超强图形性能护航5G时代解析ARM Valhall GPU架构及Mali-G77
2019-01-15张平
张平


ARM今年的新品不但有新的CPU架构,还有全新的GPU架构。在今年的年度发布会上,ARM公布了全新的GPU架构,也带来了全新的GPU型号Mali-G77。随着移动产品的应用范围和适应场景不断扩大,ARM也在积极调整产品以满足越来越大的计算量需求。VaIhall GPU架构和Mali-G77就是为应对这样的情况而生的。本文将带来ARM这一新架构的深入解读。
ARM上次发布新的GPu架构还是在大约3年前。随着近年来技术和应用的发展,ARM是时候推出全新架构了这就是我们今天要谈的“Valhall”架构。从ARM给出的资料来看,VaIhall架构在性能、密度和效率方面有着重大改进。虽然部分改进在去年的Mali-G76 1-就已经出现,但是架构级别的全面改进,则在采用Valhall架构的Mali-G77上才会全部显现。回顾Biforst
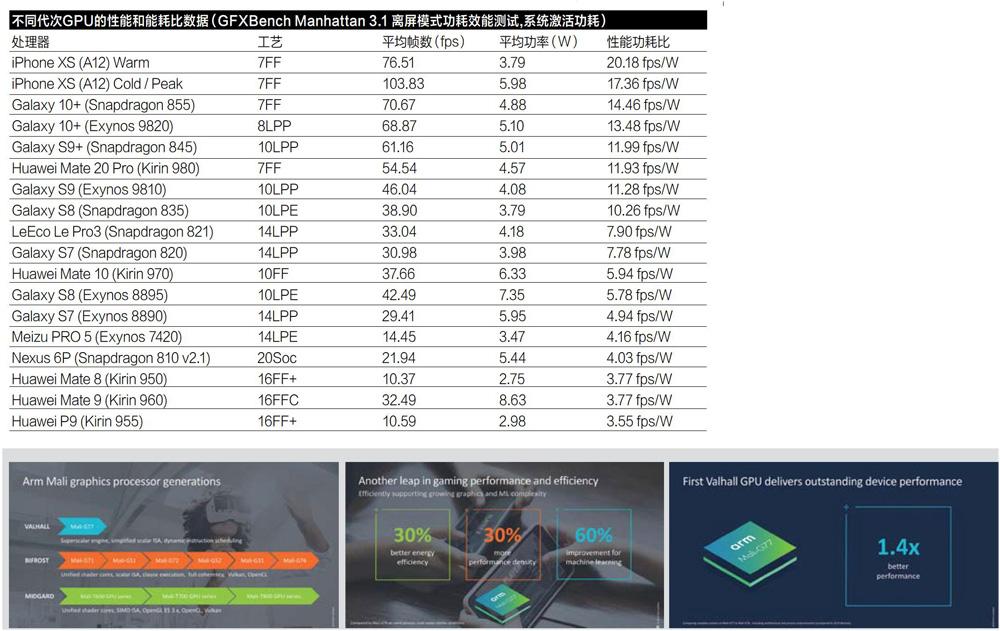
ARM在移动GPU上的演进
实话实说,ARM在移动GPU设计上的底蕴并不深厚,一个典型的例证就是ARM前几代移动GPu无论是架构还是产品的表现都不够出色,这样的情况—直持续到Biforst架构出现,但是Biforst架构的前两款产品依旧存在不少问题。
首款Biforst架构的GPU是Mali-G71,
ARM Mali-G77正式发布
它发布于2016年,华为海思旗下的麒麟960和三星Exynos 8895两款SoC使用了这款GPU。当时人们对这款GPU报以非常高的期望,毕竟这是ARM在GPu架构上做出的重大变化一Biforst是ARM首个标量GPU架构,彻底改变了之前的矢量GPu设计。在桌面GPu上,类似的改变这发生得比较早,包括英伟达在大约十年前推出的Tesla(GT200系列)架构以及AMD在大约五年前推出的GcN架构,都是由矢量转换为标量计算,基础架构的变化代表的是未来的发展方向。
Biforst也做出了这样的变化,但是Biforst架构的产物Mali-G71和MaIi-G72表现并不出色,甚至对三星和华为的产品规划带来了负面影响,比如麒麟960和麒麟970在GPU性能方面的表现令人失望,尤其是面对来自高通骁龙的同代次产品时。好在ARM也看到了这样的情况,在Biforst架构的最后—次迭代也就是第三款产品上,解决了部分问题,带来了性能的飞跃。Mali-G76的表现大大提升了,ARM GPU在消费者心中的地位,并且改善了Exynos9820和麒麟980的性能,使得这两款SoC能够更好地面对激烈的市场竞争。
但是,Biforst架构的迭代和Mali-G76的出现,并不意味着ARM在移动GPu市场中的情况变得更好了。实际上,其竞争对手的进步速度更快。高通的Adreno移动GPu架构—直以来都在引领着移动GPU的发展,尽管今年的Adreno 640并没有取得令人印象深刻的性能改进,但是它的能效比、密度和绝对性能依旧领先ARM的相应产品。另外,苹果全新A12 soc的GPu能效比表现更是相当出色,远远领先目前市面上的几乎所有竞争对手,包括高通和ARM。移动soc市场的竞争激烈程度可见一斑。
Valhall的全面进化
Valhall在架构层面带来了全新的变化,包括新的IsA和计算核心设计这些设计可以解决Biforst的主要缺点,并目看起来它和其他移动GPu供应商的设计思路更为相似了。Valhall的第一次迭代产品就是Mali-G77,接下来本文将讨论VaIhall架构的设计和改进方向。
根据ARM提供的数据,MaIi-G77相比前代产品Mali-G76,其能效比提升30%,面积密度提升30%,机器学习性能提升60%。综合性能增加40%。另外值得一提的是,由于下一代SoC在工艺上进步不大,因此其性能提升主要來自架构设计,也就是Valhall和Mali-G77的架构优势。
深Avalhall架构——全新设计的现代GPU架构
全新的Valhall架构和前代产品存在显著差异,虽然其架构本质依旧采用了标量涉及,但和Biforst异常狭窄的4宽和8宽度不同的是,Valhall的执行核心架构更类似于AMD和英伟达的桌面GPU产品。
前代Biforst架构的Mail-G71和MaIi-G72在核心执行架构上的设计比较紧凑,采用T4宽度的sIMD单元组成,其波前阵列(warp)宽度也为4。在Mali-G76上,ARM将波前阵列尺度提升至8,相比前代产品翻了一倍。所谓波前阵列宽度,是指处理器—次能够吞吐多少数据。在计算中,数据的长度往往会根据实际计算而变化,可能是2、4、8、16等,逻辑控制单元需要拆分、合并一个或者多个计算数据,并打包成波前阵列所需要的长度后,才会将数据导入波前阵列,等待进入计算单元。如果波前阵列设计得过宽,那么在面临大量小数据计算并存在一定相关性时,可能无法完全填充G Pu核心,造成浪费。较小的波前阵列可以避免这个问题,在某些情况下能够提高单元工作效率,但是在大量长度较长的数据来临时,较小的波前阵列设计反而会成为计算瓶颈,逻辑控制单元需要不断拆分数据以适应较小的波前阵列设计瓶颈将转移至逻辑控制单元。此外,较小的波前阵列需要更多的逻辑控制单元才能满足控制需求,更为耗费晶体管资源。
以当时的眼光来看,移动GPU计算中并没有太高的性能需求,在Biforst时代采用较窄的、4宽度的波前阵列设计能够有效降低ALU上的空闲周期量,同时ARM希望以更多的逻辑控制单元来实现更好的ALu利用率。但是在数年后,这种设计显得有些落伍。现在来看,移动游戏正在迅速地向更高的计算复杂程度迈进,大量Pc移植游戏的存在,以及移动游戏本身对Shader的要求日益提升,加上更多的多线程需求,都使得更宽的波前阵列设计逐渐成为主流。在这种情况下,新的VaIhall架构顺势采用了16宽度的波前阵列。虽然相比英伟达和AMD的32宽和64宽,16宽依旧显得小了些,但是考虑到这是一款移动GPU并且上代产品只采用了4宽度,这样的改进还是颇为显著了,
除了波前阵列外,新架构在执行引擎的设计上也有所调整。之前BiforstGPU老圭至Midgard GPU在设计上采用的是多执行引擎方案,每个执行引擎将拥有自己的专用数据路径和控制逻辑,自己的调度程序、指令缓存、寄存器文件和消息传递模块,这自然会带来大量的晶体管开销。在高端GPU上,这样的设计就显得颇为浪费,因为高端GPu往往会采用更多的执行引擎,如果都采用多执行引擎设计的话,每一个执行引擎都有自己的一套”班子”且会进行重复的工作,晶体管会被大量浪费。
Mali-G77改变了这种状况。Mali-G77将前几代的小型执行引擎整合在一个带有共享控制逻辑的大型P模块中。新引擎的IP设计依然存在一些重复的地方,比如ALU流水线被划分为两个“群集”,每个群集都有自己的16宽度的FMA单元以及相应的执行单元。相比前代方案,这样的设计大幅度降低了晶体管使用量,能够让更多晶体管投入到有效的计算中去。
它在ISA方面也有所改变,ARM简化了很多指令。目前还没有更多细节可供参考,但新的IsA更易编译,并经过重新设计和调整,使得其可以更好地与现代API,比女BVulkan保持一致。和之前在Biforst中使用的ISA相比,亲斤IsA采用了一部分新编码,更为规整和易用。
另外,新IsA在指令调度上带来了重大改进。Va lhall架构所采用的新ISA摆脱了固定的issue调度、clauseS子句和tuples元组。在Biforst中,ARM将指令的调度委托给编译器,并且将指令分组到所谓的子句中。这种做法在实际应用中的效果尚可,但需要在编译器上投入大量工作才能隱藏指令和数据访问之间的延迟,因此颇为麻烦。在Valhall中,这些编译器的复杂工作都将不复存在。因为ISA的调度将完全由硬件完成,更类似乱序执行的CPU的工作方式。这种设计还意味着ISA和微架构的脱节,更具前瞻性。
新lsA带来了一些其他方面的优化,包括纹理增强能力的加强,几何流的优化和ARM帧缓冲压缩技术的优化等(版本升级至1.3)。进一步深入研究执行引擎的话,可以发现执行引擎分为四个块,分别是:波前阵列调度程序、指令缓存的前端、两个相同的数据路径集群(处理单元)以及和消息块连接的加载,存储单元、固定功能模块等。
Mali-G77的前端最多支持64宽的波前阵列和1024个线程。每个处理单元具有3个ALU:FMA和BCVT的波前阵列都是16宽度,而特殊的SFU波前阵列采用了4宽度。SFU并不是常用的单元,因此并不需要太大的吞吐量。
MaIi-G77的前端可以创建或者退回波前阵列数据,并且为所有的波前阵列进行状态跟踪。另外,MaIi-G77前端还增加了一个动态调度功能,这个功能可以决定每个波前阵列将执行哪些指令,还可以将等待中的相关联波前阵列替换为准备执行的无关联波前阵列,尽可能提高执行效率。
指令缓存方面,Mali-G77的前端指令缓存采用的是共享设计模式,并且是16KB、4路关联的方式,支持2048个指令,每周期可以发出4个指令。在实际的处理单元(集群)中,Mali-G77设计74个可以发送指令到算术单元的拾取单元。每个拾取单元都设计了一个精密耦合的寄存器,以及一个用于减少访问寄存器文件延迟的转发缓冲区。FMA ALU每周期支持16个FP32FMA,是FP16的2倍,也是INT8点阵的2倍。转换单元处理基本整数操作和自然类型转换操作,同时也会被用作分支端口。
总的来看,相比Mali-G76,Mali-G77的执行引擎资源更为丰富,类似于一台发动机和三台发动机之间的区别。Nali-G77的引擎在主数据路径上有更多的资源,并且控制和指令缓存所占据的空间更少,从而提高了整个计算模块的面积效率。
在延迟方面,新架构的ALU延迟将变为4个周期深度,之前的产品为8个周期。这样的变化可以在没有链路操作时提高性能。此外,新核心具有类似超标量的功能,而不是过去的管状设计。由于延迟降低,整个核心流水线必须进行重新设计,这也是编译器简化的重要原因之一,因为编译器不需要再匹配同时发出的指令大大降低了复杂程度。
Mali-G77架构解读
在看过基本架构的设计后,再来看看Mali-G77微架构设计的内容。MaIi-G77微架构从整体来看和上一代产品存在很多相似之处,但是在一些重要的模块上存在明显的变化。
Nali-G77的Shader核心依旧包合执行引擎,其中包含了高速缓存的加载和存储单元、属性(attribute)单元,变化(varying)单元、纹理映射单元和像素后端,以及各种其他的3D固定功能模块。其中变化最大的是纹理单元模块,和Mali-G76相比,新的纹理单元模块吞吐量增加了一倍。
从高级功能来看,新纹理单元微架构的主要改变是在吞吐量的设计上。新的设计被分为2个路径,其中一个是命中路径,另一个是未命中路径,后者可以用于处理缓存内部或者纹理缓存外部的未命中情况。命中路径自然是皆大欢喜的最短延迟优化路径。此外在命中路径方面,纹理缓存得到了大幅度改进,变成32KB容量,并且能够达到16个纹理每周期的吞吐量。滤波单元也得到了改进,其吞吐量也有所提高。在Mali-G77上,双线性纹理每循环支持一个四边形处理,三线性纹理每循环支持半个四边形处理,这两者都达到了Nali-G76类似单元吞吐量的2倍。
同样,ARM也表示Mali-G77的新纹理单元和Mali-G76基本相同,不过吞吐量倍增还是显示出这是一个非常好的工程改进实例。
从根本上来说,核心纹理能力的这种大幅度增加改变了GPU的ALU:Tex的比率。尽管ALu的计算能力增加了33%,但是纹理单元的吞吐能力翻倍意味着比率回归到了一个比较低的水平,更有利于纹理吞吐量。相比之下,过去的GPu更重视计算性能。ARM认为这是面对新的工作负载所需要进行的改变,因为如今GPu在纹理方面的压力变得更大。
需要注意的是,虽然纹理单元过滤、吞吐量大幅度增加,但是像素后端吞吐量却没有增加。在这里,Shader核心依旧只能每时钟抽取2个像素,因此现在的纹理、像素比率是2:1,前代产品则是1:1。
shader核心模块中的另一个重要改进是新的读取存储缓存。这个新模块在功能上和之前的模块相同,但是经过了重新设计能够接受更多的吞吐量。在同一区域内,由于缓存重新设计因此对应管道阶段的延迟也降低至前代产品的一半。另外,新缓存的带宽也增加了,达到前代产品的2倍。具体规格方面,缓存的大小为16KB、4路关联,据说对机器学习等类似负载非常有用。
最后,我们将所有的部件放在一起,并从Shader级别扩展至GPU级别之后,可以看到ARM是如何重新组织各个单元模块而成为一个完整GPu的。目前新的架构支持Shader核心1核心扩展至32核心(MaIi-G77最多只能支持16个核心)。另外,ARM为RTL版本准备的最小核心设计采用了7个Shade—亥心。ARM还有可能公布诸如MaIi-G52这样的小核心方案,以满足不同用户的需求。
PPC和效率提高30%
前文描述了很多VaIhall架構以及MaIi-G77的变化。当然,所有的这些设计最终需要转化为性能、效率等各方面的表现,才能体现出它的意义。
ARM同样给出了相关性能的预览图。不过本次发布的性能预览和过去存在很大差异,ARM采用了每平方毫米的性能作为对比单位。一般来说,由于芯片厂商会根据自己的不同市场定位和需求进行配置,因此采用某种固定GPu核心数量和频率的方案进行比较的话,覆盖面不够广泛。因此ARM改用了每平方毫米性能作为对比参数。ARM宣称,Mali-G77相比前代产品,能够提供1.2倍到1.4倍每平方毫米性能的提升。从绝对意义上看,Mali-G77的Shader核心和Mali-G76的面积相同。
这意味着供应商在相同的性能需求下,可以选择更小的GPu,或者使用更多的GPu核心(当然需要更多的面积)来提高性能。尤其是ARIVl声称Mali-G77在重纹理游戏中的性能表现更为出色,因此未来设备在不同的工作负载下性能表现到底如何,这样是一个值得探寻的话题。
提高性能的另一个方法是提高时钟频率。不过在移动soc中,限制来自功耗,智能手机的soc最多只能容纳4W~5W的TDP功耗。在性能比较中,一些消息显示在完成相同工作负载的情况下,Mali-G77的能源消耗降低了17%-29%。换句话来说,Mali-G77的每瓦特性能是前代产品的1.2倍到1.39倍。ARN表示,Mali-G77的基本频率不会发生太大变化,ARM依旧以850MHz作为其目标值。
在横向对比方面,ARM宣称其在与采用Mali-G76的三星Exynos 9820对比时,新处理器的性能将提升1.4倍,这意味着未来采用Mali-G77架构的50C将以更高的能耗比(假设维持目前的功率水平),提供接近苹果A12处理器的GPU性能。这将给高通带来巨大压力,因为这样的性能表现将显著超越目前的高通所使用的Adreno 640。不过高通也将发布全新的Soc产品,让我们拭目以待吧。
此外,在目前大热的机器学习方面,Mali-G77的性能相比上代产品提升了60%,这不仅是由于内核数量增加了33%,还包括Lsc以及带宽所带来的性能提升。最后,ARM也展示了MaIiGPu家族性能提升的代际比较。ARM宣称其每代能耗比提升幅度大约是30%,Mali-G77相比Mali-G72更是节约了50%的能源。
ARM的又一次跃进
从官方资料来看,Valhall架构和Mali-G77将成为ARM近期的重大技术革新。全新的架构将改变ARt在移动GPU竞争中的态势,使得ARM可以提供更好的GPu架构和技术。新产品将会带来更好的表现,毕竟Valhall架构是一个具有潜力的架构,ARM还将基于它推出更多产品。
从实际产品来看,今年晚些时候或者明年初,我们就可能看到三星或华为推出了基于Valhall架构和Hali-G77的相关Soc产品。目前来看,Mali-G77能够带来出色的性能和效率提升,这使得三星和华为的处理器能够进一步缩小甚至超越和苹果、高通的产品,尤其是高通的Aderno GPU,可能将面临更为严峻的挑战。
