基于位存储Tid的CPU并行化Eclat算法
2019-01-02孙宗鑫张桂芸
孙宗鑫,张桂芸
(天津师范大学 计算机与信息工程学院,天津 300387)
0 概述
频繁项目集挖掘(Frequent Itemset Mining,FIM)在关联规则挖掘算法中具有重要的位置,其典型算法有AIS、Apriori、AprioriTid[1]、DHP[2]、Toivoen、Eclat[3]和FP-Growth算法[4]等,总体可分为3大类,分别为基于水平数据格式的Apriori系列算法[1-2]、基于垂直数据格式的Eclat系列算法[3,5-9]和基于树型数据格式的FP-Growth系列[4]算法。
Eclat算法由Zaki等人在2000年提出,该算法采用垂直数据表示方式且无需复杂的数据结构,因此,在频繁项目集挖掘效率方面优于Apriori系列算法,在内存消耗方面优于FP-Growth算法。然而,Eclat算法在挖掘频繁项目集过程中,需要大量内存对项目垂直事务标识(Transaction identifier,Tid)列表进行维护,同时交集计数的生成方式造成了算法对内存的大量消耗和挖掘效率的下降。针对上述缺点,诸多研究学者对Eclat算法进行了优化改进。文献[5]提出一种布尔散列的方法,将相交的2个垂直Tid列表映射到2个布尔列表中,使用布尔列表的标志元素判断2个垂直Tid列表是否存在交集,在一定程度上优化了垂直Tid列表交集过程,但由于布尔列表的使用,一定程度上也增加了内存消耗。文献[6]提出的Eclat_opt算法在传统的Eclat算法基础上引入了双层哈希表和剪枝策略,加快了频繁项目集的挖掘速度,但由于挖掘过程中需要在内存中长期维护一张索引二维表,因此导致内存消耗进一步增加。文献[7]提出的PEclat算法由于使用多核挖掘和算法选择策略,因此在内存消耗和挖掘速度两方面都得到了一定优化,但算法仍存在一些弊端。
本文针对以上优化算法存在的问题,在Eclat算法[8-9]的基础上,提出一种位并行化Eclat(Bit Parallel Eclat,BPEclat)算法。该算法采用二进制位存储结构[10-11]和动态分配挖掘任务的CPU并行挖掘模式[12-13],以提高频繁项目集的挖掘效率。
1 Eclat算法原理
事务数据库中数据的表示格式分为2种[14]:1)水平数据表示,如图1(a)所示,在水平数据表示的事务数据库中一条事务由唯一的Tid和单个或多个项目组成;2)垂直数据表示,如图1(b)所示,在垂直数据表示的事务数据库中一条事务由唯一的项目和包含此项目的所有Tid组成。

图1 2种数据表示格式
1.1 算法原理
Eclat算法是采用垂直数据表示格式的频繁项目集挖掘算法,同时引入了等价类的概念将搜索空间划分为多个不重叠的子空间,用深度优先搜索策略依次挖掘每个子空间内的频繁项目集。
Eclat算法在候选项目的生成中依然采用Apriori算法的链接方式,对2个频繁项目进行链接,与此同时对2个频繁项目的垂直Tid列表进行交集计数,从而可以使候选项目的支持度计算和候选项目的生成同时完成,加快了频繁项目的挖掘速度。
Eclat算法描述如下:
输入事务数据库DB,支持度阈值Min_Supp
输出所有频繁项目集L
步骤1扫描数据库计数挖掘频繁1-项目集L1和频繁1-项目集垂直Tid列表L1.Tid。
步骤2基于频繁1-项目集垂直Tid列表来挖掘剩余频繁K-项目集(k≥2)。
1.2 Eclat算法
1.2.1 内存消耗问题
在Eclat算法及其改进算法[5-7]中,多数存在内存消耗过高问题。Eclat算法和改进算法都采用整型数组存储Tid,当项目出现频率高且交易事务数过大时,算法在挖掘过程中需要大量内存来存储临时整型垂直Tid列表。此外,文献[5-6]改进算法分别使用布尔矩阵和二维表索引,在提高了挖掘频繁项目效率的同时更进一步增加了内存开销。文献[7]利用稀疏因子作为参数对Eclat和dEclat算法进行了选择使用,在一定程度上降低了内存消耗,但效果一般。
1.2.2 挖掘效率问题
Eclat算法和文献[7]改进算法计算候选项目支持度时采用垂直Tid列表进行交集计数方式,即遍历2个项目垂直Tid列表判断每个Tid是否相等,从而得出候选项目支持度,同时生成新的垂直Tid列表,交集计数方式效率低下。文献[7]改进算法虽然使用多核并行挖掘,但没有过多考虑多核之间负载均衡问题。
2 BPEclat算法原理
2.1 BPEclat算法及其改进
针对1.2节提出的Eclat及其改进算法的不足,本文提出以下3点改进策略:
1)二进制串垂直Tid列表(以下简称位垂直Tid列表)。为降低Eclat算法及相关改进算法对内存的消耗,对算法中垂直Tid列表以存储Tid的方式进行深度优化,将原有Tid由一个整数型记录变为由一个二进制位记录。Tid信息标记到与Tid相等的二进制串下标的位置,即将二进制串下标等于Tid的二进制位置1,格式如图2所示。其中,图2(a)为6个项目Tid列表(采用Uint16数组存储)占用空间(16×20)320位,图2(b)为存储6个项目Tid列表占用空间(6×6)36位。

图2 传统垂直Tid列表与位垂直Tid列表对比
2)Tid列表生成及支持度计数过程位(与)运算化。为提高候选项目垂直Tid列表生成速度和候选项目支持度计算效率,在策略1)提出的以位存储垂直Tid列表的基础上,深度优化Tid列表生成及支持度计算的过程,将以往采用2个垂直Tid列表交集计数来生成候选项目垂直Tid列表和计算候选项目支持度的方法,变为2个位垂直Tid列表的位(与)运算和位右移计数法。对比过程如图3所示。

图3 Tid列表生成原理对比
3)基于动态规划分配策略的多线程挖掘任务分配策略[15-17]。根据Eclat算法中的等价类,将并行挖掘分配与等价类对应,Eclat算法并行化的主要难点在于如何有效地保持线程间的负载均衡。因此,本文将动态规划分配方法应用到了挖掘任务分配阶段,在整个挖掘过程中为各线程动态分配挖掘任务,以确保线程间负载均衡。等价类划分多线程挖掘原理如图4所示。

图4 等价类多线程挖掘原理示意图
2.2 BPEclat算法实现策略
2.2.1 位垂直Tid列表的数据结构
BPEclat算法中项目位垂直Tid列表的存储形式实际采用的是Uint64数组类型(即:无符号64位int型数组,每64个二进制位用1个Uint64类型存储)。初始化存储项目位垂直Tid列表的Uint64数组长度为Max_Tid/64(Max_Tid为事务数据库DB中的事务数)。
2.2.2 位垂直Tid列表的生成
BPEclat算法在整个挖掘过程中位垂直Tid列表的生成包含2个阶段:
1)扫描数据库生成候选1-项目位垂直Tid列表(即位垂直Tid列表的初始化)。首先内存中维护一张hash类型位标识表Bit_64_map(见图5(a)),Bit_64_map中存储了64位无符号整数型(Uint64)第1位到第64位为1时对应整数值,将位垂直Tid列表相应二进制位所属整数值与Bit_64_map表中相应位整数相加,即可将项目位垂直Tid列表相应二进制位置为1,从而完成项目位垂直Tid列表初始化。
2)生成候选K-项目(K>1)位垂直Tid列表。此阶段采用2.1节中策略2)给出的优化策略来生成候选项目位垂直Tid列表。具体过程如图5(b)所示。
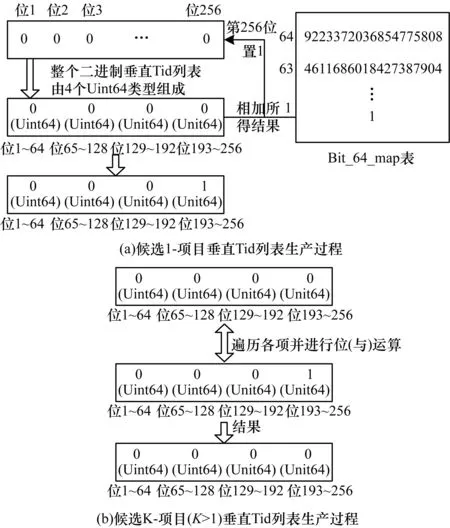
图5 位垂直Tid列表生成过程
2.2.3 候选项目的支持度计数
候选项目的支持度计数过程主要采用遍历+位右移计数的方法,遍历候选项目位垂直Tid列表中每个Uint64整数,对每个Uint64整数采用位右移计数法,最终得出位垂直Tid列表中二进制位为1的个数,即候选项目的支持度。候选项目的支持度计数过程与图5(b)中位垂直Tid列表的产生过程一同完成。
2.2.4 多线程挖掘任务分配
多线程挖掘任务分配方法如下:
1)等价类权重估算
xi的等价类[xi]的权重σ[xi]估算公式为:

2)动态规划分配方法的基本实现策略
由于硬件条件的限制,理想状态下为每个等价类分配一个线程并行挖掘各自等价类的频繁项目,在多数挖掘环境下无法实现(因为逻辑处理器数量<<等价类数量,而等价类数量与挖掘深度的平方成正比),因此算法在并行挖掘阶段采用动态规划分配方法,对挖掘任务进行实时分配以确保各线程的负载均衡。具体策略如下:
(1)挖掘任务初始分配。根据挖掘平台CPU核心及线程数同时计算每个等价类权重σ[xi],然后依据每个等价类权重σ[xi]把等价类分配到各线程进行频繁项目挖掘。
(2)各线程挖掘任务再分配。当检测到各线程当前工作线程数小于任务初始化的并行工作线程数时(一般等于挖掘平台的逻辑处理器个数),将随时采用挖掘初始任务分配策略依线程内的等价类权重进行再分配,以确保硬件资源满负荷工作。
采用动态规划分配方法进行任务分组,在一定程度上确保了各个线程间负载均衡。
算法整体流程如图6所示。

图6 BPEclat算法总体流程
3 实验结果与分析
3.1 实验环境与实验数据
实验环境为Sugon小型服务器,服务器配置信息如下:CPU为AMD 6234,48核2.4 GHz(实际使用4核),RAM为128 GB,OS为Windowsserver2012 R2,算法实现平台为VS2015,算法实现语言为C#。
为进行算法挖掘效率对比,使用以上平台及语言分别实现了文献[3]中的Eclat算法和文献[7]中的PEclat算法。实验选取了如表1所示的4个数据集,T10.I4.D100K和T40.I10.D100K数据集是使用IBM_Quest_data_generator合成的稀疏型数据集,Mushroom和Chess数据集则来自UCI数据仓库和fimi.ua.ac.be的密集型数据集。
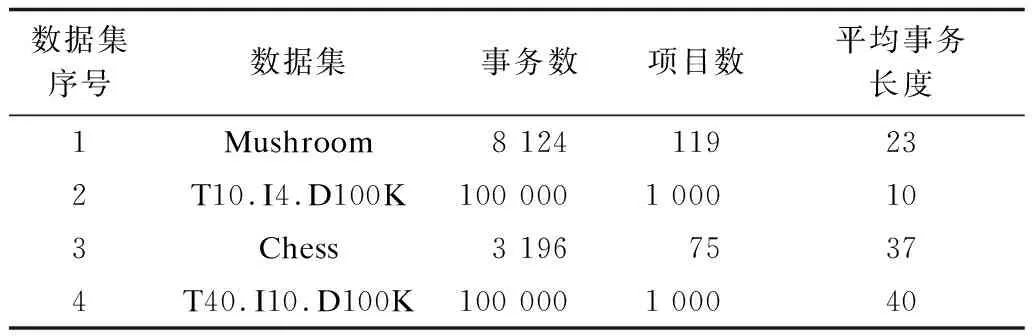
表1 实验数据集主要特征
3.2 结果对比分析
3.2.1 算法结果对比
图7~图10为算法在4个数据集上运行时间和内存消耗的实验结果。

图7 3种算法在数据集1上的运行时间和内存消耗对比
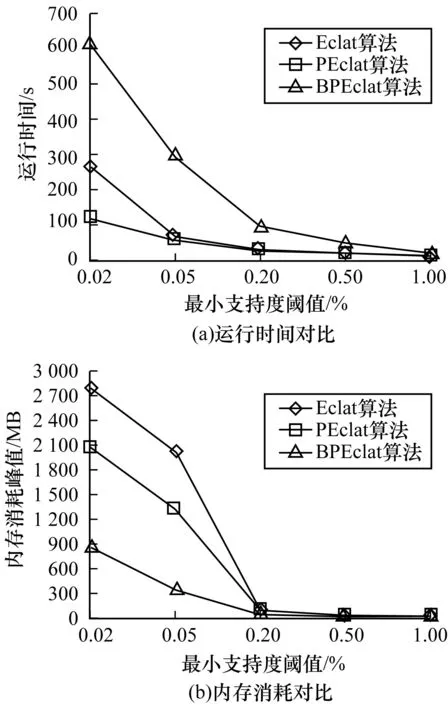
图8 3种算法在数据集2上的运行时间和内存消耗对比

图9 3种算法在数据集3上的运行时间和内存消耗对比
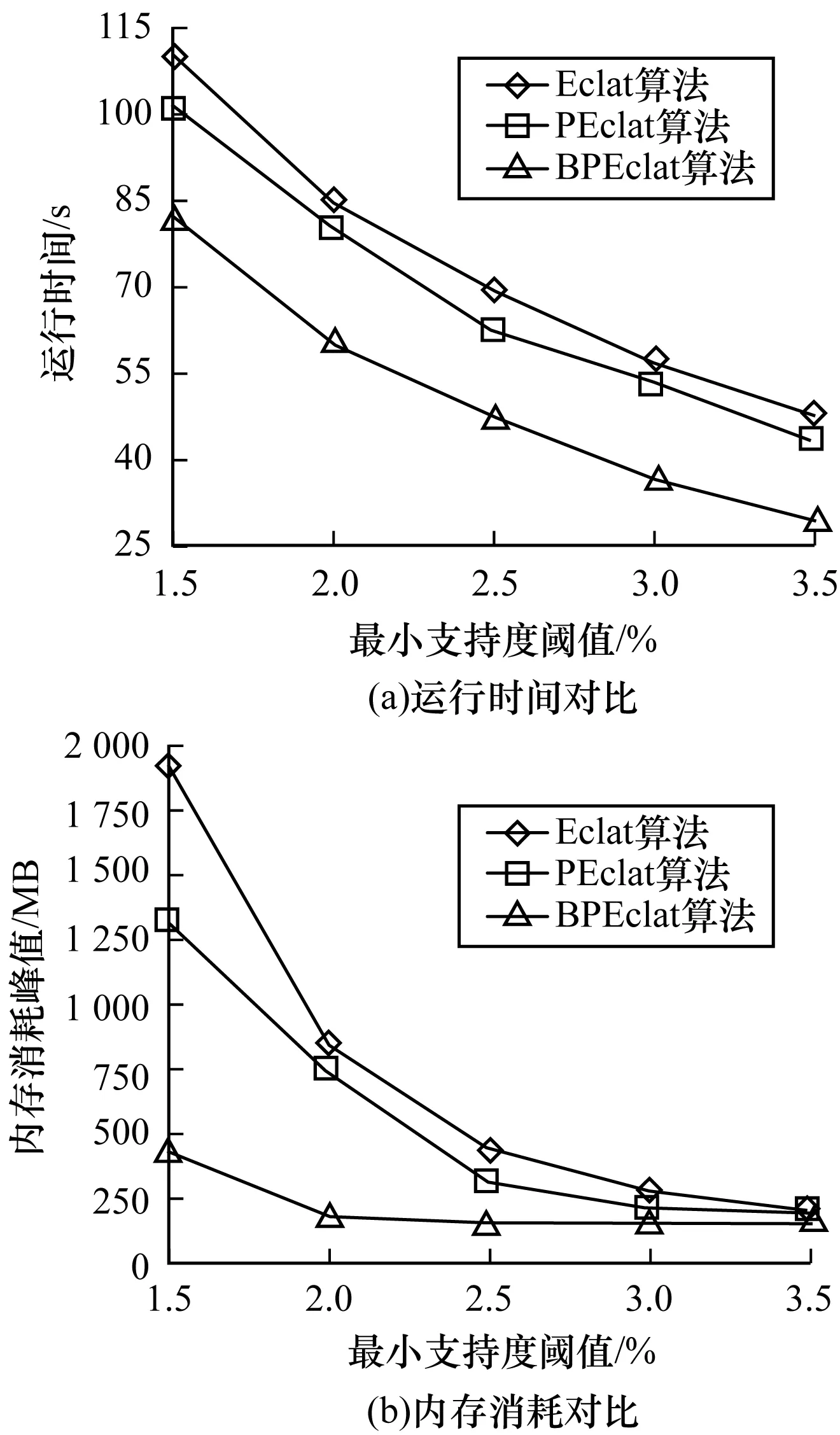
图10 3种算法在数据集4上的运行时间和内存消耗对比
实验中PEclat算法和Eclat算法的每个项目垂直Tid列表均采用Uint32数组类型存储Tid列表。
3.2.2 算法结果分析
Eclat算法分析结果如下:
1)由实验得出BPEclat算法在4个数据集上内存消耗对比(Eclat/BPEclat、PEclat/BPEclat),在图7(b)、图8(b)、图9(b)、图10(b)中依次为:(11.7,5.3),(2.9,2.2),(28.8,16.9),(3.1,2.4),在稀疏型数据集上算法空间复杂度平均降低15倍左右,在密集型数据集上算法空间复杂度平均降低2.5倍左右。
从以上对比结果可得,采用位存储Tid的BPEclat算法在内存消耗方面远远优于Eclat算法和PEclat算法,即使在多核多线程的挖掘模式下,内存消耗依然控制在较低水平。BPEclat算法在内存消耗方面的优越表现在稀疏型数据集上尤为突出。
2)由实验得出BPEclat算法在4个数据集上运行时间对比(Eclat/BPEclat、PEclat/BPEclat),在图7(a)、图8(a)、图9(a)、图10(a))中依次为:(1.9,1.7),(0.4,0.3),(1.6,1.3),(1.5,1.4),在稀疏型数据集上算法时间复杂度平均增加0.1倍左右,在密集型数据集上算法时间复杂度平均降低1.6倍左右。
通过以上运行结果可以看出,在T10.I4.D100K数据集上(图8(a))BPEclat挖掘效率下降。通过分析挖掘过程中的临时数据后发现,T10.I4.D100K数据集的频繁K-频繁项目(K>3)较少且大部分频繁2-项目支持度过低(算法在支持度为0.02%时产生了70 764个频繁2-项目,大约99%的频繁2-项目支持度小于200),而针对T10.I4.D100K数据集的10万条记录,初始化每个项目位垂直Tid列表都要使用1 563(100 000/64+1)个Uint64,每个列表的平均占用率小于12%,算法对每个项目的位垂直Tid列表一次遍历的元素个数远大于Eclat算法和PEclat算法,从而导致BPEclat算法在T10.I4.D100K数据集上的运行效率不如其他2种算法。因此,BPEclat算法在对频繁K-项目集(K>2)较少,且事务数据库事务数较大的数据库进行频繁项目集挖掘时,挖掘性能表现不佳。
综合3种算法在4个实验数据集的实验对比可以验证,BPEclat算法一定程度上提高挖掘效率,大大优化了内存的消耗。
4 结束语
Eclat算法是基于垂直列表的频繁项目集挖掘算法,本文在分析Eclat算法及其现有改进算法基础上,提出一种位存储事务标识的CPU并行化Eclat算法。该算法使用二进制位存储Tid和基于动态任务分配策略的并行挖掘模式,最大限度地提高CPU的运算性能。实验结果表明,该算法在降低内存消耗的同时提高了频繁项目集的挖掘效率。但由于算法使用的多线程任务分配策略存在缺陷,在四核CPU下并行挖掘的平均加速比依然小于2.5(最优值为4),今后将在以下2个方面进行改进:完善BPEclat算法的多线程任务分配策略,提高算法在并行挖掘下的加速比;研究BPEclat算法的分布式并行模式,将BPEclat移植到分布式处理平台上,以适应大数据下的频繁项目集挖掘。
