch进行二次开发。
采用基于本地词库和动态加载词库的正向迭代最细粒度切分算法的ik-analyzer[9]分词系统,对Nutch中文分词进行了改进。ik-analyzer对待切分的字符串采用先最大词再最小词的迭代方式进行切分,以被切分的字符串“北京师范大学珠海分校开学了”为例,首先在词库中检索最大切分词后,分割为“北京师范大学珠海分校”和“开学了”;然后将“北京师范大学珠海分校”切分为“北京师范大学”和“珠海分校”,以此类推,最后,“北京师范大学珠海分校开学了”切分为“北京师范大学|北京|京师|师范|大学|珠海分校|珠海|分校|开学|了”,ik-analyzer默认的切词方式是细粒度切分。若按最大词长切分,切分结果为“北京师范大学|珠海分校|开学了”。
2.2 主题相关性判别
国内外学者对网页主题相关性判断方法进行了研究,总体而言,有效的判断方法有以下5类:元数据判定法、扩展元数据判定法、链接分析法、语义判定法及基于特征词的向量空间模型判定法[10],各有优势与不足。文中采用基于特征词的向量空间模型算法。
传统的基于特征词的向量空间模型算法[11]没有充分考虑网页的元数据标签,主题判别的准确度不够高。文中对此进行改进,充分使用元数据标签改进传统的基于特征词的向量空间模型主题相关性判别方法,再结合就业领域本体实现主题相关性判别功能,实验证明改进后的方法能够提高主题判别的准确度。算法的具体流程如下:
(1)获取就业领域主题特征词向量T和特征词权重向量W,其中T={t1,t2,…,tn},特W={ω1,ω2,…,ωn},ωi表示特征词ti所对应的权重。
(2)通过就业领域概念间关系获取就业主题特征词ti的上下位词和同位词,保存在数组Ai中。
(3)解析网页D
(4)提取内容并分词。如果网页中有
n进行判断,如果a在数组Ai中,则将n替换成Ai,并将对应的权重ωi加1。
(6)采用TF*IDF(term frequency-inverse document frequency)[12]算法计算网页D中所有就业领域主题特征词的权重D={d1,d2,…,dn}。
(7)根据式1对网页D进行主题相关性判别。
(1)
2.3 检索结果排序
2.3.1 基于MapReduce的LinkRank并行排序算法
基于Nutch的就业垂直搜索引擎通过WebClawer抓取网页,如果在WebClawer抓取网页结束后再通过LinkRank算法计算网页得分,将会消耗大量时间。Nutch平台本身支持MapReduce并行操作,即抓取网页、网页解析、索引建立等操作都可以并行进行,以提高效率。借鉴MapReduce并行编程思想,把耗时较长的网页抓取和解析、建立索引操作转化为Key-Value的并行处理,实现基于MapReduce的LinkRank并行算法。图2为具体工作流程。
2.3.2 网页的就业相关度计算
网页的就业相关度用来衡量网页和就业领域的相关程度,是指网页和就业主题的相关度。白晓丹[13]通过层次分析理论以及模糊分析法构建网页相关性评价体系,该方法具有一定的优势,尤其在提取PDF文件时准确度较高,但是URL的评价结果不太理想。文中结合就业领域本体计算网页的就业相关度。具体步骤如下:对网页进行中文分词,去掉敏感词等停用词;提取网页特征词,根据就业领域本题库获取各特征词的上下位词和同位词,用一个三元组表示;统计三元组中每组词在网页中出现的次数,以及在多少个网页中出现,根据前文描述的TF*IDF算法计算它们的权重,计算所得的权重为各特征词的权重;使用向量空间模型表示网页。网页D可表示为:D=(ω1,ω2,…,ωn),其中ωi表示网页D中第i个特征词的权重。同时将就业领域主题词用向量K表示为:K=(k1,k2,…,kn),其中ki表示主题词i的权重。
把网页的就业相关度计算,转换为求D和T向量的距离。根据式1计算网页的就业相关度,Sim(D,T)越大则网页与就业的相关程度越高。

图2 基于MapReduce的LinkRank并行算法工作流程
2.3.3 改进Nutch原有结果排序
Nutch采用的LinkRank是一个PageRank-like的算法,该算法通过构建inlinks(链入链接数),outlinks(链出链接数)和节点的列表,然后由LinkRank类计算网页得分。LinkRank非常接近最初的页面排序公式,类似于:
(1-dampingFactor) +(dampingFactor*
totalInlinkScore)
(2)
其中,dampingFactor是垃圾网页因子;totalInlinkScore是页面链入链接数。
该算法有明显不足:没有区分链入链接的重要性,每个链入链接的权重一样;偏重历史页面;没有考虑页面内容与主题的相关程度。以上因素对网页的排序质量均有较大影响。因此做了如下改进:
(1)增加链入链接权重因子。LinkRank本身不区分链入链接的权威程度,每个链入链接的权值一样,然而,网页中链入链接的权威度参差不齐,如果采用相同的权值,无法客观反映链入链接的重要性。甚至,某些网页会故意添加广告链入链接进行作弊,以提高网站的排名。
文中给链入链接增加了权重因子,改进后的totalInlinkScore为:

(3)
其中,αi为控制链入链接的权重因子。
通过控制链入链接权重控制各网页的权威度,避免了原算法中相同权重的不客观性,对防止通过作弊提高网页的得分有一定的效果,提高了检索质量。
(2)增加时间衰减因子。LinkRank算法通过网页间的相互链接关系计算网页得分,在互联网上放置时间越长的页面将得到更多的链入链接,而新的网页就算内容比较重要,但是由于链入链接数较少,得分则会相对较低。针对这一不合理情况,引入权重衰减时间因子对旧网页进行衰减处理。
在式3的基础上进行改进:

(4)
其中,t是页面创建至统计时的时间;λ是常数因子。通过时间衰减因子λ,可以有效地调节新旧网页的权重,使得网页得分更接近真实情况。
2.4 用户查询接口扩展
2.4.1 关键字智能提醒
借助WEB2.0技术,就业垂直搜索引擎实现了自动记忆每次搜索信息的记录,同时通过就业专用词库,记录求职招聘特有的关键词,在用户输入查询关键字时在搜索框下方显示历史查询记录和该关键词的历史查询次数。通过关键字智能提醒扩展功能,搜索引擎不但可以记录用户输入的搜索关键词,了解用户习惯,并且可以形成与该搜索关键词相似的参考词组,简化用户操作。系统还可以根据关键词的搜索次数等因素,决定是否将此关键词自动识别为中文分词词库中的关键词。
2.4.2 定制爬虫
利用Java后台开发技术spring boot、spring data jpa和shiro,开发了求职招聘垂直搜索引擎的管理后台,通过后台可以对爬虫进行设置与管理,包括设定爬虫爬取时的深度与广度、设定爬取起始时间和间隔时间、Hadoop集群管理参数设置(主从节点数量及状态设置)、索引库状态设置与管理等。
2.4.3 搜索辅助接口
除了基本的检索功能之外,还有其他的一些辅助功能,以提升用户体验增加用户粘度。比如:支持多关键词同时搜索,如同时输入“Java”“MySQL”“软件工程师”;支持二次查找;设定查询结果的日期,比如最近一天、最近一周、最近一月、最近一年等;可指定搜索关键词在网页出现的位置,比如可设置为网页内的任何地方、标题或者网址;可设定搜索域,比如指定仅搜索指定网站或是将指定网站排除在搜索之外;提供搜索指引,在搜索首页与搜索结果列表页以多级分类方式提供用户搜索指引;提供历史搜索,在用户浏览器中保存用户最近搜索的5个关键词及其对应搜索时间,节省用户输入时间;订阅查询,在用户浏览器中可保存用户订阅的5个关键词,当用户进去搜索引擎首页或搜索结果列表页时,依次列出各关键词新增查询结果条数;个性化设置用户习惯,可根据用户个人使用习惯设置相关参数,如:每页显示结果数目、是否显示搜索框、设置网页语言搜索范围等;其他扩展功能如相关职位名推荐、热门词推荐、检索词高亮显示、按专业的关键词推荐等辅助功能。
3 测试与分析
3.1 测试数据准备
基于以上研究,从猎聘网下载职业词库以及从中国教育在线下载专业词库构建就业领域本体库,并选取十多个求职招聘网址,依次为智联招聘、前程无忧、58同城招聘、赶集网招聘、猎聘网、中华英才网、卓博人才网、智通人才网、我的工作网、大街网、中国人才热线、应届生求职网、应届毕业生网、过来人求职网、拉勾网、大谷打工网、招聘信息、智通人才网等作为初始URL种子。
3.2 测试及结果分析
查全率和查重率是评价搜索引擎的2个重要指标[14],理想状况下搜索引擎既有良好的查全率又有良好的查准率,而实际情况往往是两者不可兼得。文中从主题相关性、与其他搜索引擎比较这2个方面分析实验结果。
3.2.1 主题相关性分析
与百度谷歌等通用搜索引擎不同,基于Nutch的就业垂直搜索引擎设计了主题相关性判别,检索到的网页与主题相关程度,体现了垂直搜索引擎的针对性和专业性,主题相关率越高,专业性越强。主题相关率=与主题相关的网页数/检索出的网页总数量。文中选取“软件工程师”、“数据分析师”、“幼师”、“日语翻译”、“Java开发”5个关键词作为检索词,对检索结果的前40项进行分析,采用人工干预方式对改进LinkRank算法前后进行相关性分析,结果如表1所示,表中的数据“值1-值2”分别表示LinkRank算法改进后与改进前得到的值。
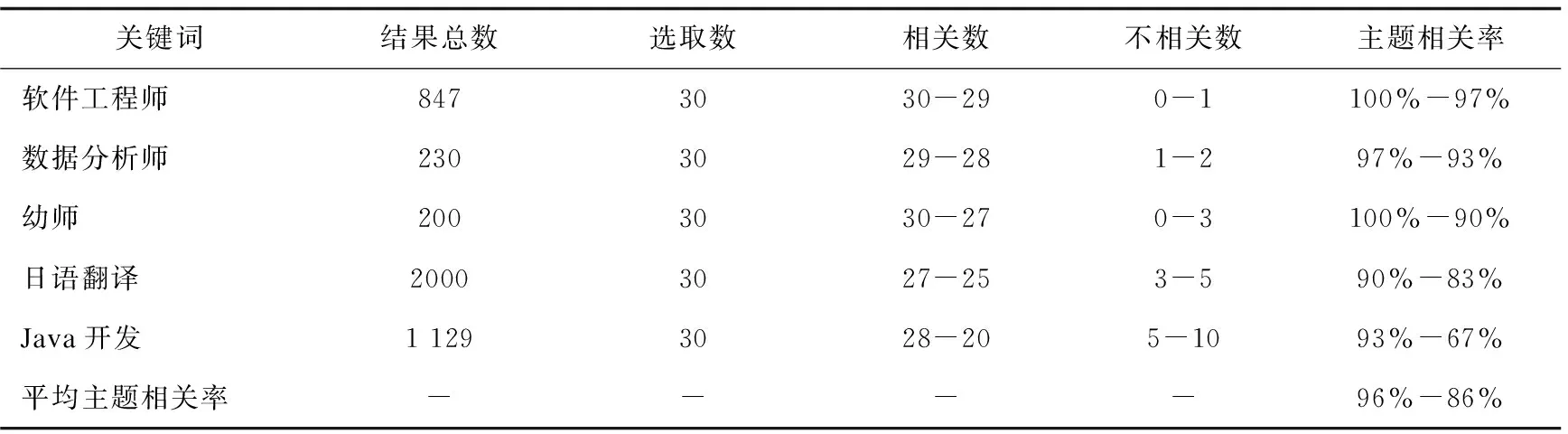
表1 主题相关性分析结果比较
3.2.2 不同搜索引擎的比较
查准率、死链率、重复率、响应时间等是搜索引擎好坏的评价指标,查准率尤为重要。继续选用前文所述的“软件工程师”、“数据分析师”、“幼师”、“日语翻译”、“Java开发”5个搜索关键词进行检索并结合以上评价指标与百度、职友集进行对比分析,其中查准率、死链率、重复率、响应时间都采用平均值,由式5计算而得。
(5)
其中,N表示搜索关键词数量;n表示网页数量(文中取40);n1表示与用户需求有关的网页数量。
详细数据如表2所示,表2中的数据“值1-值2”表示改进LinkRank算法后和改进前的值。

表2 不同搜索引擎比较分析
由表2数据可知,通用搜索引擎在响应时间方面有较大的优势,响应时间短,但是在查准率、死链率和重复率方面的劣势也较明显。文中基于Nutch的就业垂直搜索引擎虽然响应时间比其他搜索引擎长,但是在可接受范围内,在查准率、死链率和重复率方面有较明显优势。
4 结束语
文中设计并实现了基于Nutch的就业垂直搜索引擎,根据行业特色和需要对Nutch进行二次开发,加入ik-analyzer中文分词,同时运用就业领域本体改进基于特征词的向量空间模型,进行主题性判别,结合LinkRank算法改进排序结果。此外运用Java开发技术及框架,对用户查询接口进行了二次开发,增加了许多便于用户操作的功能,如关键词智能提醒、爬虫定制、高级检索、关键字订阅、定制用户显示界面、热门词推荐、关键词高亮显示等。基于Nutch的就业垂直搜索引擎与通用搜索引擎相比方便了用户检索招聘信息,提高了求职招聘信息的查准率。
