基于CNN-NSVM的入侵检测模型
2019-01-18王佳林童恩栋牛温佳刘吉强
王佳林 童恩栋 牛温佳 刘吉强 赵 迪
北京交通大学智能交通数据安全与隐私保护技术北京市重点实验室 北京 100044
引言
随着互联网用户持续呈指数形式增长,网络空间的保护也在不断改善。但与此同时,攻击者的攻击频率也在不断增长。根据国家互联网应急中心[1]统计,仅在2017年7月,我国就发生了近3000起网络漏洞攻击事件,严重威胁了人民的信息安全,网络空间安全的防护迫在眉睫。目前网络安全防御通常是利用放置在网关处的防火墙来检测入侵活动。为了动态监视入侵活动,IDS(Intrusion Detection System, 入侵检测系统)被用作第二道防线,它可以主动监视计算机中的网络日志以及文件系统等,通过分析网络流量中的正常或异常行为,可以检测出未知的或新的攻击[2]。IDS可分为HIDS(Host-based Intrusion Detection System,基于主机的入侵检测系统)以及NIDS(Network-based Intrusion Detection System)。HIDS使用由单个计算机系统收集的信息,而NIDS收集原始网络数据包作为网络数据源并分析入侵标志[3]。
目前实现IDS的方法主要包括:统计分析方法,模式匹配方法,基于数据挖掘的异常检测方法,机器学习、深度学习方法等。Tian等人[4]提出了一种基于误用检测与异常检测相结合的IDS模型。在该模型中,误用检测基于模式匹配,异常检测基于统计分析。该方法降低了假阴性率和假阳性率,提高了IDS的准确性。然而,使用统计分析技术需要建立一个区分异常事件的阈值,如果设置不当,将导致大量误报和漏报,并且在模式匹配技术中,会忽略没有规则描述的攻击。Zhang等人[5]提出了两种基于数据挖掘的改进算法,分别为INFLOF(Influenced Local Outlier Factor,基于对称邻居关系的离群因子)算法和COF(Connectivity based Outlier Factor,基于连接的离群系数) 算法。该方法可以解决由密度簇引起的边缘误判问题,但在参数选择上存在一定的困难。虽然LOF(Local Outlier Factor,局部异常因子)算法可以通过观察不同的k值,然后取最大的离群值来解决这个问题,但是仍然需要确定参数的边界。
为了解决上述问题,一些浅层的分类器被应用在了入侵检测领域,其中SVM(Support Vector Machine,支持向量机)基于统计学习方法,相比传统分类方法,SVM对小样本数据、高维数据展现出了良好的效果。Guang[6]等人为了提高复杂非线性系统中SVM的检测能力,提出了一种基于小波核最小二乘的入侵检测方法。然而,该算法的训练和测试时间相对较长。Pervez[7]等人为了改进基于SVM的入侵检测系统,提出了一种基于遗传算法的入侵检测算法,其选择了SVM的最优特征子集,但没有考虑SVM的错误率。为了克服浅层学习的问题,一些研究者已经证明,分层的深度学习算法和浅层分类器进行结合能够更好地对网络数据进行学习以及分类[8]。然而这样的方法在入侵检测领域仍然存在一定的局限性。文章[9]使用非对称的栈式自编码器和随机森林相结合进行入侵检测,使用KDD99数据集进行实验,模型在整体性能上表现良好,但是在数据集中小样本的检测准确率较低。并且在自编码器中由于相邻层之间的完全连接单元,还有贪婪式的预训练使得模型具有大量的训练参数。
鉴于上述原因,开发了一种新的基于CNN-NSVM(Convolutional Neural Network-support Vector Machine,卷积神经网络-多类支持向量机分类器)的方法来提高入侵检测的性能。我们考虑了数据集中存在数量较少的小样本数据,因此改进了少数类合成算法对数据进行过采样操作,解决了数据中存在的不平衡现象。利用CNN(Convolutional Neural Network,卷积神经网络)对数据集进行特征提取,通过稀疏连接和共享权重的方式减少模型的参数,提高检测效率,并且设计了多类SVM分类器,缩短了训练的时间,提高了入侵检测的准确率以及召回率。
2 基于CNN-NSVM的入侵检测方法
CNN可以有效地学习特征,通常被用来对图像进行处理,但同样可以用来进行数据流量检测。SVM[3]用于解决小样本和非线性问题,解决了维度灾难、过拟合等常见问题,是当前机器学习的重要方法。通过结合CNN与SVM,我们提出了CNN-NSVM模型。如图1所示,CNN-NSVM主要包括3部分:1)预处理阶段;2)CNN特征提取阶段;3)多类SVM分类阶段。
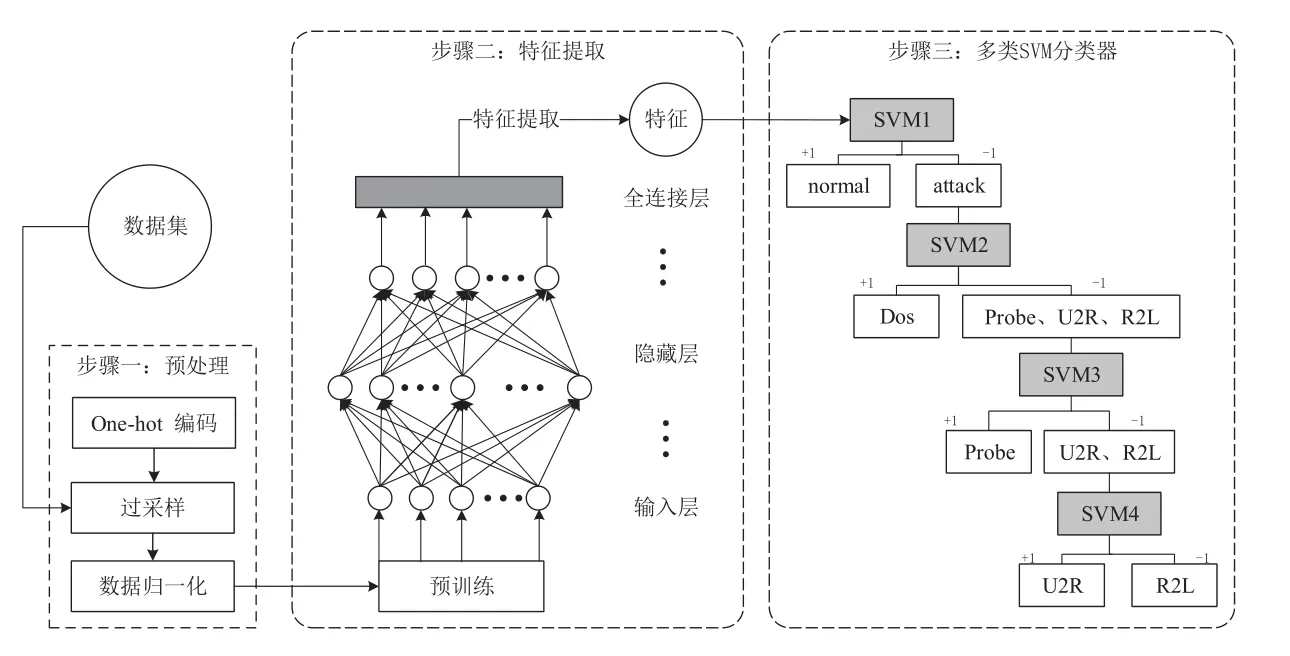
图1 CNN-NSVM整体架构
2.1 预处理
2.1.1 稀疏特征合并
在数据特征中会存在一些特征值v对应的标签y是相同的,那么这些v之间是没有意义的,我们通常将他们进行合并,这可以降低数据的计算成本,提高数据分类的准确性,同时减少数据的稀疏度。
2.1.2 特征编码
基于神经网络的训练需要使用到数值型的特征。因此在预处理阶段需要把非数值型的特征转换为数值型的特征。本文使用One-hot编码将字符型数据映射为数值形式。
2.1.3 改进的少数类合成算法
在网络流量中,大多数是合法的数据流量,只有少量数据流量是非法的,但往往是这些占少量的数据流量危害更大。提高小样本的检测率,对提高整体入侵检测技术有重要意义。过采样技术可以解决数据集中各类数据的不平衡问题,Chawla等人[10]首次提出了过采样技术少数类合成算法,但是这种方法在过采样操作时存在一定的盲目性,没有考虑到小样本数据的分布问题,容易使数据边缘化问题恶化,使得数据在过采样之后的检测率不增反减。因此针对这个问题我们对少数类合成算法进行改进。
在训练集S中,xi是数据集中的少数样本。计算出与xi相似的k近邻半径内数据集Pi。我们计算k近邻时采用欧氏距离r,计算公式如下所示。
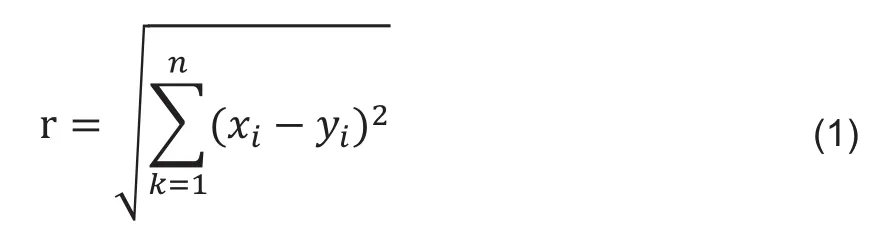
统计Pi中多数类样本的个数xd,计算xd在Pi中的比例k,根据过采样数量的大小设定阀值t,如果0<k<t,则从Pi中随机选择一个样本xaq,进行样本的人工合成;如果t<k<1,则不进行数据合成。具体的数学表达式如式(2)所示。

其中,rand(0,1)表示随机数字在0到1之间选择。然后根据所需的过采样集的数量重复过采样操作,并将新的合成的少量样本添加到初始训练样本中。从而增加样本数量,降低数据集中的不平衡,并获得新的训练样本。改进的少数类合成算法小样本增量过程如下所示。
输入:小样本数据集T;多数类样本数据集M;采样率N%;采样阀值t;
输出:(N/100)*T新的合成少数类样本。
对于每一个样本 xi,xi∈T;
在T找到xi的k近邻半径内Pj,j∈(1…k),T,M∈Pj;
k=M/Pj;
如果 t<k<1;
对xi不处理;
否则,如果 0<k<t;
从k个近邻中随机的选择一个样本xaq,在0到1之间随机的选择一个随机数,从而合成一个新的样本fiq。
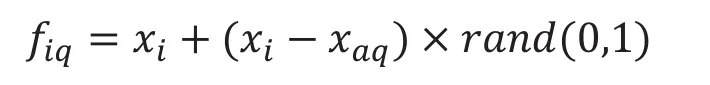
对步骤二重复进行N次,得到新的样本数据集。
2.1.4 归一化
数据集中存在一些离散或连续的数值,它们的范围不同,使得数据在各维度之间不存在可比性,规范化方法使用以下方法映射[0,1]之间的数字属性。
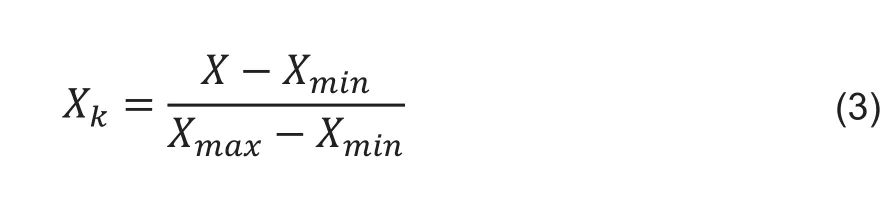
其中,X是数据中某一维度的值,Xmin是该维度的最小值,Xmax是该维度的最大值,Xk是最后得到的归一化之后的数据。
2.2 特征提取
我们使用CNN对数据流量进行特征提取,将数据流量重新整理成数据矩阵,矩阵中的每一个值都代表一个像素点,通过卷积、池化的不断操作,将数据中的特征进行学习,并且保存下来。在CNN-NSVM模型中,我们使用3×3的卷积核将预处理数据输入到输入层,保存在最后一个全连接层中提取的特征。模型中使用的CNN结构如表1所示。
2.3 多类SVM分类
SVM是一种高效的两分类机器学习算法,但大多数分类案例都是多分类的。在本文中,提取的特征被输入到基于二叉树构造的多类SVM分类器中。其中的核函数是高斯核函数,核函数中的参数σ=0.0001,惩罚因子C=1000,实验经过五折交叉验证的结果来调节参数获取最高的分类准确率。多类SVM的分类步骤如下。
1)将得到的特征输入到SVM1中,SVM1首先判断数据是正常类型还是攻击类型,如果攻击类型,则将攻击类型的数据输入到SVM2中,否则标记normal标签。
2)SVM2判断得到的数据是Dos还是Probe、U2R、R2L中的某个类型,如果是Probe、U2R、R2L中的某个类型,则将这类数据输入到SVM3中,否则的话标记Dos标签。
3)SVM3判断得到的数据是Probe还是U2R和R2L中的某个攻击类型,如果是U2R和R2L中的攻击类型,则将该类数据输入到SVM4中进行分类,否则的话就标记为Probe类型。
4)SVM4判断得到的数据是否是U2R还是R2L,判断结果用于标记数据,最后对所有数据进行分类。
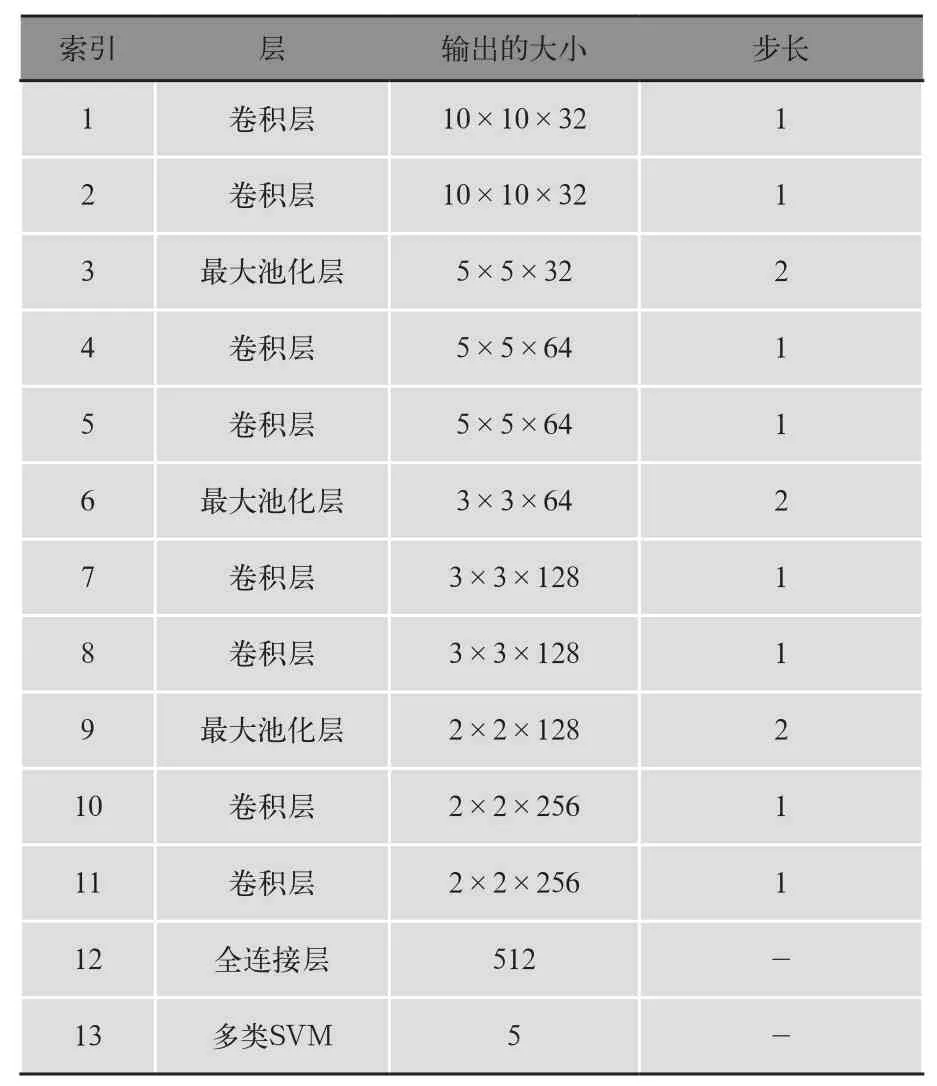
表1 CNN结构
3 实验
3.1 实验设计
本文的实验过程如图2所示。首先将KDD 99数据集进行2.1节介绍的预处理操作,将获得的标准数据集输入CNN进行特征提取,进一步将提取的特征输入多类SVM分类器进行训练和测试,根据实验结果分析改进模型。采用Accuracy、FNR、FPR等评价标准将本文的结果和其他模型进行对比。
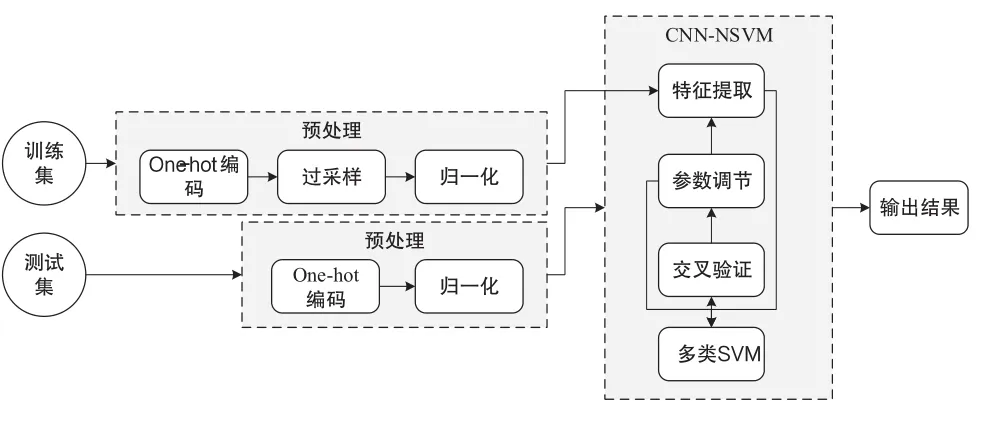
图2 实验流程
3.2 实验数据
KDD99数据集是美国空军9周收集的网络连接和系统审计数据,涵盖各种用户类型,各种网络流量和攻击方法,以模拟真实的网络环境[11]。训练数据包括490万单个连接数据,测试数据包含200万个网络连接数据。我们仅使用数据集的10%进行训练,其中有494021条记录。这个数据集有五种类型,包括Normal、DoS、R2L、U2R、Probe。攻击类型分为4类,共39种攻击类型,其中22种类型的攻击出现在训练集中,另外17种未知类型出现在测试集中。每个连接有41个特征。其中Normal类型有97278条记录,Probe类型有4107条记录,DoS有391458条记录,U2R有52条记录,R2L有1126条记录。它们分别占总数的19.69%、0.83%、79.24%、0.01%、0.22%。
3.3 数据预处理
1)合并稀疏特征。我们发现“service”中“ntpu、tftpu、redi”对应的标签都是“normal”,可以将他们3个进行合并。“pmdump”、“http2784”、“harvest”、“aol”、“http_8001”所对应的标签都是“satan”,可以将它们5个进行合并。
2)数值化特征。本文使用One-hot编码处理非数值型的数据。在KDD 99数据集中有3种协议类型,对应3维的向量;70种服务符号取值,则对应70维不同向量;11种标签的符号取值,对应11个向量。我们为他们建立相应的数值映射(例如TCP=[1,0,0],UDP=[0,1,0],ICMP=[0,0,1])转换为数值特征。最后数据在编码之后的维度从41维变成了122维数据。
3)过采样技术。因为在KDD 99数据中U2R样本类型的数量较少,所以本文将得到的数值化之后的122维数据中的U2R攻击类型进行过采样操作。过采样之后的数据集中类型的数量如表2所示。
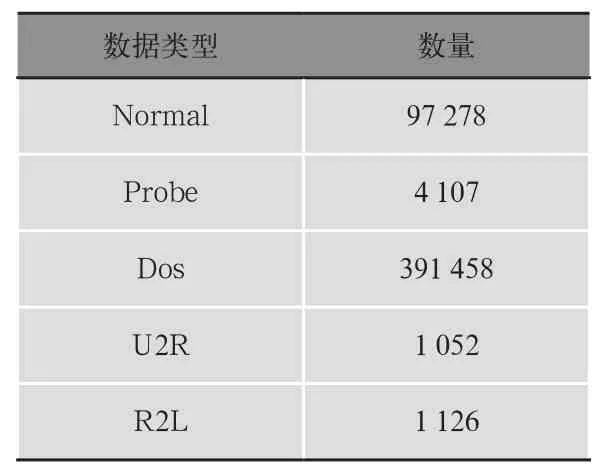
表2 过采样之后的数据类型数量
4)归一化。KDD99数据中存在一些离散或连续的数值,它们的范围不同,使得数据在各维度之间不存在可比性,我们将数据归一化操作,将数据映射到[0,1]之间再对数据进行提取以及分类操作。
3.4 实验结果与分析
1)实验1,卷积核长度对检测结果的影响。
本文分析了CNN中卷积核长度对结果的影响,检测指标是假阴性率(FNR)和假阳性率(FPR),实验结果如图3所示。从图3中可以看出两个检测指标都存在先下降后上升的趋势,在卷积核长度为2的时候FNR达到最低,说明此时攻击类型检测的准确率最高,但此时的FPR较高,我们希望的是提升整体的准确率。在卷积核长度为3的时候,FPR达到最低,同时FNR也达到了一个相对较低的水平。当卷积核长度达到4、5、6时,FNR和FPR都比卷积核长度为3时高,所以卷积核长度为3的时候综合性能最好。可见,卷积核的长度不宜过大,过长的卷积核会导致模型的参数增多,增加模型的训练难度,从而在一定程度上降低模型的检测性能。过短的卷积核容易导致特征学习不到,降低检测率。因此,应当充分实验,选取合适的卷积核长度,提高模型检测性能。
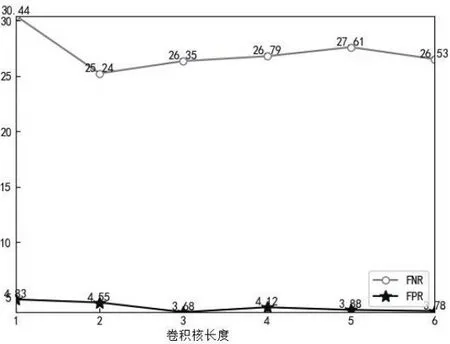
图3 CNN中卷积核长度对检测结果的影响
2)实验2,过采样的性能。

图4 比较过采样性能的精确率
采用少数类合成算法的CNNNSVM和没有采用该算法的CNNNSVM进行训练和测试,比较两种结果的精确率和召回率,结果如图4、图5所示。采用少数类合成算法之后,U2R的精确率提升幅度最大,为17.2%。召回率方面,采用少数类合成算法之后的方法中Normal和Dos两种类型的召回率变化较小,因为他们已经有了很高的召回率,数据集中的小类U2R和R2L的提升幅度较大,分别提升了40.4%和48.6%。结果证明采用少数类合成算法可以有效解决数据不平衡的问题。
3)实验3,与其他模型的性能比较。
使用我们的模型与深度置信网络算法[12]相比较,使用相同的隐藏层个数,深度置信网络的训练时间为54660s,我们模型的训练时间是5023s,节约了90.81%的时间。
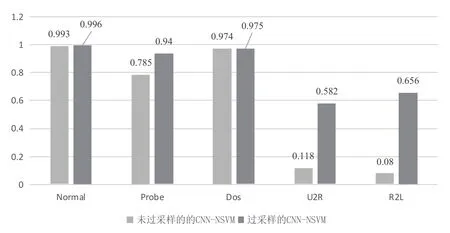
图5 比较过采样性能的召回率
与基于蚁群网络和SVM的入侵检测算法[13]相比,CNN-NSVM中每一步的召回率(Recall)都比CSVAC高,CNN- NSVM中假阳性和假阴性率都低于CSVAC。与基于启发式遗传算法的SVM[14]相比,CNN-NSVM具有更高的召回率。与GF-SVM算法[15]相比,CNN-NSVM算法的假阴性率低于GF-SVM。与Chi-SVM[16]相比较,CNN-NSVM的假阳性率假阴性率均比较低。表3所示,CNN-NSVM可以提高召回率,同时减低FNR和FPR。
4 结束语
文章对入侵检测领域中的现状进行了全面调研,提出了一种新的深度学习方法来进行入侵检测。该模型改进了少数类合成算法来处理不平衡数据集,并设计多层CNN来提取数据特征,进一步使用多个SVM分类器完成入侵分类。实验显示,本文提出模型的整体准确率到达了96.60%,提高了数据集中小样本的准确率,同时减少了训练的时间,提高了召回率。后续我们将继续丰富样本,改进特征提取算法,在降低训练时间的同时进一步降低模型的假阴性率和假阳性率。
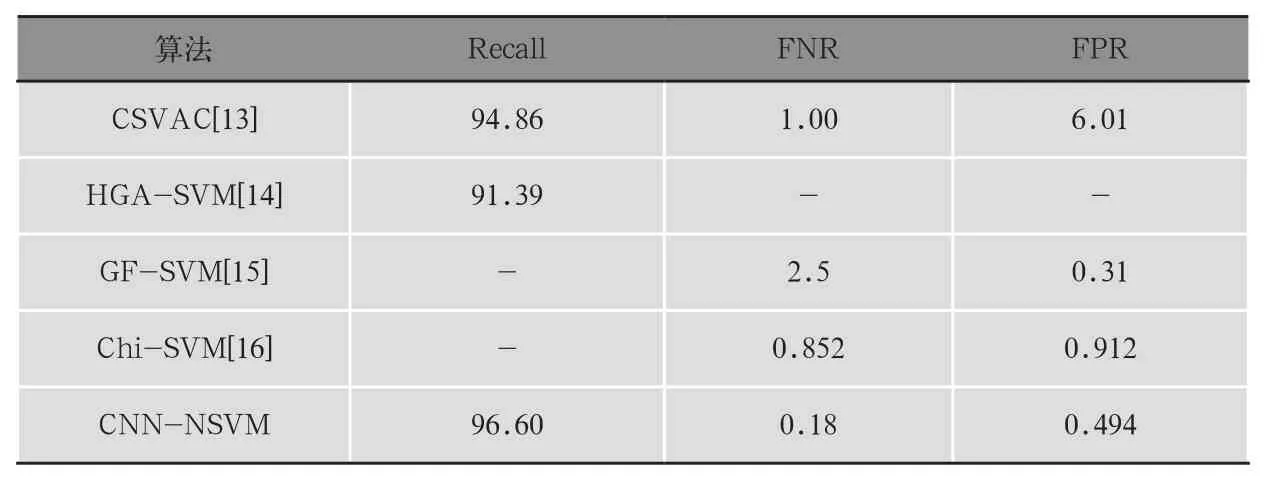
表3 模型性能比较
