基于多局部显著视图与CNN的三维模型分类
2019-01-02司庆龙刘振刚秦飞巍
白 静,相 潇,司庆龙,刘振刚,秦飞巍
(1.北方民族大学 计算机科学与工程学院,银川 750021; 2.杭州电子科技大学 计算机学院,杭州 310018)
0 概述
随着三维建模技术及计算机视觉等领域的不断发展,目前三维模型已被广泛应用于虚拟现实、工业设计、影视动画和分子生物学等各个领域,其数量呈指数级增长。合理组织和高效检索三维模型是有效利用这些宝贵数据资源的首要前提,成为相关领域的研究焦点。
传统的三维模型分类方法通过人工预设方式获取三维模型的描述符[1],进而实现分类和检索。随着三维模型复杂度及数量的不断增长,学者们发现这种传统的三维模型分类方法存在无法客观、合理捕捉模型本质特征的天然缺陷,难以满足不断增长的分类需求。深度学习技术也称为特征学习技术[2],其能通过学习获得复杂数据的多抽象层表示,在语音识别、计算机视觉等多类应用中取得了突破性进展,也为三维模型检索工作带来了新的思路。
由于三维模型表征的非结构化,输入数据的构建是基于深度学习三维模型检索首要解决的问题。部分研究人员将三维模型表征为体素模型实现三维模型表征的结构化,进而利用三维深度学习模型,如3D ShapeNets[3]、三维卷积神经网络(Convolutional Neural Network,CNN)[4]、VoxNet[5]、引入方向信息的VoxNet[6]、PointNet[7]、变分自编码VAE-深度卷积神经网络模型[8]、卷积-自动编码机[9]实现特征的自动提取和三维模型的分类,取得了非常好的分类效果。但是这类表征方式存在高维、稀疏的特点,一定程度上影响了对应网络的分类性能。此后,有学者针对性地提出了基于多分辨率的紧致表征和深度学习网络[10-11],分类效果有所改善,但是仍有较大的增长空间。于此同时,部分学者利用二维卷积神经网络的突出表征和分类能力,提出了基于视图的三维模型表征方法,如基于单视图的DeepPano[12]、基于多视图的MVCNN[13]、Pairwise[14]、卷积结合词袋模型[15]等一系列研究工作,并取得更加优异的分类和检索性能[16]。
本文以视图为三维模型的表征,提出一种基于多局部显著视图和卷积神经网络的三维模型分类算法。该算法利用局部显著视图集表征原始三维模型,通过集成CNN模型完成三维模型分类。
1 本文算法框架
本文算法分为2个部分:首先选取不同视角建立表征三维模型的局部显著视图集;然后建立集成CNN模型完成三维模型分类。算法框架如图1所示。在局部显著视图集的构建中,通过候选局部视图提取模块确保视图数据的有效性、视图间信息的互补性和多样性,利用局部显著视图集确定模块进一步确保单个视图的显著性和视图集的完整性;在集成CNN模型的构建中,首先构建面向单个视图分类的弱深度学习模型,然后利用bagging策略,通过投票法完成三维模型分类,提高深度学习模型的泛化能力。
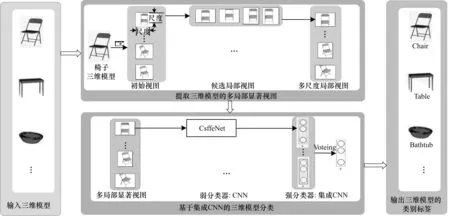
图1 算法框架
2 局部显著视图集的构建
三维模型的局部显著视图集是指模型所对应的那些具有明确代表性和显著区别性的局部视图集合。给定三维模型M,本节旨在构建三维模型的局部显著视图集SV={SVi,1≤i≤n},形成对三维模型的原始表征,构成深度学习模型的输入,实现三维模型分类。
通过分析三维模型视图的特点可知,通常情况下,当一组局部视图满足以下4点时,它就对应了一个局部显著视图集:1)视图集内的每个视图都是有效的;2)视图集内的每个视图都具有足够的显著性;3)视图集内的视图间具有较强的互补性和较低的相关性;4)视图集内的视图共同构成原始三维模型较为完整的描述。为此,本文将局部显著视图集的构建分为以下两步:1)提取候选局部视图;2)确定局部显著视图集。
2.1 候选局部视图的提取
分析基于视图的各类三维模型分类算法[12-16],综合比较视图数目、分类结果可知,12个视图的表征方式是最为高效的。因此,给定三维模型M。本文沿用MVCNN的视图获取方式[13],构建基于12个视角的视图集作为表征三维模型的初始视图集IV={IVi,1≤i≤12}。由于这12个视角每隔30°均匀地位于三维模型不同视点,相互之间具有较强的互补性和较低的相关性,因此构成三维模型较为完整的描述。
为保证候选局部视图的有效性,本文以1/2为最小尺度,以1为最大尺度,从中选取合适的尺度scale构建局部视图。给定三维模型的每一个视图IVi,分别采用如图2所示的窗口滑动方式,获取其占据全局1/2、9/16、3/5、16/25、2/3、3/4、4/5、9/10不同尺度下的局部视图SIVij,形成对应尺度的候选局部视图数据集SIVi={SIVij,1≤j≤m},其中m为给定尺度下每个原始视图所对应的局部视图的数目。至此,给定一个三维模型M和局部尺度scale,本文构建并获取了其对应的候选局部视图集SIV={SIVi,1≤i≤12}。

图2 不同尺度局部视图的建立方式
2.2 局部显著视图集的确定
局部显著视图集的确定原则为:只有当一个局部视图具有足够的显著性时才能构成最终的局部显著视图集。因此,针对候选局部视图集每个视角下的局部视图数据集SIVi={SIVij,1≤j≤m},本文将进一步计算各个局部视图SIVij的显著性s(SIVij),并选取其中显著性最高的局部视图构成该视角下的局部显著视图,形成三维模型的局部显著视图集SV,计算公式如下:
SV={SVi,1≤i≤12}
(1)

由于对三维模型而言,形状是决定其分类的主要属性;相应对三维模型的视图而言,方向特征就成为决定其显著与否的关键要素。因此,本文中局部视图的显著性由该视图方向特征的显著性决定。计算过程如下:
步骤1高斯金字塔的构建。给定视图V,基于高斯滤波器下采样构建其高斯金字塔g(V,σ),σ为尺度参数,其中σ∈[1,7]。
步骤2计算高斯特征图各尺度的方向特征。利用Gabor滤波器计算g(V,σ)在0°、45°、90°、135°方向上的方向特征o(V,σ,θ),其中θ∈{0°,45°,90°,135°}。
步骤3计算σ∈[1,3]各尺度视图对应方向特征的显著图。
步骤3.1针对每个方向,以o(V,σ,θ),σ∈[1,3]为中心层,以o(V,σ+ϑ,θ),ϑ∈{3,4}为围绕层,通过最近邻插值法实现围绕层的上采样,使之与中心层对齐,逐像素求差。计算公式如下:
sd(V,σ,ϑ,θ)=o(V,σ,θ)-
upSamp(o(V,σ+ϑ,θ),2ϑ)
σ∈[1,3],ϑ∈{3,4},θ∈{0°,45°,90°,135°}
(2)
其中,sd(V,σ,ϑ,θ)表示视图V以σ为中心层、以σ+ϑ为围绕层、在方向θ上计算所得的分方向特征显著图;upSamp(img,2ϑ)为上采样函数,表示对图像img上采样2ϑ倍。
步骤3.2综合各个尺度下的分方向特征图,计算获得该尺度下的方向特征图d(V,σ)。计算公式如下:

(3)
步骤4计算视图的方向特征显著图。通过下采样,将σ=1,2尺度下的方向特征d(V,σ)统一至尺度σ=3,逐像素相加,获得视图的方向特征显著图。计算公式如下:
d(V)=d(V,3)+downSamp(d(V,1),22)+
downSamp(d(V,2),21)
(4)
其中,downSamp(img,2ϑ),ϑ∈{1,2}为下采样函数,表示对图像img下采样2ϑ倍。
步骤5计算视图的显著性。取视图方向特征图中各个像素的平均值作为视图的显著性,计算公式如下:
s(V)=mean(d(V))
(5)
需要特别说明的是,在本文中,视图显著性的计算旨在比较同一视角下各个局部视图的显著性,是否进行归一化并不影响其相对大小,因此,本文中并未引入归一化操作。
至此,给定一个三维模型,通过候选局部视图的提取、局部显著视图集的确定,本文将一个三维模型表征为多个局部显著视图的集合SV。该局部显著视图集相对完整的表征了原始三维模型,并可作深度学习模型的输入用以分类。
3 基于集成学习的三维模型分类
给定三维模型M及其对应的局部显著视图集SV={SVi,1≤i≤12},本节旨在以其为输入,构建集成CNN模型,完成三维模型的分类。由于局部显著视图集中的每个视图对应三维模型不同视角下的视图信息,彼此之间具有相对独立性,视图间的最大池化、平均池化等其他类型的合成操作均无直接物理意义,且可能造成信息的丢失和混淆,因此本文首先利用卷积神经网络完成基于单视图的三维模型分类;然后将每一个基于单视图的深度学习模型作为弱分类器,利用bagging集成策略构建强分类器,通过投票完成三维模型的最终分类。上述过程如图3所示。

图3 集成CNN模型
4 实验与结果分析
实验过程:使用MATLAB实现局部候选视图的提取和局部候选视图显著值的计算;使用Python实现局部显著视图集选取;以Caffe框架为基础,使用CaffeNet网络完成基于多局部视图和深度学习的三维模型初步分类;再使用Python实现对初步分类结果的投票,实现最终的分类。
数据集:本文选用Princeton ModelNet[17]的子集ModeNet10作为训练及测试数据集对本文算法进行测试和验证。具体的,ModelNet10包含4 899个三维模型,分属10个类,每个类分为测试集和训练集。针对ModelNet库,同MVCNN[13],每个类选取测试集的前20个和训练集的前80个模型,进行一次实验,获得实验结果。其中,具体数据集信息如表1所示。

表1 实验中ModelNet10数据集信息
网络训练:在基于集成学习的三维模型分类中,本文选用CaffeNet作为集成学习中的个体学习器,其网络结构如图4所示,其网络参数设置如表2所示。在网络训练时,初始学习率设置为0.000 1,每迭代50 000次时,学习率降低为原来学习率的1/10,重复此过程。为防止过拟合,在全连接层引入DropOut层,dropoutratio均设置为0.5。

图4 CaffeNet网络结构

层类型滤波器尺寸步长输出规模参数数量卷积层(C1)11×11496×5×55 34 944池化层(S1)3×3296×27×27 —卷积层(C2)5×51256×27×27307 456池化层(S2)3×32256×13×13 —卷积层(C3)3×31384×13×13885 120卷积层(C4)3×31384×13×13663 936卷积层(C5)3×31256×13×13442 624池化层(S5)3×32256×6×6 —全连接层(FC6)——4 09637 752 832全连接层(FC7)——4 09616 781 312全连接层(FC8)——cc×4 096+c
在表2中,c为输出类的数目。本文算法的所有实验均是在此参数的CaffeNet网络上进行训练和测试。
4.1 模型参数取值实验及分析
模型参数的设定会对算法产生不同的影响。经过分析,对本文算法产生决定影响的模型参数主要包括高斯金字塔尺度参数、视图尺度参数和多尺度视图集成参数,本小节主要从这3个方面对模型参数的选择进行讨论。
4.1.1 高斯金字塔尺度参数选取实验及分析
高斯金字塔的尺度决定了视图的显著性计算结果,影响多局部显著视图集的生成,进而影响三维模型的分类。本文实验旨在验证不同高斯金字塔尺度的选取对算法的影响。
表3给出了在ModelNet10数据集上,根据尺度为5、7、8的高斯金字塔在不同尺度视图对应的三维模型分类准确率。

表3 不同高斯金字塔尺度分类结果对比 %
由表3可见:对于9/10局部,尺度为5和7的高斯金字塔结构对应的三维模型分类准确率相等;对于其他局部,尺度为7的高斯金字塔结构对应的三维模型分类准确率均高于尺度为5的高斯金字塔结构对应的三维模型分类准确率;对于9/16局部,尺度为7的高斯金字塔结构对应的三维模型分类准确率低于尺度为8的高斯金字塔结构对应的三维模型分类准确率;对于3/4局部,尺度为7和8的高斯金字塔结构对应的三维模型分类准确率相等;其余尺度为7的高斯金字塔结构对应的三维模型分类准确率均高于尺度为8的高斯金字塔结构对应的三维模型分类准确率。综合实验结果对比可知,尺度为7的高斯金字塔结构对应的三维模型分类准确率最好。实验结果表明:高斯金字塔尺度参数是决定三维模型分类结果的一个主要因素;选择合适的高斯金字塔尺度可能进一步提高三维模型分类的准确率。所以,在本文所有多局部显著视图集确定的实验中,本文均选用尺度为7的高斯金字塔结构。
4.1.2 视图尺度参数选取实验及分析
视图尺寸的选取既影响视图集的代表性,也影响对应深度学习网络的泛化能力。本实验旨在验证不同尺度视图的选取对算法的影响。
依据图2给出的特定视角下不同尺度局部视图的建立方式,建立候选局部视图;通过显著性评价,确定局部显著视图集,并以此为基础完成三维模型分类。
表4给出了在不同尺度的局部视图下本文算法所得三维模型分类准确率。

表4 不同尺度视图分类结果对比 %
由表4可见:从1/2到全局视图,不同尺度的视图对应了不同的分类准确率,其中,当视图尺寸由1/2到4/5不断增加时,其分类准确率不断提升,4/5时达到最大值94%;此后,随着视图尺寸的增加,三维模型的分类准确率不再增加。同时比较局部视图和全局视图分类准确率发现,当局部视图的尺度达到3/5及以上时,其对应算法的分类准确率已经超过全局视图的分类准确率92%。实验结果表明:1)局部视图的选取增加了三维模型视图的多样性,改善了对应深度学习网络的泛化能力,因而一定程度的提高了三维模型分类的准确率;2)局部视图尺寸的选取影响三维模型分类准确率,过小的局部视图无法有效捕捉三维模型的关键信息,不具有足够的代表性,影响三维模型的分类准确率;过大的局部视图难以体现多样性,不能充分激活网络的泛化能力,也会影响三维模型的分类准确率。
4.1.3 多尺度视图集成参数实验及分析
不同尺度的视图集成可以进一步增加视图的多样性,激活深度学习网络的泛化能力。本实验初步测试了基于多尺度局部显著视图完成三维模型分类的效果。实验中不区分视图尺度大小,针对每个特定视角仍然选取1个显著性最大的视图构成局部显著视图集,并以此为基础完成三维模型分类,得到如表5所示的实验结果。

表5 多尺度视图分类结果对比 %
由表5可见:综合考虑16/25和4/5的局部视图集合时,其分类准确率为92.5%,较16/25局部的92%高,较4/5局部的94%低;综合考虑1/2和4/5的局部视图集合时,其分类准确率为94.5%,较1/2局部的89%和4/5局部的94%高。实验结果表明:在多尺度视图集成中,视图尺度间的差异性是决定其分类结果的一个主要因素;合适的多尺度视图集成,可进一步增加视图的多样性,因而可能进一步提高三维模型分类的准确率。
4.2 集成CNN对比实验及分析
本实验旨在验证集成CNN算法是否能有效提高三维模型分类器的泛化能力,并改善分类效果的有效性。分别以2/3局部、4/5局部、全局视图为输入,采用基于单视图的、基于MVCNN合成视图的[13],以及本文所提出的集成CNN算法对三维模型进行分类,得到如表6所示的实验结果。

表6 3种不同算法的分类实验效果对比 %
由表6可见:无论是对于局部视图还是全局视图,本文所提出的集成CNN算法的分类准确率均优于其他2种算法。另一方面,对于4/5局部,无论采用哪种深度学习模型,分类准确率均为同类方法中最高;2/3局部分类准确率在单视图和合成视图上低于全局视图,在集成CNN模型上高于全局视图。实验结果表明:1)本文所提出的深度学习模型确实可以一定程度提高学习器的泛化能力,改善分类准确率;2)合适尺度局部视图的引入可增加三维模型视图的多样性,改善对应深度学习网络的泛化能力,进而提高了三维模型的分类准确率。
4.3 各个类的分类准确率分析
以4/5局部为输入,本文算法在ModelNet10各个类上的分类分布情况如图5所示。由图5可见:本文算法在bathtub、bed、chair、monitor和toliet这五个类上的分类准确率均为100%;在dresser、night_stand和sofa这三个类上的分类准确率均为95%,即只有1个实例被错分在其他类;在desk类上的分类准确率为90%,存在2个实例被错分;在table类上的分类准确率最低,为65%,有7个模型错分至desk类中。如图6所示,通过比较desk和table类内的测试实例会发现,这两个类内的模型在整体形状上极其相似,而本文算法在区别模型细节特征方面仍然存在不足,因而无法有效区分这些模型所属类别。
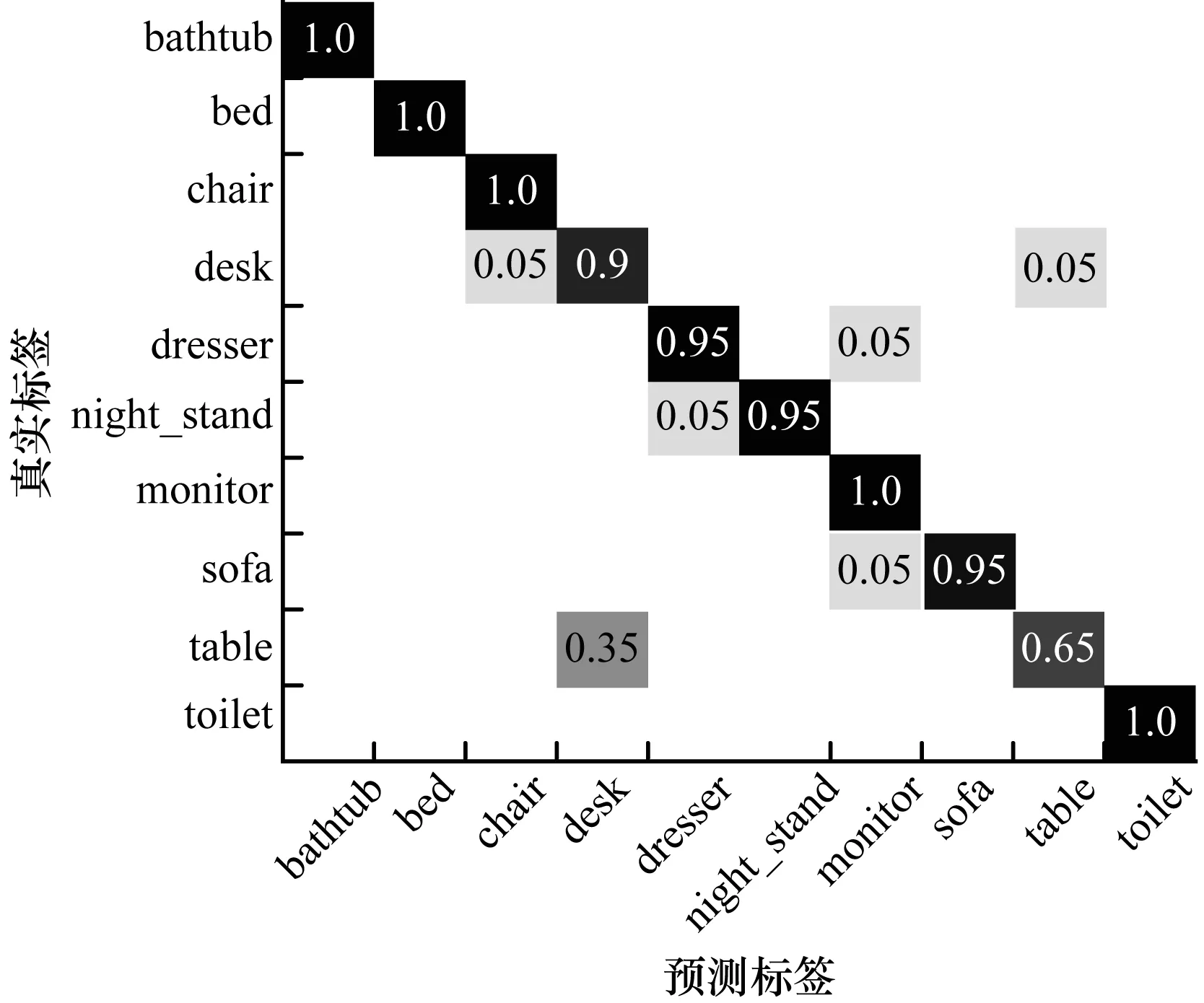
图5 本文算法在ModelNet10各个类上的分类结果
为进一步说明本文算法的特点,图7给出了ModelNet10数据集中bathtub、desk和table 3个类内9个不同三维模型某一个局部显著视图所对应的4 096维特征的可视化结果。
由图7可知,基于视图提取的刚性三维模型特征具有以下特点:1)类间三维模型的特征整体相似;2)相似类之间的特征相似度比非相似类之间的特征相似度要高,如desk和table两个类特征相似度要比desk和bathtub、table和desk相似度要高;3)一定程度上,对于相似的三维模型,如desk1和table3、desk3和table2,其三维模型特征相似度也很高。这一可视化结果进一步说明了本文算法能够有效区分非相似类,但在区别模型细节特征方面仍然存在不足,因而无法完全正确区分desk和table等相似模型所属类别。
4.4 基于视图的三维模型分类实验对比
表7给出了本文算法和其他基于视图的分类算法在ModelNet10数据集上的分类性能比较。其中,由于MVCNN工作中未给出其在ModelNet10数据集上的分类准确率[13],其实验结果由本文实现并获取,其他方法的准确率均为官方数据。由表7可知,就目前的各种基于视图和深度学习的分类算法而言,本文算法的分类准确率最高,这也再次验证了本文算法的有效性。

表7 基于视图的三维模型分类结果对比 %
5 结束语
本文提出一种基于多局部视图和CNN的三维模型分类算法。首先给出局部显著视图的提取方法,然后设计并实现集成CNN模型,最后基于ModelNet10数据集验证本文算法的有效性。实验结果表明:合适尺度的局部显著视图可以有效捕捉三维模型代表性信息,同时进一步增加视图的多样性和学习网络的泛化能力;而集成CNN模型则可以进一步集成单个视图的分类结果,取得较单个深度学习模型更优的分类效果。相对于已有的三维模型分类方法,本文算法具有兼顾表征数据的完整性和多样性、学习模型的泛化能力强和分类准确率高的特点。下一步将研究基于多尺度局部显著视图的三维模型分类算法,同时设计并实现端到端的集成深度学习模型。
