电力监控平台I6000接口的数据处理模型
2019-01-30李斌赵中英王敏
文/李斌 赵中英 王敏
1 相关工作
1.1 研究背景及意义
随着信息化的迅速发展,大数据、云平台在电力领域的广泛应用,电力数据规模越来越庞大,部分数据的价值不高,I6000作为电力领域信息化的业务平台,每天产生大量的数据,如何有效的处理数据,探测其中有效的数据,及时的探测其中有效的数据显得颇为重要,通过一定的数据挖掘和算法对数据进行采集和分析,可以快速检测到其中的隐藏数据和故障数据,有助于保证系统安全稳定的运行,提升运维工作效率。
1.2 算法概述
Mitchell定义机器学习为:对于一个给定任务,通过一个性能参数P来衡量任务的性能高低,一个目标程序可以从实例中或者经验中进行学习,通过学习,这个目标程序对于给定任务的处理效率和性能就会提高。本文以T作为给定的任务,E作为训练样本,性能的度量参数设置为P,经过训练集E的训练以后,采用新的测试集进行测试,观测参数P的变化。结合I6000接口数据的特点,本文采用的是无监督学习法,无监督K-means算法流程为:
给定const值K,从测试集中选择一个random M 值作为聚类中心。对于测试集中的每一个点w(x,y),计算点w到M的距离D(x),公式如下:
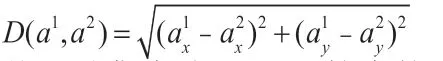
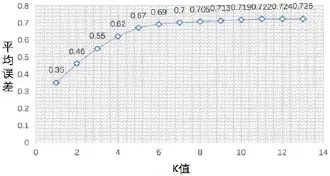
图1:K值的选取
从测试集中选取D(x)较大的点作为新的聚类中心:a.同理,对于测试集中的每个点,计算其和最新聚类中心的距离D(x),并将结果保存,Sum(D(x)=所有保存结果之和。b.重新选择随机值,通过同样的方法计算新的聚类中心。Sum(D(x)*Randomr=r,currSum += D(x),循环遍历直到其currSum>r。得到种子点。
重复重复上述步骤,至数量M=k即可。对测试集中所有测试点与k个中心的距离进行计算。将最小的距离记为Ki。计算所有的检测框后,重新计算每一类的质心。再重复计算,直到聚类中心的变化小于5%,最终输出k个坐标的x和y。
2 数据集选择
本文采用的数据都是I6000接口的测试数据,经过清理、集成、选择、归一化等过程。使用的数据都是测试环境中的真实数据。在数据选择前,对数据进行预处理,删除不符合字段类型等错误数据。量化数据进行归一化处理。公式如下:x*=(x-min)/(max-min)把数据变为(0-1)区间进行分析。
3 实验过程
3.1 K-means算法K值的选取
本文通过测试K值和聚类后平方误差的关系,绘制图表,如图1所示,随着K值的增大,平均误差逐渐趋于平稳,当K值增大到6以后,平均误差基本不再发生变化。
3.2 对数据进行聚类
在选定k值后,对于给定的I6000接口数据进行聚类,聚类完成后,得到对应的数据分析的结果分布,本文实验结果显示,数据呈现具有规律性,不同类型的数据会分布在一定的区域内。不同区域的数据代表不同的数据结果和导向。
4 结语
本文通过I6000测试环境中的实际数据,对数据进行了聚类分析和深度学习,通过测试发现,I6000的接口数据可以通过聚类分析的方法使得结果呈现不同的类型,便于对系统的故障和敏感信息的定位,同时解决了I6000数据延迟问题,本文只需要在I6000接口采集相应的数据进行处理,无需通过延迟或者定期传输。
