基于多尺度特征融合的小尺度行人检测
2019-01-02罗强,盖佳航,郑宏宇


摘 要: 随着无人驾驶技术的蓬勃发展,针对行人的检测成为一大难点,同时也是热点研究问题。而针对传统行人检测框架(One-stage和Two-stage等)对小尺度行人检测效果不佳的问题,本文在FPN网络基础上尝试了新的策略,致力于提高视频序列不同尺度行人的识别精度。算法先通过ResNet50提取特征,并采用FPN进行多尺度特征融合,同时利用RPN产生推荐区域,最后Fast RCNN对RPN产生的推荐区域实现分类与回归,经过非极大值抑制后处理等到最终结果。实验结果表明,本文基于FPN构建的行人检测算法,在CityPersons数据集上达到了11.88% MR,比基准模型Adapted Faster RCNN在小尺度行人检测上有较大提升,相比于传统检测框架能更好的检测不同尺度的行人。该技术可以广泛应用在智能视频监控,车辆辅助驾驶等领域中。
关键词: 卷积神经网络;小尺度;行人检测;FPN;特征融合
中图分类号: TP3 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.12.023
本文著录格式:罗强,盖佳航,郑宏宇. 基于多尺度特征融合的小尺度行人检测[J]. 软件,2019,40(12):100105
Small-scale Pedestrian Detection Based on Multi-scale Feature Fusion
LUO Qiang, GAI Jia-hang, ZHENG Hong-yu
(Computer Science and Engineering School, Nanjing University of Technology, Nanjing, Jiangsu 210000)
【Abstract】: With vigorous development of unmanned driving technology, pedestrian detection has become a major difficulty, and a hot research issue. To solve the problem of being ineffective of traditional pedestrian detection frameworks (One-stage and Two-stage, etc.) for small-scale pedestrian, the paper tries to improve pedestrian recognition accuracy of different scales in video sequence with new strategy based on FPN network. Firstly, the algorithm carries on multi-scale feature fusion based on ResNet50 feature extractration with FPN. At the same time, generate recommendation regions with RPN. Finally, carry on classification and regression for RPN generated recommendation regions with Fast RCNN, obtainfinal results after non-maximum suppression processing. Experimental results show pedestrian detection algorithm based on FPN achieves 11.88% MR on CityPersons data set, which is much better than small-scale pedestrian detection with benchmark model Adapted Faster RCNN, and can detect pedestrians of different scales better than traditional detection framework. The technology can be widely applied in intelligent video surveillance, vehicle assisted driving and other fields.
【Key words】: Convolutional neural network; Small scale; Pedestrian detection; FPN; Feature fusion
0 引言
近年來,随着人工智能的蓬勃发展,无人驾驶车辆的研究得到了重大发展。行人检测是无人驾驶车辆研究的一个重要课题,对于提升车辆感知周围行人的能力有重要影响。
目前,针对行人的检测技术还不够成熟,因为复杂场景下的行人检测面临着许多挑战,如尺度、外观姿态变化和遮挡等。第一点是在图像或者视频序列中所采集到的行人图像尺度范围分布较广,且常常存在较远处的小尺度行人,难以被识别,加大了行人检测的难度。第二点是行人的外观变化,即不同场景下往往行人具有不同的光照条件、衣着、姿态等,给行人检测带来了巨大的挑战。第三点便
是密集场景下行人的互相遮挡,使得行人检测算法很难做出较为全面的检测,限制了算法的精度。
本文主要研究的是行人检测小尺度问题。现实场景中在视频监控时行人的尺度变化范围较广,目前通用的行人检测算法不能很好的识别不同尺度的行人。本文在FPN网络基础上进行了新的尝试,致力于提高不同尺度行人的识别精度。本文的研究 使得小尺度的行人检测精度有了新的提高,理论上可以应用在智能监控、无人驾驶等领域精确的检测行人。
1 小尺度行人检测
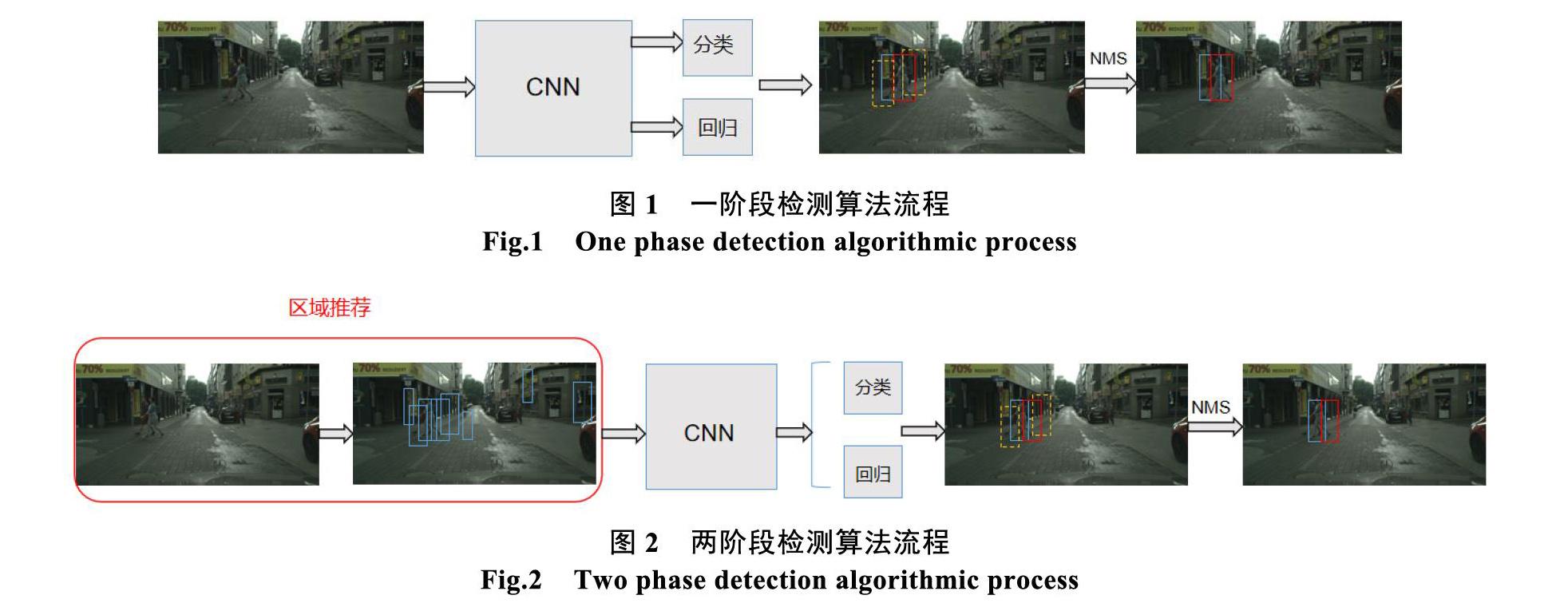
对图像中的物体进行识别和定位是计算机视觉领域的基础问题之一,作为目标检测的实际应用之一的行人检测,是利用计算机视觉技术判断图像或者视频序列中是否存在行人并给予精确定位的技术。基于深度学习的行人检测器可根据有无区域推荐过程分为一阶段检测器和二阶段检测器,还可根据是否依赖锚框分为Anchor-Based检测器和Anchor- Free检测器。
(1)一阶段检测器不依赖于区域推荐的过程,一般先定义一系列的先验框,然后由卷积神经网络从图像提取特征,利用提取的特征对先验框经过一次分类和回归,最后经过一次非极大值抑制算法进行后处理,去除多余的检测框,得到最终结果。由于算法流程简单,因此算法速度较快,但精度一般低于两阶段检测算法。例如YOLO[1]-[3]、SSD[4]等。
(2)两阶段检测器依赖于区域推荐的过程,由区域推荐算法生成推荐区域,然后由卷积神经网络从图像提取特征,利用提取的特征对推荐的区域进行分类和回归,得出精确的位置,最后经过一次非极大值抑制算法进行后处理,去除多余的检测框,得到最终结果。由于存在区域推荐和两阶段级联检测,两阶段检测算法精度上具有优势,但由于步骤繁琐,速度总体慢于一阶段检测算法。例如RCNN[5]、Fast RCNN[6]、Faster RCNN[7]等。
图1 一阶段检测算法流程
Fig.1 One phase detection algorithmic process
圖2 两阶段检测算法流程
Fig.2 Two phase detection algorithmic process
(3)Anchor-Free检测器不依赖于预定义的先验框,先由卷积神经网络从图像提取特征,然后分类分支对特征图逐点分类得到一个分类结果的热力图,由回归分支对特征图逐点回归得出尺度和偏移量信息,最后通过后处理,得到最终的检测结果。例如CSP[8]等。
图3 Anchor-Free检测算法流程
Fig.3 Anchor-Free detection algorithm process
1.1 算法流程
1.1.1 特征提取与融合流程
(1)特征提取
FPN算法[10]使用的主干卷积神经网络为ResNet50[9]。ResNet主要解决的是训练深层神经网络困难的问题,其通过在网络中加入跳层连接引入恒等映射,使得深层网络更容易学得恒等映射,使得在适当的时候,网络可与浅层网络达到近似的效果,使得一般情况下深层神经网络至少不会产生比浅层神经网络更高的错误率,同时也降低了优化网络的难度,并且解决了梯度消失的训练问题。ResNet50即为拥有50层卷积的ResNet,其中还引入了Bottleneck结构,通过1x1的卷积来降低运算量,从而加速计算。ResNet50共有五个阶段,特征提取时,第一到第四阶段的特征,分别取名为C2-C5,通道数为256,512,1024,2048,C2-C5全部输出作为下一步特征融合的输入。
(2)多尺度特征融合
FPN接收ResNet50的四个阶段的特征C2-C5作为输入,提供过引入横向连接,使用1x1卷积先将C2-C5的通道数全部统一降为256,得到LC2- LC5,然后将从LC5开始,先通过最近邻插值对其进行上采样,使得长宽扩大为原来的一倍,并与LC4进行逐点相加得到VC4,之后再将VC4上采样,与LC3逐点相加得到VC3,如此往复可得到VC2-VC4,同时令LC5为VC5,然后再利用3x3,填充为1的卷积逐一作用在VC2-VC5上进行进一步特征融合,得到P2-P5,最后再利用1x1,步长为2最大池化作用于P5得到P6。P2-P6为多尺度、高低层特征融合得到的特征金字塔,各层都具有较强的语义信息,同时整个金字塔具有不同的感受野,有利于尺度变化情况较大场景下的行人检测。
图4 算法流程图
Fig.4 Algorithm flowchart
图5 残差块
Fig.5 Residual block
图6 Bottleneck结构
Fig.6 Bottleneck structure
图7 多尺度特征融合
Fig.7 Multi-scale feature fusion
1.1.2 RPN区域推荐流程
(1)锚框计算
定义在特征图上一个点的锚框即为一组拥有相同中心点,但拥有不同的宽高比的矩形框,引入锚框可以作为坐标回归时的参照,从而降低坐标回归的难度。RPN接收到提取的特征后,根据预定义的一组尺度和宽高比参数为特征图上每一个点都计算
图8 锚框
Fig.8 Anchor frame
一组锚框,密集覆盖了整张图片。
(2)分类与回归
RPN接收到P2-P6的特征后,为每一级特征都先使用一个3x3卷积进行处理,然后由分类分支对特征图上定义的每一个锚框进行前景和背景二分类,同时还使用回归分支为每一个锚框进行坐标偏移量的回归,得出初步的坐标位置。分类分支和回归分支都仅由一个1x1卷积组成。
(3)后处理产生推荐区域
RPN对P2-P6的所有锚框进行了分类和回归后,分别对每一级产生的推荐区域进行一次非极大值抑制抑制处理,减少了大量的虚检,最后再综合各级检测结果,筛选前1000个置信度最高的框作为最终的推荐区域。
1.1.3 Fast RCNN
(1)ROIAlign
得到推荐区域后,ROIPooling操作可以根据输入的推荐区域和特征图对推荐区域进行特征提取对齐,输入到后一步的分类和回归。但由于ROIPooling存在两次量化操作,导致了一定程度上的特征对齐问题,因此影响了精度,而在MaskRCNN中提出的ROIAlign使用双线性插值操作,避免了量化,因此可以更好的进行特征对齐,因此在此处使用ROIAlign操作对推荐区域进行特征提取对齐。
由于存在P2-P6的多级特征,且靠近低层的P2、P3等具有较高的分辨率,较小的感受野,适合检测小物体,靠近高层的P5、P6具有较低的分辨率,较大的感受野,适合检测大物体,因此在此处根据每一个推荐区域的尺度大小,将其动态映射到适当的特征金字塔层级进行特征提取,更加有利于多尺度行人检测。
(2)分类与回归
推荐区域经过特征提取后,Fast RCNN[6]对其使用全连接层进行二次分类和回归,得出更加准确的分类结果和更加精确的坐标位置,进一步提升了算法的精度。
1.1.4 非极大值抑制后处理
经过了Fast RCNN的分类和回归后,仍然存在大量的虚检,而这些虚检的框往往与正确的框之间有很大的交并比(Intersection Over Union),因此可以预先设置一个阈值,并先将所有检测框按置信度由高到低排列,取出有最大置信度的框与剩余所有框计算交并比,若大于该阈值,则将其移除,并将高置信度的框加入到最终結果集合,反复执行贪心合并的过程,即可得到最终的检测结果。
1.2 FPN训练细节
1.2.1 迁移学习
我们使用在ImageNet上预训练过的ResNet50进行模型微调,并将其前两个阶段冻结,不进行参
图9 IoU计算
Fig.9 IoU calculation
图10 非极大值抑制之前
Fig.10 Before non-maximum suppression
图11 非极大值抑制之后
Fig.11 After non-maximum suppression
数更新。迁移学习被广泛运用在计算机视觉各个领域,它使得我们能在较小的数据集上加速收敛,并取得更好的结果。
1.2.2 数据预处理
对输入图片先进行归一化处理,然后以0.5的概率随机进行水平翻转,最后将其进行0填充使得高和宽为32的倍数。
1.2.3 锚框参数
根据对数据集的统计和行人宽高比的先验知识的综合考量,高宽比选择为2.44,尺度为8。
1.2.4 非极大值抑制阈值
过高的阈值会导致较多的虚检,而过低的阈值则会导致较多的漏检,经过实验考量,最终选择阈值为0.5。
1.2.5 优化参数
优化器选择为带动量的批量随机梯度下降,学习率初始设置为0.02。总共训练12轮,前500次迭代进行模型预热,将学习率从0.006逐步线性增长到0.02,并在第9轮和第10轮时将学习率分别调整为0.002和0.0002。
2 实验结果与分析
2.1 实验数据集
本次实验使用的数据集为CityPersons行人检测数据集[11]。CityPersons是在Cityscapes数据集的基础上进行精细的边框标注得到的一个具有多样且复杂场景的行人检测数据集。该数据集由训练集和验
表1 CityPersons数据集组成
Tab.1 Composition of CityPersons data set
Train Val. Test Sum
#cities 18 3 6 27
#images 2975 500 1575 5000
#persons 19654 3938 11424 35016
#ignore regions 6768 1631 4773 13172
图12 CityPersons数据集
Fig.12 CityPersons data set
证集以及测试集组成。本次实验在训练集上进行训练,在验证集上进行实验效果评估,评估的标准为MR(Log Miss Rate Averaged Over FPPI Range Of [0.02, 1.00])。
2.2 实验环境
操作系统:Ubuntu16.04
GPU:GTX 1080TI 11G
CPU:I7-8700
GPU加速库:CUDA9.0
C++编译器:GCC5.5
编程语言:Python3.6
深度学习框架: PyTorch1.1
2.3 实验结果
本次实验的基准模型为Adapted Faster RCNN,如图13所示。
2.4 实验结果分析
从实验结果1和2的MR_Resonable指标可看出,在1x分辨率下,FPN达到了15.4%MR,略高于基准模型Adapted Faster RCNN,从MR_Resonable_ small指标来看,FPN在小尺度数据子集上达到了21.38% MR,大幅领先于基准模型Adapted Faster RCNN,这表明了经过多尺度特征融合后的FPN检测算法在小尺度行人检测上的优越性。
由實验结果2和3可得出,在高宽比的选择上,2.44由于更加符合人体的结构,使得先验框更加贴近目标对象,降低了检测的难度,因此也取得了更好的结果。
由实验结果2和4可得出,在FPN多尺度特征融合过程的特征选择上,P2由于感受野过小,在ROIAlign操作中的特征图匹配过程中并未起到太大的贡献,使用的价值并不大,去掉P2之后,模型得到了一定的提升。
图13 CityPersons实验结果
Fig.13 CityPersons experimental results
在经由对原图进行1.3倍上采样后,从MR_ Resonable指标可看出,使用单个宽高比2.44的FPN依旧领先于基准模型Adapted Faster RCNN,同时在MR_Resonable_small指标上,FPN依旧具有较大的优势。
为了进一步提升FPN的表现,在实验7,将图片分别进行1.2倍、1.3倍、1.4倍的上采样,构成图像金字塔进行多尺度测试,最后将所有的检测结果通过非极大值抑制进行融合,进一步提升模型的精度,此时模型达到了最高的精度11.88% MR。
2.5 行人检测效果展示
在CityPersons数据集上实验部分结果如图14所示,本文提出的小尺度行人检测算法能够较好的检测不同尺度的行人。
图14 效果图
Fig.14 Design sketch
3 结论
本项目实现了基于FPN的行人检测算法,在CityPersons数据集上达到了11.88% MR,相对于基准模型Adapted Faster RCNN在小尺度行人检测上有较大提升,对多尺度场景下行人检测具有一定的改进。利用该技术可以在智能视频监控,车辆辅助驾驶和人体行为分析等应用中发挥非常突出的作用,同时也可应用于航空拍摄照相,自然灾害受害人员营救等领域,具有广阔的应用前景和较高的使用价值。
参考文献
[1]Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[2]Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C] //Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7263-7271.
[3]Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[4]Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector[J]. 2015.
[5]Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[6]Uijlings J R R, Van De Sande K E A, Gevers T, et al. Selective search for object recognition[J]. International journal of computer vision, 2013, 104(2): 154-171.
[7]Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]// Advances in neural information processing systems. 2015: 91-99.
[8]Liu W, Liao S, Ren W, et al. High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 5187-5196.
[9]He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[10]Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2117-2125.
[11]Zhang S, Benenson R, Schiele B. Citypersons: A diverse dataset for pedestrian detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3213-3221.
