基于Python的天猫商品爬虫技术
2019-01-30侯洁茹吕继续
侯洁茹 吕继续
摘 要:信息技术的跨越式发展,尤其是人工智能新潮浪起的时代,不论身处哪个领域,数据已经成为一种重要的资源,而数据的采集很大程度上依赖于爬虫技术。该文结合对天猫出售的商品信息的抓取,阐述数据采集的基本流程。
关键词:网络爬虫技术 天猫网站爬取 数据采集
中图分类号:TP391.1;TP393.092 文献标识码:A 文章编号:1672-3791(2019)11(b)-0010-02
随着互联网科技的飞速发展,网上购物成为人们的生活中的一部分。天猫网站是网购中具有代表性的大型电子商务平台。它的商品信息数据十分庞大,包含了生活、学习、工作等多个领域的商品信息。该文以抓取天猫网站中的口红商品信息为例,详细介绍了使用网络爬虫实现从数据获取到数据分析,再到数据结构化存储的过程。
1 相关技术
该文涉及的主要技术为网络爬虫技术与python编程语言的应用技术。
1.1 网络爬虫
网络爬虫(又称网页蜘蛛、网络机器人或网页追逐者)是[1]一种能自动采集互联网信息的程序。为了提高效率,节省时间,往往采用爬虫框架来实现抓取。目前爬虫技术已经较为完善,有很多优质的爬虫框架,如基于Java的webmgaic框架、Apache Nutch2框架;基于python的scrapy框架、pySpider框架;基于C语言的DotnetSpider框架、NwebCrawler框架,等等。能够很好地实现分布式,以及多线程的网络数据爬取。
1.2 Python语言
Python是目前较为流行的计算机程序设计语言,是一种面向对象的动态类型语言。基于python的网路爬虫技术十分完备,对于大型的爬取任务,可以分布式、多线程的抓取,对于规模较小的网页爬取,python提供了能够实现http请求的功能模块,如urllib库、resquests库;以及能够解析网页的功能模块,如BeautifulSoup库、lxml库、pyquery库。可以很好地实现静态网页、动态网页,以及多页抓取等数据采集的任务。该文基于resquests库与BeautifulSoup库实现天猫网站的商品信息的采集。
2 爬取天猫商品信息
天猫商品信息的爬取过程可以概括为4个部分,即URL请求、页面数据解析、多页爬取、数据的存储。
2.1 URL请求
如同使用浏览器浏览网页一般,网络爬虫需要通过URL向服务器发送请求。服务器在接收到请求后,传回相应的页面。此次抓取的初始URL是在天猫官网搜索口红后的页面的URL。具体网址如下。
https://list.tmall.com/search_product.htm?q=%BF%DA%BA%EC&type=p
2.2 页面数据解析
Python的requests库可以模拟浏览器过URL发送Http请求,此次爬取任务不需要提取表单,只是信息的获取,采用get函数实现。由于天猫网站具有一定的反扒机制,所以采用了get函数中的headers参数模拟浏览器信息,该参数为字典格式。此次模仿的是Google浏览器,具体参数如下。
{‘User-Agent:Mozilla/5.0(Windows NT 10.0; Win64;x64)AppleWebKit/537.36(KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36}
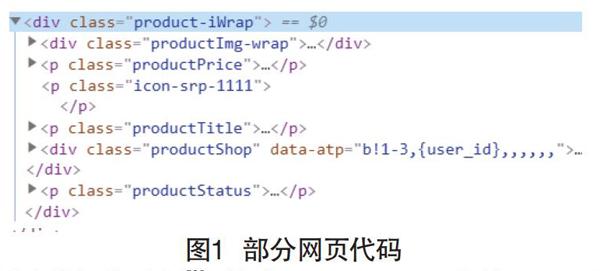
成功获得网页页面信息后,采用BeautifulSoup库从爬取到的网页中解析出此次爬取需要获取的商品名称、价格、店铺名称以及月销等信息,首先通过Google浏览器的开发者工具查看网页结构,我们想要的信息在属性class的值为“product-iWrap”的div标签下,如图1所示。
利用递归的思想[3],结合BeautifulSoup中的find()函数,解析出商品名称、价格、店铺名称以及月销等信息,并以列表的格式存储。
2.3 多页的爬取
通过上述的操作,可以很好地实现目标网页的信息抓取,但我们需要大量抓取数据,所以要对口红商品进行多页爬取。通过对不同页[2]的URL的观察,发现口红商品改变页码以后,网址URL中只有参数s会发生变化,并且s与页码的关系为s=60×页码。依据发现的规律使用递归构造不同页的URL。
2.4 数据的存储
将解析完的数据以csv格式存储[4],使用python的文件处理语句,使其自动实现。以写入的方式创建并打开一个csv文件,制定文件的路径为相对路径,命名为“lipstick.csv”。在数据爬取到以后,使用write()函数,将数据写入到csv文件中,并保存。
3 存储结果展示及结语
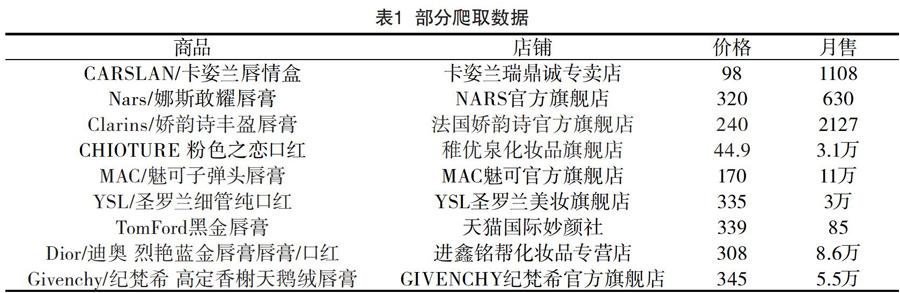
由于得到的数据较大,只对部分数据进行展示,具体情况见表1。
从我们获得的数据来看即使是同一品牌的口红,由于出售店铺、款式、型号等因素的影响,在价格上也会有很大差別。这使得数据具有很大的价值,对数据进行聚类、排序、筛选或者其他算法分析可以挖掘到很多有利的价值为大众购物提供参考。
参考文献
[1] 陈方,谭爱平,成亚玲,等.主题爬虫技术研究综述[J].湖南工业职业技术学院学报,2008(5):13-16.
[2] 杨帆,董俊,唐宏亮,等.基于Python的淘宝评论爬取技术研究[J].中国管理信息化,2019,22(4):162-163.
[3] 廖勇毅,丁怡心.基于Python的股票定向爬虫实现[J].电脑编程技巧与维护,2019(5):45-46.
[4] 裴丽丽.基于Python对豆瓣电影数据爬虫的设计与实现[J].电子技术与软件工程,2019(13):176-177.
