基于凝聚层次的驾驶行为聚类与异常检测方法
2019-01-02景首才
惠 飞,彭 娜,景首才,周 琪,贾 硕
(长安大学 信息工程学院,西安 710064)
0 概述
异常驾驶行为通常指行车速度超过速度限制、驾驶员突然改变速度或不断地改变车辆侧向位置等非平稳行为,此类行为是导致交通事故的重要诱因。因此,为交通管理部门提供可靠的异常驾驶检测方法具有非常重要的实际意义。
目前异常驾驶行为检测方法主要基于视频数据和车辆GPS轨迹数据进行研究。文献[1]利用视频数据对车辆的轨迹和速度进行分析,在背景差分法的基础上通过建立跟踪车辆信息链实现对车辆跟踪和异常行为检测;文献[2]利用背景差分法和均值漂移算法获取车辆位置、速度、方向等判别参数,对3种判别参数的状态函数加权融合检测车辆异常行为;文献[3]利用GPS提供的位置、时间、速度信息,以车辆正常行驶情况下的纵向和横向加速度为阈值,检测和识别驾驶员异常驾驶行为;文献[4]以大量重特大交通事故数据为基础,通过聚类分析从危险驾驶行为角度研究外部影响因素与驾驶行为的关系。笔者通过对文献的分析发现,目前基于视频的异常行为检测,主要针对单车受限场景,难以对运输全过程进行监控[5]。而对GPS的轨迹分析,也以对单车进行先验阈值判断为主,大多是设定检测阈值而触发报警,缺乏数据深层次分析与信息挖掘步骤,不具有智能化辨识与特性分析功能。
为此,本文提出一种基于GPS数据的驾驶行为异常检测方法。首先根据时间、速度、加速度、方向、转角等全局与局部特征及其对应的13个统计量,构建车辆驾驶行为的特征属性,然后利用基于结构相似度度量的凝聚层次聚类方法对驾驶行为进行聚类建模,进而实现异常行为检测。本文方法将测试数据与训练数据集获得的模型库进行对比检测,无需使用经验指标来设定各类异常的阈值,从而有效避免人为因素对检测结果的影响。
1 驾驶行为聚类与异常检测方法框架
本文对商用车司机异常驾驶行为进行检测,主要检测超速、急加速、急减速、违章变道等行为。首先基于文献[6]提出的全局和局部运动特征分类方法,总结关于车辆运行GPS数据所体现的司机驾驶行为特征,从GPS数据中提取运动特征及其统计量,构建车辆多特征驾驶行为模型,提出基于多特征的驾驶行为聚类与异常检测方法,方法框架如图1所示。其中数据准备与预处理为大数据剔除无关噪声数据基本环节,本文不再赘述。

图1 基于多特征驾驶行为聚类的异常检测方法框架
1.1 驾驶行为多特征提取
1.1.1 全局特征提取
对于位置点数据全局特征的提取,首先根据轨迹数据点的时间信息,提取出数据点发生的17个全局时间特征,即:“月”(Month,如1月);“日”(Day,如2日);“星期”(Week,星期日到星期六分别为0~6);“周末/周内”(Workday,其属性为0/1属性,周内为1,周末为0);“节假日”(Holiday,其属性为0/1属性,法定节假日为1,法定工作日为0);“时段”(Time,本文将1 d 24 h等间隔划分为12个one-hot[7-8]时段特征,值为0/1)。在提取全局时间特征后,根据数据点信息提取其他运动参数。
轨迹是一系列连续GPS点的集合,记T=
1.1.2 超速驾驶行为特征提取
通过对两数据点间的行驶距离、速度和时间间隔分析,能够实现对超速行为的识别。统计相关超速信息,通过对超速持续时间以及超速行为之间的间隔距离来判断是否为违章超速行为,而非如超车等正常超速行为[9]。为判断超速行为是否为违章超速行为,引入违章超速行驶行为距离判断阈值ɑ与界定时长δ,按照行业判定经验取:
a≥500 m,δ≈30 s
(1)
根据超速行为行驶距离di引入“违章超速”特征值k,k=1表示违章超速,k=0表示未违章超速:
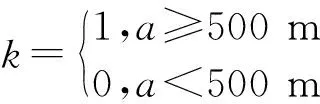
(2)
将市区内行车速度按其大小值分为4个等级:低速(v≤20 km/h),中速(20 km/h
1.1.3 急加/减速驾驶行为特征提取
在交通运输行业相关法规中,急加/减速行为并不属于违法违规行为,但经常性的急加/减速行为对制动系统及系统部件都有损害,并且急加/减速行为发生次数也是判断司机开车是否平稳的标准之一,对驾驶安全也有一定程度的影响。因此,在全局运动特征提取的基础上,根据点pi、pi+1间速度vi、vi+1和时间间隔Δti计算点pi+1的加速度值,Δti要求不大于2 s,如式(3)所示。若Δti过长,则无意义。
(3)
查阅司机驾驶行为“急加/减速”判定标准,将加速度按其大小值分为4个标准等级:一级标准(ai≥2.78 m/s2,持续时间≥2 s),二级标准(2.22 m/s2≤a<2.78 m/s2,持续时间≥2 s),三级标准(1.67 m/s2≤a<2.22 m/s2,持续时间≥2 s),四级标准(ai<1.67 m/s2,持续时间≥2 s)。因此,本文根据加速度等级增加4个one-hot特征。
根据2个数据点pi与pi+1速度差值的正负判断位置点处于加速或是减速,提取“加速/减速”特征,并根据2个数据点pi与pi+1之间的时间间隔Δti,增加“加速度持续时间”特征。
1.1.4 变道驾驶行为特征提取
在变道过程中,高速行驶状态下的车辆转向角度是很小的。因此,在提取出数据点全局特征的基础上,还需计算出2个数据点之间行驶路线的弯曲程度和转角。其中曲率si为两位置点pi与pi+1之间的移动距离与其直线距离之比,表示两点之间路径的弯曲度,如式(4)所示。
si=(dist(pi-1,pi)+dist(pi,pi+1))/dist(pi-1,pi+1)
(4)
位置点的方向由数据集提供,表示每个位置点在当前位置从正北方向顺时针旋转的角度Δθi。转角Δθi指连续2个位置点间方向转动角度,根据两点各自的方向信息θi与θi+1进行差值计算所得,如式(5)所示。
Δθi=|θi+1-θi|
(5)
两位置点的方向与转角示例图如图2所示。

图2 位置点P1与P2的方向与转角示例
根据一条轨迹为t=
1.1.5 各特征统计量计算
在已有的距离、速度、加速度、曲率、转角5个全局运动特征的基础上,分别计算其对应的13个数学统计量:均值,中值,标准差,变异系数,最大3个数,最小3个数,自相关系数,偏度系数和峰度系数。其中,用变异系数来衡量数据的离散程度。计算最大/最小的3个数[10]是为了考虑定位系统获取的GPS数据存在定位精度和误差的因素。偏度系数和峰度系数用来分别衡量统计分布的左右对称性和形状的陡峭程度[11]。自相关系数是用来度量2个位置点在时间上的相关程度[12]。一条轨迹的时间序列可表示为xt∈{x1,x2,…,xn},为计算其自相关系数,可先用式(6)计算自协方差系数{ck},其中,k为时滞长度,N为序列长度。再利用式(7)计算时滞为1时的自相关系数。
(6)
r1=c1/c0
(7)
偏度系数与峰度系数的计算可参考文献[11]。最后,对5个全局运动特征分别计算其对应13个统计量。图3显示了部分运动特征及其统计量结果。

图3 部分运动特征及其统计量
1.2 基于结构距离的相似度度量方式
当检测目标为运动位置点表现出的驾驶行为的异常情况时,不能直接采用常用的轨迹之间的相似度度量方式[13-14]。本文借鉴图像质量评价中的结构相似度(Structural Similarity,SSIM)[15]思想,采用SSIM方法来度量数据点驾驶行为特征之间的距离。
结构距离(Structure Distance,SDist)指对轨迹结构各个特征属性分别采取不同的距离计算方式来计算,最后结合为一个距离计算标准。本文数据点包含6个全局特征,其轨迹结构为pi=
定义W={Wt,Wv,Wd,Wa,Ws,Wθ,Wo}为各部分特征权重向量,分别对应轨迹的特征向量。通过这7个部分的距离构成了轨迹相似度的计算,如式(8)所示。其中,时间距离采用余弦相似度度量方式计算。位置距离采用欧氏距离计算。速度和加速度均采取各统计量和的平均。曲率和转角均采用差的绝对值衡量。
SDist(pi,pj)=Wa×timeDist+Wv×speedDist+
Wd×locDis+Wa×accDist+
Ws×curDist+Wθ×
angleDist+Wo×Dist
(8)
由于轨迹中每个特征的值域不同,需要对结构距离进行归一化处理,如式(9)所示,其中Normalized()为距离的归一化函数。因为两点间的结构相似度是对称的,所以SSIM(pi,pj)=SSIM(pj,pi)。
SSIM(pi,pj)=1-Normalized(SDist(pi,pj))
(9)
下文将针对超速、急加/减速、急刹车、违章变道等典型异常驾驶行为,在已有的全局和局部特征以及相似度度量方式的基础上,分别进行凝聚层次聚类与异常检测。
2 基于多特征的聚类与异常检测
2.1 基于多特征的凝聚层次聚类算法
聚类是将抽象的数据集划分成由相似数据构成的若干个对象集或者簇,使数据对象在同一簇中相似度越大,类间相似度越小,聚类效果就越好。聚类分析是异常行为检测的基础,在传统的基于聚类的异常点检测方法中,对象是否被检测为离群点很大程度依赖于簇的个数[16]。聚类算法中有部分算法需设定初始聚类中心和聚类数目,不能自动确定簇的个数,聚类结果不稳定。
凝聚层次聚类算法具有聚类准确率高、聚类结果稳定的优点,无需选取初始聚类中心和设定任何参数。但其计算复杂度大,为了降低复杂度,自动确定聚类数目,本文在层次聚类方法中引入拉普拉斯特征映射思想自动确定聚类簇数。
2.1.1 拉普拉斯特征映射
步骤1通过特征相似矩阵Sn×n构造拉普拉斯特征矩阵Ln×n=D-1/2Sn×nD-1/2,其中矩阵D为由矩阵S获得的对角矩阵。
步骤2对Ln×n矩阵进行特征值分解并按降序排列λ1≥λ2≥…≥λn;计算相邻特征值之差,若第i个特征值和第i+1个特征值之间差异最大,则确定聚类个数k=argmax|λi+1-λi|。
步骤3构造m×k矩阵Lm×k=[l1,l2,…,lk],其中lk为矩阵Ln×n的前k个特征值对应的特征向量;然后对Lm×k矩阵进行归一化处理,得到矩阵X=[x1,x2,…,xm]后再对低维数据xi进行后续聚类。
2.1.2 凝聚层次聚类
在对特征矩阵进行拉普拉斯变换后,根据降维后的特征矩阵及聚类数进行最后的层次聚类。基于凝聚的层次聚类算法的伪代码如下:
算法CURE层次聚类
输入数据集D={p1,p2,…,pn}
输出k个聚类簇及质心
1.3.3 患儿治疗依从性评价 由于哮喘患儿是特殊群体,其对于治疗的依从性是针对于家属,临床药师对实验组患儿家属在1年时间内,每个月评估其治疗的依从性,以能够稳定持续用药为较好,以分值5分表示;以虽未能持续稳定进行药物治疗,但对于疾病控制仍存在相应的重视及治疗为一般,以分值3-4分表示;对于用药治疗频率较低,完全不能按照疗程进行治疗为较差,以分值1-2分表示。
1.对数据集建立点与点之间的距离矩阵Sn×n。
2.根据上述步骤1~步骤3,得到低维数据矩阵X及其聚类个数k。
3.loop
4.将每个对象归为一类,得到n类,每类包含一个对象。
5.将距离矩阵Sn×n中的值升序排列,选取最小距离的2个类合并为一个类。
6.重新计算新类与旧类之间的距离。
7.重复前三步,直到最后合并成一个类或达到设定条件则退出循环。
8.输出k个聚类簇及其质心。
2.2 基于类标记的异常检测算法
正常驾驶行为有较高的重复性和相似性特点,而异常驾驶行为相较正常驾驶行为可能因不同场景和交通状况而表现出不同,与正常模式匹配存在很大的差距。在聚类结果中,有些簇的规模可能很小,在无法区分噪音和离群点下,本文将这些簇标记为异常。由上一节的聚类簇结果,在设定参数α的条件下,根据阈值标记簇为正常或异常簇,再将待测点与簇进行对比检测。
2.2.1 簇结果标记
文献[18]定义了大小簇的概念,假设C={c1,c2,…,ck}为簇集,簇成员个数记为|ci|,将其按成员数目降序排序得到{|c1|>|c2|>…>|ck|};给定参数α,当|c1|+|c2|+…+|cb|≥αn(n为原始数据集数目)时,则定义b(1≤b≤k-1)为大簇LC与小簇SC的边界。那么,可以将簇标记为大簇LC={ci|i≤b}与小簇SC={ci|i≥b},并将ci(i≤b)标记为正常簇,ci(i≥b)标记为异簇。计算大小簇边界的算法伪代码如下:
算法计算大小簇边界
输入聚类簇及簇内数据,参数α
输出簇边界b
1.计算各簇ci的成员个数|ci|(i=1,2,…,k),并对|ci|按降序排序,设置参数α
2.for(i=1;i≤k;i++)
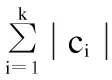
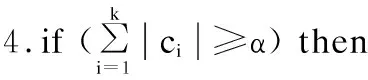
5.记录大小簇边界b并跳出循环
6.end for
2.2.2 异常检测算法
假设某车辆的一条轨迹数据为t={p1,p2,…,pm},m指该轨迹长度。计算每个点pi与所有簇之间的距离dist(pi,cj)并找到距离最小的dist(pi,cmin)。若dist(pi,cmin)大于簇半径R,则将该位置点标记为未知属性点,重新计算簇半径,将R′记为新的簇半径;否则找出簇cmin所属簇的标记,若标记为正常则点pi为正常点;若标记为异常则点pi为异常点。
3 实验与结果分析
3.1 实验环境设置与数据准备
实验环境:Windows10操作系统,Intel Xeon 2.50 GHz CPU,16.0 GB内存。开发环境:Microsoft Visual Studio 2008,Matlab12,Anaconda2.0。采用Matlab统计学工具箱计算方向和转角的统计量,其他特征采用python计算,并采用python语言对数据点进行聚类分类及后续异常检测。
实验数据采用真实的西安市2016年的商用车运行GPS数据,包括时间、经度、纬度、速度、方向等信息。实验选取经度在lon∈[108.7,109.2]、纬度在lat∈[34.1,34.5]范围的西安市区内数据,共包含59 999个轨迹点即4 953条轨迹,实验中将2/3的数据作为训练数据集,其余数据为用以验证与调 整聚类模型准确率及其他性能的验证数据集。
3.2 结果分析
3.2.1 聚类结果
图4所示为本文基于多特征凝聚层次聚类结果与文献[19]中基于因子分析的驾驶行驶聚类结果对比。其中用黑色实线框标出两处聚类细节,可以看出图4(a)中将一段道路上的GPS数据点聚类为同一类簇,而在图4(b)中更细致地区分了轨迹点之间的差异。

图4 文献[19]方法与本文方法聚类结果对比
对于本文采用的聚类算法,针对超速驾驶行为从聚类准确率与算法执行时间2个性能上,与文献[19]中的基于多特征的两层聚类算法进行比较,比较结果如图5所示,其中聚类准确率采取将聚类结果与手动标记的245个数据点进行比较的方式计算。
聚类准确率评估结果如图5(a)所示,从中可以看出,聚类准确率随着轨迹数据规模的增大而增大。当轨迹数目达到800左右,轨迹点数为9 948时,2种方法的聚类准确率趋于稳定,本文方法的聚类准确率在95%左右,文献[19]的聚类准确率在88%左右。由实验结果可知,本文的聚类算法与文献[19]采用的方法比较在聚类准确率上有一定的提高。由于本文方法同时采用了数据点的时间全局特征、两点间行驶距离、速度大小、速度行业设定等级、是否违章超速及其统计量等与速度相关的完备因素来衡量驾驶行为间的相似度,更好地提取数据点聚类的特征工程。
执行效率评估结果如图5(b)所示,从中可以看出,随着轨迹数据量的增大,本文方法在聚类效率上的优势就越加明显。当轨迹数目达到1 000条时,本文方法的聚类时间减少了24%左右。这是因为本文方法在数据点聚类前将数据划分到多个网格区域,后期同步执行聚类算法,且在计算数据点间的相似度时引入谱聚类中的拉普拉斯映射思想,降低聚类数据集的维数并能自动确定聚类数目。因此,本文方法相比文献[19]方法在聚类准确率和效率上有一定程度的提高。
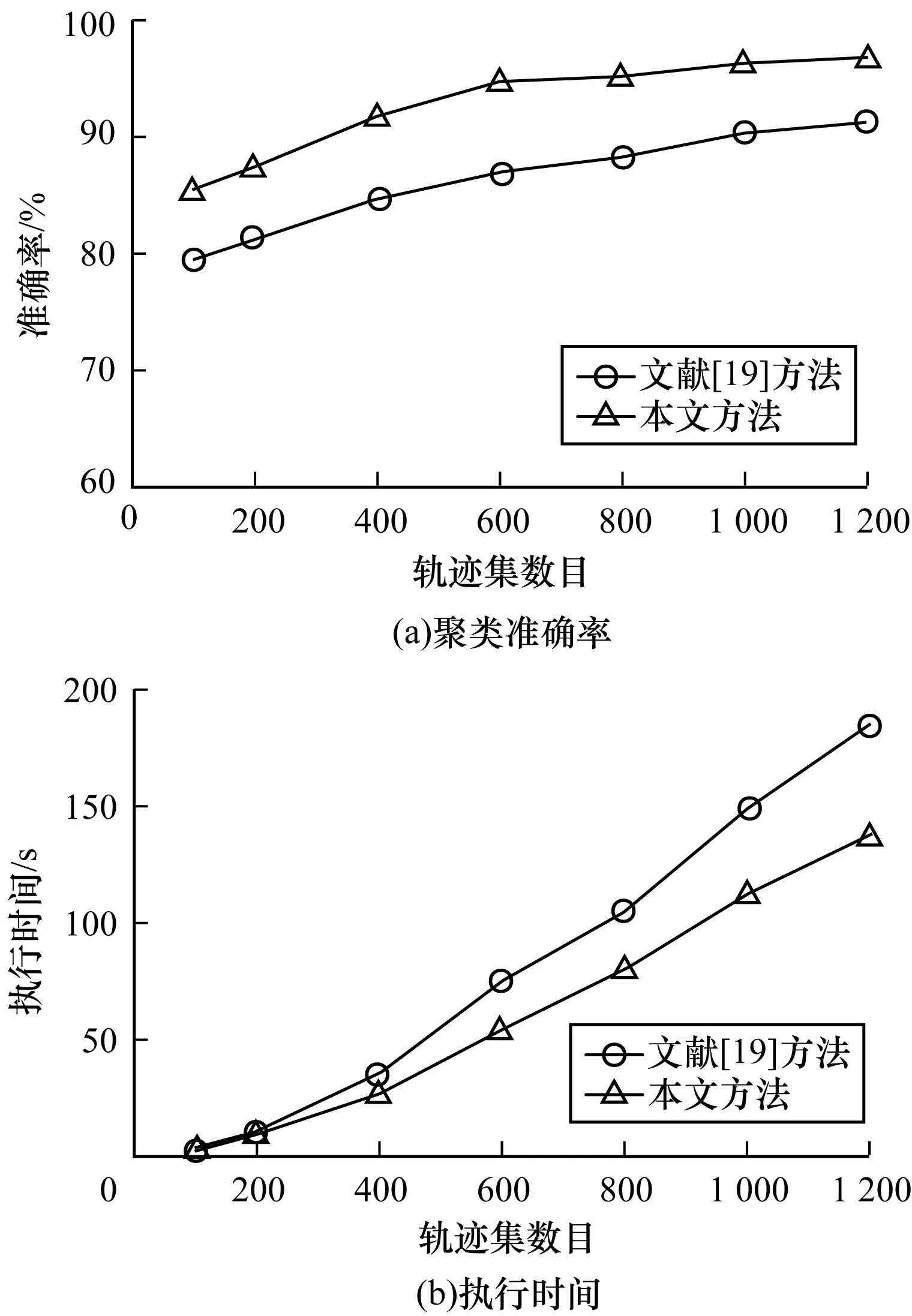
图5 聚类算法性能对比
3.2.2 异常驾驶行为检测结果
图6所示为验证数据集中针对超速驾驶行为异常检测结果。其中,灰色点是表现为正常的数据点,“×”为检测出的异常点。实验数据采用训练数据集与验证数据集生成的聚类簇作为模型库。对于测试数据集,由于不能采集到及时的商用车GPS数据,因此采取在测试车辆上安装GPS定位器的方法采集人为的异常驾驶数据,包括超速、急加/减速、突然左/右变道等几项驾驶异常行为。实验中让3位志愿者司机共做了20次超速驾驶、40次变速驾驶(包括加速/减速)、20次变道,其余100次为正常行驶实验,共2 000个数据点。
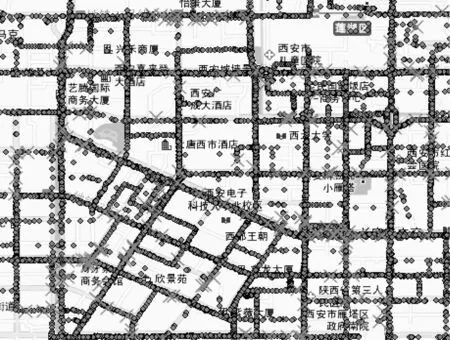
图6 验证数据集检测结果示例
将本文方法与文献[20]基于各类异常指标的驾驶行为异常检测方法进行对比,实验结果如表1所示,其中,M1指检测为异常驾行为的数目,M2为正确检测为异常驾驶行为的数目。从中可以看出,本文方法的平均检测准确率高于文献[20]中提出的基于各类异常指标的异常检测方法。因为文献[20]采用的异常检测方法是根据已有的一些经验指标来设定各类异常的阈值,对数据的测试有很强的人为主观因素。而本文方法的检测结果是将待测数据集与基于训练数据集和验证数据集获得的模型库进行比较获得,在对数据集进行训练时是基于提取的各类全局与局部运动特征以及相关统计量等因素,将 “多且相似”的正常的驾驶行为都将归为一个簇,而训练中的异常数据也将归为异常簇,因此,测试时不受人为客观因素的影响,检测准确率更高。

表1 检测准确性对比
4 结束语
基于GPS数据挖掘,本文针对商用车司机5种典型的异常驾驶行为进行检测。在最大化提取每个位置点驾驶行为特征的基础上,采用基于聚类的异常检测方法使准确率和效率得到提升,且异常检测准确率相比传统设定阈值的方法更高。但本文对算法的检测性能分析是建立在实验采集的异常数据集上,不包含商用车司机驾驶车辆时的一些实际信息,使检测准确率受到影响,下一步将对此进行改进。
