基于YOLO模型的红外图像行人检测方法
2019-01-02谭康霞秦文虎
谭康霞,平 鹏,秦文虎
(东南大学仪器科学与工程学院,江苏南京210096)
1 引 言
基于机器视觉的行人识别技术作为车辆辅助驾驶系统的重要部分,可以辅助机动车驾驶员及时预见事故的发生[1]。针对传统可见光摄像机在夜间识别率低、易受光线变化以及其他光源影响等问题,利用远红外夜视摄像头[2]的夜间行人识别技术,可以有效地提高夜间驾驶和行人的安全性。
针对红外图像中的行人检测,传统的研究方法主要有基于阈值分割的方法[3],基于模板匹配的方法[4],基于帧间差的方法[5],但这些方法都存在鲁棒性不好的问题,在复杂场景下红外图像行人的识别率较低。因此,一些学者将特征提取方法与机器学习结合来进行行人检测,在Dalal[6]等提出的梯度方向直方图(Histograms of Oriented Gradient,HOG)特征基础上,Kim[7]等针对远红外图像的单调灰度级变化特性,提出局部强度差异直方图(Histogram of Local Intensity Differences,HLID)特征,然后用支持向量机(Support Vector Machine,SVM)对该特征进行分类学习。然而,特征提取与机器学习结合的方法通常使用滑动窗口法遍历整幅图像,产生大量检测窗口,检测速度较慢,并且,这些行人检测方法匹配的特征主要是形状轮廓、颜色模式等特征。由于红外图像存在像素低、噪声高、图像模糊以及纹理特征不明显等特点[8],这些方法对红外图像行人检测的效果并不十分理想。
目前,深度学习在目标检测领域取得了突破性进展[9-12]。 Joseph Redmon[13]等则基于深度卷积神经网络构建完成端对端的实时目标检测模型YOLO,在保证识别准确率的同时,大幅提高了检测速率。
基于之前的研究基础和技术发展趋势,本文利用YOLO模型来实现驾驶辅助系统中夜间红外图像的行人检测。针对红外图像行人检测的传统方法不易检测到远处较为微小的行人且目标检测速率慢的问题,本文改进YOLO网络模型的输入分辨率,然后在基于实际道路采集的红外数据集上进行训练,保证检测速率的同时,不断提高检测准确率,得到效果最好的模型参数。在此模型基础上,本文还探讨车速与输入图像分辨率的关联,建立分辨率与车速的关联模型,使行人检测系统能适应不同车速以发挥最大性能。
2 基于YOLO的红外图像行人检测
2.1 YOLO网络
与其他使用滑动分类器的CNN网络结构相比,YOLO是可以同时预测目标位置、大小以及类别的统一网络,是基于深度卷积神经网络的实时目标检测系统。由于YOLO网络具有端对端的特点,从数据输入到结果的输出,整个训练和检测过程都在网络模型内完成,所以它在保证准确率的同时,也展现出较快的检测速度。如图1为YOLO识别系统。

图1 YOLO识别系统Fig.1 YOLO detection system
YOLO网络把图像划分成7×7个网格,如果某网格的中心内落有某目标物体的中心,则这个网格的任务就是检测该物体。每个网格预测出目标的边界框(Bounding Box)和相应的置信度(Confidence)。置信度,即一种用来判断边界框是否包含物体以及物体位置是否正确的指标,通过图像交并比(Intersection Over Union,IOU)来计算。 IOU为Bounding Box与物体真实区域(Ground Truth)的交集与两者并集之比。Confidence和IOU的计算公式如下:
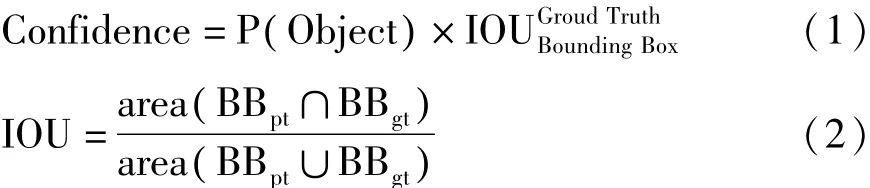
P(Object)为边界框包含目标物体的概率,如果预测框和真实值百分百重叠,P(Object)=1,则置信度为1;相反,如果网格中不存在预测框,预测框和真实值没有重叠部分,P(Object)=0,置信度为0;BBgt为基于训练样本标注的目标真实区域,BBpt为预测的目标物体的边界框,area为指定图像区域的面积。YOLO在训练过程中检查整个图像以学习其目标物体的给定类别和其背景的上下文信息。
YOLO的网络结构中有24个卷积层和2个全连接层,通过穿插1×1的卷积层来减小前一层产生的特征空间。因为全连接层输入输出的特征向量必须为固定长度,所以YOLO只能接收固定尺寸的输入图片;另外,由于YOLO采用7×7的网格,且每个网格最多只能预测出2个物体,如果一个网格中出现多个目标物体,则无法检测出来,因此该网络对图像中远距离较为微小的目标的检测能力较弱。
2.2 改进的YOLO网络结构
YOLOv2模型在YOLO基础上改进而来。YOLOv2的改进主要是将YOLO的全连接层删除,并采用固定框(anchor boxes)来预测边界框,模型中只含有卷积层和池化层,因此YOLOv2对不同尺寸的输入图片都具有鲁棒性。另外,YOLOv2删除一个池化层来提高卷积层的输出分辨率;再修改YOLO网络输入图像分辨率——由448×448改为416×416,使网络产生的卷积特征图的宽高都是奇数,从而产生一个中心网格,因为相对较大的物体通常位于图像的中心位置,这样的设计可以在一定程度上提高检测效率。YOLOv2还设置其卷积层的下采样率为32,因此网络输入图像分辨率应为32的倍数,在416×416的输入分辨率下,输出网格尺寸从YOLO的7×7提高到13×13。原本YOLO从一张图片得到预测框的个数为98,而在 YOLOv2采用固定框以后,每个网格预测9个预测框,那么有13×13×9个预测框,达到1521个,进一步提高了检测精度。
本文在YOLOv2网络结构的基础上进行模型训练。在本文的网络结构中,改变输入图像分辨率为480×480,则输出网格尺寸提高到15×15,使得最终特征图的尺寸更大,在YOLOv2_416×416基础上进一步提高了网络模型的对微小目标的检测能力。改进的YOLOv2网络结构如图2所示,其中有23个卷积层和5个池化层。

图2 改进的YOLOv2_480×480网络结构Fig.2 Improved YOLOv2_480×480 network architecture
2.3 基于车速的自适应图像分辨率的行人检测模型
当车速较低时,驾驶员行车制动安全距离短,因此不需要识别远处的行人目标;当车速较高时,行车制动安全距离较远[14],因此驾驶员需要及时预见远处的行人目标。
基于驾驶车速与制动安全距离的上述特点,本文在保证行人检测实时性的条件下(取40.5fps),本文提出通过调节图像分辨率来适应不同车速下的行人识别率需求并建立车速与输入视频图像分辨率的关联模型,以发挥行人检测系统的最佳性能:当车速较高时,提高图像分辨率,使系统不仅能识别图像中较大的近处行人还能识别到更远处较为微小的行人目标,以及时提醒驾驶员谨慎驾驶;当车速较低时,减小图像分辨率以减小系统的运行负担。
假设车辆夜间行驶的车速v范围为0~40 km/h,本文行人检测系统视频图像分辨率r×r的可调节范围为416×416至544×544像素,建立车速与分辨率的分段线性关系模型。
首先,建立车速与r的对应关系,如表1所示:

表1 车速与分辨率的对应关系Tab.1 The correspondence between the speed of the vehicle and the resolution of images
然后,建立车速与分辨率的关系式如下:
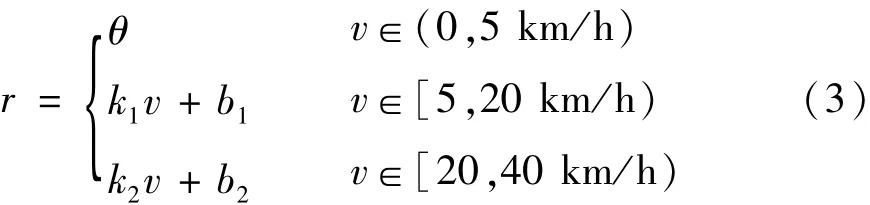
最后,将表1数据代入式(3)得到模型如下:

得到模型的对应关系曲线如图3所示。
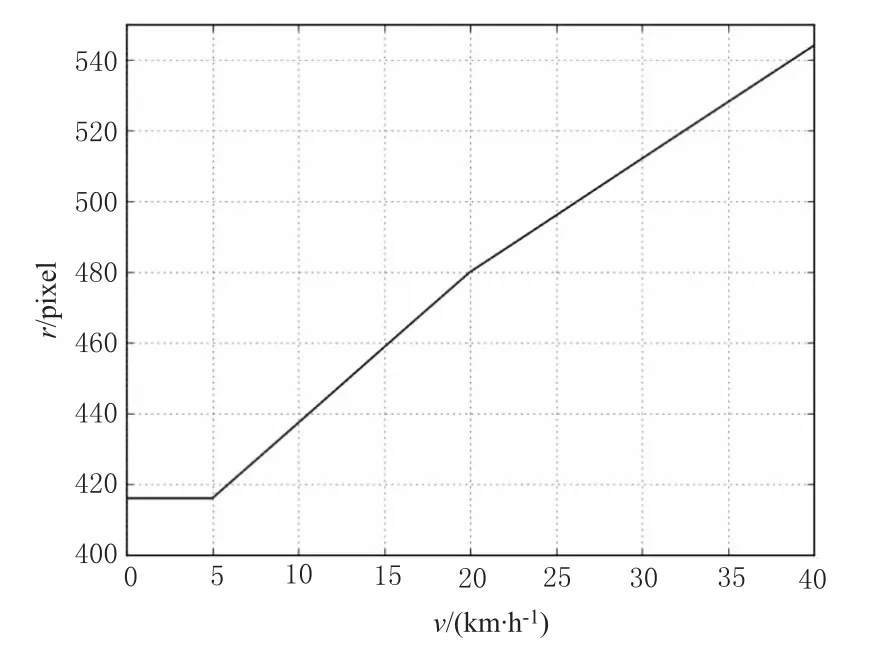
图3 基于车速的自适应图像分辨率模型关系曲线Fig.3 Relationship curve of adaptive image resolution model based on the speed of the vehicle
2.4 网络模型评价指标
本文用三个指标来衡量网络的质量:平均准确率(Average Precision,AP),图像交并比(Intersection Over Union,IOU),每秒传输帧数(Frames Per Second,FPS)。
第一个指标为平均准确率AP。首先,通过公式(2)计算预测框和真实值的交并比IOU,以此判断结果中的真正例(true positives)、假正例(false positives)和假反例(false negatives)的个数。当 IOU≥0.5,为真正例;IOU<0.5,为假正例;当 IOU=0,则为假反例。然后,通过测量分类的查准率(Precision)和查全率(Recall)来判断神经网络检测行人的效果,下式为计算公式:
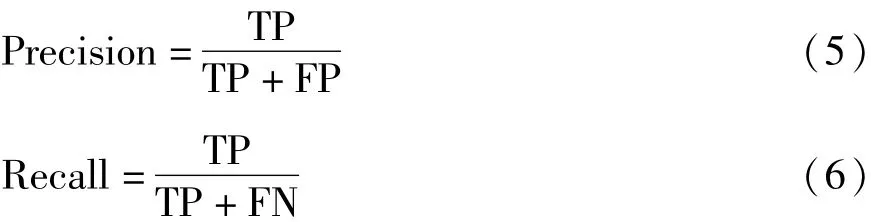
其中,TP、FN和FP分别为真正例、假反例和假正例的数量。通过调整目标检测综合得分的阈值从0%到100%,对测试集分别进行测试,得到不同阈值对应的Precision和Recall值,根据这些值绘制Precision-Recall曲线,并计算出平均准确率AP。AP为Precision-Recall曲线与x轴围成的图像面积,计算公式为:

其中,p为查准率Precision;r为查全率Recall。
第二个指标为图像交并比IOU,通过公式(2)计算可得,用于确定神经网络是否正确地预测了边界框的位置。
最后一个指标为每秒传输帧数FPS,用来验证卷积神经网络目标检测的处理速度。
3 实验
3.1 实验环境
本文采用深度学习架构YOLO-Darknet19搭建实验运行环境,并配置GeForce GTX TITAN Xp的CUDA环境进行GPU并行加速计算。具体的实验环境如表2所示。
3.2 数据集
3.2.1 数据集参数
由于本文提出的算法需要在车载环境下的道路上实施,适用的条件是车载道路上的夜间红外图像行人识别。为此,本文利用载有远红外摄像机的电动汽车在夜晚道路上行驶时拍摄所得红外视频,采集1698张红外图像作为自制标准红外数据集,其中随机选取1358张图片作为训练集,剩下的340张图像作为测试集。图4为自制标准数据集裁剪的行人样例。数据集参数如表3所示。
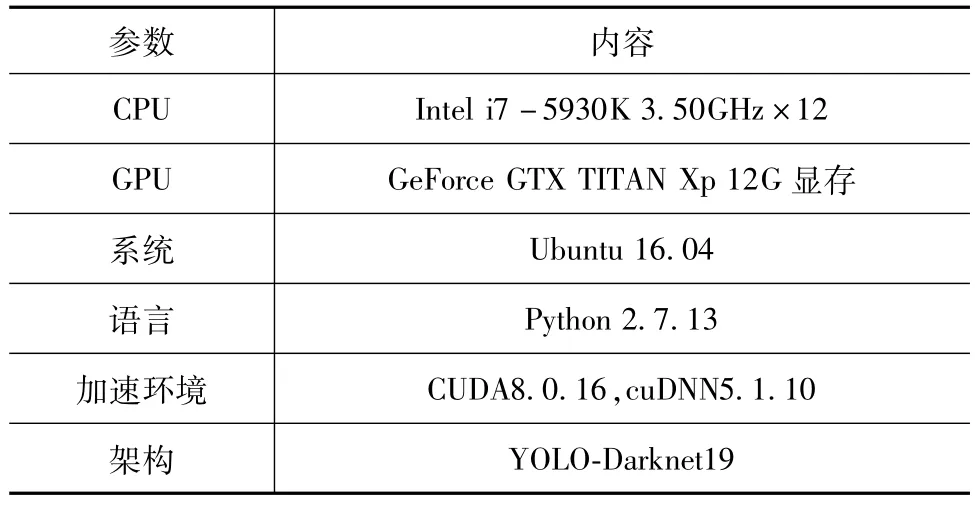
表2 实验环境Tab.2 Experimental environment

图4 红外数据集的行人示例Fig.4 Part of the pedestrian samples of the infrared dataset
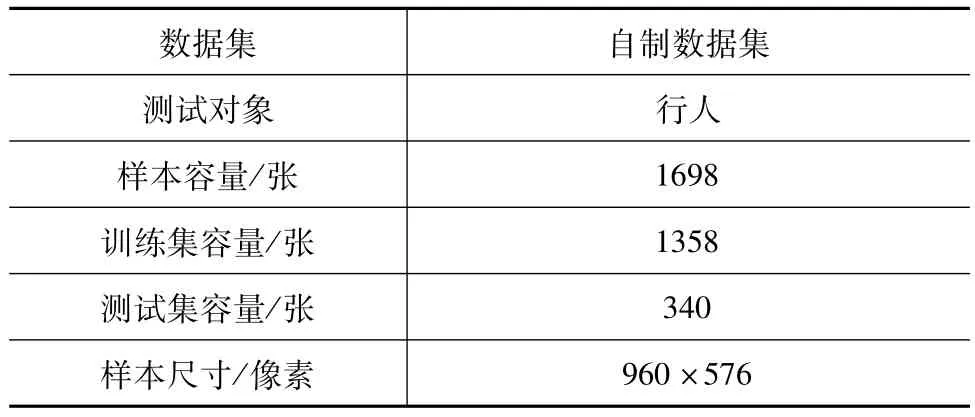
表3 数据集参数表Tab.3 Parameters of the dataset
3.2.2 数据集处理
通过训练网络来检测红外图像中的行人,不仅需要提供目标行人的分类结果还需提供行人的边界框的标注数据作为正确答案,行人的标注信息,包括(x,y)坐标、宽度 w和高度 h。 为此,利用实际道路采集的红外行人数据,对每一张红外图片手工标注行人的边界框、记录边界框的具体信息并贴上“person(行人)”类别标签,以供卷积神经网络的训练。
3.3 超参数优化
为了有效地训练网络并更好地预测结果,需要合理设置网络的超参数。动量、迭代次数、批大小和学习率等参数的值被设置用来优化超参数。表4中所示为列举的被用来训练网络的几组参数。每一组值都分别被用来训练网络,再使用100张图片测试每个训练结果的准确率。最后,选取能最大限度提高网络质量的一组值为最终的超参数。
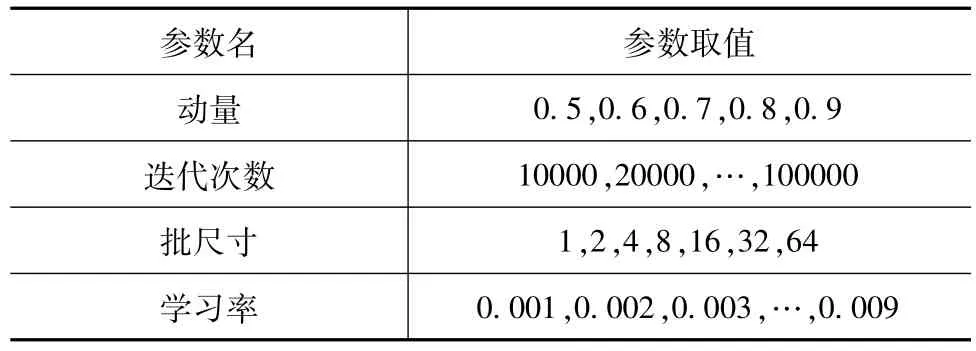
表4 超参数测试值表Tab.4 Hyper-parameters for testing
本文执行网格搜索来优化网络的超参数。当迭代次数增加时,网络展示出更好的检测效果。然而,当迭代次数超过100000,网络则显示过度拟合。另外,当批尺寸增大,网络效果同样变好,但由于内存限制并不能无限增大批尺寸。表5所示为最终用来训练和检测的超参数。

表5 超参数表Tab.5 Hyper-parameters table
4 实验结果与分析
4.1 训练过程平均损失
YOLO使用均方和误差作为loss函数来优化模型参数,loss函数的公式如下:

其中,coordError、iouError和classError分别为测试数据与真实标定数据之间的坐标差、IOU误差和分类误差。图5为实验得到的平均损失与训练时间(迭代次数)的关系图。每一次迭代随机选取8张图片用来训练神经网络,每一张图片都被使用多次。由图可知,随着训练的推进,平均损失减小到2.5%左右,这表明训练数据会影响CNN模型。最终,训练共进行80000次迭代,耗时8 h完成。
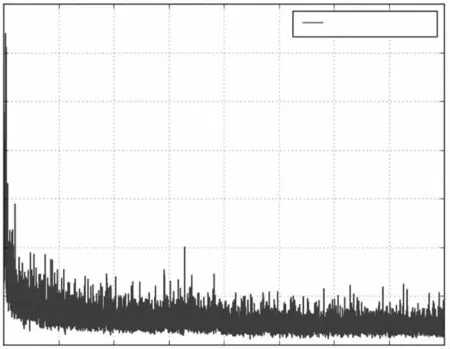
图5 训练过程平均损失变化Fig.5 Average loss curve during training
4.2 行人检测结果对比分析
4.2.1 YOLO训练结果与分析
YOLO训练结束,通过神经网络检测出行人并显示出行人的边界框。用测试集数据测试该网络,得到该网络的AP为68.1%,IOU为55.4%,FPS为70.4 f/s。如图6所示为检测结果示例,其中左图中右下角的行人未被检测出,右图中图像左边的树枝被误判为行人。

图6 YOLO测试结果Fig.6 Test results of YOLO
4.2.2 YOLOv2训练结果与分析
首先,利用YOLOv2_416×416进行训练。该网络的 AP为 78.2%,IOU为 66.70%,FPS为67.4fps。图7为检测行人的结果。由图可知,相比图6,模型的误检和漏检减少。另外从图7中可以看出YOLOv2对小目标的检测能力更强。

图7 YOLOv2测试结果Fig.7 Test results of YOLOv2
然后,改进输入网络尺寸即图像分辨率,分别训练 YOLOv2_480×480、YOLOv2_544×544和YOLOv2_608×608网络模型。基于训练得到的检测模型,通过调整行人检测综合得分的阈值,对测试集分别进行测试,得到每个模型对应的Precision-Recall曲线。如图8所示为以上四种YOLOv2模型的Precision-Recall曲线,表6为四种YOLOv2模型的检测评价指标结果表。

图8 四种YOLOv2模型的Precision-Recall曲线Fig.8 Precision-Recall curves of four YOLOv2 models
由此可见,随着输入分辨率的增加,输出特征图尺寸变大,输出网格数变多,因而对红外图像中远距离较为微小的行人的识别率变高,行人检测平均准确率变高;然而随之也带来了FPS的减小,当输入分辨率为608×608时,FPS值减小到20.4 fps,行人检测的实时性受到影响。因此,为了满足系统实时性需求,模型的输入分辨率不能无限增加,本文选取YOLOv2_544×544为最终采用的红外图像行人检测网络模型。
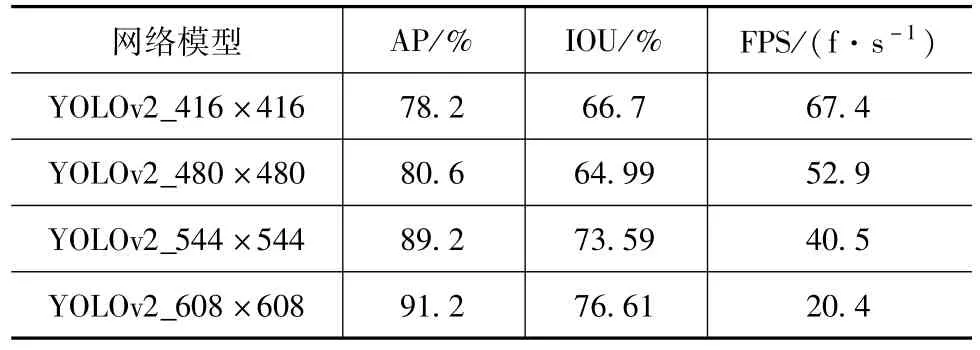
表6 四种YOLOv2模型检测结果评价指标表Tab.6 Evaluation indexes for the results of four YOLOv2 models
4.2.3 与传统方法对比
另外本文采用传统的基于滑动窗口HOG+SVM[6]的检测方法对实际道路采集的红外行人数据集进行行人检测的对比实验。测试结果对比如表7所示。
通过对比可知,本文基于改进YOLOv2的检测方法与基于滑动窗口算法的HOG+SVM检测方法相比,不仅在准确率上有提高,而且在检测速率的上有显著提升,达到40.5 f/s,满足车载情况下的实时性要求。
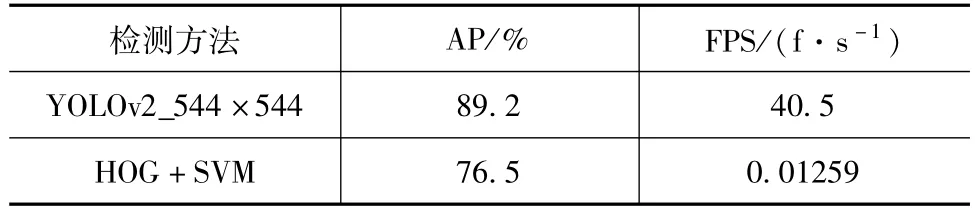
表7 本文方法与HOG+SVM滑窗法对比Tab.7 Comparison between the proposed method and HOG+SVM sliding window method
5 结束语
本文采用改进的YOLO网络结构进行基于红外图像的实时行人检测。首先对YOLO网络进行改进,调整其模型输入分辨率,提高了网络对远处较为微小的行人的识别能力;然后,用基于实际道路采集的红外行人标准数据集进行参数改进优化和模型训练,比较检测效果,得到效果最好的模型;同时提出车速与视频图像分辨率的关联模型,发挥车载红外图像行人检测系统的最佳性能,进一步提高驾驶的安全性。实验结果表明,YOLOv2_544×544综合检测效果最佳,与HOG+SVM的方法相比,可以更实时更准确地在红外图像中检测出行人。
本文的网络可用于车辆夜间的驾驶辅助系统,使用配有该网络的车载红外摄像机进行红外行人检测,提高驾驶员和行人夜间出行的安全性。
