基于矩阵分析的语义化web智能检索平台设计与研究*
2019-01-22黄珍蔡亮
黄 珍 蔡 亮
(兰州文理学院数字媒体学院 甘肃兰州 730000)
随着互联网技术的发展,网络信息总量在不断增加。信息数据的增加使可以开发的资源变得更多,越来越多的人能够利用互联网做信息的共享、利用和交流,不断刷新自己的认知,创新价值。现在,人人基本都会利用检索技术查找信息资源,这种方式也使人们的学习生活变得更加容易。目前,各领域学者都在致力于研究如何在互联网环境中快速简单地提取出有价值的信息。网络的表现形式为信息化形式,计算机自身是不能理解和处理网络信息的,所以在建立信息格式时存在异构,而网络语义具有多重性,在检索、抽取、表达等方面都存在困难,目前主要的检索技术还是利用关键字检索,应用数学算法实现搜索[1]。如何解决检索过程的语义问题是当前研究的重点。在检索时加入语义的概念不仅可以实现网络信息的预处理,而且能够有效提高交所效率,真正意义的实现智能化检索。
Web网络可以将人们输入的智能信息以一种特定的格式显示出来,所以人们也称web网络是超媒体数字资源平台,web网络会在上面显示工作序列。语义化web智能检索平台是web网络平台的一项延伸,在语义化web网络中信息拥有明确的格式,人们在日常生活中说话会有一定的语法,但是机器并不具有人的思想观念,所以必须通过智能化的手段将更复杂的语义转给机器[2]。
基于矩阵分析技术设计并研究了一种新的语义化web智能检索平台,分析了平台的基本构造,对平台的软件工作技术进行了深入具体的剖析。文章研究的web智能检索平台是一种针对整个互联网的检索平台,换言之,是一个全球性平台,拥有全球性的数据库,能够精准详细地对信息进行解释和处理,对于以后的检索发展有重要的指导意义[3]。
1 基于矩阵分析的语义化web智能检索平台框架设计
在矩阵分析技术中,所有的信息都拥有独立自主的组织方式和存储方式,信息检索实际上并不只是单单地信息检索,而是包含信息存储和信息检索。所以在设计智能检索平台时也要分两方面设计[4],所设计的基于矩阵分析的语义化web智能检索平台框架如下图1所示。
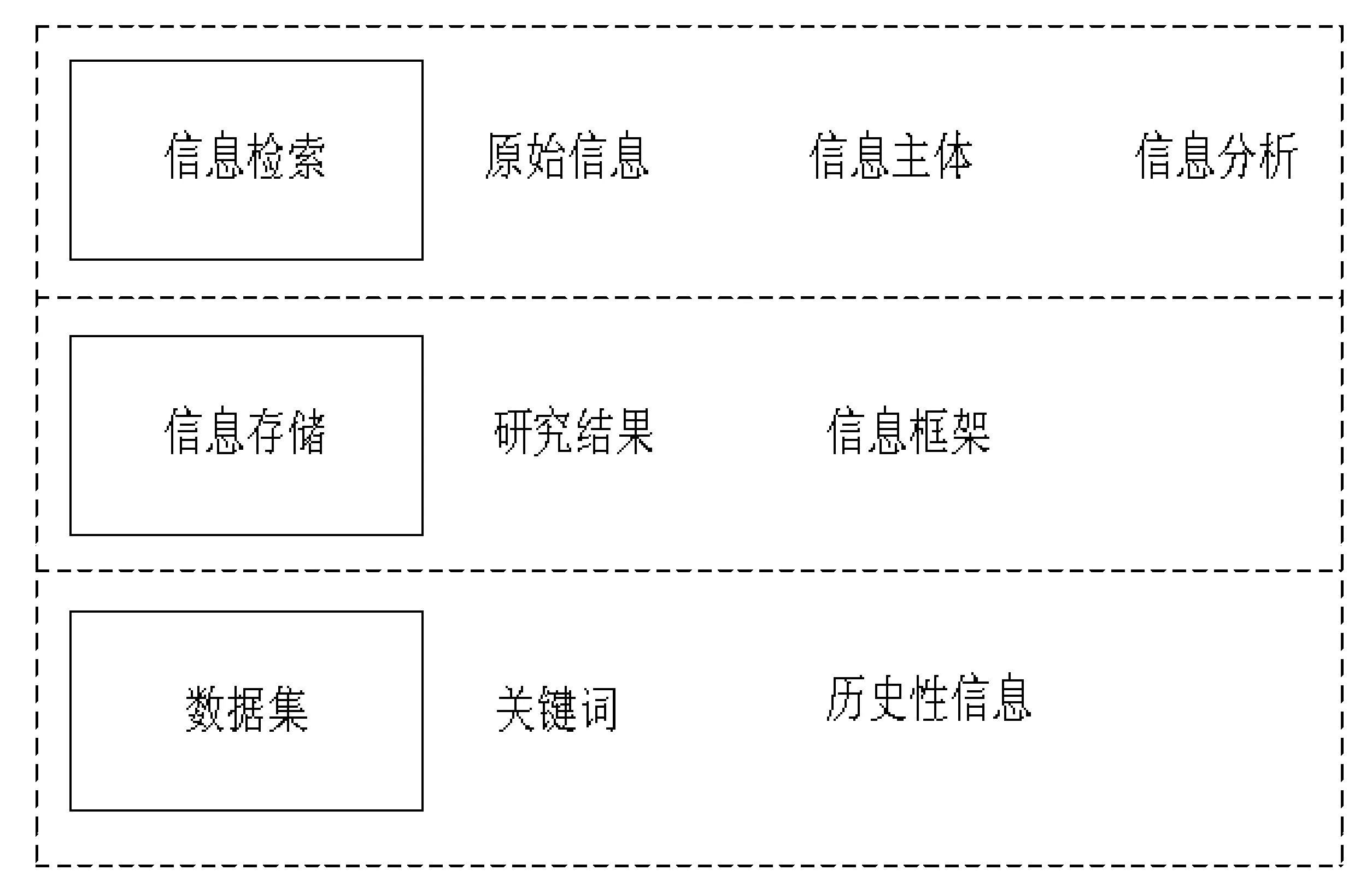
图1 基于矩阵分析的语义化web智能检索平台框架
由图1可知,信息存储需要利用多方面的手段去搜索信息,在收集到的信息中进行特征分析,根据一定的形式或者规则对信息进行存储,而信息查找是信息存储的逆过程,在存储信息以后根据一定的规则整理信息,在数据库中确定用户需要的信息。
矩阵分析具有极高的自主性,可以快速准确地对各个标引程序包含的内容作分析,然后进行精确提炼,概括出一类信息表达的主旨概念,最后与检索关键字对比[5]。
把信息检索过程解剖开,可以发现这个过程是一个匹配的过程,是用户将自己的需求与信息的存储匹配到一起的过程。如果二者不存在共性,则代表检索不成功,不能匹配,存储的信息就不再具有意义。
智能检索平台具有不同的等级标准,可以划分成如下几类:①按检索对象可分为文本检索和图像检索[6]。②按匹配方式可分为模糊检索和精确检索。③按检索方法可分为逻辑检索和嵌套检索。
检索本质是一种串字符的匹配手段,计算机自身不具有转换功能,如用户输入“study”这个单词,计算机只能对应的检索出英文结果,不能找到中文“学习”这个词对应的解释词条。而引入矩阵分析的web智能检索平台能够更加精准地理解出用户想要表达的信息,对检索方案做出有效的改善[7]。
2 基于矩阵分析的语义化web智能检索模型
每一个信息检索系统都是利用算法模型来实现匹配的,在合理查询信息的基础上,计算相似度,按照信息排列相关的框架和算法。智能检索模型是智能检索平台的一项核心内容,在信息数据中寻找关键词,引用不同的关键词对信息做出区分[8]。在资源空间和信息空间中进行匹配存在很大的不确定性,所以需要源源不断的信息资源投入,这是一个摸索过程,在摸索中寻求最精的解决方案。
基于矩阵分析的语义化web智能检索平台包括四元内容:①寻求数据与数据之间的逻辑关系,画出逻辑关系视图;②寻找用户信息与信息之间的关系,建立查找集合和任务列表;④通过数学函数将用户信息和计算机数据匹配出来,找出一个权重值;④构建数据框架,分析数据与数据之间的关系,把所有数据和信息统合到一个框架中,形成语义化web智能检索平台模型[9],具体如图2所示。

图2 基于矩阵分析的语义化web智能检索平台
根据相关度判别各种方法,建立数学模型,由于判别方法的不同,所信息检索模型也不同,包括逻辑模型、空间向量模型和统计模型[10]。这三种模型都是经典模型的延展模型,在检索时离不开关键词。在文档数据中,存在一些简单名词,关键词不能离开数据库中的文档数据。需要特别指出的是,用户绝大多数搜索的关键词都是名词,相对于副词和其他类连接词而言,名词的语义更加容易确定和识别[11]。当然并非所有的关键词都可以与文档中的词对应,需要在一系列关键词中找出一个权重值,根据关键词的重要性来进行搜索[12]。
(1)布尔检索模型。布尔检索逻辑模型是最简单的检索模型,在布尔逻辑中向用户提出问题,选择一组有效的指引词,按照布尔逻辑划分,在数据库中搜索,每个提问都会得到一个对应的逻辑匹配值。在布尔逻辑检索模型中用户需要一个简单的框架,在框架中罗列出各个提问的优点,可以完成快速检索,检索的结果也十分丰富。但是布尔检索模型的检索策略过于僵硬,只局限在关键词的检索,对于同义词、近义词和模糊性语句,布尔检索模型的检索效果往往不尽人意[13]。
(2)向量空间模型。也可以称其为代数模型,具有很高的创造性,能够精准地揭示出文档与数据之间的关系,但是复杂度和要求都要高于其它模型。向量空间模型包括属性向量、数据向量和提问向量,在空间正产生不同的权重值,利用权重值决定检索文献之间的相关度。通常相关度越大,文档数据与检索数据的匹配能力越强。
向量空间模型引用最多的函数就是余弦函数,在计算出各维空间中的文档数量和提问数量中测量余弦夹角,当提问向量和搜索向量余弦夹角一致时,则代表二者相关性最强[14]。向量空间模型拥有自己独立的排序系统,在检索后把根据相关度排列出来,相关系数越大,证明二者接近。
(3)概率检索模型。基于概率排序原理排列文档之间的关系。提问和数据不仅存在某种关系,而且存在某种概率上的联系,所以判断二者概率关系也能很容易地确定出检索结果是否有效。概率模型不需要寻找一个特定函数,只要找出相关度即可[15]。
随着信息技术的发展,各种各样新的模型被不断提出,概率推理检索模型具有一定的代表性。在一个概率推理模型中存在大量节点,包括文档节点、数据节点、信息管理节点,能够针对抽象文本、实体文本和特征文本进行描述[16]。在查询时,用户只要查询某一节点即可。概率推理可以借助概率推理理论分析网络节点之间的相关性,这种方式的理论基础较为坚实。
上述三种模型为经典模型的延伸模型,目前也有一些模型是上述三种模型的延伸模型,检索质量更好,检索效率更高。
3 基于矩阵分析的语义化web智能检索平台工作结构
语义web可以与现有的所有网络平台实现无缝对接,应用服务能力极强。传统的网络只能根据现有的要求去连接,但是在web语义平台中,就能够将不同的域一次连接到一起[17]。
在矩阵分析的基础上研发的web智能检索平台工作结构如图3所示。

图3 基于矩阵分析的语义化web智能检索平台工作结构
由图3可以看出,一个智能检索平台中包含多个层次:URI(统一字符编码)、XML、本体、逻辑、证明、信任[18],具体如下:
(1)统一字符编码层是web智能检索平台的编码基础层,能够将跨地区的字符编码统一成为一个标准格式。在统一编码层中用于标准的编码字符集,即国际通用字符集,当所有的信息资源精确成一个字符集后,精确检索信息工作就会变得更加容易[19]。
(2)第二层为NS层,是基础层的进一步延展层,能够对信息资源进行基础的编程,分析检索词的语法结构。NS可以按照结构、内容和数据将标记的语言分离,同时允许用户做自行标记,记录发布的信息。NS层对文档类型有一定的定义,可以通过标签约束关键词与关键词之间的结构[20]。文档机制通常可以从语法上表示数据内容和结构,在格式化语言中表现信息资源。数据结构和内容的分离处理使计算机在理解结构化语义和非结构化语义上面更加容易。
(3)第三层是资源描述层,可以根据提供的语义模型描述资源,为资源描述提供一种有效的解决方式。资源描述层自身对于数据没有特殊的规定,但是在描述时,需要利用一个固定的体系。资源描述层具有很强的开放性,利用机器描述数字语言[21]。
(4)第四层是检索扩展层,可以分析各个资源之间的关系,展示资源与资源之间的关系,挖掘资源的进一步含义,信息按照内容和结构分离,这种分离方式是一种完全意义的形式化分离,对计算机的数据理解能力有很高的要求。
(5)第五层是逻辑层,不仅能够推断规则,同时也能提供智能化服务[22]。
(6)第六层为证明层,根据各项函数以及数据与数据之间的关系,证明逻辑层的检索结果是否正确。
(7)第七层为信任层。Web智能化检索平台必须要有相关的认证理论和信任机制,根据这些信任机制确保建立的语义web是安全且有效的。用户在网络中不仅要建立合作的关系,还会有适当的交易,所以该检索平台必须是安全可靠的,只有这样才能真正意义上的实现广泛使用。
5 实验研究
为了检测文章设计的基于矩阵分析的语义化web智能检索平台的实际检索效果,与传统检索平台进行了对比,设计了对比实验。
5.1 实验参数
实验参数如表1所示。

表1 实验参数
5.2 实验过程
根据设定的参数进行实验,选用传统检索平台和文章研究的智能化检索平台同时检索几个关键词,对比检索时间和检索内容的相关度,分析两种平台的实际工作效果。
5.3 实验结果与分析
(1)检索时间。观察图4可知,在搜索同一内容时,传统平台消耗的时间要多与文章研究的智能检索平台。如检索内容为2kb时,传统检索平台花费的时间为1.1μs,而文章研究的智能化检索平台花费的时间为0.21μs。

图4 检索时间实验结果
(2)检索相关度实验结果。由图5可知,智能化检索平台相对于传统平台检索到的内容与关键词的相关度更高。如当检索内容为20kb时,传统系统检索到的结果与关键词相关度为5%,文章系统检索到的结果与关键词相关度为16%。

图5 检索相关度实验结果
5.4 实验结论
由实验结果可知,传统的检索平台和文章的检索平台都可以根据关键词和输入的信息进行检索工作,但是在检索同一类型的信息时,文章研究的智能检索平台检索耗费时间要远远少于传统检索平台。而且在短时间内文章研究的智能检索平台可以检索到大量相关性内容,但是传统的检索平台检索的内容和关键词相关度相差很大。
综上所述,基于矩阵分析的语义化web智能检索平台检索的能力要远远好于传统的检索平台,消耗的成本更低,给用户带来的搜索体验更好,更加值得推广和使用。
6 结束语
矩阵分析是一种有效的计算机智能技术,可以赋予计算机人工性思维,在各个领域都有广泛的应用。利用矩阵分析技术设计了一款语义化web智能检索平台,该款平台将最先进的智能技术引入其中,在布尔检索模型、向量空间模型和逻辑模型三种模型上进行延展,通过统一字符编码层、NS层、资源描述层、检索扩展层、逻辑层、证明层和信任层来完成检索工作。不仅能够有效提高检索质量,同时也能提高检索速度,广泛适用于各种网络检索。文章研究的智能化检索平台缺少一定的实践,在未来的使用中可能会出现一些未知性的问题,有待进一步验证。
