基于无监督学习的语音签到系统
2019-01-02赵从健,雷菊阳,李明明


摘 要: 针对语音签到系统在实际运用中识别率较低的问题,从提高对标签缺失数据的利用角度出发,提出一种利用无监督学习来提高识别率的方法。该方法基于深度置信网络隐马尔可夫混合模型(DBN-HMM),利用受限波尔茨曼机(RBM)为无监督学习提取特征参数,接着利用深度置信网络(DBN)得到对原始数据的观测概率。隐马尔可夫(HMM)据此通过前向算法求出数据的似然概率,并将概率值最大的类别作为识别结果。实验表明,使用DBN-HMM模型可以有效利用存在标签缺失的数据,提高语音签到系统的识别能力。
关键词: 语音识别;签到系统;无监督学习;DBN-HMM
中图分类号: TN912.3;TP183 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.12.041
本文著录格式:赵从健,雷菊阳,李明明. 基于无监督学习的语音签到系统[J]. 软件,2019,40(12):183187
Voice Check-in System Based on Unsupervised Learning
ZHAO Cong-jian, LEI Ju-yang, LI Ming-ming
(Shanghai University of Engineering Science, College of Mechanical and Automotive Engineering, Shanghai, 201620, China)
【Abstract】: Aiming at the low recognition rate of speech check-in system in practical application, this paper proposed a method, from improving the utilization of tag missing data, to improve recognition rate by unsupervised learning. This method was based on Deep Belief Network mixed Hidden Markov Model (DBN-HMM), used the Restricted Boltzmann Machine (RBM) to extract the characteristic parameters for unsupervised learning, then used Deep Belief Network (DBN) to get the observation probability of raw data. Based on this, Hidden Markov Model (HMM) calculated the likelihood probability of data by forward algorithm, and took the category with the largest probability value as recognition results. Experiments showed that DBN-HMM model could effectively utilize the data with missing tags and improved the recognition ability of speech check-in system.
【Key words】: Speech recognition; Check-in system; Unsupervised learning; DBN-HMM
0 引言
目前,國内高校、企业对考勤系统的要求不断提高,如何安全且经济地完成考勤成为一项研究课题[1-5]。传统的考勤方式,如人工点名、刷卡签到等方式存在他人代替、遗失和被盗用等风险[6]。因此,传统的考勤方式面临着严峻的挑战,与当今人工智能的发展越来越不协调。
语言作为人类最常用、最重要和最有效的交流载体,是最适合用来身份认证的方式之一。和其他方式相比,语音信号获取方便,人机交流时最自然和便利,而不基于固定文本下的语音识别具有很高的安全性[1-8]。过去的研究缺乏准确的模型,无法处理大量未经注释的数据,而深度学习的兴起为语音识别提供了强大的建模能力,提高了原始数据的利用率[9-12]。
语音识别本质上是模式识别的一种,签到系统下为非特定人群的识别,决定了特征选取的难度。深度学习中,相关的特征由网络训练后提取而出,特征向量高维且抽象但能更准确地表示模型[13-14]。文献[15]中,利用DBN作为特征参数的提取器可以降低GMM-UBM模型下的错误识别率。高维的特征向量、海量的数据加上复杂的深层神经网络结构,严重影响了深度学习在语音识别中的训练效率。文献[16]提出,利用重构方法来修剪深度网络的节点数,修剪后的训练速度提升了4倍以上。
对此,本文设计了一种无监督学习的语音签到系统。在利用MFCC和RBM对原始数据提取特征的基础上,引入DBN建立深层次的结构模型,提高模型概率观测的准确性。再将DBN网络得到的状态观测概率带入HMM模型用于签到识别。图1为语音识别流程图,先无监督学习再匹配识别。
图1 语音识别流程
Fig.1 Speech recognition process
1 语音处理
1.1 语音采集及预处理
课堂语音签到系统依赖含有大量学生信息的特定数据库,这些数据库中的语音信号主要记录了学生的音频特征。这些特征的选取需要有效区分、易提取、可靠和稳定地识别学生,目前完全满足这些特征是难以找到的,这里采用无监督学习的方式找到部分满足的特征。
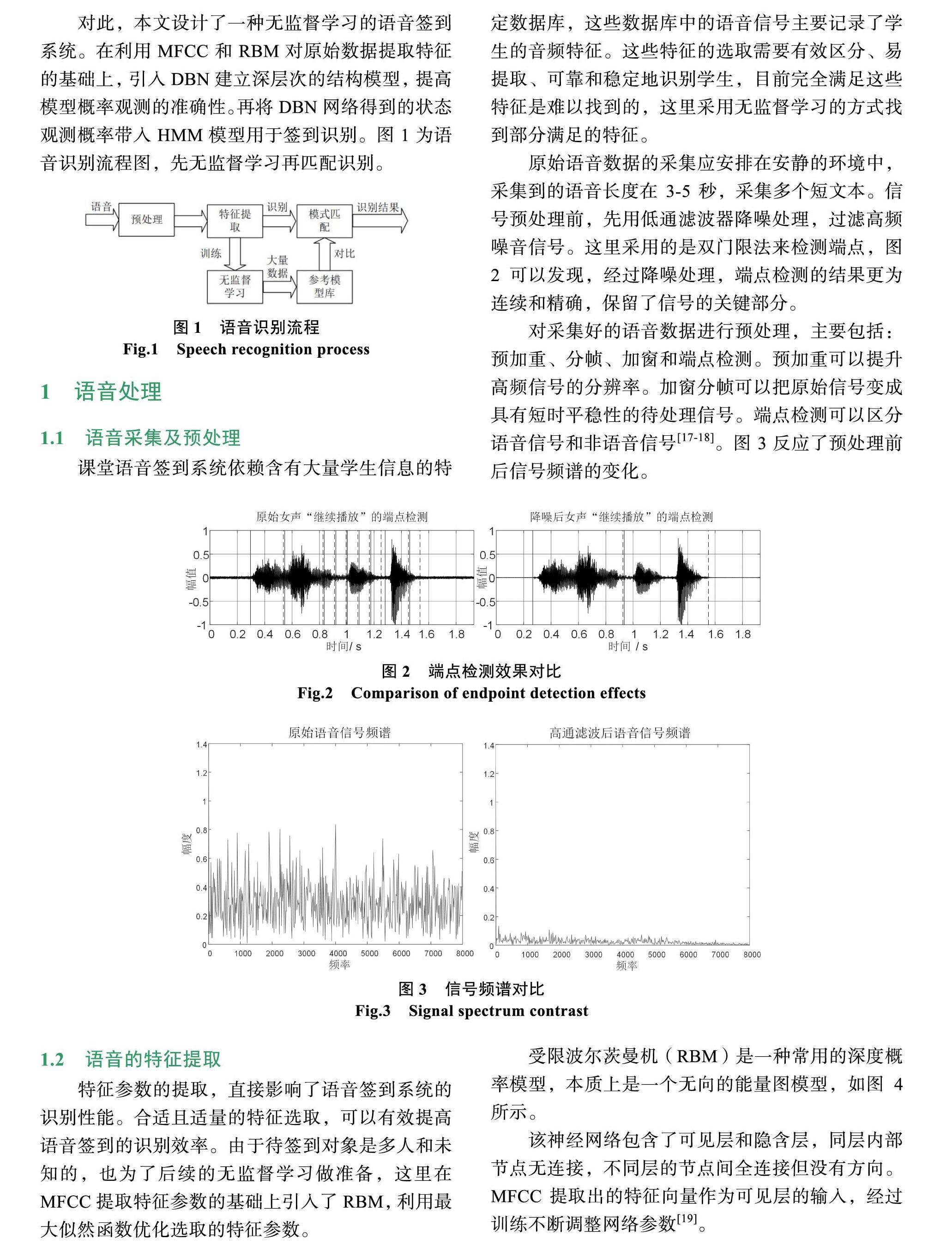
原始语音数据的采集应安排在安静的环境中,采集到的语音长度在3-5秒,采集多个短文本。信号预处理前,先用低通滤波器降噪处理,过滤高频噪音信号。这里采用的是双门限法来检测端点,图2可以发现,经过降噪处理,端点检测的结果更为连续和精确,保留了信号的关键部分。
对采集好的语音数据进行预处理,主要包括:预加重、分帧、加窗和端点检测。预加重可以提升高频信号的分辨率。加窗分帧可以把原始信号变成具有短时平稳性的待处理信号。端点检测可以区分语音信号和非语音信号[17-18]。图3反应了预处理前后信号频谱的变化。
图2 端点检测效果对比
Fig.2 Comparison of endpoint detection effects
图3 信号频谱对比
Fig.3 Signal spectrum contrast
1.2 语音的特征提取
特征参数的提取,直接影响了语音签到系统的识别性能。合适且适量的特征选取,可以有效提高语音签到的识别效率。由于待签到对象是多人和未知的,也为了后续的无监督学习做准备,这里在MFCC提取特征参数的基础上引入了RBM,利用最大似然函数优化选取的特征参数。
受限波尔茨曼机(RBM)是一种常用的深度概率模型,本质上是一个无向的能量图模型,如图4所示。
该神经网络包含了可见层和隐含层,同层内部节点无连接,不同层的节点间全连接但没有方向。MFCC提取出的特征向量作为可见层的输入,经过训练不断调整网络参数[19]。
图4 受限波尔茨曼机
Fig.4 Restricted boltzmann machine
假定數据集为S={s1,s2,s3,…,sns},其中的数据si={x1i,x2i,x3i,…,xji}(i=1,2,…,ns)由MFCC提取。则RBM网络参数更新式如下所示:
(1)
(2)
(3)
其中,Δw表示可见层和隐含层之间的权值矩阵,Δa表示可见层的偏置向量,Δb表示隐含层的偏置向量,P(h|s)表示的是可见单元为特定训练样本s时,对应的隐藏层概率分布。
2 基于DBN-HMM的语音识别网络
隐马尔可夫模型(HMM)现已成为了语音识别的主流技术,尤其在连续语音识别系统中无可替代。HMM模型依赖训练数据的状态标签,而实际训练中存在大量标签缺失的原始数据,影响识别效果。DBN是一种无监督学习算法,可以有效利用标签缺失的数据,其深层次的网络结构增强了对信号特征的建模能力,可以提供更准确的观察概率,结合HMM模型得到的状态转移概率矩阵,并将概率得分最大的类别作为语音识别的结果[20]。
2.1 DBN模型
DBN网络主要由多个RBM网络叠加而成,采用逐层无监督训练的方式。前一层RBM的输出作为下一层RBM的输入,逐层学习,最后再用BP算法对网络进行反向微调。
图5为DBN的网络结构图。其中每层的RBM包括了正向预训练阶段和重构阶段,BP算法为全局反向微调阶段。
利用交叉验证法将经过处理和标签的语音信号划分为训练集和测试集,再将训练集作为向量输入到DBN网络中训练。训练主要包括:DBN网络及参数的初始化;网络的预训练;全局的反向微调。
图5 DBN网络结构图
Fig.5 DBN network structure diagram
(1)DBN网络及参数的初始化
目前关于DBN的研究中,主要依据经验来选择网络深度和隐含层的节点数。由于在提取特征时使用了单层的RBM网络,将其隐含层的相关参数作为DBN输入层参数的预设值。 在确定网络深度、隐含节点数的过程中,还需要依赖重构误差的曲线来调整。重构误差主要对比的是原始数据和对其经过k次Gibbs采样后(RBM中的对比散度算法)的差异,其2-范数公式表达为:
(4)
其中,n为可视层的个数,m为隐含层个数,y为隐含层输出值,x为可视层输入值,q为取值个数或范围。
(2)网络的预训练
网络由多层RBM堆叠而成,整个预训练过程分为多个RBM的学习过程。从最底层的网络输入处理好的原始数据,每相邻的两层作为一个RBM网络进行无监督的学习过程。每次只训练一层,并将训练后的隐含层作为下一个RBM的可视层输入,最后一个RBM的隐含层作为整个网络的输出。
(3)全局的反向微调
每个RBM网络经过参数调优可以使重构误差最小,但整个DBN网络无法保证参数最优,此时结合BP对网络自顶向下进行有监督的反向微调,更新每层网络的参数。
2.2 基于DBN-HMM的语音识别
在图6中,DBN根据输入的特征向量数据学习训练,最后输出向量数据的后验概率P(s|h)。再利用贝叶斯公式,将其转化为状态的观测概率:
(5)
其中,P(s)表示状态s的先验概率,P(h)表示观测样本的先验概率。
图6 DBN-HMM模型
Fig.6 DBN-HMM model
DBN为HMM提供观察概率,再采用前向算法求出向量数据的似然概率P(H|λ),保留其中概率最大的类别,输出结果。
3 结果及分析
3.1 实验设计
为了实现语音签到系统的设计,现从中文普通话开源语音数据库AISHELL-ASR0009中选取一部分作为实验数据。数据由不同的10个人随机录入不同文本信息的10段语音,共100段3-5秒的语音数据组成。
为真实反映实验需求,对于选取的语音数据,男女各占一半,全为普通话但包含了南北的口音差异,每段语音均为随机不同的文本信息。实际建立语音签到数据库的过程中,还需要对每个已知个体建立对应的信息表,具体包括姓名、工号、性别、年龄等相关信息,这样可以确保区分开所有个体。由于本实验选取了小样本数据,现对每个个体标号以区分。
首先对原始的语音数据预处理;然后利用RBM对处理好的特征向量数据降维和提取;接着利用交叉验证的方式将数据分为训练集和测试集两部分;对于训练集,采用DBN-HMM网络学习和训练;最后用测试集验证和评价训练的结果。完整的训练流程如图7所示。
图7 训练流程
Fig.7 The training process
3.2 实验分析
为了提高RBM的学习训练能力,需要选择合适的网络参数,网络的训练性能可以用重构误差曲线来表示。图8反映了不同隐含节点数下网络的训练性能,适当增加节点数可以提升性能,过多的节点会增加计算量降低网络性能,由此确定隐含层节点数为30。
图8 不同隐藏层节点数下的重构误差曲线
Fig.8 Reconstruction error curves of
different hidden layer nodes
图9为不同网络深度下DBN的重构误差曲线,误差大小与RBM堆叠的数量有关,选取的数值为训练时有限次迭代后的平均数值。可以发现,当堆叠的RBM网络数为3时,网络拥有较低的重构误差。随着网络层数的增加,计算量增大,重构误差并没有随之降低,由此确定使用三层RBM堆叠的DBN网络。
实验所用不同的10个个体语音对应了不同的测试编号,这些编号可以帮助我们将语音库的所有个体完全区分开来。接着利用交叉验证的方法,将数据集拆分成训练数据和测试数据,这样可以使拆分后的小样本尽量可靠和稳定地反应原样本的分布规律。
图9 不同网络深度下的重构误差
Fig.9 Reconstruction errors at different network depths
表1为DBN-HMM与GMM-HMM对不同测试数据集的测试结果对比。可以发现,DBN-HMM的测试结果明显更高,这是因为DBN对信号特征建立了更深层的模型,性能强于GMM,可以为HMM提供更为准确的观察概率。
表1 两种方法下测试结果对比
Tab.1 Comparison of test results between the two methods
测试编号 DBN-HMM GMM-HMM
D0012 84.8 83.2
D0013 88.2 86.6
D0014 84.4 82.8
D0015 88.3 86.7
D0018 84.7 83.1
T0016 T00 87.4 85.8
T0017 83.1 81.5
T0019 84.1 82.5
T0020 88.3 86.7
T0021 81.9 80.3
TOTAL 85.5 83.9
结合图5、6以及表1的结果考虑,DBN模型是一个深度学习的模型,可以直接从原始信号中提取特征和识别,由于具有更深层次的模型建立能力,可以取得更高的识别精度。对于深度学习方法,计算量大,需要确定合理的参数和网络结构,在降低运算量和提高识别率中取得平衡。最后的测试结果也说明了,DBN-HMM用于语音签到系统中的优势明显。
4 结束语
本文对语音签到系统进行了研究,提出了一种可以无监督学习的混合模型,该模型对原始语音具有更深层次的建模能力,通过梯度上升算法和对比散度算法,可以在提高识别率的基础上降低算法的计算量。实验结果表明,该方法可行且具有一定优越性。
由于语音数据量、硬件设备缺乏、环境干扰影响等限制和能力的不足,我们并没有获得识别率在95%以上理想的DBN-HMM语音识别模型,如何在更复杂的环境干扰下,尽可能使用最少的语音数据学习训练是需要今后进一步研究的内容
参考文献
[1]王爱芸. 语音识别技术在智能家居中的应用[J]. 软件, 2015, 36(7): 104-107.
[2]刘星燕, 贾磊, 薛君彦. 浅谈张家口121语音答询系统几个常见问题的处理[J]. 软件, 2018, 39(1): 180-182.
[3]陈恒, 李宏达, 赵晓艳. 基于微信的大学课堂点名系统的设计与实现[J]. 软件, 2018, 39(3): 45-47.
[4]杨士卿. 基于B/S的一卡通会议签到系统设计与实现[J]. 软件, 2018, 39(5): 66-69.
[5]王芳, 蔡沂. 基于生成树的学生互校验签到应用研究[J]. 软件, 2018, 39(7): 06-11.
[6]阮超. 基于Android系统语音云记事本的设计与实现[D]. 安徽大学, 2016.
[7]陈硕. 深度学习神经网络在语音识别中的应用研究[D]. 华南理工大学, 2013.
[8]于俊婷, 刘伍穎, 易绵竹, 等. 国内语音识别研究综述[J]. 计算机光盘软件与应用, 2014, 17(10): 76-78.
[9]侯一民, 周慧琼, 王政一. 深度学习在语音识别中的研究进展综述[J]. 计算机应用研究, 2017, 34(08): 2241-2246.
[10]王海坤, 潘嘉, 刘聪. 语音识别技术的研究进展与展望[J]. 电信科学, 2018, 34(02): 1-11.
[11]杨俊安, 王一, 刘辉, 等. 深度学习理论及其在语音识别领域的应用[J]. 通信对抗, 2014, 33(03): 1-5.
[12]刘豫军, 夏聪. 深度学习神经网络在语音识别中的应用[J]. 网络安全技术与应用, 2014(12): 28-30.
[13]郭丽丽, 丁世飞. 深度学习研究进展[J]. 计算机科学, 2015, 42(3): 28-33.
[14]Deng Li. Industrial technology advances: deep learning from speech recognition to language and multimodal processing[J]. APSIPA Trans on Signal and Information Processing, 2016(5).
[15]Qian Yanmin, He Tianxing, Deng Wei, et al. Automatic model redundancy reduction for fast back-propagation for deep neural networks in speech recognition[C]//Proc of International Joint Conference on Neural Networks.[S.l.]: IEEE Press, 2015.
[16]Liu Yuan, Fu Tianfan, Fan Yuchen, et al. Speaker verification with deep features[C]//Proc of International Joint Conference on Neural Networks. 2014: 747-753.
[17]刘琦, 尹国祥. 基于Matlab的语音信号预处理技术研究[J]. 电子技术与软件工程, 2014(01): 62-63.
[18]张毅, 黎小松, 罗元, 等. 基于人耳听觉特性的语音识别预处理研究[J]. 计算机仿真, 2015, 32(12): 322-326.
[19]张建明, 詹智财, 成科扬, 等. 深度学习的研究与发展[J]. 江苏大学学报: 自然科学版, 2015, 36(2): 191-200.
[20]Yu Dong, Deng Li. 解析深度學习——语音识别实践[M]. 俞凯, 钱彦旻, 等译. 北京: 电子工业出版社, 2016.
