生成式对抗网络在语音增强方面的研究
2019-02-25孙成立王海武
孙成立,王海武
(南昌航空大学 信息工程学院,江西 南昌 330063)
0 引 言
人工智能[1](artificial intelligence,AI)和基因工程以及纳米技术被称为21世纪三大顶尖科技。AI隶属于计算机学科,它的实质是让人类理解智能科技,核心就是机器学习。机器学习[2](machine learning)是以计算机为基础来模拟人的意识、学习行为,以得到新的知识或技术,将这些已经存在的知识进行重组使自己的能力得到不断提升的学科。近年来,随着计算机计算能力的不断提升,使得机器学习从之前的浅层学习[3]过渡到了现在的深度学习[4]。伴随着人工智能热度的上升,科技领域的研究者们对深度学习的关注度也越来越高,基于深度学习的模型如GAN、DBN(深信度网络)、RNN(循环神经网络)、CNN(卷积神经网络)[5]、自动编码器[6]等也不断被提出。在大数据的背景下,大量的数据样本被保存起来,使得GAN得到了迅速发展。当前,GAN已开始应用在语音生成[7]、图像处理[8]和生成语言文本等领域。
语音信号处理作为人工智能的一个研究方向,不断推动着人工智能的发展,特别是语音增强的研究。语音增强就是从含噪的语音环境中,提取出纯净语音信号的过程。文中研究了GAN在语音增强中的应用,实现建模,再根据语音质量评估方法(segSNR、PESQ)计算相应的值,将GAN增强后的语音与其他传统方法进行比较。
1 GAN的概念和模型
1.1 GAN的概念
GAN作为深度学习模型之一于2014年由Ian J.Goodfellow等[9]根据博弈论中的二人零和博弈的思想而提出,将进行博弈的两人分为生成器(generator,G)和判别器[10](discriminator,D)来进行建模。生成器是获得真实的数据样本中所含的隐含信息而产生新的数据样本;判别器是根据输入的数据判断是真实的数据样本还是生成器生成的数据样本,实质是二分类器。根据博弈论[11]中的观点,二人为了达到各自所需要的结果,会不断优化自己,提升自己的博弈能力,同样在GAN中生成器会不断地提升自己生成数据的能力,判别器会不断地提升自己判断数据的能力。
1.2 GAN的模型
根据GAN中的概念可以得出GAN的流程,如图1所示。
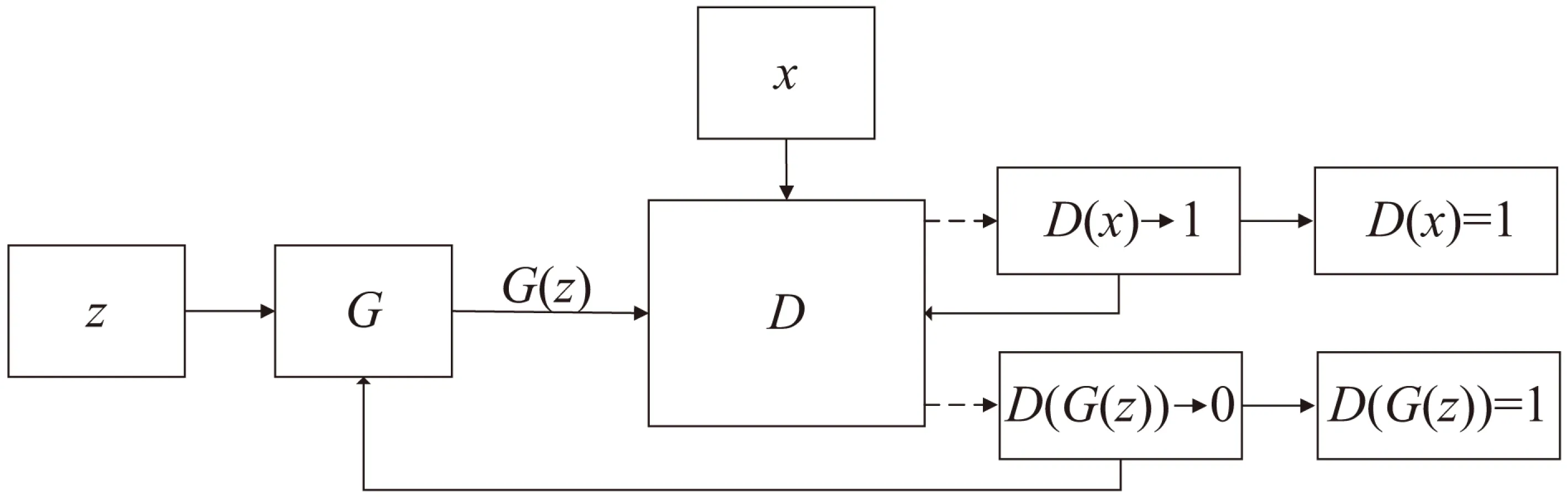
图1 GAN的流程
图中,z表示随机变量,服从pz(z)分布,G表示生成器,G(z)表示生成器生成的数据,x表示真实的数据样本,服从pdata(x)分布,D表示判别器,D()表示概率。判别器D判断输入是来自真实的数据样本还是来自生成器,若来自真实的数据样本则将其置为1,来自生成器的将其置为0。
随机变量z通过生成器G,生成G(z)的数据样本,G(z)和真实的数据样本x通过判别器,在开始的时候判别器判别输入的数据是来自真实的样本还是生成器生成的,使D(x)向1趋近,D(G(z))向0趋近;然后将判别的结果返回到判别器和生成器,判别器和生成器不断进行优化,生成器的目的是使判别器对生成的数据产生误判,所以最后的结果是D(x)=1,D(G(z))=1,这就是GAN模型图的含义。在实际的建模中,单单有模型图还不够,还需要GAN的数学模型,根据传统GAN的概念,GAN的数学模型可以表示为:

Ez~pz(z)[log(1-D(G(z)))]
(1)
但在实际的建模中,由于判别器D会同时使用对数损失(log loss)和sigmoid函数[12],sigmoid函数会发生快速饱和的情况,导致D的梯度迅速降为0。对于学习真实数据的分布,对数损失(log loss)不产生作用,而在训练生成器G时是需要使用到D的,会导致G的训练受到很大的影响。为了解决这个问题,可以将模型1改变为:
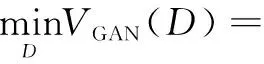
(2)
(3)
2 GAN在语音增强的应用
2.1 语音增强的GAN概念
语音增强的实质是从混有噪声的语音信号当中过滤噪声,获得纯净的原始语音信号。语音增强的GAN也就是将GAN中的随机信号z和真实的数据x映射到需要增强的语音信号和纯净的语音信号,由GAN的概念,GAN是将随机信号z服从pz(z)分布转换成另一种x服从pdata(x)分布(也就是真实的数据分布)的模型,所以这里可以把随机信号z当成是含噪语音noisy,真实的数据x可以看成是纯净的语音pure voice。
2.2 语音增强的GAN数学模型
依据GAN应用在语音增强中的概念和GAN的数学模型,可以得到语音增强的数学模型,见式4和式5。这里将含噪语音noisy记为n,设其服从fn(n),纯净的语音pure voice记为p,设其服从fp(p)。
(4)
(5)
2.3 语音增强的GAN算法流程
语音增强的GAN算法流程为训练判别器D的权重和固定判别器D的权重训练生成器G的权重,流程如图2和图3所示。
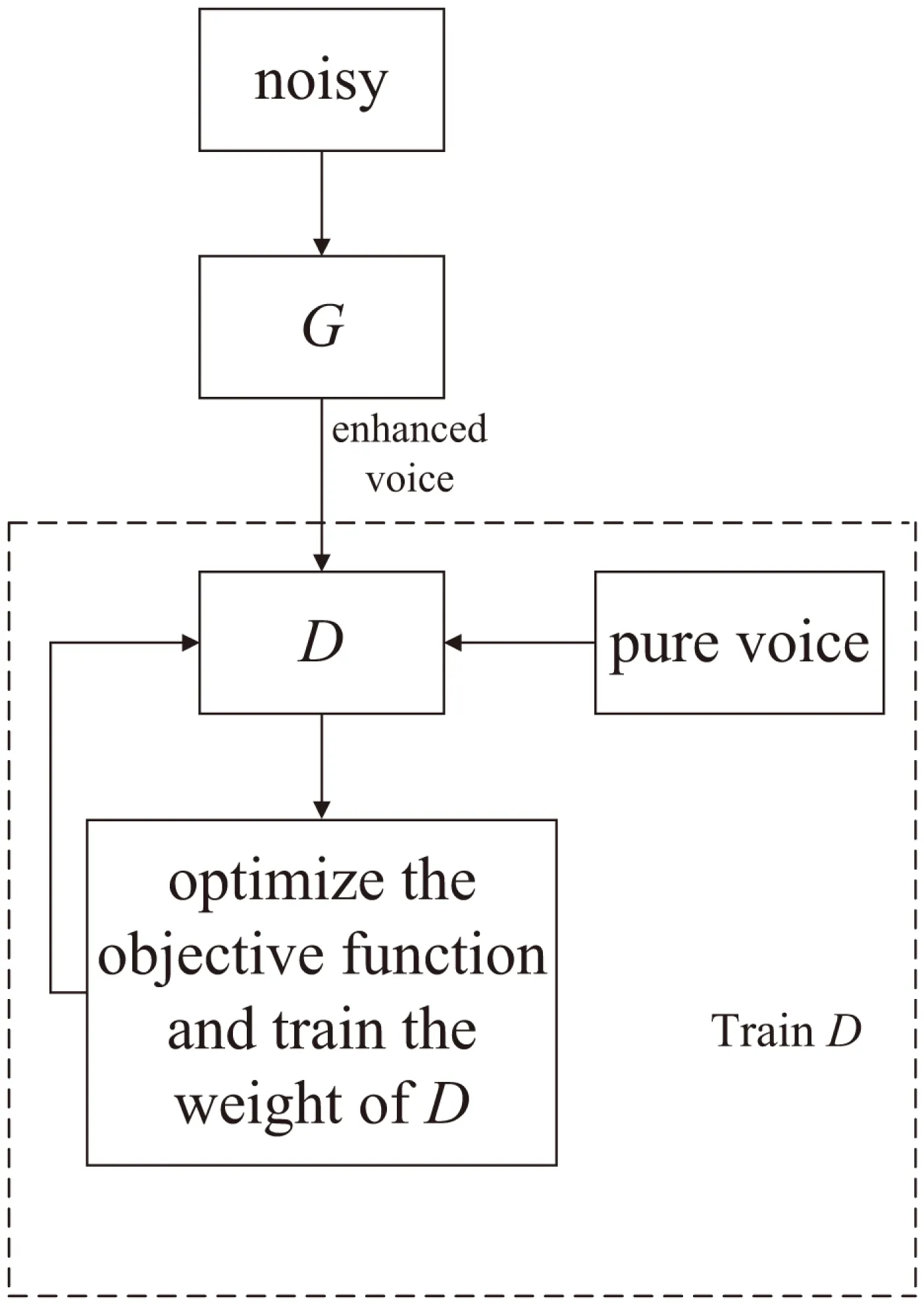
图2 训练判别器D的权重
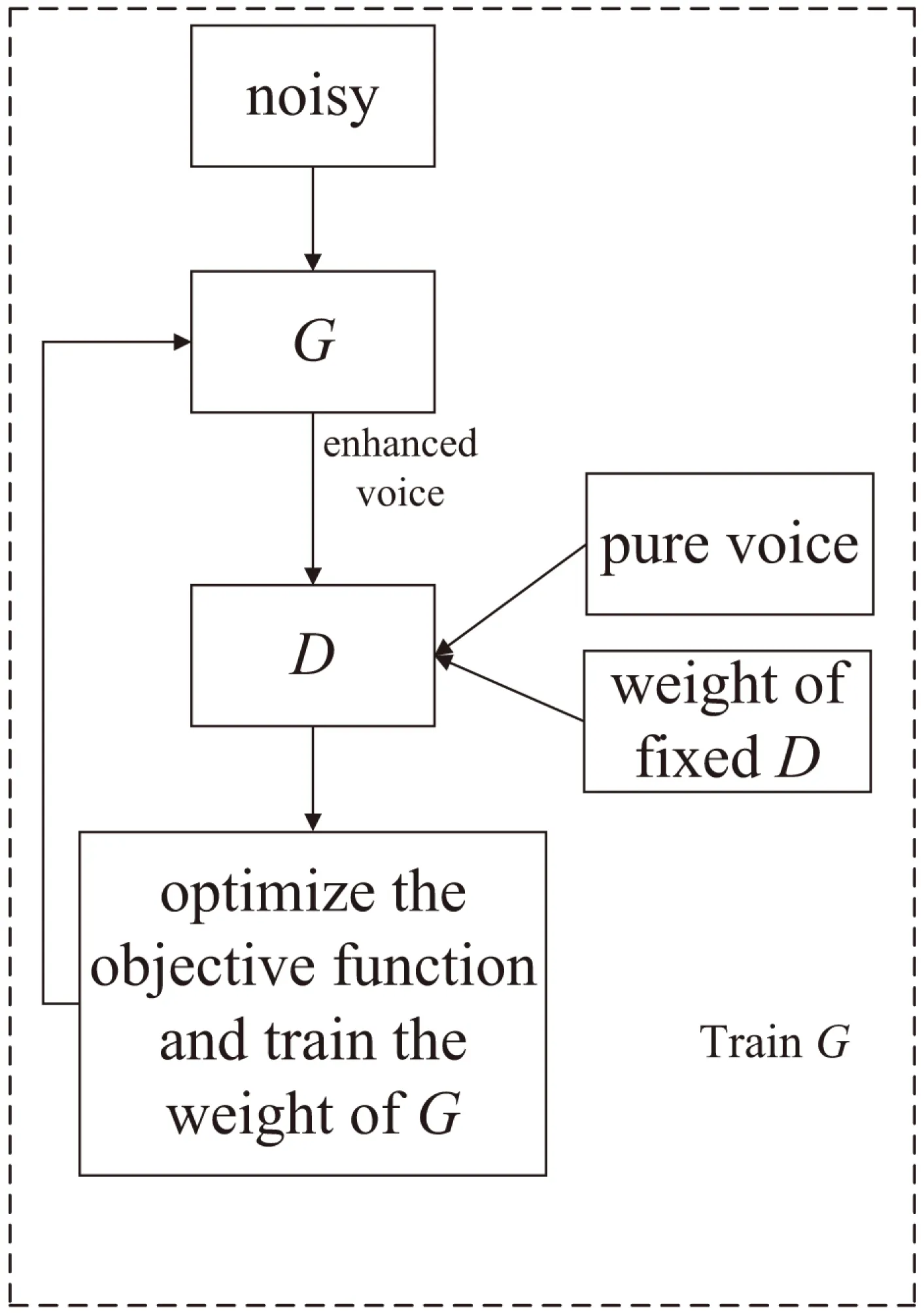
图3 训练生成器G的权重
3 实验及结果分析
3.1 实验过程
实验是把tensorflow作为后端,基于keras实现,通过卷积神经网络来建立D和G模型。G是通过二维的卷积层和反卷积层实现,宽度是31,选用“same”的补零策略,以及PReLU激活函数,D是通过一维的卷积层实现,宽度是31,选用“same”的补零策略,以及LeakyReLU激活函数(alpha=0.3),最后连接了一个全连接层。实验用的训练数据是NOISEX-92噪声库[13]中的babble噪声,纯净的语音来自NOIZEUS语音库[14],将babble噪声和纯净的语音进行叠加,形成语音信噪比分别为-5 dB、0 dB、5 dB、10 dB、15 dB各100个含噪语音句子,总共500个含噪语音句子。用Matlab先将含噪语音和纯净语音转换成.mat格式的数据,重叠率为50%画窗截取波形,采样频率是16 kHz,测试用的是20个信噪比为0 dB的语音句子。
3.2 实验结果分析
图4和图5是根据传统的GAN数学模型直接引入到语音增强中进行建模得出的结果,迭代次数b取50。其中noisy是含噪语音,voice是增强后语音,pure是纯净语音。从图中可以看出,通过生成器增强后语音波形发生了改变,但增强后的语音波形与纯净的语音波形相差很大。
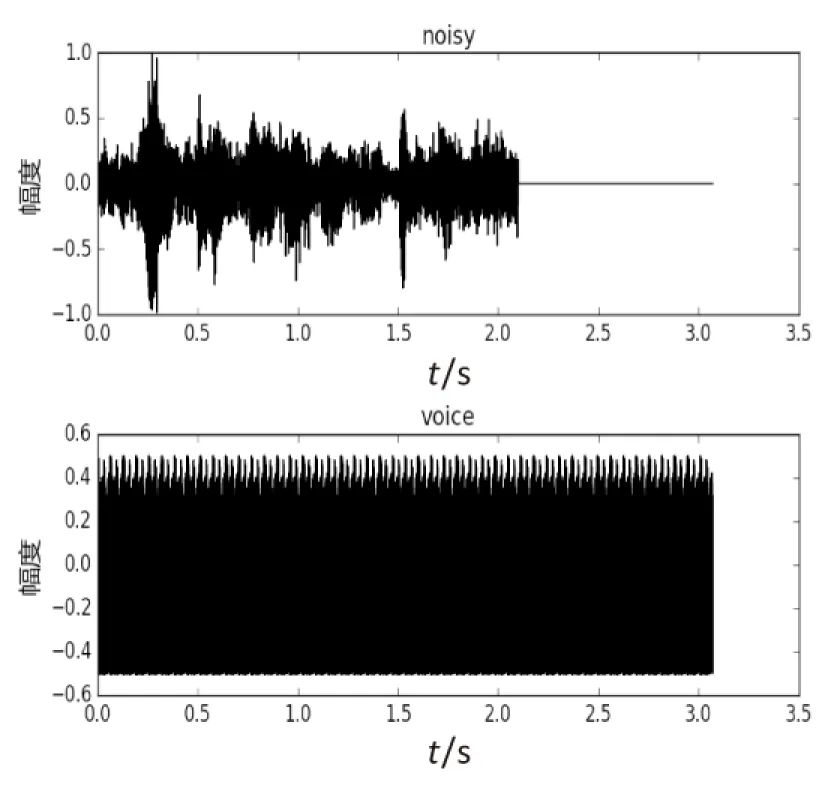
图4 含噪语音和增强后语音波形图对比
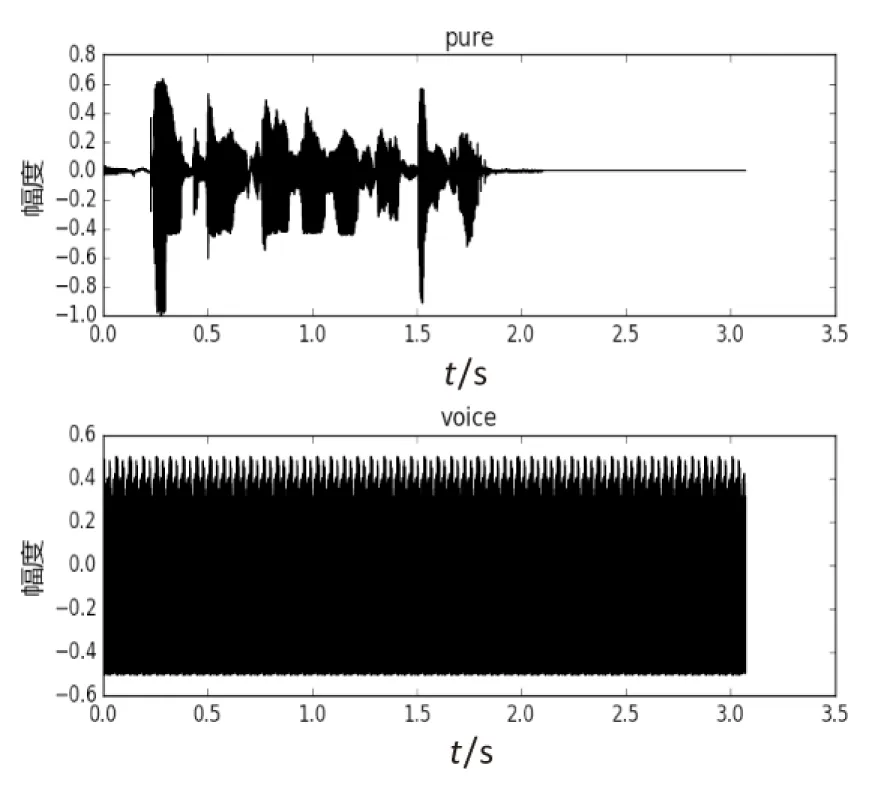
图5 纯净语音和增强后语音波形图对比
4 改进语音增强GAN模型与传统的语音增强算法比较
4.1 改进语音增强GAN模型
从上面的实验结果发现,根据传统的GAN模型来实现语音去噪是很不理想的,生成器并没有很好地实现语音增强。原因是由于模型需要训练的参数太多,增加了模型的复杂度会产生过拟合[15]现象,同时学习了训练样本中噪声数据和语音数据的无关特征,使得训练误差小(从程序运行的过程看,训练误差确实很小),但在测试数据的时候误差往往比较大。为了解决这个问题,提出了稀疏因式,即含噪语音与纯净语音差的绝对值均值,将其加入到生成器的损失函数中。在这里将式5改为:
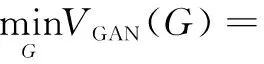
ρEn~fn(n),p~fp(p)[|G(n)-p|]
(6)
其中,ρ为稀疏因式的系数。
根据式6中生成器的损失函数再次进行实验,迭代次数b同样取50,ρ取100,实验结果如图6所示。
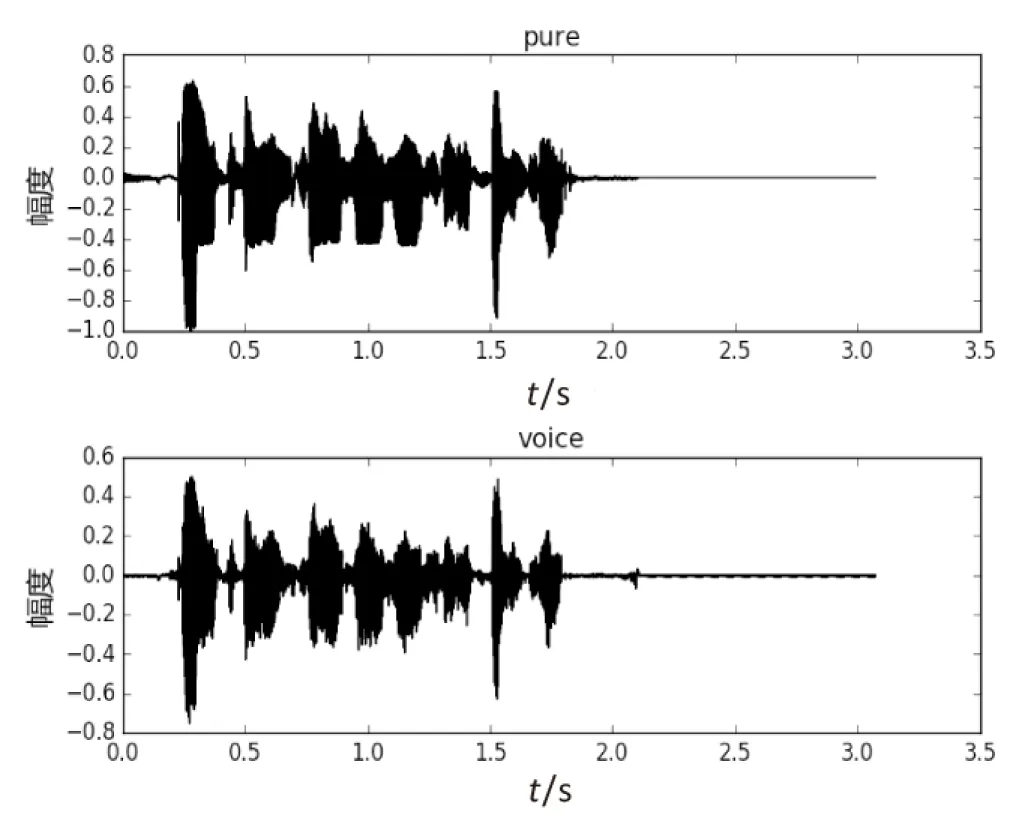
图6 纯净语音和增强后语音波形图对比
从图6可以看到去噪效果比较好,增强后的语音波形比较接近纯净的语音波形。
4.2 语音增强GAN与传统的语音增强算法的比较
选用CLSMD[16]、mss_map[17]、subspace[18]、MMSE[19]、SS[20]、Wiener[21]等传统的语音增强方法作为参考,选用语音质量评估标准中最为经典的segSNR[22](分割信噪比)和PESQ(perceptual evaluation of speech quality)[23]来计算得分,其中segSNR是指对噪声的抑制能力,值越大越好,PESQ是指评估主观的语音质量,值也是越大越好。噪声同样选择了NOISEX-92噪声库中的噪声,分别为babble餐厅噪声、pink噪声和white噪声,纯净的语音同样来自NOIZEUS语音库;将三种噪声和纯净的语音分别进行叠加,各自形成了自己的语音信噪比,分别为-5 dB、0 dB、5 dB、10 dB、15 dB各100个含噪语音句子,总共500个含噪语音句子。实验结果如表1和表2所示。
从表1和表2中可以看到,语音增强GAN算法的PESQ和segSNR得分明显要高于其他传统语音增强算法的PESQ和segSNR得分,在低信噪比的环境中表现更为突出,所以语音增强GAN算法在抑制噪声的能力和提升主观语音的质量方面要优于其他传统语音增强算法。
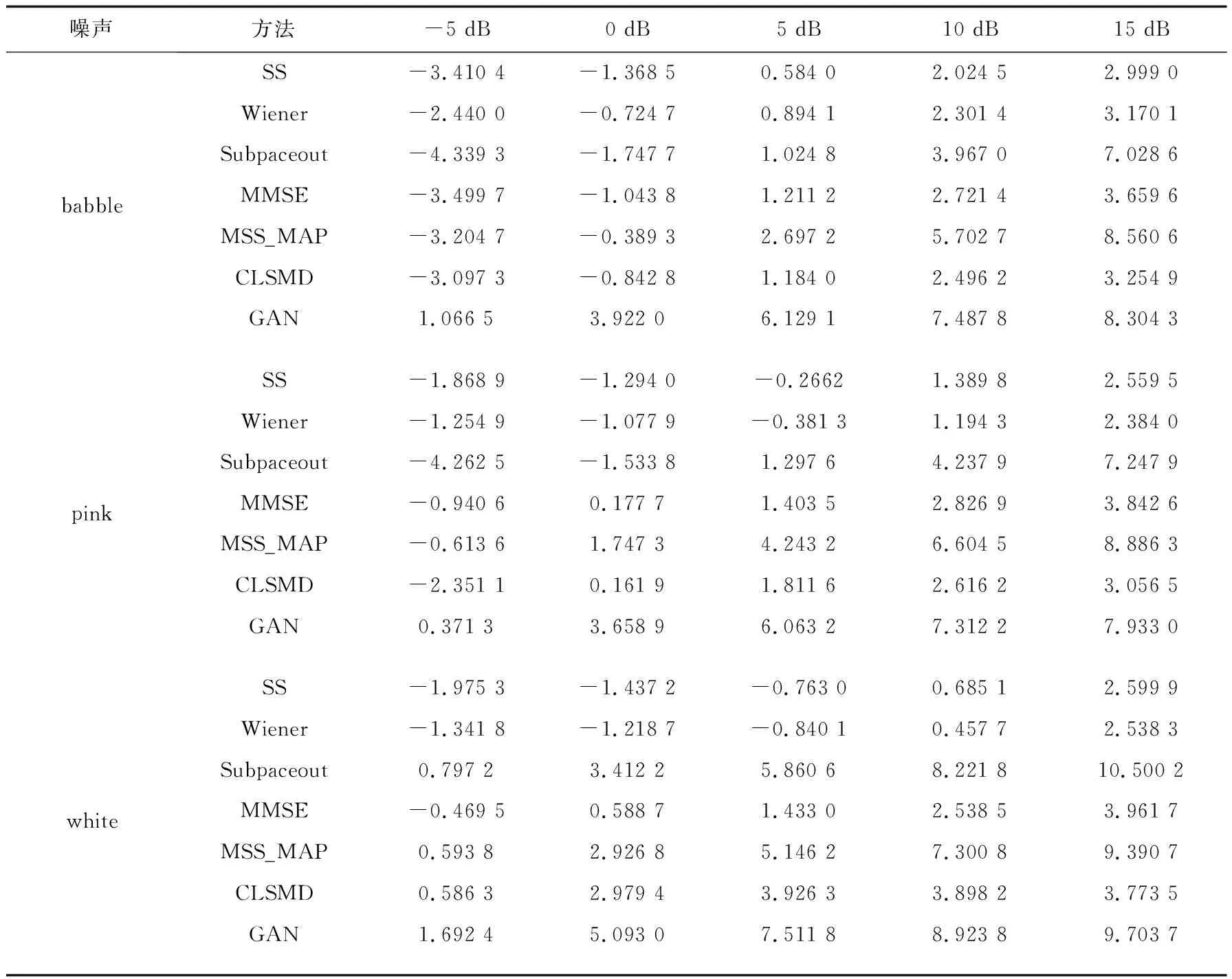
表1 在不同的噪声条件下各语音增强方法的segSNR
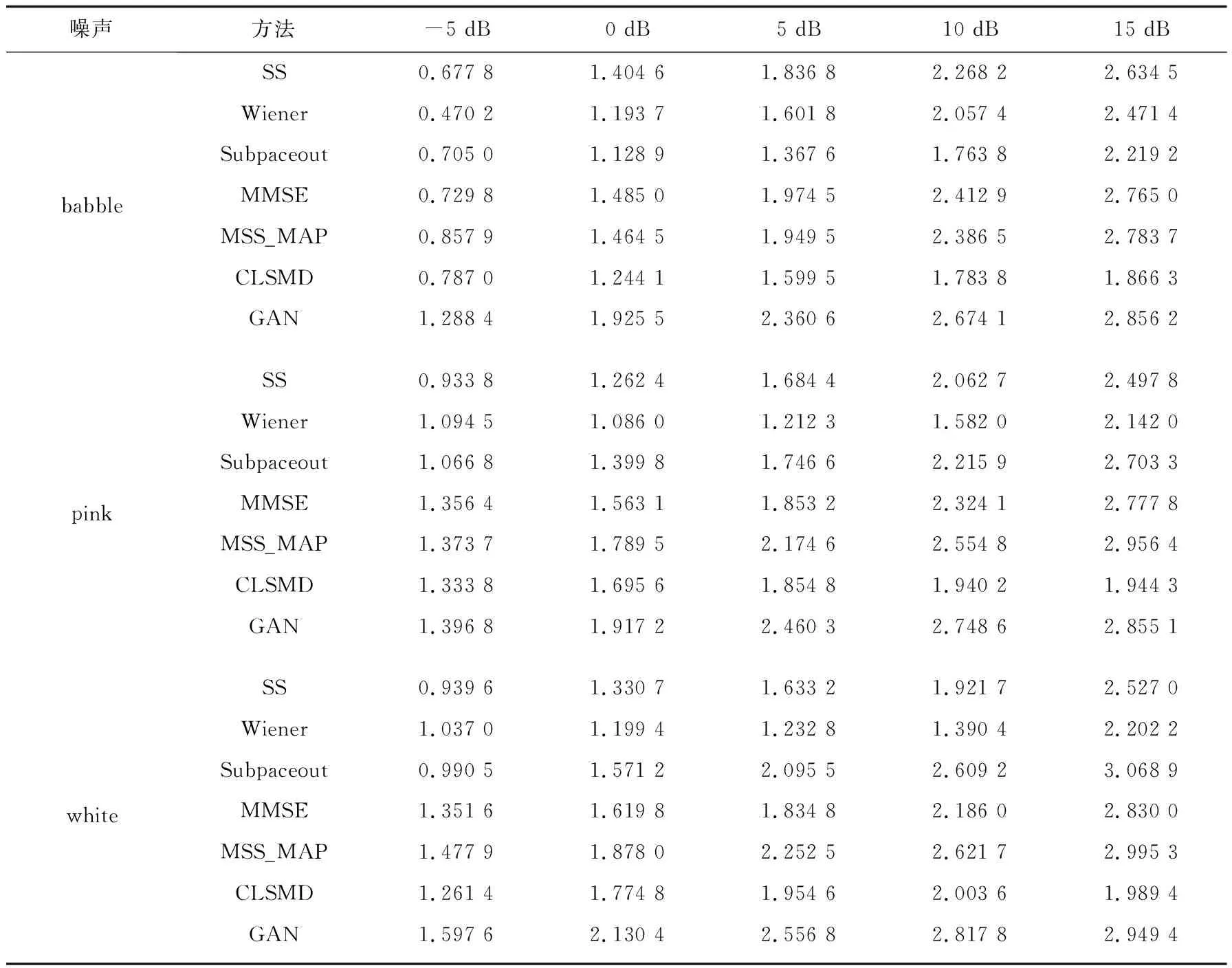
表2 在不同的噪声条件下各种语音增强方法的PESQ
5 结束语
引进了当今热门的GAN模型,写出了GAN的概念和模型,将GAN的对抗式训练思想与语音增强相结合,得出语音增强的GAN模型,成功实现了GAN在语音增强中的应用,并通过实验发现直接将传统的GAN模型用于语音增强是不理想的,于是提出将稀疏因式加入到生成器G的损失函数中,并通过实验得出在G中加入稀疏因式后的图形更加接近纯净的语音波形,能更好地去除噪声。最后计算GAN增强后的语音与其他传统方法增强后的语音的segSNR和PESQ值,通过对比可知,语音增强的GAN算法能更好地实现语音去噪。
