基于Adaboost的发动机故障诊断训练数据影响分析
2019-01-28曹惠玲阚玉祥
曹惠玲,高 升,阚玉祥
(中国民航大学航空工程学院,天津 300300)
数据挖掘作为发动机故障诊断的重要研究手段已相对成熟。在不明确各参数函数关系的情况下,依照数据挖掘所建模型,即可完成发动机的状态监控与故障诊断,受到了很多学者的关注。常见的数据挖掘方法包括人工神经网络、支持向量机、模糊集、遗传规划、免疫机理等。
发动机故障诊断指印图是实际诊断中的重要工具,标识了不同故障对应的发动机主要气路性能参数的小偏差量,如图1所示。其原理是根据以往大量故障现象及故障时发动机性能参数的变化,总结出有规律的典型故障样板,将发动机的具体性能参数变化情况与故障样板对照,用以判定发动机的状态,再利用其他手段进行故障隔离和定位[1]。
航空发动机在一定的飞行条件和工作状态下,都有一组与之相对应的特性参数,如高压转子转速、低压转子转速、排气温度和燃油流量等。同一运行条件下,当发动机出现故障时,各性能参数随之变化。不同故障对应不同的参数偏差量,可作为故障诊断依据[2]。由于指印图中的数据来源于大量实际故障的统计,所以可利用数据挖掘方法,首先还原指印图数据所代表的各类故障,将其作为基础数据来源,以此进行有效扩充,来建立故障诊断模型。

图1 发动机故障诊断指印图Fig.1 Finger-print of aero-engine fault diagnosis
1 Adaboost算法
Adaboost算法是一种组合分类方法[3-5],其核心思想是加大分类错误的样本分布权重,降低分类正确的样本权重,从而得到新的样本分布,在新的样本分布下再次训练得到新的弱分类器。以此类推,得到若干弱分类器,经一定权重的叠加(boost),从而形成强分类器。由于循环训练对样本分布权重不断更新,模型会越来越关注分类错误的样本。只需要调节训练轮数T,要求每轮循环中的分类器精度高于随机猜想即可,而正确率会随着训练轮数T的增加而提高,理论上可以趋近于1。通常情况下,组合分类的效果会比单个分类器的分类效果好,也更适合样本不对称的数据集。发动机故障诊断是一个多分类问题,Adaboost用于多分类问题时,可采用Adaboost.SAMME算法。
1.1 Adaboost算法基础分类器选择
由于Adaboost算法只是一种用来提升分类精度的组合策略,算法本身并不能对样本进行分类,因此,解决分类诊断问题时,还需要选择适合所要解决问题的基础分类器。

图2 发动机故障诊断的多分类Adaboost算法流程Fig.2 Flow chart of multi-classification with combined Adaboost diagram for engine fault diagnosis

1.2 Adaboost算法流程设计
结合Adaboost.SAMME算法,以SVM作为基础弱分类器,设计基于Adaboost的航空发动机故障诊断流程,如图2所示。输入训练样本后,根据交叉验证方法,选定SVM参数范围:设定适当训练循环数M,规则化常数C值,σ初始值σini,σ下限值σmin,以及σ减小步长σstep。采用SAMME算法对分类器权重α(m)进行调整,以适应发动机故障类型的多分类情况;以SVM为基础分类器,以适应航空发动机故障诊断中故障样本数量少、不对称、高维度等特点。
2 基础数据处理
2.1 数据处理原理
在数据挖掘过程中,训练数据的选取对模型的准确度有很大影响。根据小偏差故障数据的特点,不同程度的同类故障数据之间存在比值关系。实际偏差数据与指印图偏差数据比值为1时,表示该故障与指印图中对应故障的类型和程度完全一致;当比值为N时,表示该故障与指印图中对应故障的类型一致[3],但程度不同。
运用指印图进行故障诊断,需考虑如何正确识别不同程度的同类型故障。为将通过指印图所得诊断模型用于实际诊断,应选择有效方法处理指印图中的故障标识数据,以便得到适应范围更广的训练数据。文献[6]中的相关系数法和比值系数法,此基础上增加单位向量法进行数据扩充。在图1所示指印图中,除基本性能参数小偏差外,EGT/FF也可作为诊断指标,需要时可用以扩充数据识别维度。选取PW4000发动机指印图,提取性能参数小偏差,作为模型训练基础数据,如表1所示。
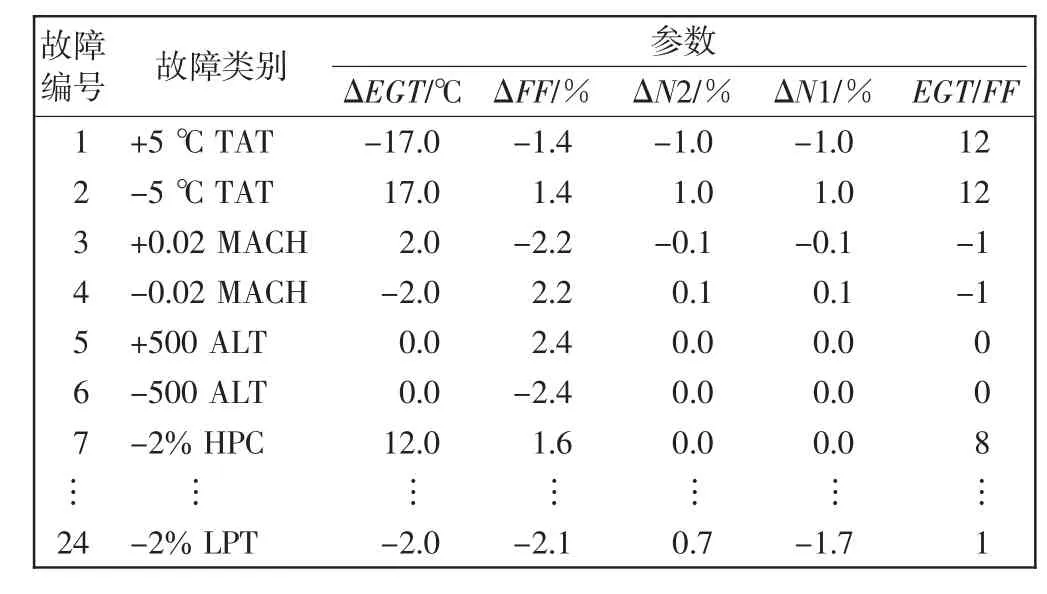
表1 PW4000指印图故障偏差数据Tab.1 Finger-print deviation data for aero-engine fault diagnosis
2.2 数据处理方法
从指印图得到基础数据后,应采用不同数据处理方法,来识别不同程度的同类型故障。比值系数法利用故障偏差的相对比值来表征故障类别。ΔFF通常不为0,故可将指印图各故障偏差数据ΔEGT、ΔN2、ΔN1转换为 ΔEGT/ΔFF、ΔN2/ΔFF、ΔN1/ΔFF。相关系数法是原始故障偏差数据之间某一故障与各故障之间的线性相关系数,将4维表征数据变为24维。经过这样的处理后,能够用新的标识数据代替基础数据,表示出不同程度的同类型故障。新提出的单位向量法是将指印图中各偏差数据进行单位向量化,使各故障向量落于单位向量组成的“球”空间中,从而避免同一故障程度差异的影响,如表2所示。

表2 单位向量法故障标识Tab.2 Failure identification with method of unit vector
2.3 数据噪声的添加
噪声的添加可使诊断模型适应随机偏差的影响,增加模型的鲁棒性。利用指印图故障偏差数据添加噪声进行训练时,存在两种噪声添加思路。
1)在表1所示的原始偏差数据中加入一定程度的随机噪声,然后用比值系数等方法处理,所得数据作为训练和测试样本。诊断时,需将实际参数的偏差数据利用比值方法等进行处理,得到类似表2中的转化数据,再进行诊断。
2)在表2的数据中,直接根据已转化的数据进行噪声添加。此时如果直接引入同一程度的随机误差,显然对各标识数据影响程度不同。因此应添加与自身数值呈一定比例的偏差,来保证噪声数据也呈故障的线性比例。
第1种思路采用比值系数法相除后会将偏差放大,单位向量各故障标识数据之间差异较小。因此,原始数据不宜加入过大噪声,而相关系数维数增加、故障类型增多会使问题复杂化,不适用于故障问题较多的情况。第2种思路可以加入较大的噪声,但应根据具体故障标识数据采用不同程度的噪声添加。
3 诊断模型分析与检验
通过以上准备,确定了训练数据和模型算法,即可建立相应的诊断模型。训练数据准备方法的不同对训练结果会产生较大影响,由于第1种噪声添加思路加入噪声较小,理论上生成的训练数据诊断正确率较高,但不能反映出Adaboost算法的提升效果。而第2种噪声添加思路则通过加入较大噪声来体现Adaboost算法的提升效果,并进行诊断模型的分析。
构造相应方法下的训练集24×200组、测试集24×100组数据进行训练和测试。首先,用交叉验证法分别寻找不同训练数据对应的基础分类器(支持向量机)参数C与σ合适的取值范围。在训练多分类Adaboost诊断模型时,预先设置训练轮数M=50次来观察训练情况,循环中σ的减小步长σstep的设置对最终性能的影响不大,通常为1~3,实验中设置为1。
弱分类器的个数选择会直接影响到训练时间和精度,图3显示了运用Adaboost算法,不同诊断模型的错误率随分类器个数增加的变化情况。可以看出,当分类器个数增多时错误率明显下降最后趋于相对稳定的波动。相关系数法与单位向量法的诊断模型正确率在分类器个数小于10时趋于收敛;而比值系数法模型正确率则在分类器个数将近20时才接近收敛。
同时从图3中可看出,相关系数法和单位向量法的相关诊断模型错误率并没有随着弱分类器个数的增加而进一步减小。分析发现,与比值系数法相比,采用相关系数法和单位向量法准备的一些故障数据标识过于相似(如表3中第7、8、9类故障)、容易混淆。而SAMME算法虽然放宽弱分类器错误率限制,但未关注到弱分类器的质量,不能保证每次被弱分类器正确分类的训练样本权值一定大于其错分到其他任一类别的训练样本权重,从而不能确保最终强分类器正确率的提升[7],即算法中多个弱分类器将某一故障固定地诊断为另一种故障引起的诊断错误。

图3 不同模型诊断错误率与弱分类器个数的关系Fig.3 Test errors of different models with increasing number of weak classifiers
由于Adaboost算法实质是以牺牲时间效率来提高正确率,因此可根据计算时间和诊断准确率综合确定弱分类器的数量,设置比值系数法弱分类器个数为20个,其余3种为15个。各数据准备方法下用多分类Adaboost算法在进行对应次数迭代训练后,模型诊断正确率如表4所示(其中,A、B分别表示在第1种、第2种噪声添加思路下所建的模型,下同)。
通过表4可看出:比值系数法A、B和单位向量法A的正确率较高,优于其余模型;第1种噪声添加方法的正确率高于第2种方法,符合之前的预期。

表3 相关系数法中数值相似的故障标识(7、8、9类故障)Tab.3 Failure identification with similar values of correlation coefficient method(Fault No.7,8,9)

表4 模型训练数据类型及诊断正确率Tab.4 Training data category and diagnosing accuracy
综上可知,初始训练数据对诊断结果影响较大,各种数据准备方法所构建的数据,在反映不同故障特征时有差异。由测试集正确率可知,应优先考虑比值系数法和第1种噪声思路下的单位向量法,其余诊断模型可适当考虑。
4 实例诊断
4.1 PW4000型发动机故障诊断
选取某航空公司3起未造成严重后果、只引起特征参数不正常的故障实例进行诊断分析。通过监控软件观察到发动机参数短时间有较大变化,表明发动机状态不正常,由各参数与基线值的偏差分析,得到相应参数偏差值[8],如表5所示。

表5 实例性能参数小偏差值Tab.5 Performance parameter minor deviation of instances
采用所建诊断模型进行诊断,结果如表6所示。

表6 实例诊断结果Tab.6 Results of case diagnoses
由表6可知,训练数据准备方法不同,则诊断结果有所差异。比值系数法B和单位向量法A诊断全部正确,符合表4中这两种方法正确率优于其他模型的结论。比值系数法A虽然正确率较高,但也出现了错误诊断。其余诊断模型均有一定的误诊,诊断结果可作为参考。综合分析表6各分类模型诊断结果,最有可能的故障类型为7、7、1,根据指印图可知第7类故障为高压压气机组件性能损失,第1种为总温指示偏差。由图4所示,实例1为高压压气机叶片出现损坏,实例2为某2.5级放气活门连接曲柄与连接环出现脱落,实例3为Tt2探头覆盖鸟毛。实例1和实例3诊断结果完全正确,实例2中,2.5级放气活门问题影响高压压气机组件效率,与指印图中故障7有直接联系。实际诊断中需采用进一步手段进行故障隔离。
4.2 其他型号发动机案例诊断
好的诊断效果。由此可知,采用比值系数法和单位向量法可进行相应诊断,但通常情况下,综合多个模型的诊断结果会更加准确。
上述分析与诊断已经验证了以上方法的有效性。应用比值系数法和单位向量法中正确率较高的方法,对应指印图生成训练数据进行建模,用于其他型号发动机的故障诊断,来检验该方法的可推广性。两种不同型号发动机在发生故障时对应气路参数的小偏差值,以及诊断模型判断属于指印图的故障类型与实际故障类型的对比如表7所示。
由表7可知,将指印图的数据进行相关处理,建立诊断模型的方法同样适用于其他机型,能够得到较

图4 故障实例排故检测结果Fig.4 Actual troubleshooting results of fault instances

表7 发动机实际故障案例Tab.7 Practical engine fault cases
5 结语
使用比值系数法、相关系数法和单位向量法对指印图中的故障标识数据进行处理,得到不同的诊断模型训练数据。在Adaboost算法及其改进算法基础上,以支持向量机为基础分类器,建立对应训练数据的故障诊断模型,然后由各模型诊断结果综合判断故障类型,避免单一模型诊断某些故障的不确定性。通过实例检验,证明了该方法对实际故障诊断的有效性。对于如何运用指印图或在故障数据量较少的情况下进行实际故障诊断具有较好的参考意义。
