中文复述问句生成技术研究
2019-01-11曹雨,张宇,刘挺
曹 雨, 张 宇, 刘 挺
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
0 引 言
复述生成技术在很多方面有着重要应用,如:在问答系统中,可用来提升系统对问句的理解能力,优化系统性能;在机器翻译领域[1],可用来扩展语料规模,解决数据稀疏问题;在阅读理解任务中,可用于问句多样性的研究,使机器自动生成的问题更符合人类的自然语言规范。
复述模板的表示和抽取[2]是研究复述的重要方法之一,合适的复述模板表示方法和复述模板自动抽取方法是主要难点。复述模板拥有很强的表达能力,能够有效地表达自然语句的结构和特征,可以用来进行大量复述实例的生成。目前已存在很多种复述模板的表达方法,如:利用词的词性作为特征表示复述模板;将某些词语替换成变量作为复述模板。本研究从句法分析入手,结合词性、命名实体和功能词等信息,形成了一种新的复述模板抽取的方法,同时也保留了句子的结构信息、语义信息以及每个词对应的上下文信息。在该方法中,每条中文问句对应一个句子模板,从而每组复述语料可对应一组模板,再结合匹配生成方法,生成一系列的候选生成句,最后利用基于相似度计算和语言模型相结合的方式,对候选生成句进行打分排序。
本文引入现有较好的其它基于问句模板的复述生成方法以及基于深度学习模型的复述生成方法作为对比,进行实验。实验结果证明了本文所提出的方法的有效性,可以大大提升复述生成的准确率。
1 相关工作
近年来,学界已陆续涌现了许多研究方法与模型,并且均取得了可观成果,但这些模型与方法也都有着各自的弊端,有些准确率偏低,如:Lin等人[3]提出的DIRT方法;有些规模受限、领域受限,如:基于机器翻译评测语料的复述句抽取方法;有些生成的结果偏于复杂,如:Pang等人[4]提出的有穷自动机方法;有些复述的来源受到限制,如:Zhou等人[5]提出的翻译特征方法。
目前,虽然国内对于复述的研究日渐重视,但与国外相比中文的复述研究仍亟待完善,尤其是针对开放领域问答系统的问句复述技术的研究上,面临着较大的研究挑战。仅就问句分析技术而言,因其作为自动问答系统中至关重要的组成部分,分析效果的好坏将对整个问答系统的表现发挥决定性的影响作用。其中,针对问句分析模型可以理解和分析更多的可变长度的问句的问题,在很长一段时间内,主要遵循了2种途径方法:问句扩展和复述生成;基于句法结构复述生成方法,与之前2种方法相比可以生成更多可扩展的问句,但前述方法多数情况下会用于英文语料的研究,究其原因则在于中文语料存在以下3个难点:
(1)中文语料不足,且规模较小。
(2)不存在面向中文语料的语法分析器。
(3)中文语法过于灵活和复杂。
机器学习和深度学习技术的迅速发展,也为复述生成技术的研究提供了更多可能的有效解决方法。但其对语料的要求较高,需要大规模高精度的中文复述资源库,针对开放领域问答系统的研究,需要大量的高精度单语复述问句句对,因此中文问句复述语料规模的限制成为问句复述技术研究应用于开放领域问答系统的瓶颈。
2 基于模板匹配的复述生成方法
研究提出的方法主要分为问句模板抽取、模板匹配生成以及候选生成句排序三个模块。对于某一问句qinput,首先采用一系列的预处理操作,然后通过问句模板抽取模块,抽取模板tinput,再利用匹配生成模块生成候选模板集T和候选问句集Q,最后利用候选生成句排序模块对候选生成问句进行排序。下面,将对每部分研究展开详述如下。
2.1 复述语料获取及预处理
本次研究主要针对开放领域,且复述语料资源有限,因此选取“百度知道”相似问题作为语料来源,共爬取百度知道完整问句2 232 051条、373 704组。研究采取的具体形式可见表1。
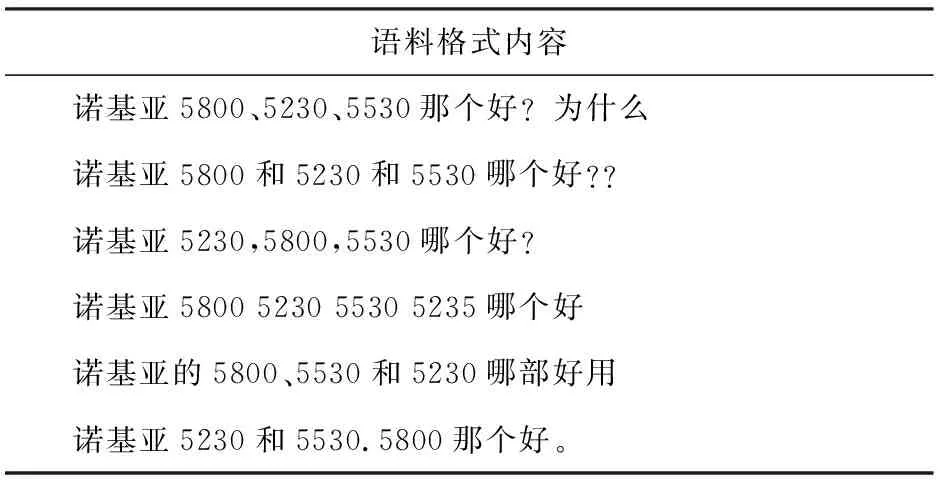
表1 语料格式
语料中的很多问句较长,其中含有引用成分,如:“白日依山尽”这首诗的作者是谁。引号中的成分在模板抽取的过程中应作为一个成分,在后续的分词过程中不应进行处理。所以,研究将语料中书名号和引号中的内容进行标记,不参与分词,在模板抽取过程中直接对应
从线上问答系统中获取的语料资源来自于用户提出,问句中符号、标点的使用极其不规范,必将影响后续的实验研究过程,因而需要删除。但实验过程中发现,标点、符号的使用会牵涉到句子的分词、词性标注及依存关系分析,如图1所示,基于此,研究中将采用LTP平台对语料进行依存关系分析和词性标注后,再将问句资源中的符号进行删除处理。
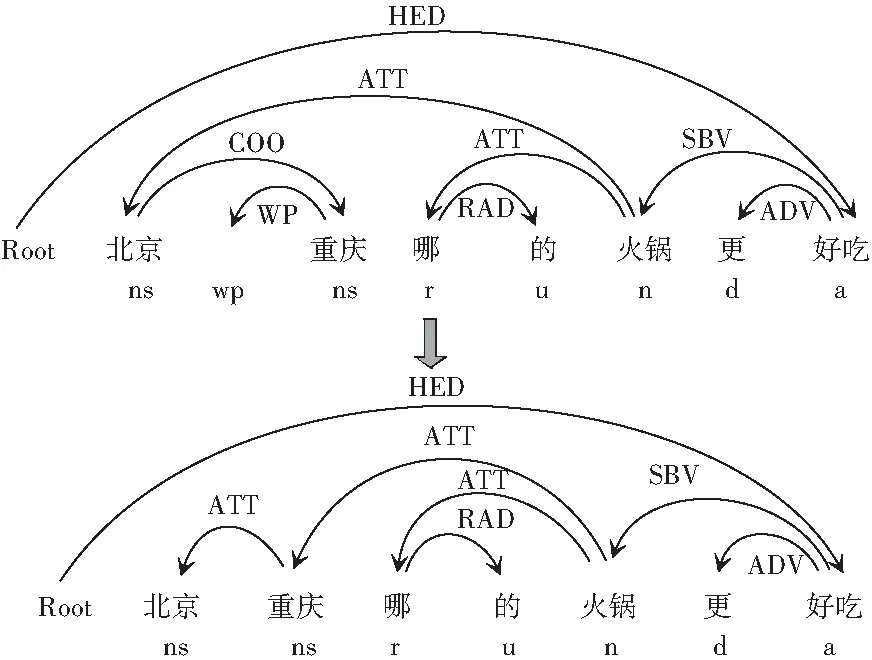
图1 符号对依存关系分析的影响
语料中还有很多问句的成分是不完整的。这类问句在后续实验的问句简化过程中,句子长度会急剧减少。如:“河北城乡建设小学宿舍”,这个句子中,“河北城乡建设小学”作为“宿舍”的修饰限定,在句子成分简化过程中会被暂时移除,保留其中心词“宿舍”,无法构成一个完整的句子,对后续问句模板提取没有任何贡献。又因为构成一个完整的中文问句至少需要包括3个词,如:“马云是谁”,且问句长度过长难以进行有效分析。所以,对语料进行依存关系分析,去掉其中修饰限制成分后,问句长度最短为3,最长设定为20。
经上述预处理过程后,研究中共保留复述语料1 178 126条、272 174组。
2.2 问句模板抽取
问句模板提取主要包括5个部分:分词、词性标注、命名实体识别、功能标签替换以及句法分析。对此可做阐释论述如下。
采用LTP平台对语料进行分词、词性标注、命名实体识别,在保持句子中词汇顺序不变的条件下,用词性标签和实体标签代替其所对应的词汇,初步形成问句模板,过程解析详见表2。
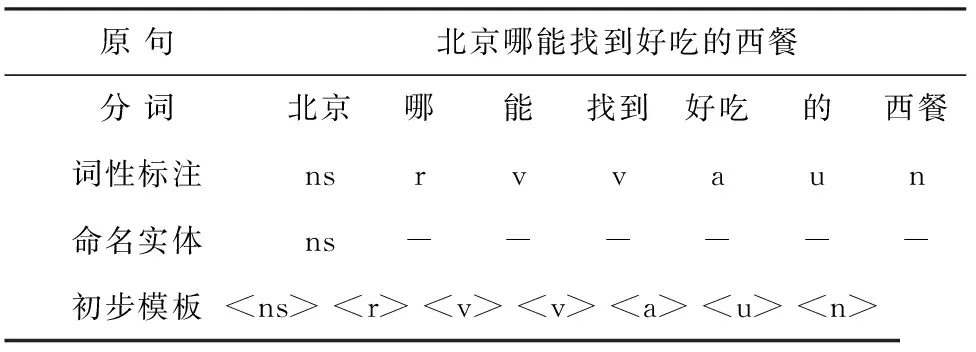
表2 初步形成问句模板
此时的问句模板已经具有一定的表达和泛化能力,可代表与此句式结构相同的一部分自然语言问句。但在诸如表2所示的实验样例中,研究观察初步生成的问句模板可以发现,“哪”表示地点疑问词,在上述过程中仅仅被简单地标注为‘r’(代词)标签,无法表征出其语义特征;“能”、“找到”两个词都被标注为‘v’标签,但这并不准确,实际上“能”属于情态动词,并不表示实际或具体的动作。因此,上述步骤是不完善的,无法真实有效地表示出某些词汇的语义特征、语法结构及句法结构。至此,为了将诸如上例所述的这部分特殊词与其它与之具有相同词性的词汇进行区分,研究专门收集了一些与表2实例中“哪”类似的可表示问句特征的关键词以及一些与“能”类似的情态动词,形成词表,进行人工标注,为每一个词赋予一个标签,最终形成的功能词表可见表3。更新后的问句模板为:
中文语法灵活多变,导致某些问句结构成分复杂,难以分析。此类问句在语料中占有较大比重,经分析发现,句中含有大量的修饰限制成分,如:“中国北京有多少家好吃的餐馆”,在此例中“中国”是用来修饰“北京”的,“好吃”和“的”是用来修饰“餐馆”的,此类词汇的有无对句义不会造成很大的影响,却会在后续的模板匹配和生成过程中产生重大影响,使得同类型的句子因为修饰限制词的影响而无法成功匹配生成。综上可知,虽然无法具体去确定每一个词的修饰限制用法,但却可以就某一类词进行研究,从而找出其通常情况下用法,将句中的修饰限定成分暂时移除,简化句子结构,从而使得句子模板更具泛化性,寻找到更多匹配模板,生成更多的候选问句。

表3 功能词表
句子结构的简化过程极其繁琐、费时。在此过程中,并不能简单地将某一类词直接从句子中移除, 如:形容词(词性标注为a)是最常见的修饰词,通常情况下用来修饰名词(词性标注为n),可以被移除,但通过实验及对语料的分析,发现类似于“马尔代夫和毛里求斯,哪个风景更漂亮”这样的问句,本句中“漂亮”是一个形容词,但却不能直接移除,若直接移除,则该句成分将会出现严重缺失。与此类似的句子在语料中还存在很多,如:“视频转换大师与格式工厂哪个更快”。中文句法过于灵活,其中还存在着多种修饰限制关系,如:“文化教育”为名词修饰名词;“调查研究”为动词修饰动词;“漂亮美丽”为形容词修饰形容词等等。本次研究中采用句法分析,并根据句法分析的结果构建句法树,先引入6种较为常见的修饰关系对语料进行简化,分析句子简化的结果,根据某种修饰关系对语料简化的影响程度,排除已有的修饰关系或引入新的修饰关系,如此反复,最后筛选确认8种对句子简化最为有效、且移除后不会对句子主干造成影响的修饰关系,对此描述可参见表4。
句子成分精简后,如表2所示的样例的最终模板变为
2.3 模板匹配生成
上述模板抽取过程结束后,会生成2部分资源。一部分为原始语料进行句子精简后的自然问句复述资源,另一部分为其对应的复述模板资源。将这2部分资源作为匹配生成过程中待查询的资源库。
输入某一新问句,作为待改写生成的问句,采用上述的句式精简和模板抽取对该问句进行处理。在对此问句的精简过程中,仅仅是暂时移除句子中的修饰限制成分,将其保留起来,待后续使用,如图2所示。抽取待改写问句模板,将该模板在整个复述模板库中进行全匹配检索,在某一复述组中检索到该匹配项,则证明该组其它句子具有改写成该句的可能性,将这若干组模板复述资源重组,形成新的候选复述模板资源,候选复述模板资源所对应的精简自然问句构成新的候选自然句复述资源,即如图3所示。

表4 可简化修饰关系
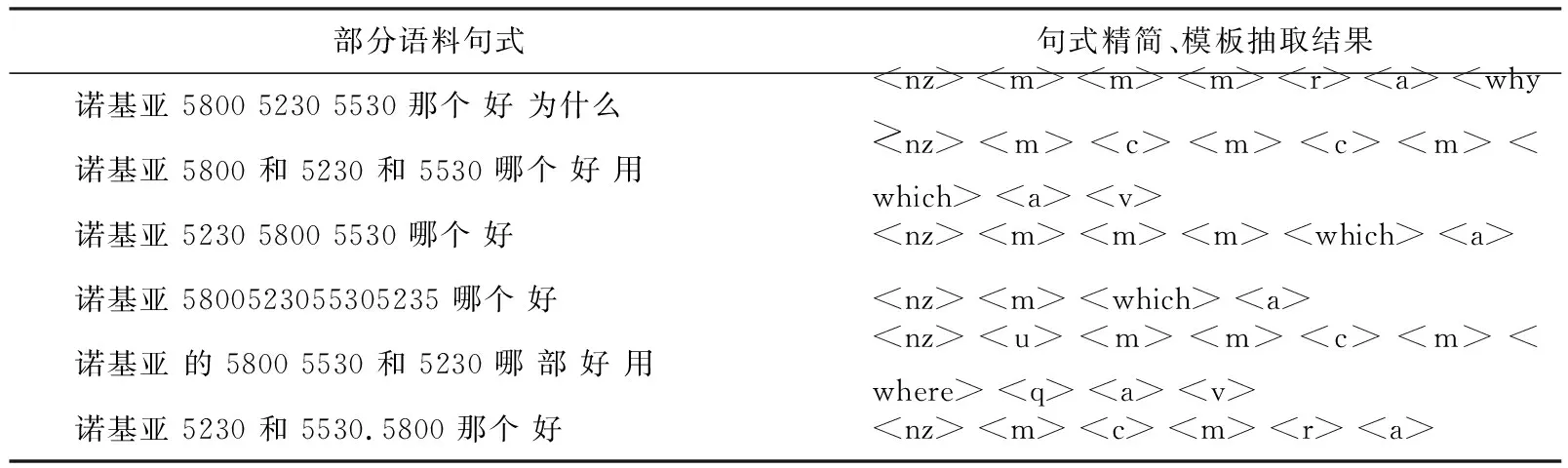
表5 部分语料句式精简、模板抽取结果

图2 句式精简及还原过程
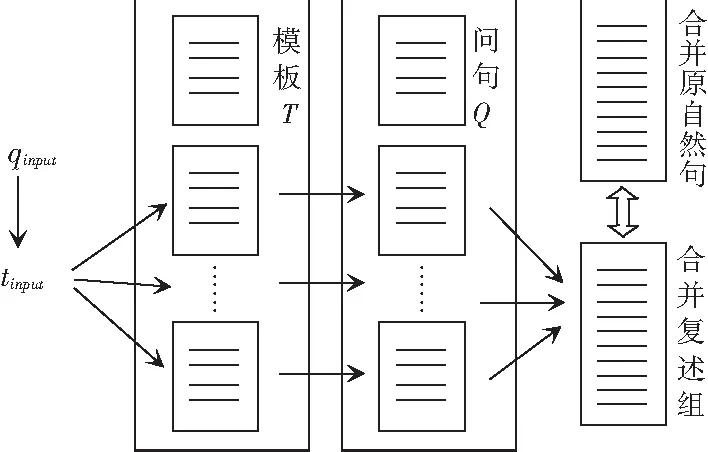
图3 复述组合并
选取候选复述模板资源中的某一条,与待改写问句模板进行比对,将其与原模板相同的标签部分作为槽,其余部分为其特征部分,保持不变,如此可形成待生成的特征模板。将待生成的特征模板与其自然问句对应,保留其特征部分的词,其余部分作为槽。将带改写问句中的词根据槽所对应的标签,依次填写进槽内,生成新的问句。其设计过程如图4所示。

图4 复述改写生成过程
2.4 候选生成句排序
本部分研究提出一种基于相似度计算与语言模型相结合的方式进行候选生成句的打分排序,其中语言模型采用RNN-LM,相似度计算采用Wang等人[6]研发的基于相似与相异信息的CNN模型。
RNN-LM[7]利用神经网络对语言进行建模,与传统的N-gram相比,尤为突出的一个优点就是将历史信息映射到了一个低维的空间,从而降低了模型的参数,并将相似的历史信息进行了聚类。先用RNN-LM对候选生成句进行打分,记为Slm,然后对其进行归一化操作,所得分值作为语言模型对于候选生成句的最终打分,记为S1。
基于相似与相异信息的相似度计算方法,可得模型设计结构如图5所示。研究中,首先使用由Mikolov等人[8]提出的模型训练出来的词向量进行句子的表示。对于句子S和T,则将其表示为向量矩阵S=[S0,…,Si,…,Sm]和T=[T0,…,Tj,…,Tn],其中S和T是句子中词汇的d维词向量,m和n则是句子中包含词汇的数量。
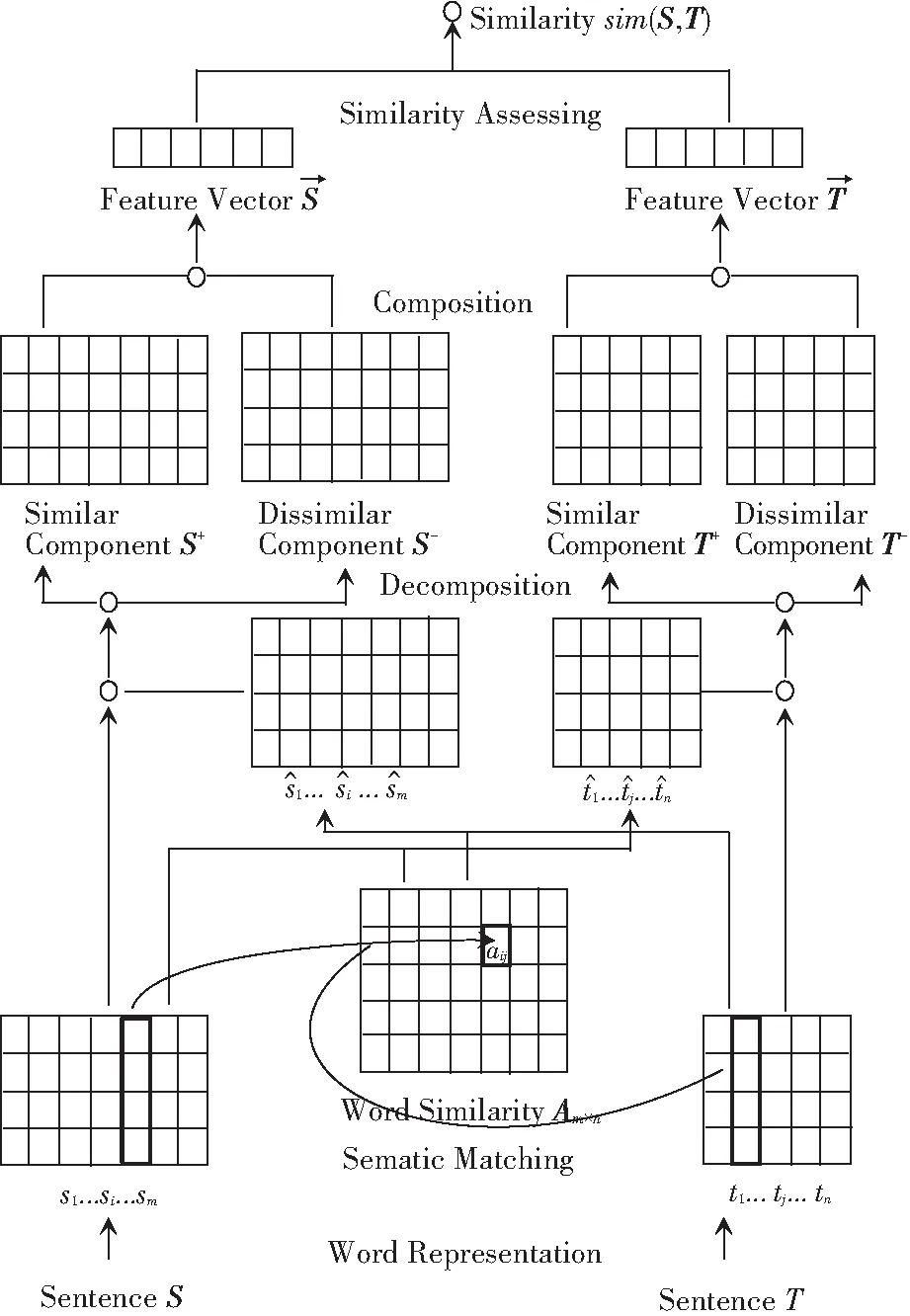
图5 基于相似与相异信息的CNN模型

首先使用余弦相似度计算句子S和T的相似度矩阵Am×n,对于相似矩阵Am×n,矩阵中的元素aij是Si和Tj的余弦相似度,则可通过式(1)进行计算:
(1)
通过Am×n运算得到了句子T中同Si最相似的词汇Tk,并使用Tk及其上下文来表示Si,研究推得数学公式如下:
(2)
其中,k=argmaxjaij为T中同Si最相似的词的下标。
研究中使用Tk及其窗口大小为w的上下文的词向量的加权平均来表示Si,每个词的权值大小为该词同Si的相似度,以Tk为例,其权值为相似矩阵Am×n的元素aik。
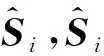
(3)

这里,将使用以上信息对S和T进行建模并计算两者的相似度。受到Kim等人的启发,研究使用双通道的CNN模型对相似矩阵S+及相异矩阵S-进行建模,得到句子S的特征向量Fs和句子T的特征向量Ft。最后研究中再次使用Fs和Ft计算S和T的相似度。
CNN模型一共包含3层,即:卷积层、max-pooling层以及全连接层。以S为例,在卷积层中,将重点在相似通道和相异通道上设置了一组过滤器{w0,w1},用于生成一组特征,其数学运算则可写作如下形式:
(4)
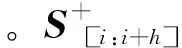
最后,研究即使用全连接层对Fs和Ft进行计算,通过sigmoid函数将结果归一化得到句子S和T的相似度。通过利用这种方法对候选生成句进行相似度计算,所得分值记为S2。
通过反复实验与观察,讨论后确定了候选生成句分值的数学运算公式可表示为:
Score=0.000 1S1+S2
(5)
运算后,则按照分值高低对所得的候选生成句进行排序。
3 实验
为了对上述方法进行有效性的验证,研究采用“百度知道”的相似问句作为复述语料资源,并以目前效果较好的其它基于问句模板的复述生成方法[9]以及由Prakash等人[10]最新提出的基于残差LSTM模型的复述生成方法作为对比,进行实验。研究中,将对此阐述如下。
3.1 实验设置
研究采用哈尔滨工业大学社会计算与信息检索研究中心的语言云平台对语料进行分词、词性标注与依存关系分析。
在RNN-LM的使用过程中,研究以语料资源的2/3作为训练集,1/3作为验证集,隐含层单元数设为40,控制开关个数设置为2,控制通过环反向传播错误设置为4,词语分类为200类。
在使用基于相似与相异信息的CNN模型计算相似度的过程中,研究中对所用语料使用Mikolov的模型训练了100维的词向量,并从语料中抽取了3 259对问题对,添加了人工标注,将其中2 500对作为训练集,500对作为开发集,759对作为测试集。设置过滤器的大小为3,过滤器个数为500,学习率为0.01,共进行了10轮训练。
3.2 实验结果
实验过程中,研究随机选择100条问句作为测试集,分别用传统的模板匹配生成方法、基于残差LSTM的复述生成方法以及本文提出的基于模板匹配的复述生成方法进行实验,并以覆盖率与准确率作为评价指标。对此研究内容可分述如下。
(1)覆盖率。成功复述生成的问句在测试集中所占的比例,运算时可参考数学公式如下:
(6)
其中,Tparaphrase为测试集中被成功复述的问句数量,Tall为测试集中的问句总数量。
如:测试集问句共100条,其中70条问句经过复述生成产生了新的结果。则其覆盖率为70%,该指标可以反映不同方法的复述生成能力。
(2)准确率。提取的候选生成结果中正确的数量与提取的候选生成结果总数量的比值,运算时可参考数学公式如下:
(7)
其中,Ncorrect为提取的候选生成句中正确的数量,Nextract为提取的候选生成句总数量。
如:研究共选取了50条候选生成问句进行标注,其中有20条是正确的,则其准确率为40%,该指标可以反映不同方法的复述生成效果。
选取候选生成结果中的Top3和Top1进行人工标注评价,实验结果见表6。
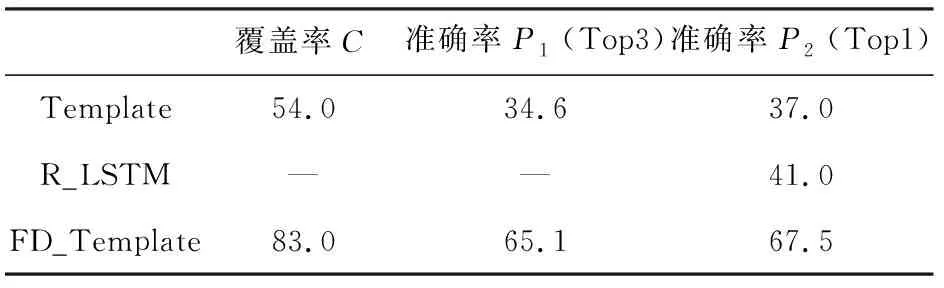
表6 不同方法的复述生成结果
在表6中,Template为已有效果较好的基于模板匹配的复述生成方法,R_LSTM为基于残差LSTM的复述生成方法,FD_Template为本文提出的基于模板匹配的复述生成方法。
研究分析后可知,Template和FD_Template方法为基于模板匹配的复述生成方法,部分问句无法进行复述生成,因此需要统计覆盖率,且每条可复述的问句可能生成多个候选结果,因此结果中包含Top3、Top1两个评价部分。R_LSTM为基于残差LSTM的复述生成方法,每个问句能且只能生成一种可能性最大的候选结果,因此其覆盖率无需参与对比,且不存在Top3结果统计。
采用本文所提出的FD_Template复述生成方法进行实验,并取其生成结果的Top3,部分结果可见表7。其中,Qi为原始问句,Pj为复述生成的候选结果。

表7 FD_Template复述生成的Top3结果
3.3 实验分析
通过对以上结果的分析,可以得出本文所提出的FD_Template复述生成方法在覆盖率和准确率指标上均取得不错结果,与传统的基于模板匹配的复述生成方法和基于残差LSTM的复述生成方法相比,效果提升明显。
与传统的基于模板匹配的复述生成方法相比,本文的方法在模板抽取部分引入了功能词和句式精简,突出了模板的特征,增强了模板的泛化能力,探索出了一种更为适合的问句模板的表示方法;在候选生成句抽取的过程中,本文提出了一种近似于复述检测的方法—基于相似度计算与语言模型相结合的方法,该方法不但考虑了生成句的流畅性,更利用了问句所涵盖的语义信息。
与基于残差LSTM的复述生成方法相比,基于残差LSTM的复述生成方法将复述生成研究视为一种机器翻译任务。该模型对问句的语义可以进行更深程度的挖掘,但由于当前缺少大规模、高精度的复述问句语料资源,故而该模型的学习能力受到极大限制。而本文提出的方法对于语料的要求较低,在现有的低精度的复述语料资源上即可取得不错效果。
4 结束语
本文在传统的基于模板匹配的复述生成方法的基础上,加入了功能词、句式精简,可对问句模板进行更合理的表示,提出了一种新的候选生成句打分排序方法,可对候选生成句实现更为有效的抽取,且避免了基于深度学习方法开展复述生成研究时面临的大规模、高精度语料缺少的问题。通过最终的实验结果可以发现,本文提出的复述生成方法的覆盖率与准确率较高,证明其可对大部分问句进行复述并得到不错效果。
