基于粗糙集的慢性病变分级方法①
2019-01-07胡建强
胡建强,王 元
(厦门理工学院 计算机与信息工程学院,厦门 361024)
中国卫生部《健康中国2020战略研究报告》明确指出:加强基层医疗体系建设,建设基于网络体系的全民电子健康系统、推进预防慢性病及重大疾病,大力发展民族健康产业,投入资金总规模将达4000亿.云健康监测综合运用传感器网络、云计算和大数据处理等技术,可以实现多生理参数实时采集、海量数据存储和大数据智能分析与处理,是下一代家庭健康监测的主要发展方向.
目前国内外学术界围绕健康监测领域展开很多积极的探索,主要工作包括:美国田纳西大学设计一种实时监测人体生理ECG数据云Cloud-ECG[1],保证云端数据存取的ECG数据质量.西班牙格拉纳达大学采用可穿戴式胸带传感器监测人体的心电、心率、呼吸频率、皮肤温度,生理监测数据存放在个人微云(Cloudlet);心电数据采用马拉松算法处理并以红、绿、黄颜色警示患者身体健康状况[2].台湾国立台中科技大学基于体感网 WBANs(Wireless Body Area Networks)采集人体的血压、心率和体温等生理数据;采用VMware搭建的微云存储数据;采用融合粗糙集的等级评定算法[3]协同推荐信息到相关医疗群体[4].飞利浦保健算法研究中心提出一种ECG波形实时质量评估算法—ST段心肌梗死评估算法[5,6].东南大学采用织物电极采集ECG数据[7]、北京工业大学提出采用可穿戴式多参数心脏活动监测设备采集心音、心电和心冲击图数据,在线监测心脏活动[8];中科院提出“低成本健康海云工程”,采用无缝接入的智能医疗终端监测患者生理健康状况;利用云计算技术实现海量电子病历和电子健康档案存储[9],但未给出生理监测数据的处理算法.
云健康监测可以有效解决现有家庭健康监测系统(终端)在数据存储容量方面的局限性,但生理监测数据仍缺乏高效、实用的智能分析算法,特别是传统的分类算法(例如SVM,KNN,决策树等)很难直接应用,难以满足居民慢性病变智能预警和突发状况救治需要.其主要原因是:生理监测数据具有时间连续性、非精确性、模糊性等特性,实际应用存在数据遗漏或缺失.例如,体温数据相对恒定,但 24小时略有波动;动态ECG信号需采用小波分析算法对QRS复合波实时检测和有效筛选,24小时内波动较大[10].
针对上述问题,本文提出一种基于粗糙集的慢性病变分级方法,帮助个体全面认识慢性病变风险,该方法包括以下步骤:首先,采用融合相关度和Chi-merge统计量对连续属性离散化,提高聚类能力;然后,基于相容矩阵的属性约简算法去除数据冗余属性,降低原始数据集维数;最后,基于批量和增量相结合的分类规则挖掘,确定最优分类规则集合,并基于MapReduce框架运用上述规则实现慢性病变智能分级.结合厦门市集美区病例数据验证算法,基于自主研制的联接厦门市“健康医疗云”的云健康监测系统Cloud-Health[11]平台展开上述方法的有效性验证.
1 方法原理
1.1 融合相关度和Chi-merge统计量的属性离散化
离散化本质上是利用选取的断点来对条件属性构成的空间进行划分,即将m维空间划分有限个区域.为提高系统的聚类能力,增加对生理监测数据噪音的鲁棒性,应该采用尽可能少的断点来完成划分过程.随着属性个数和样本量的增加,候选断点数将会成倍增长[9].断点选择对保证最小的结果断点集合至关重要.下面给出融合相关度和Chi-merge统计量的属性离散化的一般性方法.
定义1[12].决策表S=(U,R,V,f),U={x1,x2,···,xn}是有限的对象集合;R=C∪D是属性集合,子集合C和D分别为条件属性集C={c1,c2,...,cm}和决策属性集D={d};m为条件属性的个数.假设决策种类的个数为r(d),f:U×R是一个函数,指定U中的每一对象x的属性,属性ci的值域Vci为:
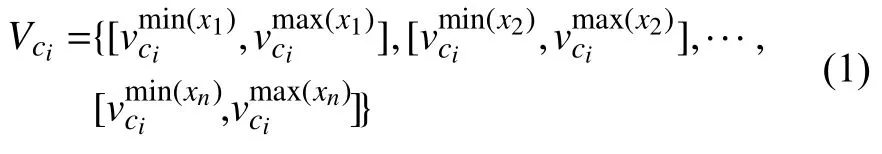
定义2.设a=[a1,a2],b=[b1,b2],设,表示区间中最小或最大数,L为区间a,b中区间长度的较大值,则区间a,b之间的相关度:
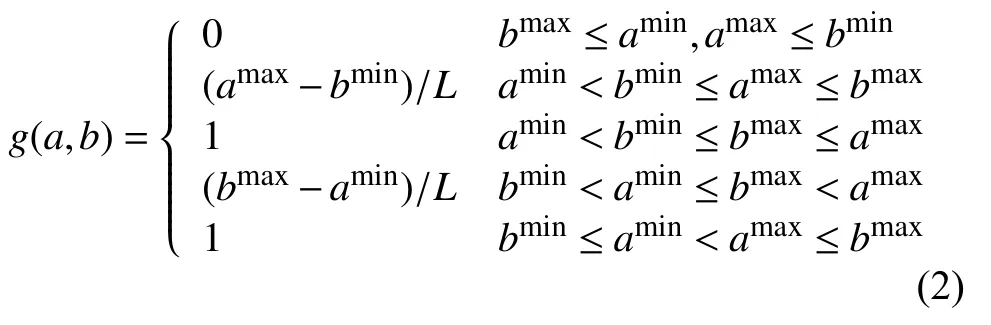
定义3.Chi-square是一种度量离散化数值型数据的统计量

其中,p表示目标属性个数,Aij表示第i个区间中第j个目标属性的实例数;Eij表示第i区间中,第j个目标属性出现频率(期望).
为克服相似区间长度不固定且区间长度相差较大问题,基于相关度离散化区间属性;本文采用Chisquare度量条件属性和目标属性之间关联程度,即两相邻区如果存在相似目标属性频率分布则合并为同一区间,即计算相邻区间 χ2值,合并χ2值最小的相邻区间,迭代合并直到满足终止条件.具体描述如下:

算法1.融合相关度和Chi-square统计量的属性离散化算法① 根据对象 在属性 的取值特点(区间数长度和相邻区间的交叉x ic j

新段落大小),定义相关度 ;U={x1,x2,··,x n}c jg j② 对象属性上的取值排序,记为;U(c j)c j U(c j)={x1(c j),x2(c j),··,x n(c j)}③ 遍历 比较相邻对象 ( )g(x(c j)x i(c j)1≤i≤n若,继续遍历;g(x(c j)i,x(c j)i+1)>g j若,决策相同继续遍历;g(x(c j)i,x(c j)i+1)≤g j且f(x(c j)i)=f(x(c j)i+1)若i,x(c j)i+1)≤g j且f(x(c j)i)≠f(x(c j)i+1),添加断点( 区间最小值);x(c j)i,x(c j)i+1④ 按遍历取断点从小到大排序实现连续数据离散化;选取显著性水平并结合自由度( ),确定 统计量阈值 ;χ 2 r(d)-1 c jχ 2 j⑤ 计算连续数据离散化相邻区间 统计量,如果大于 ,则相邻区间合并;χ 2 χ 2 j⑥ 按⑤循环迭代合并直至满足:相邻区间 统计量大于阈值 或最终保留区间个数.χ 2 j
1.2 基于相容矩阵的属性约简算法
由于生理监测数据涉及较多属性,且容易存在部分条件属性(如心率、血氧)取值有遗漏或缺失,需要降低原始数据集维数,同时避免组合爆炸和提高属性约简效率.在保证一定的正确分类率 α的前提下,尽可能缩小属性约简的搜索空间.
定义4.对于决策表S=(U,R,V,f),对于 ∀ α ∈(0.8,1],决策属性集D与条件属性集C的基于参数 α的分类率为

其中,CαYj表示决策类Yj相对于条件属性集C的 α下的近似值,α参数放松S=(U,R,V,f)对近似边界的要求.
定义5.条件属性C的相容矩阵定义如下:

其中,若条件属性的取值有遗漏或缺失,*记为遗漏属性值.
定义6.对于决策表S=(U,R,V,f),P,Q是条件属性集合的两个子集,相容矩阵的交运算定义为:

下面给出基于相容矩阵的属性约简算法:首先,采用间接处理方法将不完备数据转化成完备数据;其次,将决策表中条件属性的所有组合形式用二进制编码表示,即“1”表示属性出现,“0”表示属性不出现;然后,比较二进制表示的组合属性集与条件属性的分类质量,如果相等则该组合属性作为候选集合一行;最后,根据准则删除那些子集已经是约简的行以及全为零的行.

算法2.基于相容矩阵的属性约简算法输入:决策表,是属性集合,子集合 和 分别为条件属性集 和决策属性集 ;为条件属性的个数;分类率C S=(U,R,V,f)R=C∪DCD C={c1,c2,··,c m}D={d}mα输出:最小约简属性集① 采用相容矩阵并基于启发式算法[13]将不完备决策表 转化为完备数据集;C={c1,c2,··,c m}S=(U,R,V,f)② 将条件属性 所有组合形式通过二进制编码表示;···,2 m-1③ 计算编码j=1,2,所对应的属性组合 在参数 条件下的分类质量C jα β C jβ C j=■■■■■■■■∪Y j∈U/D Cα Y j|U|(7)■■■■■■■■④ 如果 ,则用属性组合 代替属性集 ,即 ;重复步骤②;Cβ C j=β CC jC C=C j⑤ 删除冗余及全为零的行,形成最小约简属性集 .
1.3 批量和增量相结合的分类规则挖掘
生理监测数据具有典型增量数据特点,分类规则可以对未知数据预测,由于分类规则强调准确性、速度、健壮性和伸缩性,因此确定最优分类规则集合至关重要.按照定义1,决策表S每一行对应决策规则,存在r(d)个决策规则,可以表示为:

记为CU→DU,可以定义规则强度、确定度和覆盖度因子.
定义7.决策规则CU→DU规则强度、确定度和覆盖度分别为:

其中,|·|运算表示集合基数.

算法3.基于批量和增量相结合的分类规则挖掘算法CD S=(U,R,V,f)① 根据生理监测数据确定对象的条件属性 和决策属性 ,决策表,选取生理监测数据集 ;D a t a0 D a t a0② 对 进行预处理,融合相关度和C h i-m e r g e统计量的属性离散化连续属性值;基于相容矩阵约简属性,得到数据集 ;③ 调用基于粗糙集分类算法[14]得到一组最优的分类规则集并保存在分类规则库中;D a t a C

④ 读取增量数据集并进行预处理(融合相关度和C h i-m e r g e统计量的属性离散化),得到 ;如果增量数据集为空,跳转到⑥;D a t a C D a t a C⑤ 用当前分类规则库中的规则对 进行分类,如果达到预期效果 (规则强度、确定度和覆盖度),则将 与 合并,跳转到④;否则执行③;⑥ 输出当前分类规则集.D a t a CΔ D a t a C D a t a C=D a t a C∪Δ D a t a C
算法3采用顺序覆盖策略,每学习一个规则可删除该规则覆盖数据;对其它数据重复该过程直到终止条件,即没有训练样本/返回的规则的分类质量低于预期效果(规则强度、确定度和覆盖度).
为提高慢性病变智能分级的准确性,特别是针对大规模生理监测数据,需要发挥云端并行化处理优势.MapReduce并行化框架通过对数据集的大规模操作分发给网络上的每个节点;每个节点会周期性返回所完成的工作和最新状态.用户只需编写Map函数和Reduce函数,即可实现大规模数据并行处理.慢性疾病智能分类及预测的完整过程:实时监测获取生理数据;经过融合相关度和Chi-merge统计量对连续属性离散、基于相容矩阵的属性约简算法降低原始数据集维数以及基于批量和增量相结合的分类规则挖掘;在线生理监测数据利用上述分类规则聚类,确定病例智能分级.
2 实验
厦门理工学院自主研制云健康监测系统Cloud-Health,该系统基于 Android 4.1.2,jdk1.7,基于 Bluetooth协议连接人体生理参数采集终端,并支持2G、3G、4G、WIFI等连接云平台.Cloud-Health实现心电、心率、血压、血氧饱和度和血糖在线监测,并根据慢性疾病智能分类及预测的结果,进行膳食推荐、运动推荐和就医服务推荐.Cloud-Health支持联接厦门市“健康医疗云”,该医疗云支持与各类健康管理终端对接,已实现体重、体温、血压、血糖、心电、血氧、血脂等14项生理指标的收集,已建立个人健康档案330余万份,占90%常住人口),最终满足居民慢性病变智能预警和突发状况救治的需要.图1展示云健康监测系统的主界面及心电监护界面.
实验数据取自厦门市集美区110198条健康监测数据.每条数据包括个人资料(年龄、性别、民族、婚姻、学历)、生活偏好(抽烟、喝酒、锻炼、睡眠时间等)、常规体检数据(身高、体重、腰围、臀围)和监测数据(心电、心率、血压、血氧饱和度和血糖),样本平均年龄64.9岁.糖尿病(Diabetes)数据共40个条件属性、高血压(Hypertensive disease)数据共35个条件属性、冠心病 (Coronary heart disease)数据共 35 个条件属性;健康风险就是决策属性(H高等风险、M中等风险和L低等风险).

图1 云健康监测系统
以糖尿病数据为例,运用基于粗糙集的慢性病变分级方法,融合关联度和Chi-merge统计量对数据连续区间离散化,得到初始属性40个、初始断点数123;基于相容矩阵的属性约简(正确分类率 α=0.9),得到剩余属性9个、断点数16个.表1给出慢性病(糖尿病、高血压、冠心病)主要属性.
表2展示部分糖尿病数据分级预测结果.采用批量与增量相结合的分类规则挖掘,得到12条规则;基于MapReduce框架运用规则库实现分级预测.记年龄(c1),身体质量指数(c2),腰臀比(c3),吸烟(c4),甜食(c5),血氧饱和度 (c6),心率 (c7),血糖 (c8),收缩压 (c9),健康风险类别(d),部分规则示例如下:

对x1数据运用规则R1:57岁,男性,身体质量指数BMI值为 26.9(中国标准:[24,27.9],偏胖),有吸烟史、喜欢甜食,血氧饱和度 SpO2 值 92%(中国标准:<94%,供养欠缺),心率 (中国标准:[60,100],标准),血糖(FBG)值范围 (6.98,7.48] (中国标准:空腹全血血糖FBG≥6.7毫摩尔/升两次可诊断为糖尿病);收缩压(132,136] (中国标准:≥140 mmHg,高血压),经分类规则判定为高等风险(H).对x7数据运用规则R3:54岁,男性,身体质量指数BMI值为24.1,有吸烟史、喜欢甜食,血氧饱和度 SpO2 值 91%,心率 (76,83],血糖(FBG)值范围 (6.7,7.06];收缩压 (145,157],经分类规则判定为低等风险(L),医生综合诊断后更倾向于高血压(低等风险L).该方法识别准确率89.23%、误识率10.77%,其根本原因在于生理监测数据具有时间连续性、非精确性、模糊性等特性.

表1 慢性病 (糖尿病、高血压、冠心病)主要属性

表2 部分糖尿病慢性病变分级结果
需要说明的是,虽然对于常见的慢性疾病(高血压、糖尿病和冠心病),使用基于粗糙集的慢性病变分级方法虽可以得到较好的预测结果.但限于数据等条件,该方法目前尚未完全发挥云计算技术在大数据分析和挖掘中的优势.如果在云端平台采用多种数据挖掘方法对生理监测数据进行协同分析,可以提高慢性病变分级和诊断的精确度.
3 结论与展望
目前传感器网络、云计算和大数据技术正逐步应用到智慧医疗领域.云健康监测利用附着人体的智能生理参数传感器获取人体生理数据,并上传到健康医疗云端,是智慧医疗领域未来发展方向之一.为满足居民慢性病变智能预警和突发状况救治需要,根据生理监测数据的时间连续性、非精确性和模糊性等特点,本文提出一种基于粗糙集的慢性病变分级方法,即首先采用融合相关度和Chi-merge统计量离散化生理监测数据;然后,基于相容矩阵的属性约简算法去除数据冗余属性;最后,基于批量与增量相结合挖掘分类规则,基于分布计算框架MapReduce运用规则实现慢性病变智能分级.该方法有利于帮助个体全面认识健康状况和病变风险,有助于“健康医疗云”走入家庭慢性疾病监护领域,有利于缓解目前医疗资源紧缺现状.
下一步工作包括:提高云健康监测中慢性病变分级的识别率,包括:提高生理监测数质量,充分考虑降低数据的缺失值比率;完善云健康监测系统的功能,展开示范性应用和推广.
