字符级的维吾尔语形态协同分析方法
2019-01-29吐尔洪吾司曼杨雅婷艾孜孜吐尔逊程力
吐尔洪·吾司曼 杨雅婷 艾孜孜·吐尔逊 程力,†
1.中国科学院新疆理化技术研究所, 乌鲁木齐 830011; 2.中国科学院大学, 北京 100049; 3.新疆民族语音语言信息处理实验室,乌鲁木齐 830011; 4.和田师范专科学校数学与信息学院, 和田 848000; † 通信作者, E-mail: chengli@ms.xjb.ac.cn
在自然语言处理中, 语法结构的分析离不开对词汇形态学的分析, 句子语义的分析也离不开对词汇语义的分析, 因此形态分析是自然语言处理中的基础性问题, 在机器翻译、信息检索和问答系统等领域具有广泛的应用前景[1]。维吾尔语是一种黏着性语言, 丰富的构形词缀连接词干, 表示数、格、时态等语法功能, 例如, 词干“(夏天)作为名词时, 连接属格缀“得到(夏天的), 连接时位格缀“”得到“(在夏天);(写)作为动词时,连接过去式形动态缀得到(写的), 嵌套连接能源体缀、否定缀、现在-将来时缀及代词缀“, 得到(我不会写)。因此, 维吾尔语单词通过构形方式衍生出新词。
自然语言形态分析研究始于1955年, Harris[2]进行英语词素边界识别方面的研究, 1970年, Harris[3]进行英语词素边界识别方面的研究, 并提出基于前文的词素边界识别思想; 1994年, Merialdo[4]利用隐马尔可夫模型(HMM)进行基于无监督训练的英语词性标注研究。2001年, Goldsmith[5]提出最小描述长度准则(minimum description length)的形态分析方法, 在最小描述长度的启发式算法中, 较短的字符串更可能被选中为词干。2005年, Creutz等[6]提出最大自然估计算法的形态分析工具Morfessor, 并于2007年用最大后验估计算法对它进行改进, 得到在英语、芬兰语、土耳其语和阿拉伯语语料上的准确率分别为66.2%, 66.4%, 70.7%和68.1%[7]。2013年, Ruokolainen等[8]基于条件随机场(CRF)算法, 进行少量标注语料的有监督形态切分研究, 实验结果显示有监督训练的效果明显高于无监督训练。
针对维吾尔语的形态分析研究始于1997年, 玉素甫·艾白都拉等[9]首次进行维吾尔语词法分析的研究。2006年, 阿依克孜·卡德尔等[10]进行维吾尔语名词及词缀进行语法形态学方面的分析。艾山·吾买尔[11]2008年做了有限状态自动机与词典相结合的维吾尔语名词词干切分研究, 测试的准确率为91%; 2009年采用有限状态自动机和最大熵模型(MEM)的混合模型, 来解决词干切分中的歧义问题[12]。2011年, 薛化建等[13]在词缀库的基础上, 提出一种无监督维吾尔语词切分方法, 该方法在测试集上的准确率达到80.4%。
以上研究主要采用基于规则的方法, 这类方法最大的缺点在于收集到的规则无法涵盖所有的语言现象, 积累规则需要较高的语言学方面的知识。因此, 在后来的研究中基于统计的方法成为主流方向。麦热哈巴·艾力等[14]提出维吾尔语词法分析有向图模型, 将有向图的节点作为词干和词缀, 图边表示节点之间的转移概率, 针对维吾尔语的音变现象, 提出词内字符对齐算法的自动还原模型, 并用统计的方法解决词内音变现象, 实验结果显示最终词干提取正确率为94.7%。张海波等[15]将音变还原问题结合在形态切分过程中, 有效地避免了串行模型中音变还原对形态切分的错误传播问题。米尔阿迪力江·麦麦提[16]用Morfessor模型在大规模网络文本上做实验, 词干提取准确率可以达到86.08%。Tursun等[17]结合词典及规则进行形态切分, 得到维吾尔语形态标记马尔科夫模型。哈里旦木·阿布都克里木等[18]采用双向门限递归单元神经网络, 进行维吾尔语的形态切分研究, 通过门限递归单元, 有效地处理长距离依赖问题。Maimaiti等[19]用BILSTM-CRF模型进行词性标注实验, 并在实验中论证特征对标注模型的重要性。
维吾尔语形态分析的目标是词干、词缀切分以及为它们的语法功能进行自动标注, 这是维吾尔语自然语言处理研究的首要任务。一方面, 作为形态复杂的黏着性语言, 维吾尔语具有众多的构形词缀、丰富的构形规则、歧义的边界及词性以及复杂的音变现象等特点, 使维吾尔语形态分析成为具有挑战性的研究。另一方面, 作为语料资源相对缺乏的语言, 没有相应的开源标注语料库, 制约了相关研究的进一步深入。本文在文献[15]的基础上, 提出基于字符层面的协同分析方法, 将形态切分、形态标注及音变还原任务统一定义为字符序列的标注任务, 从而有效地降低数据稀疏和数据量少等问题对形态分析的影响。
1 维吾尔语形态分析
维吾尔语的词缀有构词词缀和构形词缀两种,构词词缀的数量较少, 且构词规则相对固定, 衍生出的新单词一般在词典里可以查到, 因此构词词缀不在本文的研究范围内。构形词缀数量众多, 以不同的组合方式连接到词干, 可以产生多种形态变化,衍生新的单词, 使词汇量剧增, 并在组合过程中发生音变现象。当不同的构形词缀嵌套组合时, 表达的意思更复杂。表 1 给出维吾尔语形态切分的例子。
目前维吾尔语形态分析研究面临的具挑战性的问题如下。
1)维吾尔语词缀众多, 构形方式丰富。维吾尔语是形态复杂的语言, 共有300多个构形词缀, 分为17个大类, 如人称、格、比较级和时态等, 每一类表达的语法意义各不相同, 构形规则也不同。
2)词素有歧义。维吾尔语单词的词性有歧义,这种现象在形容词和副词中较常见, 如单词“”表示“多”的意思, 修饰名词时具有形容词特性, 而修饰动作时具有副词特性。同样, 词缀“当动名词缀时构形的动词具有名词性质, 而当共同态缀时表示动作共同完成。
4)切分有歧义。有时不同的单词经过构形后,派生的单词在书写形式上是一样的, 如“(给)和(去)由状态副动词缀构形后变成此时很难用规则判断其词干。

表1 维吾尔语形态切分例子Table 1 Example of Uyghur morphology
5)音变现象。维吾尔语在构形过程中要遵循语音和谐规则, 当词干与词缀、词缀与词缀相互连接时, 有可能发生脱离、弱化以及增音等音变现象(表 2)。
通过以上分析可以发现, 一个维吾尔语词干以不同的构形方式派生出不同的新单词, 派生过程中人称、数以及时态等语法信息以词缀的形式表达,这种现象导致机器翻译系统中词对齐效率的降低,增加未登录词的数量, 从而影响译文质量[20-21]。在信息检索过程中对内容进行形态切分, 可以压缩倒排表的大小, 并且检索结果可以覆盖拥有相同词干的所有单词, 因此在缩短系统运行时间的同时, 还可以得到较高的查全率[22]。图1为维-汉统计机器翻译中词干切分之前(a)和词干切分之后(b)双语句子的对齐结果, 图1(a)中中文单词“加强”与它对应的维吾尔文单词没有对齐, 而把维吾尔文单词错误地与中文单词“金融业”对齐。词干提取之后解决了图1(a)中的对齐错误, 如图1(b)所示。

表2 维吾尔语音变现象Table 2 Example of phonetic change in Uyghur morphology
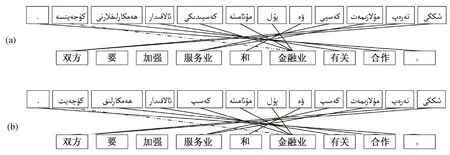
图1 统计机器翻译中的词对齐Fig.1 Word alignment in statistical machine translation
维吾尔语形态分析的目的包括形态切分、形态标注及音变还原, 这是进行句法分析研究的前提,可对有效地辨别短语结构提供帮助。例如, 名词和代词与格词缀组成格短语(kasus phrase, KP), 动词与时态词缀组成时态短语(tense phrase, TP)。图2显示例句(他在困难面前没有害怕。)从词法分析到句法分析的过程: 第1层是原句的分词状态, 第2层是句子中各单词的词素切分状态, 第3层是各词素的词性标注, 第 4 层是其短语结构。
2 形态协同分析方法
2.1 任务定义
假设维吾尔语单词由字符序列c=(c1,c2,c3, …,cn)组成, 其中n为单词的长度。l=(l1,l2,l3, …,ln)表示c的形态特征序列, 其中li表示字符ci的形态特征信息, 包括所在词素的边界信息、词性信息以及所在位置的音变现象信息, 可由li的上下文信息预测得到。因此, 本文将单词的形态分析任务定义为字符序列的标注问题, 即通过观察序列c, 得到其形态特征序列l。
Lafferty等[23]提出将线性链条件随机场(linear chain)应用于标注问题的思路。条件随机场是一种概率无向图模型, 由无向图表示联合概率分布, 当给定随机变量X的条件下, 预测随机变量Y。本文将单词划为若干个字符组成的字符序列, 其条件随机场模型定义为
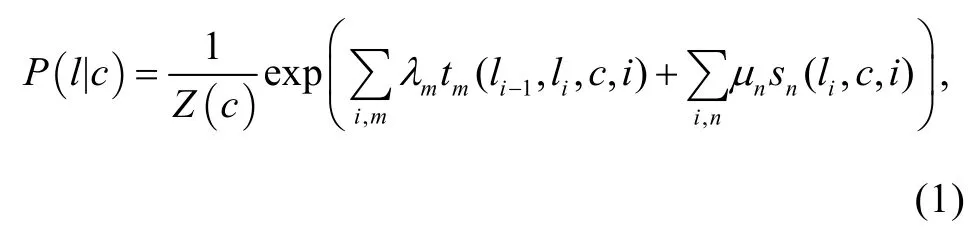
2.2 模型描述
从维吾尔语单词词素边界识别的角度考虑, 可以简单地设置为{B, I}标记。其中, B 代表词素的起始位置, I 代表词素的非起始位置。为了达到维吾尔语形态协同分析的目的, 本文扩充{B, I}标记方式。具体地, 把只有形态切分功能的标记扩充为同时包含形态切分、形态标记以及音变还原功能的标记。
词素切分由{B, I}标记表示。形态标记由词素的词性(POS)表示, 例如, “N”表示名词, “V”表示动词, “CASE”表示格词缀, 等等。音变现象分别由{N, I, R, S}标记表示。N(none)表示没有发生音变现象。I(insert)为增音标记, 表示当前字符在构形过程中被增加的字符。R(remove)为脱落标记, 表示当前和下一个字符之间发生字符脱落的现象。R标记连带一个字符位, 表示被脱落的字符, 如“R表示字符发生脱落现象。S(substitute)为弱化标记, 表示当前字符在组合过程中被弱化。S标记同样连带一个字符位, 表示被弱化的原始字符, 如表示字符被弱化成当前字符。下面以单词(他们没有说)为例, 具体处理流程如下。
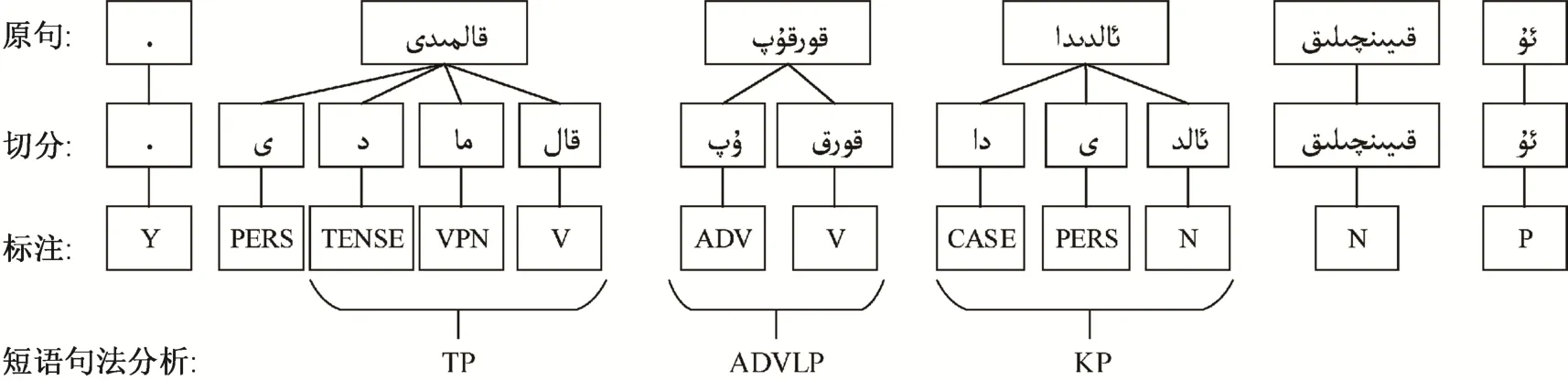
图2 词法和句法分析过程Fig.2 Process of morphological analysis and syntactic parsing
1)语料库中所有单词进行人工切分得到对应的词素序列。单词的词素切分形式为
3)通过字符对齐方法识别词素内的音变现象,得到对应的音变还原标记序列。音变还原过程由式(2)表示, 其中i为原单词c的当前字符索引,j为词素序列m的当前字符索引。
字符对齐形式如图3所示, 各个词素的起始位置分别在1, 4, 6, 8和9位。从图3可以发现, 单词的第2和第7字符分别弱化成字符和得到“S”标记, 第3个字符为增音字符, 得到“I”标记。
4)根据词素的形态标注信息、字母对齐信息以及音变还原信息, 最终得到如表 3 所示的协同标记序列。
2.3 特征选取
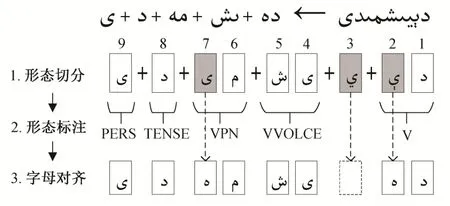
图3 字符对齐示意图Fig.3 Letter alignment in Uyghur wordmorpheme segmentation
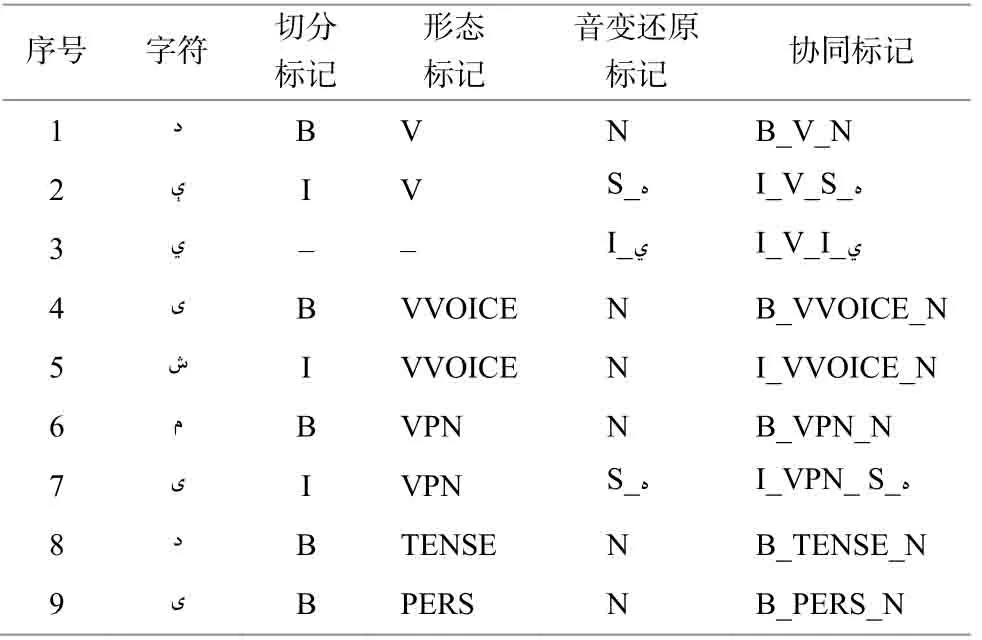
表3 维吾尔语形态标注符合标记Table 3 Compound labels used in Uyghur morpheme segmentation
在训练和解码过程中, 序列标注模型需要加入特征元素, 并且特征的优劣直接影响模型的预测能力。在字符序列中, 上下文关系是最重要的特征信息, 因此本文在上下文中分别取 1 个字符、2 个字符和3个字符作为模型的特征。表 4 给出本文选取的特征模板, 其中i为观察窗口的半径, 并且列举当前字符为单词的第 5 个字符, 观察窗口半径为 4 时的特征例子。
3 实验
3.1 实验数据
本文实验所用语料是人工进行形态标注的 3533条句子, 包含政务新闻、法律法规以及文学类内容,其中的 54039 条维吾尔语单词(词项 12700 条)中有7116 条单词发生音变。表 5 给出语料中各种音变现象的统计数据。从语料中抽取 90%的句子作为训练数据(3180 条句子, 包含 48663 条单词), 其余的 10%作为测试数据(353 条句子, 包含 5376 条单词)。

表4 特征模板Table 4 Feature template
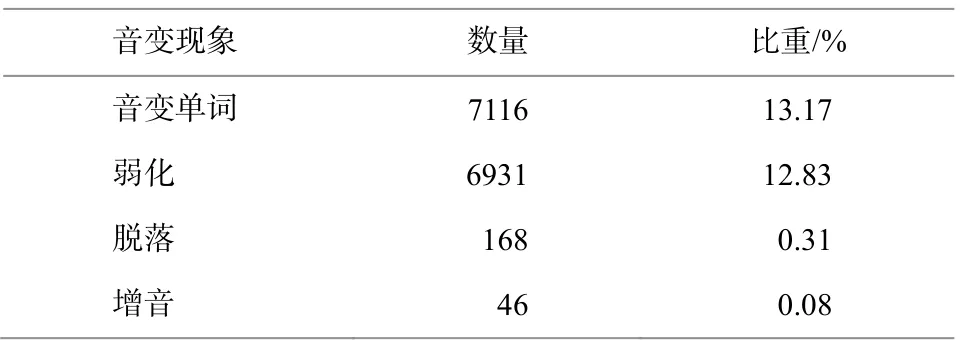
表5 语料库中音变现象的统计情况Table 5 Statistics of phonetic changes in the dataset
3.2 实验结果
本文使用 CRFsuite (http://www.chokkan.org/soft ware/crfsuite/)作为训练和解码工具。为了确定最优特征模板的窗口半径, 在窗口半径为 2~10 的范围内进行9次实验。本实验除使用准确率(Accuracy)外, 还使用词素边界识别率(MBIAccuracy)、词干提取识别率(SSAccuracy, 定义形态切分中得到的第1个词素为该单词的词干)、形态标注准确率(MAAccuracy)以及音变还原准确率(PRAccuracy)等作为评价指标。表6列出各个评价指标的定义, 表 7 给出窗口半径取值不同时的实验结果。
在同样的训练集以及测试集上, 用Morfessor(http://morpho.aalto.fi/projects/morpho/)、HMM (http://www.nltk.org/_modules/nltk/tag/hmm.html)以及最大熵 (MEM, http://homepages.inf.ed.ac.uk/lzhang10/max ent.html)模型分别做3次实验, 表8列出CRF, Morfessor, HMM 及 MEM 模型下的最好实验结果。
3.3 实验分析
3.3.1 协同形态分析实验
从表 7 可以看出, 当特征模板的窗口半径设置为 2 时, 实验结果得分最低。随着窗口半径增大,实验结果得分也明显提高, 当窗口半径设置为5时,实验结果得分最高。当窗口半径超过 5 以后, 实验结果得分几乎持平, 并有轻微的下降。通过对实验数据进行分析, 对该现象的解释如下。
1)过拟合。特征模板的窗口半径超过 5 以后,系统对未登录词的预测能力开始下降, 说明系统中存在过拟合现象, 只能有效地预测训练集中出现的字符序列, 而对训练集中没有出现的字符序列的处理能力下降。
2)兼类词歧义。当兼类词构形时, 词缀作为上下文特征, 在判断词性时发挥重要作用。如果兼类词没有发生构形, 此时没有词缀可以作为其特征信息, 因此系统将该词概率最大的词性作为它的词性返回。例如, 单词(其他, 下次)在训练集中出现69次, 其中作为形容词出现37次, 作为副词出现7次, 作为语气词出现25次, 因此在测试集中作为副词出现时, 模型错误的预测成形容词。
3)切分歧义。当不同的词干构形之后得到相同的单词时, 将出现频率最高的切分形式作为预测值。如 副 动 词的 切 分 形 式 有去)和给), 第一种切分形式在训练集中出现9次,第二种切分形式出现28次, 因此将测试集中出现的所有切分成第二种形式。
4)音变还原歧义。构形过程中发生音变现象的词缀还原时, 还原成同一类词缀的另一种形式。例如, 测试集中单词在事业当中)的正确切分形式为但测试结果中的切分形式为没能正确地还原时位格缀上发生的弱化现象。虽然在训练集中位格缀和发生弱化次数同样为3次, 但是字符发生267次弱化, 明显小于字符弱化的次数(313), 因此模型没能正确地还原这种音变现象。
针对第一种情况, 需要合理设置特种模板的窗口半径。针对其他3种情况, 通过单词间的上下文关系, 可以缓解歧义现象。本文只考虑词内字符间的上下文关系, 如果将单词间的上下文关系作为特征信息参与训练和测试, 可以降低歧义造成的误判率。
3.3.2 对比实验
对比 4 组实验结果(表 8)可以发现, 实验1的结果最好, 实验 2 和 3 的结果明显差于实验 1, 实验 4的结果接近于实验 1。分析原因如下。

表6 评价指标Table 6 Evaluating indicators
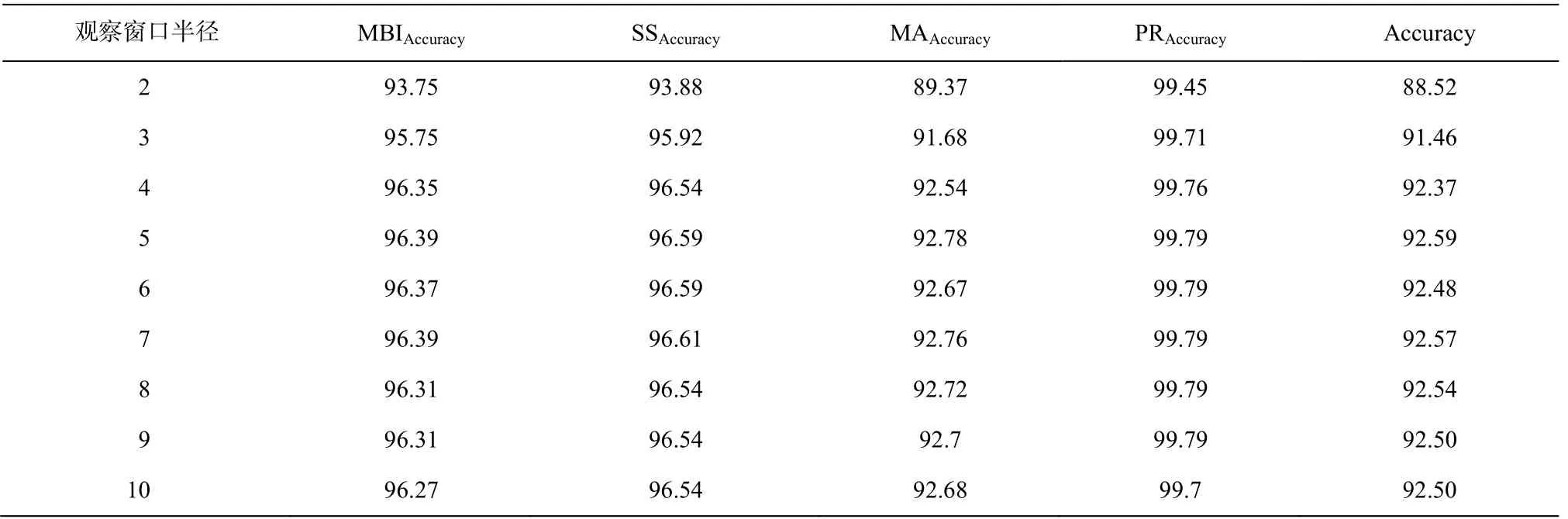
表7 不同观察窗口半径取值情况下的实验结果(%)Table 7 Experimental results based on different half window size (%)

表8 CRF、Morfessor、HMM 和 MEM 模型的结果对比(%)Table 8 Experimental results on CRF, Morfessor, HMM and MEM (%)
1)实验 2 中的Morfessor模型训练时需要大量的语料, 而我们的训练语料的规模不大。实验2的结果中发现过度切分现象, 如词干(职业)被错误地切分成的形式, 是因为在语料库中出现由词根切)构词的不同单词。由 于Morfessor模型不具备标注能力, 因此实验中没有形态标注和音变还原结果。
2)实验 3 中词素切分和词干提取的结果不理想,是因为HMM模型假设当前状态只与前一个状态有关, 因此没有充分利用字符序列中的上下文信息。
3)实验 4 中 MEM 模型采用局部最优化训练模式, 而实验 1 中 CRF 模型采用全局最优的训练模式,因此MEM对训练集中未出现情况的处理能力比CRF 模型差。图 4 给出当观察窗口半径取值不同时,CRF 和 MEM 模型未处理未登录词数量的区别。
4 结论
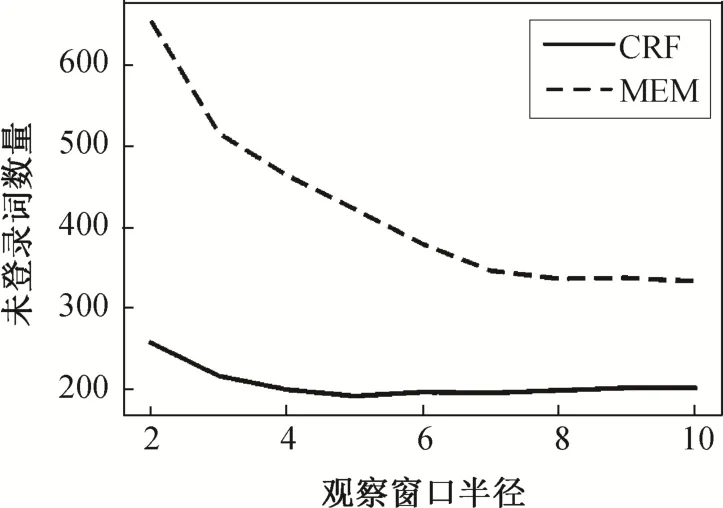
图4 未登录词数Fig.4 Count of unregistered words
本文提出基于字符级别的有监督维吾尔语形态协同分析方法。该方法结合维吾尔语的黏着性特点, 将词素边界识别、形态标注及音变还原等形态分析任务定义为字符序列的标注问题, 采用序列标注方法, 实现用一个模型完成复杂形态分析的任务。实验结果证明, 我们提出的模型在维吾尔语的形态分析任务中得到较好的效果, 并且根据不同的应用场景, 从结果中可以得到词干、词性标注等不同的分析数据。该模型在相似语种之间具有一定的通用性, 因此还可以用于与维吾尔语形态特征相似的哈萨克语、柯尔克孜语等语种的形态分析任务。针对实验过程中发现的问题, 在后续工作中, 我们将以单词间的上下文关系作为特征进行模型优化,从而有效地降低歧义导致的误判率, 进一步提高形态分析的正确率。
