基于卷积模型的农业问答语性特征抽取分析
2019-01-05张明岳吴华瑞朱华吉
张明岳 吴华瑞,2 朱华吉
(1.国家农业信息化工程技术研究中心, 北京 100097; 2.北京农业信息技术研究中心, 北京 100097;3.农业农村部农业信息软硬件产品质量检测重点实验室, 北京 100097)
0 引言
问答社区是基于互联网,以用户提出问题、回答问题和讨论问题为主的知识服务社区,能够更好地满足互联网用户获取信息和交流知识的需求,是目前自然语言处理(Natural language processing,NLP)和信息检索(Information retrieval,IR)领域备受关注、具有广泛发展前景的研究方向[1-2]。“中国农技推广APP”作为服务于农技人员的专业平台,用户每天在农技问答模块发布的提问有上万余条,这类文本具有稀疏性、实时性、不规范等特点,加剧了问题文本关键词特征的稀疏化,难以充分挖掘特征之间的关联性,如何从数据集中方便、快捷地挖掘有效信息并提供更高质量和智能化的农业信息服务已成为农业信息分类领域文本挖掘的主要任务之一。传统的人工筛查需要消耗大量的人力、物力,并且很难高效地完成对无效冗余数据的处理。目前常用的人工特征分类及浅层分类学习模型虽然能够辅助完成数据筛查及剔除等工作,但由于其过分依赖人工选取特征和分类器性能,不具备从数据中自动抽取和组织信息的能力,导致经典的文本分析方法在短文本处理上的适用性下降[3-4]。因此利用计算机实现农技冗余问答自动、智能筛查是“中国农技推广APP”需要解决的一个重要问题。神经网络模型具有灵活性和多样性的特点,在序列标注[5]、语义匹配[6]、情感分析[7]等自然语言处理任务中表现出较好的性能,由于该类模型能够以端到端的方式进行训练,自动学习特定任务并挖掘文本内的大量语义关系,有效减少了传统的统计机器学习方法中人工设定大量特征等相关工作[8]。
目前结合神经网络模型开展自然语言处理的相关应用已经取得了一定成果,其中卷积神经网络(Convolutional neural network,CNN)在情感分析和文本分类领域得到很好的应用[9-12]。由于农业领域一直缺乏大规模可用的数据库,因此关于这方面的研究还较少,只有个别研究者针对农业特定领域研究神经网络模型在农业问答系统的应用,但仍处于起步阶段。赵明等[13]构建了基于Word2vec和双向门控循环单元神经网络(Bi-directional gated recurrent unit,BIGRU)的番茄病虫害问句分类模型,对番茄病虫害智能问答系统用户问句进行高效分类。针对传统的句子相似度算法准确率较低的问题,梁敬东等[14]通过构建基于 Word2vec和长短期记忆网络(Long short-term memory,LSTM)的神经网络计算问句相似度,并在水稻常问问题集(Frequently asked question,FAQ)中的问句上进行验证,以提高系统回答的准确性。以上研究的开展为神经网络应用于农业知识问答系统提供了参考和可行性依据,但关于神经网络应用于文本多样性、情感极性等农业文本特征挖掘方面仍有不足,关于利用卷积神经网络检验农技推广提问数据的精确性和可靠性方面尚未见报道。
为了实现农技推广社区问答情感特征信息的有效挖掘和表达,本文利用基于卷积神经网络模型的知识自动化的方法,有针对性地引入农业词库字典进行中文分词和词向量表示[15],利用卷积神经网络提取文本情感表达作为文本特征向量,用于情感分类,并进一步针对其重要的结构参数和训练策略进行优化和改进,构建一种基于卷积神经网络的农业问答情感极性特征抽取分析模型,以实现农技推广提问的精确高效识别。
1 数据采集与预处理
1.1 样本采集
本文数据集来源于“中国农技推广APP”农技问答模块,以2017年8月上线到2018年4月产生的130多万条提问数据作为基础样本。由于人工标注百万级样本十分困难,参照文献[16-18]使用的文本分类数据集量级,根据月份选取8 000条数据作为试验样本集。其中人工标注有效及无效提问各3 000条作为学习数据集,用于卷积神经网络训练和优化参数验证,人工选择样例如表1所示。剩余2 000条样本数据作为模型效果验证的测试集,由于测试集是在训练集和验证集选取之后选取,已经较大限度地保证了训练与测试数据集文本的不重叠,因此可以将测试结果的平均准确率作为文本模型的识别效果评价指标[19]。
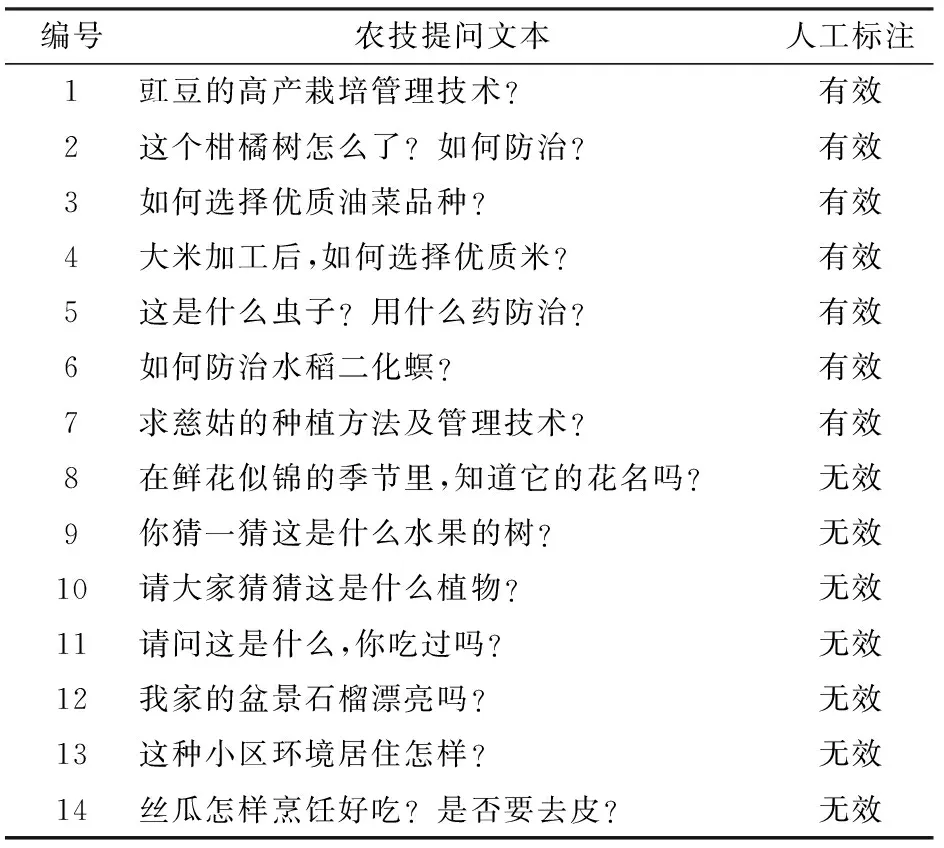
表1 人工选择样例Tab.1 Worked examples of manual annotation
1.2 数据集预处理
中文文本需要进行预处理转换为数字形式,以便能够被计算机识别。为最大程度地保留原始中文文本的特征及语义信息,减少信息损失,需要对文本进行去噪、分词、向量表示等预处理操作,主要步骤如图1所示。
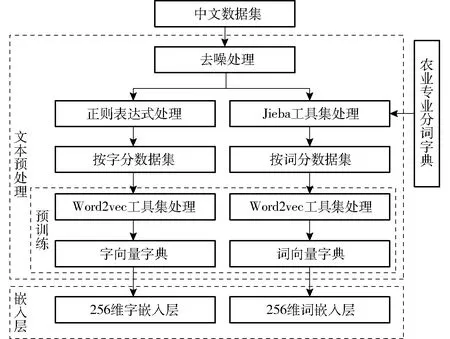
图1 数据预处理过程示意图Fig.1 Schematic of data preprocessing
(1)去噪:数据集中原始数据包含中文特殊字符、英文特殊字符、空格等多种类型的符号信息,不利于语性特征抽取。因此使用正则表达式对数据集进行去噪处理,仅保留中文、英文、字母、数字等通用特征信息。
(2)分字与分词:利用Python正则表达式对数据集中每条语句的汉字进行分割形成分字数据集。由于中文分词[20]主要依赖语义与语境,而农技提问又包含很多农业专业词汇,基础分词库很难满足要求,本试验还需要建立农业专业词汇的自定义分词字典。参照文献[21]选择搜狗农业词汇大全中的8 874个词汇作为农业专业分词字典,再利用Jieba分词工具包对数据集进行精确模式分词形成分词数据集[22]。
(3)生成词向量:使用Word2vec工具集的Skip-gram模型[23]对分字集和分词集进行预训练,具体操作方法是对文本中的字、词等元素的出现频率进行统计,通过无监督训练,获得作为语料基础构成元素的字、词对应的指定维度的向量表征,最终生成指定维度的字向量和词向量。
(4)文本向量化:为便于神经网络训练,文本数据需要转化为字或词嵌入,具体操作是将样本中每个字或词替换成对应的向量表示,将文本转化为向量组。对样本每条数据的字或词进行统计,选择字或词数最多的那条文本的字或词个数作为文本向量维度,其余提问长度不足的通过0来补齐。
2 基于卷积神经网络模型的农业数据筛查方法
自KIM[10]研究了利用卷积神经网络处理自然语言后,大量研究人员在其基础上做了拓展与优化,尽管文本分类模型变得越来越丰富,但所有模型的基本架构都与图2相近。基本思路是字或词经过嵌入层后利用不同神经网络结构提取局部、全局和上下文信息,经过全连接层合并到一起,最后利用不同分类器进行文本分类得到结果。

图2 文本分类基本架构Fig.2 Basic structure of text categorization
本文在基本架构基础上进行了拓展,增加了卷积层数以及更多尺度的卷积核,同时在激活之前增加了批标准化进行规范化处理,全连接层中也增加了批标准化处理,最后使用Softmax逻辑回归作为分类器,进行数据的语性特征抽取。
模型中卷积核的尺寸与数量对于CNN的性能至关重要。输入语料通过i个不同的卷积核卷积,生成j个不同的特征图,卷积层满足公式
(1)

f(·)——批标准化及激活函数
Mj——输入图像的特征量

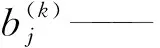
针对各层分布不均和精度弥散等问题,在进行激活之前使用批标准化(Batch normalization,BN)来规范响应,同时加快网络收敛,防止过拟合。具体公式为
(2)
(3)
(4)
yi=γi+β=BNγ,β(xi)
(5)
式中x——输入值
m——批量化的数目
γ、β——学习参数

ε——常量,用来保证值的稳定性
yi——结果输出值
BNγ,β(·)——批标准化函数
参考CLEVERT等[24]的试验,模型激活函数使用修正线性单元(Rectified linear unit, ReLU),公式为
f(x)=max(0,x)
(6)
根据文本分类的特性,需要在一定程度上降低卷积层参数误差造成的估计均值偏移所引起的特征提取的误差,试验选用Max-pooling作为池化方法。网络的训练阶段使用批量随机梯度下降法(Mini-batch stochastic gradient descend)。
本文使用Softmax逻辑回归来做特征分类器(对应Softmax loss损失函数),进行实际文本的语性特征抽取[25]。最终确定的卷积神经网络结构如图3所示。

图3 基于文本的卷积神经网络结构示意图Fig.3 Schematic of text-based convolution neural network
3 试验及结果分析
3.1 硬件及软件
本试验处理平台为联想台式计算机,处理器为Intel(R)Core(TM)i5-4590、主频3.30 GHz、内存8 GB、容量120 GB金士顿固态硬盘,运行环境为:Windows 10专业版 64位,软件环境为Python 3.6.5和Tensorflow 1.8.0。
3.2 试验操作流程
(1)输入层
输入层为经过预处理的256维词嵌入,对分词后数据集的词组个数进行统计,可以得到数据集中最多词数为58个,即每条提问的词向量维度为58×256。将输入数据顺序打乱并随机排列,选取前面90%(5 400条)作为训练数据,后面10%(600条)作为验证数据。训练次数设置为200次,每批次输入500条,共计输入2 200批次,图4为输入层中“植物”一词的向量示例。
(2)卷积层
卷积层的作用是特征提取,设置卷积核长度为58,窗口层数为5,每层窗口滑动尺寸分别是1~5,卷积核每个窗口特征映射数为200,所以第1层卷积核W1的尺寸为(1~5)×58×1×200,第2层卷积核W2的尺寸为(1~5)×58×200×200。
(3)池化层
池化层的作用是特征压缩,在进行池化前使用了批标准化进行处理。最后连接一个Softmax逻辑回归分类器,用于将压缩好的特征映射到输出层。S1对前面的特征图进行了最大池化操作,每批次得到500个1 000维的特征图。
(4)Softmax分类器
经过训练,最后剩下的神经元由Softmax分类器将其拼合成为一维列向量,全连接到输出层,计算出属于每类特征输出的概率值。
(5)输出层
比较分类器中计算出的语性特征概率值,将结果归类到概率最大的一组,然后合并归类结果并保存到prediction.csv文件中,识别结果样例如表2所示,表中“○”表示识别结果与真实值相同,“X”表示识别结果与真实值不同。
3.3 结果与误差分析
采用试验所描述的卷积神经网络结构使用训练样本来训练模型,网络权重初始化采用标准差为0.01、均值为0的高斯分布,样本迭代次数均设置为200,批处理尺寸设置为100,设置权重参数的初始学习速率为0.001,动量因子设置为0.9。对上述训练集做2 600次迭代训练,其训练曲线如图5所示。
从图5可以看出,随着迭代次数不断增加,模型分类误差逐渐降低。当训练迭代到2 000次时训练集的识别准确率最高达到98.6%,迭代到2 200次时验证集的识别率最高达到93.5%,且从第1 400次迭代以后训练集和验证集两者的误差差值趋于稳定,说明模型状况良好,卷积神经网络达到了预期的训练效果。由试验可以确定训练达到2 200次以后模型对样本的识别准确率趋于拟合,将训练次数设定为2 200能够使模型得到充分训练。

图5 迭代次数与识别准确率关系曲线Fig.5 Diagram of relationship between number of iterations and accuracy
为了验证不同类型嵌入层对模型效果的影响,分别使用字向量嵌入、词向量嵌入以及经过农业字典分词的词向量嵌入作为输入层,对试验模型进行2 200次的迭代对比训练,识别结果如图6所示。
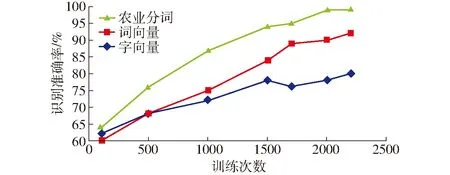
图6 不同嵌入层迭代次数与识别准确率关系曲线Fig.6 Diagram of relationship between number of iterations and accuracy in different embedded layers
由图6可以看出,随着迭代次数增加,各模型识别准确率均不同程度增加,当上涨到一定程度后各模型识别率趋于稳定。经过2 200次训练,词向量嵌入的识别准确率最高达到92%,字向量嵌入的识别准确率最高达到80%,经过农业字典分词的向量嵌入识别准确率是三者中最高的,接近99%。试验证明,输入层使用分词嵌入能够比分字更好地表达文本特征,针对所属领域使用专用的词汇进行细化分词后会更加充分地表达文本特征。
通过表3可以看出,增加卷积核滑动窗口个数以及窗口特征映射层数能够有效增加模型的识别准确率。当模型参数增加到一定程度后继续增加参数宽度和深度,模型的识别准确率很难继续提升,但模型需要的训练时间更长。通过模型参数比较,设定卷积核的窗口宽度为5、映射特征层数为200的训练模型能够在现有软硬件的条件下较好地满足试验要求。

表3 试验模型参数的比较Tab.3 Comparison of experimental model parameters
为了进一步证明提出方法的性能,将其与现有的JOHNSON等[26]提出的One-hot词表示法+CNN的文本分类方法、ASEERVATHAM等[27]提出的SVM分类器方法、DANTI等[28]提出的文档矢量空间表示模型(DVSM)+词间距离度量分类方法、ZHANG等[29]提出的KNN分类器方法以及使用Dropout代替Batch-Normalization执行标准化的CNN分类方法等5种文本分类方法进行比较,对测试集的2 000条提问数据进行识别,各种分类方法的筛选性能如表4所示。
通过表4可以看出,各类算法都能够对测试集进行有效的特征筛选,本文使用方法在6种算法中识别准确率最高,达到了82.7%。尽管文献[26]的方法也使用了CNN模型,但由于输入层使用的是One-hot方法,其准确率只达到68.2%,明显低于其他筛选方法,说明Word2vec的Skip-gram模型能够更高效地表示语料特征,也证明了输入层的文本处理方式对于模型训练结果存在较大影响。虽然文献[27]方法在测试集中的识别准确率比文献[28]方法高出1.1个百分点,但是精确率和F1度量值明显不如后者,这也间接说明相邻分词之间的关联语意对识别结果存在影响。使用Batch-Normalization规范响应相较于卷积神经网络常用的Dorpout标准化方法能够加快收敛,使训练更加充分,防止过拟合,显著提高识别准确率,识别准确率高出6.3个百分点。综合表4列出的各类文本分类方法,本文提出的基于CNN优化模型因为权值共享机制减少了网络中的可训练参数,有效降低了模型复杂度,具有更好的泛化能力,因此相较于其他机器学习模型取得了更好的分类效果[30]。卷积神经网络的核心特点是每个卷积层包含数个卷积核及大量特征面,通过池化操作大量减少模型中的神经元个数,增强了模型表达能力,因此对输入空间的平移不变特征更具鲁棒性,有效防止训练过拟合[31]。尽管卷积神经网络模型训练时间远高于表4其他分类方法,但通过权值共享、局部连接、批标准化增强、池化操作等使本文方法具有更少的连接和参数、更易于训练,具有自动抽取语性特征并且得到更多分类特征的特点。

表4 各种分类方法的比较Tab.4 Comparison of various classification methods
4 结论
(1)研究方法满足实际应用需求。通过卷积网络模型筛选数据,减小了人工筛查的工作强度,避免了传统识别方法中复杂的预处理和特征筛选过程,提高了算法优化效率,对测试集特征识别准确率达到82.7%。
(2)优化输入层表示及模型结构能显著提高识别效果。不同类型嵌入层对于筛选结果也有较大影响,使用农业专业词典进行分词处理的嵌入层在模型学习效率和识别准确率上都有提高。另外使用Batch-Normalization替换Dropout训练后识别效果相较于Dropout标准化的卷积神经网络识别准确率提升了6.3个百分点,对比其他类型的文本分类模型识别效果也具有明显优势。
