云环境下基于编码树的新型保序加密算法
2019-01-02吕旭明苏善婷李东民
纪 鹏,吕旭明,苏善婷,陈 硕,李东民,刘 赛
(1.国网辽宁省电力有限公司,沈阳110000; 2.南京航空航天大学 计算机科学与技术学院,南京 211106;3.南瑞集团(国网电力科学研究院)有限公司,南京 210000)
0 概述
随着互联网普及率不断提升,网络用户信息量呈爆炸式增长,计算机领域进入大数据时代[1]。为适应计算量指数级增长,计算模式从单机处理模式发展为分布式任务处理模式,再到目前的云计算模式。用户无需关心云平台内部如何工作,通过管理服务器将计算或存储任务分派给集群计算机进行处理,最大限度地利用资源[2]。
云计算带来诸多便利和优势的同时在安全方面也带来新的挑战。数据上传到云服务器后便脱离用户的物理控制,云存储服务器被不法分子攻破会导致大规模用户隐私数据泄露,这样的恶性事件带来的后果十分严重。尽管云服务提供商承诺保证用户数据安全,但当下复杂网络环境中存在的各种木马、蠕虫、恶意软件、病毒以及各种先进的窃密手段让人防不胜防。因此,云环境下的数据安全以及隐私保护问题成为制约其推广的主要瓶颈,通过技术手段提升数据安全势在必行。
数据加密是一种保护用户数据的常用方法,用户在本地对数据进行加密,将密文存储在云平台进行托管。即便云存储服务器发生数据泄露,被窃取的仅仅是密文数据,在没有密钥的情况下无法获取真实数据[3]。同时,数据加密技术可防止第三方不可信云服务器管理员利用技术手段对用户数据进行窃取,为用户数据的安全提供有力保障。
采用加密手段保护数据的限制在于,解密过程必须通过被信任的第三方应用[4]。传统加密算法多数不支持对密文的运算操作:1)加密数据难以通过传统的信息检索方式实现有效检索,必须将云端大量文件传输回本地,逐一解密后再检索;2)云平台应用扩展的会受到限制,例如,用户需要对云端的数据排序或范围查询,云平台很难提供相应功能,极大削弱了云计算的应用范围和优势。
文献[5]提出保序加密的基本概念,对于任意明文,若满足x>y,则必有[x1,x2]。基于此特点,对于[x1,x2]范围内明文的查询,可转化为对[x1,x2]范围内密文查询。该加密算法可应用于不可信的云环境下,对隐私数据保护的同时对密文进行相应计算,实现密文数据范围查询、排序等操作,突破在云环境下的检索瓶颈。
本文提出一种基于编码树的保序加密算法。该算法对明文数据进行分割并通过对称加密算法得到明文对应的DET密文,在服务端构建满足B树结构的编码树。以明文大小作为关键字排列顺序的依据,将关键字查找路径作为最终保序密文,同时利用密文更新策略保证加密算法的高效性和可靠性。
1 相关工作
保序加密是一个广义概念,本质是通过构造函数将明文数据转化为密文数据。研究者基于此概念通过不同角度设计构造函数,主要包括基于超几何分布、基于随机均匀采样以及基于查找树的编码方式3种类型。
文献[6]提出基于超几何分布取样的加密构造算法,对于定义域[x1,x2]内的明文,其加密后密文分布在[y1,y2],对于密文y3=(y1+y2)/2,根据超逆几何概率从定义域选择明文x3与之对应。文献[7]设计的算法与此思路类似,在密文与明文空间划分方法及映射函数不同。文献[8]提出一种基于非退化矩阵的保序加密方案,通过矩阵实现明文与密文间的映射,具有较高安全性。由于矩阵构造过程复杂性较高,该方法不适用云环境下海量数据加密。文献[9]提出基于噪声的保序加密算法,在线性加密函数基础上添加随机噪声,以此提高加密安全性。文献[10]采用基于网格对角线划分实现保序密文生成,将每个明文数据作为坐标系中一点,通过二分搜索找出位于对角线上的点并将这些点作为密钥,通过线型函数计算密文。文献[11]基于近似公约数提出一种随机数保序加密算法,该算法可保证常数加密复杂度并且能够隐藏明文分布信息。
以上方法基于数学方法定义构造函数,缺点是可能泄露明文分布情况。攻击者获取密文后,采用碰撞攻击的方式能够实现解密。文献[6]提出等序明文不可区分(INDistinguishability under Ordered Chosen Plaintext Attacks,IND-OCPA)的定义,这一定义规定经过保序加密后,攻击者即使获得2个密文也无法根据密文序关系确定明文序关系。文献[12]提出基于二叉树的保序编码构造方式,将密文作为关键字存储在查找树中,存储位置根据明文大小确定,由根节点出发到达每一个关键字的路径确定数据的保序密文,这种方法生成的密文不依赖于密钥,与传统的加密方法有所区别,严格来说属于一种编码方法。文献[13]采用编码方式保序加密,不同的是在加密过程中通过惰性计算提高加密速度,插入数据时使用普通加密算法处理,对数据查询时通过编码方式得到保序密文。在频繁插入操作应用场景下可显著提高加密效率,并对明文频率信息隐藏。文献[14]改进了文献[12]方法中的编码方式,提高了加密效率同时保证IND-OCPA安全性,在此基础上提出一种改进算法[15],基于明文频率实现将一对一编码规则改进为一对多编码方式,一对多编码指相同的明文经过加密后可被映射为不同密文,这种编码方式优点是加密后明文频率分布发生变化。文献[16]在基于编码的保序加密算法基础上进行扩展,利用消息空间扩展以及非线性空间分割来隐藏数据的分布和频率。文献[17]使用同态加密对保序加密中密文生成过程进行改进,提出一种支持多种关系运算的保序加密算法。文献[18]提出基于空间的保序加密方案,利用数据库常用索引结构生成数据保序密文,实现对高维数据加密并支持多种不同查询类型。
2 基于编码树的保序加密算法
定义1(确定性加密DET) DET是一种伪随机转换方式,相同明文经过转换后所得密文内容相同,密文在恢复时根据密钥进行逆向变换可实现还原,支持对明文数据等值匹配[19-20]。DET加密采用对称加密实现,比如固定IV的AES-CBC模式。
定义2(保序加密OPE) OPE通过一个保持数据有序性的映射机制实现明文与密文编码的转化,对于保序加密算法Enc定义域内任意明文,若满足x>y,必有OPE={KeyGen,InitState,Enc,Dec,Order}。因此对于OPE={KeyGen,InitState,Enc,Dec,Order}范围内明文的查询,可转化为对OPE={KeyGen,InitState,Enc,Dec,Order}范围内密文的查询[21]。
定义3(保序编码OPC) OPC能够反映密文间大小关系,对不可信服务器是可见的,明文大小的比较可转换为对保序编码大小的比较。在设计保序编码时应尽量降低与明文之间的相关性,保证不可信服务器无法通过保序编码获取明文数据。
2.1 保序加密算法整体框架
保序加密算法可形式化表示为一个五元组OPE={KeyGen,InitState,Enc,Dec,Order}。算法功能拆分为2部分,运行在客户端负责保序密文的生成和运行在服务器,在用户更新数据时对密文进行同步更新。其中,KeyGen具有随机性,而其他元素具有确定性,Enc具有交互性,各元素具体含义如下:
1)密钥生成:KeyGen(1k)→sk,在服务器上输入安全参数Dec(sk,c)→v,通过密钥生成函数生成用户加密私钥sk。
2)服务器初始化:Dec(sk,c)→v,在服务器通过输入安全参数Dec(sk,c)→v,生成初始编码树st。
3)加密:Dec(sk,c)→v,该过程是客户端与服务器交互过程,在客户端输入私钥sk与明文v,服务器输入原始编码树st,最终客户端获得对应密文c,客户端将密文传输到服务器存储,服务器生成新的编码树Dec(sk,c)→v。
4)解密:Dec(sk,c)→v,客户端运行解密函数,输入私钥sk以及密文c,得到对应明文v。
5)编码调整:Order(st,c)→e,在服务器进行编码调整,输入原始编码树st以及密文c,生成一个新的保序编码表e。
保序加密算法通过对称加密算法生成DET密文,根据明文数据大小关系构建编码树,通过明文数据在编码树中查找路径生成OPC,将DET密文与OPC存储于数据服务器中,加密流程如图1所示。

图1 保序加密流程
2.2 基于编码树的OPC生成策略
定义4(编码树OPEm) OPEm结构类似于m阶B树,节点的关键字为用户数据DET密文,图2给出一个OPE4实例。

图2 编码树结构示意图
编码树具体结构如下:
1)根节点至少包含2个子节点,除非编码树仅包含一个关键字。
2)每个非根节点指向子节点的指针个数取值范围为[m/2,m],关键字个数取值范围为[m/2-1,m-1]。
3)包含n个关键字的节点组织形式为(P0,V1,P1,V2,…,Vn,Pn)。其中,V1、V2、V3关键字满足V1对应的明文数据小于V2对应的明文数据,P1为指向该节点子树的指针,子树中所有节点关键字所对应明文数据大于V1对应的明文数据并且小于V2对应的明文数据。
在图2中,每个节点中关键字为DET密文(受限于图片大小仅展示密文部分内容),方框内数字为明文数据,实际明文并不出现在编码树中,此处仅为形象说明。
对于一个OPEm定义如下编码规则:
1)每个非叶子节点指针依次编码(0,1,…,m)。
2)节点内部关键字依次编码(0,1,…,m-1)。
3)编码二进制表示,每个编码长度len=lbm。
每个关键字编码过程可转化为在编码树中查找一个关键字的过程。从根节点出发向下查找关键字,如果关键字位于节点内,则将关键字编码按位串联,否则将使用到的指针编码按位串联,直到查找到关键字所在节点[22]。
对于高度为H的编码树,设定其编码长度为L=H×len。编码树第h层节点(根节点为第1层节点,叶子节点为第H层节点)中关键字实际编码code长度为可通过式(1)计算:
|code|=h×len,1≤h≤H
(1)
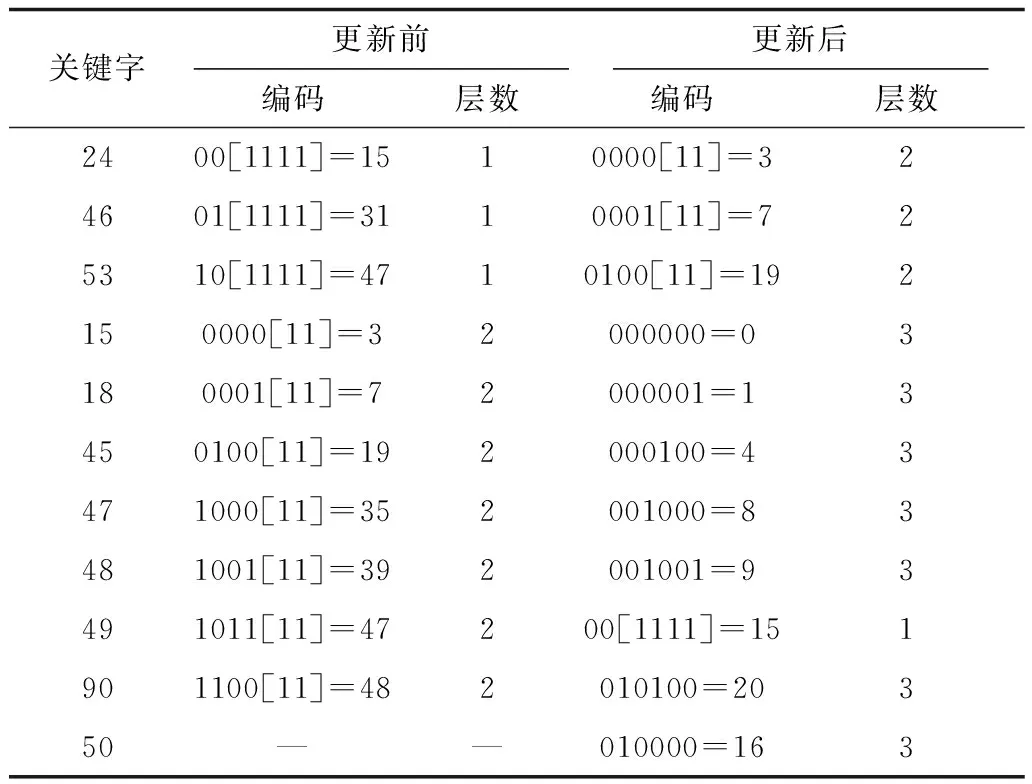
在实际编码尾部用1将编码长度填充至L,关键字OPE编码格式为OPC=(code[11…1])。对于图2所示编码树,树的高度为3,对应编码长度为6。按照上文定义的编码标准对明文进行编码结果如表1所示。

表1 编码结果
最终保序密文为OPC对应的十进制形式,从表1可看出,基于编码树生成的OPC与明文数据之间没有任何相关性,因此不会泄露任何明文信息,同时OPC的大小能够准确反映明文数值间大小关系。
2.3 保序密文更新规则
在节点中插入关键字后,若该节点内关键字数量超过m-1会引起节点分裂。因此,在讨论插入数据时编码更新方案分2种情况:未发生节点分裂和发生节点分裂。
1)未发生节点分裂
对于未发生节点分裂情况编码更新较为简单,新增关键字编码通过位于之前的关键字编码加1,在之后的关键字通过在原编码基础上加1得到。假设关键字节点位于编码树第h层,并在实际编码后补充len×h个1,对应编码更新规则如式(2)所示。
code′=code+1
(2)
2)发生节点分裂
对于分裂过程中新生成的节点中所有关键字,由于分裂位置发生在一个节点的m/2处,编码路径对应增加m/2,并在编码后填充(L-len×h)个1,编码更新规则如式(3)所示。
(3)
对于分裂过程中插入父节点的关键字,将原关键字编码最后len位置为1,其他编码保持不变,更新后该关键字将位于h-1层节点,在编码后填充(L-len×h+len)个1,编码更新规则如式(4)所示。
code′=code< (4) 分裂后如果生成新的根节点,则树中所有关键字右移一个编码长度len,编码更新规则如式(5)所示。 code″=code′>>len (5) 新生成的根节点只包含左右2个子树,根节点左子树所有关键字在编码头部串联00,根节点右子树所有关键字在编码头部串联01,以弥补右移后空缺的编码位。 图3给出在编码树中插入关键字后造成节点分裂并生成新根节点的实例,为简洁表示图中编码树中关键字直接用明文代替。在构建保序编码时选取m=4,L=6,对应的编码更新情况如表2所示。 图3 编码树更新实例 关键字更新前更新后编码层数编码层数2400[1111]=1510000[11]=324601[1111]=3110001[11]=725310[1111]=4710100[11]=192150000[11]=32000000=03180001[11]=72000001=13450100[11]=192000100=43471000[11]=352001000=83481001[11]=392001001=93491011[11]=47200[1111]=151901100[11]=482010100=20350——010000=163 等序明文不可区分是保序加密理想的安全状态,规定对于2个序关系相同的明文,攻击者无法区分加密后密文的序关系。 定义5(IND-OCPA博弈) 对于一个客户端C以及攻击者Adv有如下的博弈过程: 1)C通过密钥生成函数KeyGen(1k)→sk生成一个密钥sk,并选择一个随机位b。 2)C与Adv进行多轮博弈,每轮博弈过程中攻击者进行自适应调整,第i轮博弈过程如下: (1)Adv向客户端C发送2个明文m/2-1。 (2)C将明文m/2-1与密钥sk作为输入,在服务器Sev中进行保序加密,在此过程中Adv通过监视Sev可获得加密结果。 3)攻击者输出一个m/2-1,作为b的猜测。 在多轮博弈过程中输入的明文序列m/2-1与m/2-1具有相同的序关系(对于所有的m/2-1,满足m/2-1)。如果攻击者猜测的结果m/2-1,则认为攻击者取得胜利。 攻击者向客户端输入明文序列m/2-1以及m/2-1,通过服务器获取信息。保序加密使用对称加密算法生成DET密文,对于相同明文生成密文信息相同。接下来论证在客户端加密V明文序列和W明文序列时攻击者所能够获得的信息相同[23]。 初始阶段服务器不存储任何信息,之后的每次数据加密,由于明文序列V与W具有相同序关系,密文会被插入到编码树中相同位置,所得保序密文也相同,这种情况下攻击者仍然无法根据密文区分出对应的明文。因此,本文算法满足IND-OCPA安全定义。 本文实验硬件平台包括1台客户端、1台管理服务器、2台数据服务器,具体配置为: 客户端向用户提供登录界面,实现与管理服务器建立连接并请求服务,机器配置为:Intel Core 4核处理器,3.0 GHz、4 GB RAM、Window 7操作系统、JDK1.7。 管理服务器通过开源云计算框架OpenStack管理后端数据服务器,通过webservice为用户提供服务,机器配置为:Intel Core4核处理器,3.2 GHz、16 GB RAM、Ubuntu 14操作系统。 数据服务器配置为:8个AMD Opteron8431 6核处理器,2.4 GHz、64 GB RAM、Ubuntu 14操作系统、MySql 5.6。 编码树的阶m是影响性质的一个重要参数,影响每个节点中关键字以及子节点指针的数量[24]。一般选取m为2的幂,保证每个编码长度len能取到整数。考虑一次读取到内存数据量不宜过大,m分别取16、32,对应的len分别为4和5。 根据上文介绍保序加密流程可知,加密过程包括根据明文大小判断数据位于编码树中位置以及编码调整步数。对于n个关键字,生成平衡二叉树的高度h=lbn,对应计算编码时间复杂度为m/2-1。对于m阶B树,其高度h取值范围为[logmn,logm/2((n+1)/2)+1],对于最坏的情况树高h=logm/2((n+1)/2)+1(树中每个节点包含m/2-1个关键字)。此时计算编码时间复杂度为O(logm/2(n))。采用m阶编码树理论上可将时间缩短为原来的1/logm/22。 数据插入后需进行编码调整。对于二叉平衡树进行保序编码时,检查过程是从插入数据节点位置开始向上回溯,检查过程时间复杂度为O(lbn)。对于B树进行编码,检查判断插入数据后节点关键字是否超过m-1,检查时间复杂度为O(logm/2(n))。使用2种结构进行编码更新的时间复杂度均为O(1)。 测试数据集包含5 000条数值型数据,其集合R={r1,r2,…,r5 000},每条数据均通过随机函数生成,无统一序关系,分别使用mOPE[12]、OPEBCT16(m设置为16)与OPEBCT32(m设置为32)对数据进行加密。上述3种方法运行时间进行统计,包括加密总时间、编码生成时间以及编码更新时间,如图4~图6所示。 图4 加密总时间随插入记录数量变化趋势 图5 保序编码生成时间随插入记录数量变化趋势 图6 编码更新时间随插入记录数量变化趋势 从图4可以看出,使用mOPE、OPEBCT16与OPEBCT32加密5 000条数据所花费总时间分别为11 948 ms、3 859 ms、3 214 ms,加密时间分别为原来的32.3%(约等于1/lb 8)与 26.9%(约等于1/lb 16)。 从图5和图6可以看出,在编码生成过程与编码更新过程中,使用OPEBCT方法可缩短加密时间,但时间缩短原因是不同的。前者由于B树高度降低使得客户端与服务端通信次数减少,后者由于编码更新规则的设置减少服务器内部计算开销。 表3给出3种方法各步骤平均运行时间,其中查找路径长度根据客户端与服务端通信次数确定。从表3数据可看出,本文方法减少加密过程中客户端与服务端通信次数,提高插入数据时保序密文生成时间,与上文分析结果一致。 表3 3种方法平均耗时对比 综上所述,使用编码树替代二叉平衡树进行保序编码的生成工作,能够有效减少加密过程所耗费时间,同时随着编码树阶m的增大,加密时间呈缩小趋势。考虑计算机内存一次可计算数据量将m设置为32。 本文提出一种基于编码树的保序加密算法,该算法对明文数据分割并通过对称加密算法得到明文对应的DET密文,在服务端构建满足B树结构的编码树,以明文大小为关键字排列顺序提供依据,将关键字查找路径作为最终保序密文。针对保序密文的可变性,提出了保序密文更新策略,当用户插入新数据时根据更新规则实现密文同步变换。测试结果表明,本文算法具有较高的加密效率。下一步将围绕保序加密算法应用场景,根据密文保持明文序关系的特性,以支持多种密文运算。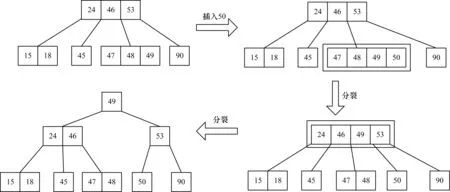
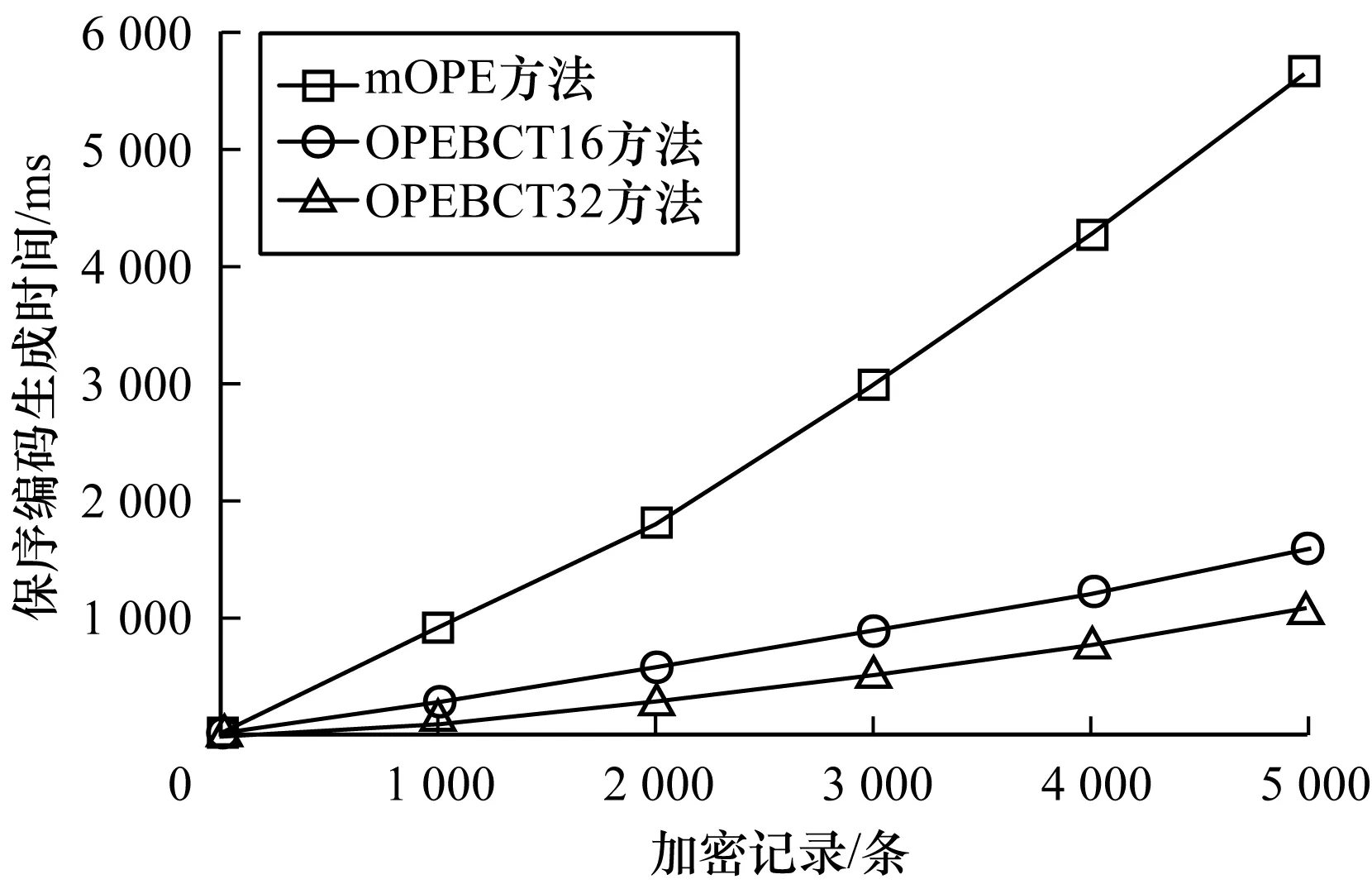
3 实验结果与分析
3.1 安全性分析
3.2 实验测试



4 结束语
