基于MODIS数据的洪涝灾害分析研究
——以2017年洞庭湖区洪水为例*
2019-02-20饶品增蒋卫国王晓雅
饶品增,蒋卫国,王晓雅,陈 坤
(1.北京师范大学 地理科学学部 环境演变与自然灾害教育部重点实验室,北京 100875;2.环境遥感与数字城市北京市重点实验室北京师范大学 地理科学学部,北京 100875;3.中国环境科学研究院土壤与固体废物研究所,北京 100012)
洪水灾害是发生最频繁和影响最严重的自然灾害之一。较高分辨率的光学遥感影像能应用于洪水水体淹没范围的监测和研究,尤其是平原地区的湖泊和河流等[1]。目前,常用于监测洪水的遥感数据包括Landsat和MODIS等。其中Landsat系列数据具有较高的空间分辨率(普遍为30 m),能提取较小范围的水体,但由于时间间隔较大(16 d及以上),对周期短和强度大的洪水的监测常存在不足[2-3]。MODIS数据具有较高的空间分辨率(250 m和500 m等),且其时间周期短,能很好地监测洪水动态变化过程[4-5]。对于时间周期较长的影像如Landsat数据,洪水时期通常只有一期或少数几期影像能满足要求,有时甚至没有。但洪水期间常存在着巨大的水体淹没范围波动,不同日期洪水的淹没范围完全不同。可见,时间间隔较大的遥感影像所获取的洪水水体淹没结果的实时性较差,且不全面。而对于时间周期短的遥感影像如MODIS,能很好的捕捉到洪水期间水体淹没的动态变化过程,这有助于更准确地探究洪水所造成的灾害影响等[6]。理论上说,洪水期淹没的最大范围减去正常水体覆盖即为洪水淹没的有效范围。
遥感数据常用的水体提取方法主要包括两大类:指数方法和监督/非监督分类的方法。指数方法通过利用2个及以上的波段构建一个新的指数,通过设定阈值区分水体和非水体。指数方法几乎都是在正常水体情况下构建的,在提取洪水范围时,会受到很多因素的干扰,包括水质和云等。监督/非监督分类方法不用设定阈值,利用相关的数理统计方法和合适的分类器便可达到分类的目的,当下热门的机器学习方法便属于此类方法,典型的如支持向量机[7]、神经网络和随机森林等。该类方法通过选取适量的样本点和足量的波段信息,便可构建相应的分类模型并实现水体提取的目的。
洞庭湖由于其特殊的气候条件和地理位置,是中国洪水灾害发生最频繁的地区之一。2017年6月~7月,洞庭湖上游地区普降暴雨,局部地区出现特大暴雨,湘江、资水、沅水三条干流及洞庭湖区等地均出现了超警戒水位。7月中旬,洞庭湖的入湖洪量达64 630 m3/s,超过了1998年的63 360 m3/s,直逼1954年的67 000 m3/s[8],造成了该地区前后一个多月严重的洪水灾害。目前针对该次洪水事件的相关研究较少,且对洪水造成的灾害损失的评估存在欠缺。本文选取随机森林模型和多期MOD09A1产品数据获取得到该次洪水造成的洪水淹没范围,并统计淹没区内可能造成的农作物损失及相应的经济损失,得到了较为可靠的结论,这为相关部门和该地区的洪水灾害损失提供了一种较好的评估途径。
1 研究区概况
洞庭湖是中国第二大淡水湖泊,仅次于鄱阳湖,位于长江中游湖南省北部,经纬度介于28°30′N~30°20′N和112°25′E~113°15′E之间,北与长江相连,南部地区为洞庭湖的水系来源,流域面积达26.28万km2,主要涵盖了湖南省大部分地区及周边省份部分地区。流域内降水丰富,且存在明显的季节性变化,夏季降水频繁且强度大,冬季则降水稀少。夏季丰水期时,洞庭湖水面辽阔,洪水灾害时有发生;冬季枯水期时,水面严重萎缩,形成多草的滩地。本文选择洞庭湖及和湖周边低洼平原地区,主要涵盖了湖南省的15个市县(图1)。
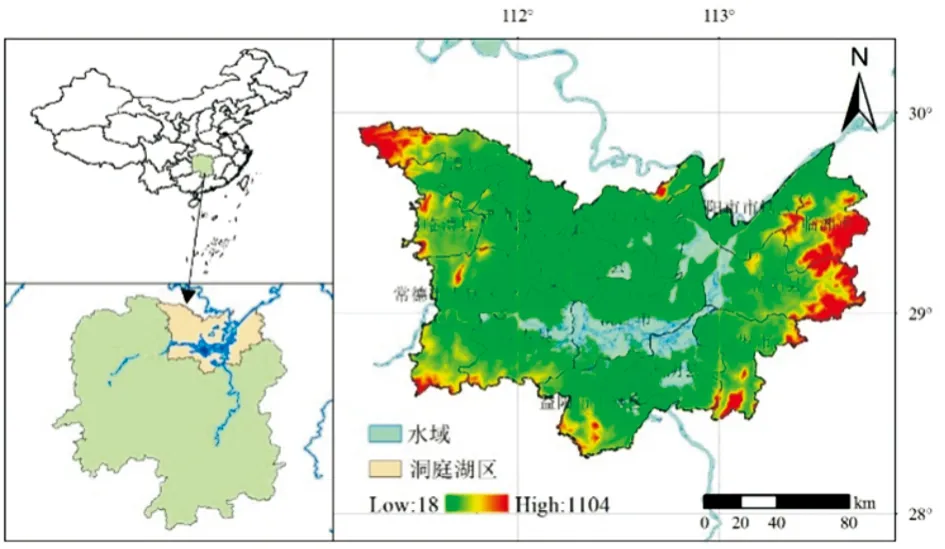
图1 研究区地理位置
2 数据来源与研究方法
2.1 数据来源
2.1.1 MODIS数据
(1)MOD09A1
MOD09A1是Terra卫星经过大气辐射和气溶胶校正后的MODIS地表反射率合成产品,属于陆地2级产品,其空间分辨率为500 m,时间分辨率为每8 d,主要涵盖的数据为MODIS的1~7波段反射率数据,以及其他一些辅助数据,包括太阳天顶角,像元生产日期和波段质量数据等。本文从USGS官网(https://lpdaac.usgs.gov/)下载了2017年2017001-2017361天共46期的MOD09A1数据。数据格式为HDF,采用MRT(MODIS Reprojection Tool)工具进行批处理获取得到相应的1~7个波段反射率数据。
(2)MOD44W
MOD44W最早是由Salomon等[9]在2004年生产的一套全球250 m分辨率的陆表水体数据,目前该套产品已被MODIS官方收录在MODIS产品当中,而且有了第6代产品。该套数据覆盖了全球主要的湖泊和较大型河流,其水体分类效果较好已被许多研究人员证实,但整体上略偏大[10]。MOD44W产品主要提供了粗略的水体淹没数据,其中水体值为1,陆地值为0,空值或者边界值为253。本文使用的MOD44W数据为第5代的产品数据,用作水体样本点选取的先验知识。
2.1.2 农作物分布数据
本文获取了陈军等[11]生产的2010年全球30 m的土地利用数据,该数据提供了10种地表类型,包括水体、湿地、人工表面、林地、草地、耕地、灌丛、冰雪、苔原和裸地等。本文选取了洞庭湖区的土地利用数据,涵盖其中的8种土地利用类型,其中占比较大的包括耕地、水体、湿地和林地等(图2)。
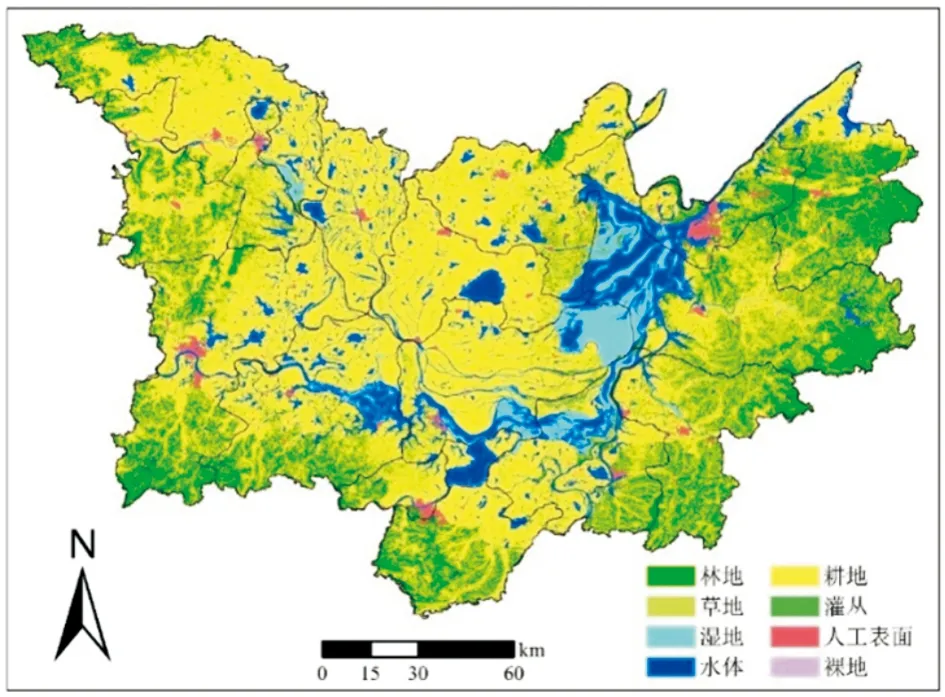
图2 洞庭湖区土地利用数据
2.2 研究方法
本文使用的方法主要包括两部分:水体提取方法和洪水淹没范围确定方法。采用机器学习的方法做监督分类,主要需要考虑三个问题:①水体和非水体样本点的选择;②解释变量的获取;③机器学习方法的高效性。本文通过多种方法比较,包括传统的指数方法和目前应用较广泛的逻辑回归、支持向量机和随机森林方法等,最终选择了随机森林作为洪水水体提取的分类方法。另外,对于洪水水体淹没范围的获取,本文采用了空间叠置和统计的方法,构建了洪水淹没水体获取的整体流程。
2.2.1 随机森林模型
随机森林(Random Forest,RF)是由Leo Breiman等[12]于2001年提出来的。它是基于传统的决策树原理改进成的集成分类器,决策树是单一的树,而随机森林则是由多棵决策树组合成分类回归树(Classification And Regression Tree,CART)构成。在训练过程中,对于每一棵树来说,他们之间都没有关联,选择从已知提供的总训练集中有放回地随机选取样本用作训练,其训练样本都不完全相同。训练结果通过某种判决条件来进行判断,好的结果保留,差的去除,这使得样本被使用的频率完全不同,其中有效样本被多次、高效利用,无效样本的使用率降低,使得其噪音影响也随之下降。基于此原理,相比于单一的决策树分类方法,随机森林由于具有多棵树和重复采样的特点在分类过程中表现出更稳健,泛化能力更好的特点。
根据Leo Breiman的文章和其他一些相关材料,随机森林的过程可以定义为:随机森林是由一系列树状分类器组成的一个集成分类器。它主要通过一个边际函数来进行收敛,公式如下:
(1)
式中:avk表示取平均;I(·)是一个指示函数,显然,I(hk(X)=Y)和I(hk(X)=j)等于0或者1,前者代表了投票正确的概率,后者则代表了其它分类(分类的目标变量应该大于等于2)投票错误的概率,两者取平均相减,当差值mg(X,Y)越大,则表明分类正确的置信度越高。
2.2.2 洪水水体提取流程
对于一次洪水过程,其造成的水体淹没范围应为洪水时期的最大淹没范围去掉洪水前的淹没范围。水体提取流程包含6个步骤:第1步,获取MOD09A1数据并预处理,通过相应波段生产NDVI、NDWI和MNDWI三个指数,和MOD09A1本身含的7个波段一共构建10个特征变量;第2步,利用MOD44W人工采集水体和非水体样本点,总数约1 000个左右,水体和非水体均约500个;第3步,基于拥有的特征变量和样本点,利用随机森林分类器进行分类;第4步,初步分类结果通过人工目视解译去除云和云阴影等噪声;第5步,区分洪水期和非洪水期水体影像,将洪水期水体影像进行叠加得到洪水期最大淹没面积,背景水体影像则采用非洪水期的最大一期水体影像;第6步,利用背景水体掩膜洪水期最大淹没水体,获得洪水淹没水体范围,其它部分还包括正常水体和非水体像元(图3)。

图3 洪水水体提取流程图
2.2.3 其他方法
除随机森林方法外,本文还利用了NDVI、NDWI和MNDWI等三个指数提取水体。另外,为了验证随机森林方法相比其它类似的机器学习类的监督分类方法效果更好,本文还尝试了应用逻辑回归(Logistic Regression,LR)和支持向量机(Support Vector Machine,SVM)提取研究区的水体。逻辑回归方法为改进的多元线性回归方法,被广泛应用于分类和回归,其中应用较多的研究领域为地质灾害易发性评价等[13-14]。支持向量机是非线性分类器,提出于1995年,目前被广泛应用于数据分析、地物分类和模式识别等。在遥感地表分类方面,其效果也得到了广泛的认可[15]。
3 评价结果分析
3.1 水体提取方法比较分析
选取洪水时期含云量较少的一期影像(2017185天),采用三个指数(NDVI、NDWI和MNDWI)和三种机器学习方法(LR、SVM和RF)提取水体,不做去噪声处理,并和2、5、3波段假彩色影像进行比较(图4)。其中,通过多次尝试,NDVI、NDWI和MNDWI选择的最优阈值分别为0.1、-0.1和-0.1。对比图4中效果,彩色图中的蓝色圆圈为薄云覆盖区域,NDVI、NDWI和MDNWI指数存在将较大部分的云错分为水体,尤其是MNDWI,云几乎都被识别为水体。红色圆圈里面的水体在LR和SVM方法中均存在较明显的漏分现象,尤其是LR,大量水体像元未被识别。RF在错分和漏分两个方面表现均较稳定,相比其它五种方法较为精确和稳定。因此,本文选择RF作为最终的洪水水体提取方法。
根据假彩色影像,目视解译其中的水体部分,并与随机森林的水体提取结果进行叠加比较。结果显示,水体重叠率为95.65%,这可看作为该影像的水体提取精度。
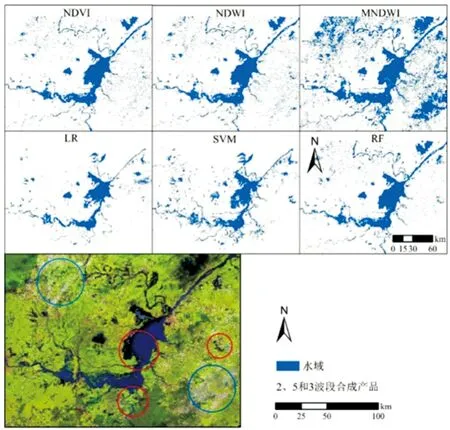
图4 2017185天MOD09A1遥感影像水体提取结果
为了确定非洪水时期的水体提取效果,本文选择洪水前的一期影像(2017169天)进行精度验证。该影像本身也含有部分云,本文利用MOD09A1的波段质量数据,去除云层,并手动去除噪声和修复部分水体,得到最终如图5b中的水体分布结果。目视解译图5a中的水体部分,将两者进行叠加,统计得水体像元的重合率为95.53%。可见,随机森林方法能很好地应用于研究区的水体提取。

图5 2017169天MOD09A1遥感影像水体提取结果(RF)
3.2 洪水水体变化分析
据调查和分析,6-7月洪水造成的大范围淹没水体主要发生在6月底和7月,2017169天可看作为洪水前的背景水体,2017177-2017209天的5期MOD09A1影像可看作为洪水淹没水体,结果见图6。
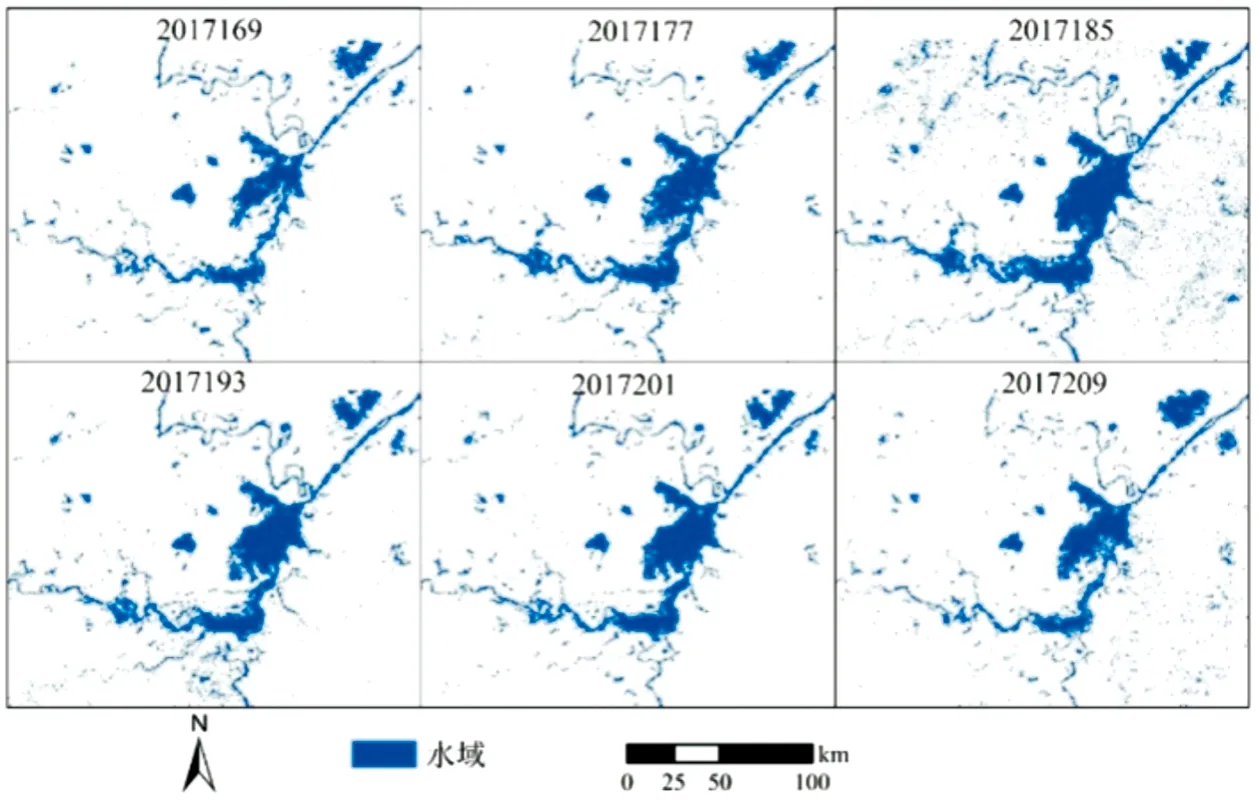
图6 2017年洞庭湖区洪水前后淹没范围变化
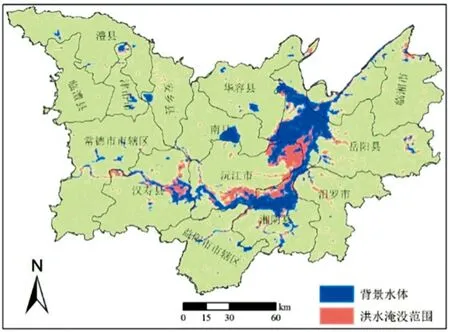
图7 2017年洞庭湖区洪水淹没范围
根据2.2.2中的洪水水体提取流程和方法,叠加2017177-2017209天的5期水体结果影像得本次洪水淹没的最大水体面积,该结果被认为是本次洪水的水体淹没范围,背景水体选择洪水前2017169天的水体提取结果影像,洪水淹没范围见图7。经统计,洪水时期最大的水体淹没面积为3 569.8 km2,去掉背景水体的面积1 926.7 km2,实际造成的水体淹没面积为1 643.1 km2,淹没面积相当于正常水体面积的85.28%。受淹地区主要位于洞庭湖周边,包括东洞庭湖南侧、南洞庭湖北侧和西洞庭湖西侧等地。按行政区域划分,受淹面积最大的县级单元为沅江市,离洞庭湖水域较远的县市受淹面积相对较小,如临澧县等。
3.3 农作物损失评估
叠加洪水淹没范围图和土地利用图,统计得本次洪水淹没的各种土地利用类型面积(表1)。损失面积最大的为耕地,面积达503.46 km2。
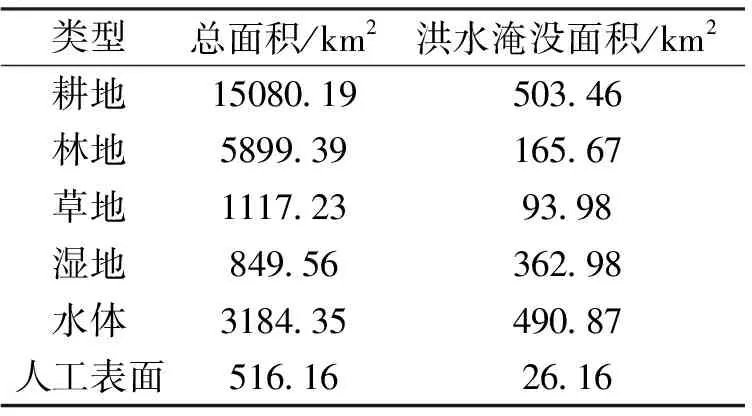
表1 洪水淹没区各土地利用类型面积
土地利用数据没有给出明确的耕地类型,据先验知识和调查,洞庭湖区耕地,尤其是洞庭湖周边的耕地基本都为水田。因此,受淹耕地均可看作为水田。由于阳历6月底和7月为洞庭湖水稻成熟和收割季节,本次洪水很大程度上会摧毁该地区的水稻作物。通过查阅2016年湖南省经济社会发展报告,最近一年(2015年)湖南省稻谷单位面积产量为6 429 kg/hm2[16],假设所有农田水稻均被破坏,根据此计算得该次洪水造成的粮食产量损失为32.37万t。以2017年12月湖南省大米均价每市斤2.23元[17]计算,得农作物受损导致的经济损失约为14.44亿元。
统计洞庭湖区各个市县受损作物面积、作物损失量和经济损失(图8)。以县级单元统计,受损最严重的为沅江市,受损作物面积达到11.95 khm2,对应的作物损失量和经济损失分别为7.68万t和17.13亿元;以地市级单元统计,受损最严重的为岳阳市,受损作物面积达到20.76 khm2,对应的作物损失量和经济损失分别为5.95万t和13.35亿元。

图8 洞庭湖区各市县洪水受灾结果图
4 结论与讨论
不同于前人利用单期影像反映洪水水体,本文提出了基于多期影像叠加的方式获取洪水水体淹没范围。此外,本文对比了多种水体提取方法,最终确认了随机森林方法的高效性和鲁棒性。最后,基于获取的洪水水体淹没范围统计了本次洪水可能造成的农作物损失等。结果表明:
(1)随机森林方法相比传统的指数方法(NDVI、NDWI和MNDWI)和常用的机器学习方法(逻辑回归和随机森林)具有较好的水体提取效果,在研究区的水体提取精度约为95.59%。
(2)根据洪水水体提取流程,本次洪水淹没面积为1 643.1 km2,淹没面积相当于正常水体面积的85.28%,受淹较严重的区域主要位于东洞庭湖南侧、南洞庭湖北侧和西洞庭湖西侧等地。
(3)本次洪水造成的农作物淹没面积为503.46 km2,基于此估算的作物损失量约为32.37万t,导致的农作物经济损失约为14.44亿元。其中受灾最严重的地级市为岳阳市,最严重的县级单元为沅江市。
