大数据下模式匹配算法研究*
2019-01-22余飞
余 飞
(安徽电子信息职业技术学院 安徽蚌埠 233030)
随着大数据与网络技术的快速发展,每天所产生的数据信息量呈指数级增长。如何对互联网数据流量进行高效快速的处理,已经成为当今信息安全研究的重要方向。大数据具有4V特性,即体量巨大(volume)、类型繁多(variety)、时效性高(velocity)以及价值高密度低(value)[1],传统的数据处理方法很难应对,大数据检索与快速匹配已经成为很多系统应用需要解决的问题。如防火墙数据过滤、入侵检测系统、天气股票分析与预测等应用,都离不开模式匹配算法。
模式匹配算法是数据检索与快速匹配技术的核心。模式匹配算法有两种分为单模式匹配算法和多模式匹配算法。单模式匹配算法在文本串中只能寻求一个模式串的匹配结果,而多模式匹配算法是一个模式集合即多个模式串在文本串中快速匹配的方法。对单模式匹配算法的研究是多模式匹配算法的基础,而在现实中多模式匹配算法具有更为广泛的应用。例如,在网络海量的数据中检测某些特征值来识别非法信息与网络攻击;应用在生物信息DNA搜索识别中[2],对DNA序列进行大量精确模式搜索,改变了以前DNA序列近似搜索的状况;网站数据的搜索与处理等。
1 模式匹配算法的概念
单模式匹配算法的数学模型可描述为:文本串为T[0,1,2……n-1],长度为n;模式串P[0,1,2……m-1],长度为m。对于给定的文本串T,判断模式串是否在该文本串中出现。如果出现,则称匹配成功;如果没有出现,则称匹配失败。当前主流的单模式匹配算法有BM、BMH等。
多模式匹配算法的数学模型可描述为,文本串为T[0,1,2……n-1],长度为n;模式集合为P{p1,p2,p3,……,pk},长度为k,其中最短的模式串长度为m;P和T的字符均来自字母集∑。多模式匹配算法是指对于给定的文本串T,判断模式集合P中的每个模式串是否在该文本串中出现。如果出现,则称匹配成功;如果没有出现,则称匹配失败。当前主流的多模式匹配算法可分为两种,基于前缀匹配算法AC和基于后缀启发式搜索算法WM。
2 模式匹配算法的的主要种类
2.1 单模式匹配算法(BMH)
BMH(boyer-moore-horspool)算法是基于坏字符后缀的单模式匹配算法,主要利用Badchar函数进行跳转与偏移。具体思想是:模式串P与文本串T进行匹配,首先从右向左比较P[m-1]和T[j+m-1],若相同则继续比较P[m-2]和T[j+m-2],….,一直比较直P[0]与T[j]为止。如果都相同,则匹配成功。如果中间发现P[i]与T[j+i]不相等[3],则分为如下两种情况:
(1)在P[i]与T[j+i]处失配,但T[j+i]…T[j+m-1]与P[i]…P[m-1]都是匹配的,这些相同的字符串,标记为u。在u中,最后一个字符T[j+m-1],标记为d。如果在模式串P中,除P[m-1]外,还能找到P[k]处值为d。则模式串P向右滑动,让T[j+m-1]与P[k]对齐,并从模式串末端开始,从右向左继续比较[3]。
(2)如果在模式串P中,除P[m-1]外,没有找到d。则模式串P直接向右滑动m位,并从模式串末端开始,从右向左开始新的一轮比较,如图1所示。

图1 BMH算法找坏字符的偏移情况
2.2 多模式匹配算法(AC)
2.2.1 算法原理分析 AC(aho cora sick)算法是一种基于前缀匹配的多模式匹配算法。它构造有限状态自动机,基于自动机扫描文本串中的每一个字符,根据自动机进行状态跳转和状态判断,从而进行模式匹配。AC算法需要goto表、fail表、output表来完成,3个表的功能如下:
(1)goto表中的内容是由P中的所有模式串构造的有穷状态自动机。构造AC算法中的Tree状结构,通过goto函数读入P中的每一个模式串,创建该模式的分支,并把该分支添加进Tree状结构中,如果该模式的分支在Tree状结构之前已有重复的部分,则利用该重复的部分进行创建,在最后一个字符标记为终止状态。
(2)fail表记录当状态自动机处的某个状态,即输入模式串,读入文本串T的字符按照状态机进行状态跳转,当状态失效即匹配失败时,fail函数则根据有穷状态自动机计算其跳转状态。跳转深度最大的状态就是fail表中对应的那个状态。
(3)每一个状态都有一个output表。output表记录的是状态达到终止状态时,模式串的集合。当构造goto表Tree状结构时,每添加一个模式分支,最后一个字符状态都会加上一个output表,在构造fail表的过程中,所有状态最后无论是失效、跳转还是匹配等,其终止状态都会被写入output表。
2.2.2 原理示例 以模式集合P={ma,sma,mis,maps}为例构建有限状态自动机,goto表构建的Tree状结构如图2所示。
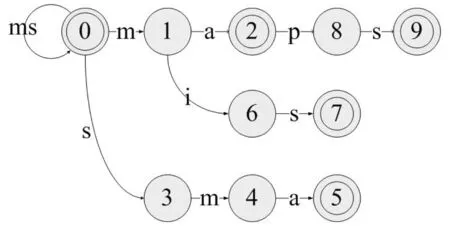
图2 有限状态自动机示例
AC算法的扫描过程为:输入模式P,读入文本T的每一个字符,依据状态机进行跳转,当失效时,则依照fail表进行跳转,按照找各种方法对字符进行扫描,最后根据output表将匹配的模式进行输出。fail表如表1所示,output表如表2所示。

表1 fail表

表2 output表
2.2.3 优缺点分析 AC算法最大的优点是效率高,利用有穷状态自动机可以从一个状态直接跳转到另一个状态,实现跳跃式匹配。而文本串T的长度与复杂性对算法的匹配效率基本上没有影响,算法设计完善运行稳定。长度为L的文本串,算法的初始化时间复杂度为O(|P|),匹配时间复杂度为O(L)。AC算法的缺点是需要占用大量的存储空间来构建状态机,若模式集合的大小为∏,自动机所造成的空间复杂度为O(|∏||P|),模式P越大,该算法占用的内存空间呈指数级上升,将会形成内存墙[4]的问题,很难适应大规模的模式集合。当前AC算法的改进大多数都是在专有硬件上提出优化[5]。
2.3 经典算法(WM)
2.3.1 算法原理分析 WM(Wu Manber)算法是一种基于后缀扫描的多模式匹配算法。该算法使用坏字符的匹配思想,以模式集合P中最短模式串的长度m做为扫描窗口的大小,进行最大距离的跳转。扫描窗口的数据结构由Hash表、Shift表、Prefix表构成,这三个表是由模式集合的每一个模式截取其前m个字符串来构造的,构造规则(如图3所示)如下:
(1)Hash表。模式集合的每一个模式截取其前m个字符的最后长度为B的字符块,计算Hash值,形成Hash表的每一项里是该Hash值的模式链接成的模式链表[6]。
(2)Shift表。主要用于计算和记录当字符不匹配时跳转的距离。利用模式集合中所有模式串的前m个字符来构建Shift表,在选取B时通常选择2或者3。在构建Shift表的过程中,若字符块L在模式集合的模式串中,则选择L在模式集合的最靠右的位置;若L没有出现在模式集合中,则Shift[L]=m-B+1[7]。
(3)Prefix表。当模式集合较大时,Hash计算容易产生冲突,Prefix表记录模式前几个字符的Hash值,能避免相同后缀Hash值的集合过大,从而提高扫描效率。
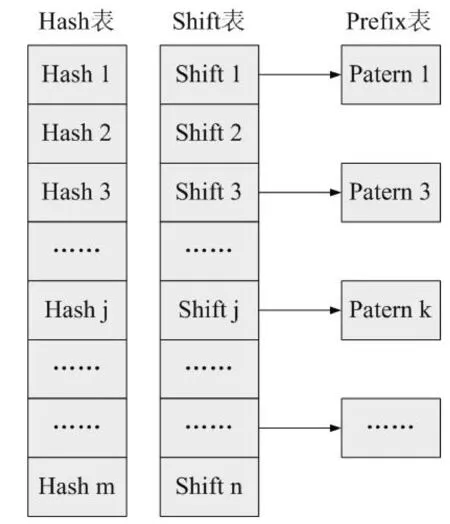
图3 WM算法三个表的数据结构
算法过程为:以模式集合中模式最短长度m计算和设定扫描窗口,计算后缀字符B的Hash值h,并在Hash表中查找h,若找到则查看Shift表,若没有找到,则跳转m-B+1个字符。如果跳转距离为0,则计算前缀的Hash值,找到Prefix表相应的值,再进行扫描来判断模式是否命中。如果跳转距离为正数,则按照这个数值进行跳转。
2.3.2 优缺点分析 WM算法主要是基于Hash值寻找不能匹配的坏字符块进行跳跃匹配,提高算法效率。匹配成功时,时间复杂度为O(m),扫描过程的时间复杂度为O(BN/m)[7]。不同于AC算法,WM算法空间使用率较低,匹配的模式数量与存储空间线性增长,内存占用很小,扫描快速稳定,非常适合大规模数据的处理。但当有很多短模式在模式集合中时,跳转效率将会明显降低,因此使用该算法要注意其模式集合中较短模式的数量。
3 结语
文章探讨了大数据下用于互联网数据流量处理的数据检索与快速匹配技术,研究了该技术的核心算法—模式匹配算法。该算法分为单模式匹配算法和多模式匹配算法,单模式匹配经典算法BMH通过Badchar函数进行跳跃式匹配;多模式匹配算法能够对一个模式集合的多个模式同时进行匹配,具有很强的实用价值,经典算法有AC和WM算法。AC算法构造的有穷状态自动机较为消耗内存,适合用于模式较少的情况;WM算法占用内存较少,适合于短模式较少的大数据流量的处理。
