基于传感器网络的1比特RLS算法*
2018-12-26彭秋燕刘兆霆姚英彪
彭秋燕,刘兆霆,姚英彪
(杭州电子科技大学通信工程学院,杭州 310000)
由大量传感器节点组成的无线传感器网络在环境监测、目标定位和跟踪等领域具有广泛的应用。这些应用所涉及的理论问题一般可以归结为是从传感器采集的测量数据中估计未知的物理量参数,并且随着无线传感器网络的快速发展,该问题已经吸引了大量国内外学者的关注。通常情况下,无线传感器网络中每个传感器节点由电池供电,其计算、通信和信息存储能力有限[1],另外,网络的通信带宽也是一个有限的资源。这使得如何基于传感器网络获得有效的参数估计,同时尽可能降低网络的使用成本问题成为一个具有理论意义和实用价值的研究热点。
解决此问题的其中一个研究方向是将每个传感器节点的测量值压缩为1比特或多比特的信息,然后利用这种压缩后的数据,设计相应的算法实现参数估计。与未经量化的模拟测量值相比,压缩后的1比特测量值虽然仅含有非常有限的信息量,但通常可以通过更便宜的二进制传感器来获取,并且能够降低设备的存储容量和减小网络的通信带宽。目前,国内外已有大量基于1比特参数估计算法的研究,例如,在被估计参数是一个标量的情况下,人们提出了许多参数化方法[2-4]和非参数化方法[5-7];在被估计参数是一个矢量的情况下,人们提出了回归参数的1比特估计方法[8,9],1比特系统辨识方法[10,11],1比特压缩感知算法[12-16]等。
这些现有的方法都有各自的优点,但它们一般都依赖于某些假设,如噪声方差已知[3,4]、噪声的累积分布函数可逆[5,11]、量化器的输入不含噪声[13,15,16]、未知参数的动态范围已知[6]、模型中使用的量化器阈值为零[9,12]等。这样的假设在许多实际情况下并非总是成立的。例如,Wigren T[14]提出了一种利用1比特测量值的归一化随机梯度自适应滤波方法,但是该方法假设量化器的输入端不存在测量噪声,在噪声存在的情况下不能保证收敛。此外,大部分现有的算法大都是批处理方法,很少考虑基于1比特测量值的在线参数估计问题。在线处理相对于批处理方案具有更低的复杂性和存储要求,并且能够实现对慢变参数的估计。虽然Zayyani H等[16]将输入矢量乘以估计矢量的符号函数与1比特测量值之间的最小均方误差准则用于压缩感知中1比特测量值的在线稀疏参数估计,但是该准则也不能为所得的估计性能提供强有力的理论支持。
在自适应滤波中,递归最小二乘RLS(Recursive Least Square)算法在收敛速度和估计精度方面均优于最小均方LMS(Least Mean Square)算法。然而,基于1比特测量值的RLS参数估计算法很少有报道。本文提出了一种基于无线传感器网络1比特测量值的自适应RLS参数估计算法。该算法结合了期望最大EM(Expectation Maximization)和递归最小二乘法,具有与经典RLS算法几乎相同的稳态性能。
1 传感器网络和信号参数估计模型
假设一个由K个节点组成的传感器网络,每个节点能够与一个共同的融合中心FC(Fusion Center)进行无线通信,且每个节点k在每个时刻i能够获得对某一感兴趣信号的测量值yk,i:
(1)
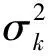
如引言所述,为了降低网络的通信带宽和节点的能量消耗,本文考虑每个传感器节点不直接传输测量信号yk,i,而是先将其与一个门限值进行比较,然后向FC报告测量信号是大于该门限(用1表示),还是小于该门限(用-1表示),即每个节点向FC传输1比特数据dk,i:
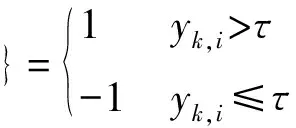
(2)
式中:τ是选定的门限值。另外,正如Chi Y等[17]以及Konar A等[18]的做法,本文进一步假设,每个传感器节点的输入矢量uk,i是由随机序列发生器根据不同的随机种子产生的,并且FC已知每个随机种子,从而可以同步复制每个传感器节点的输入矢量uk,i。本文的主要目的是利用各个节点传输给FC的1比特数据{dk,i}来实现对未知参数w0的自适应估计。
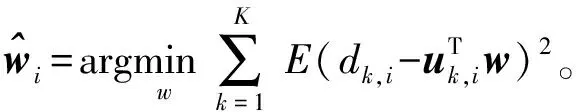
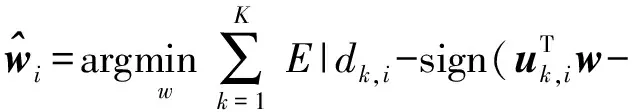
(3)
然而,当噪声vk,i存在时,(3)不能保证参数的估计性能。因此,本文将从最大似然估计(Maximum Likelihood Estimation,MLE)原理推导一种基于期望最大和递归最小二乘的自适应参数估计算法。
2 最大似然估计方法
此节首先给出一种基于随机梯度SG(Stochastic Gradient)迭代和Probit模型的最大似然估计方法,然后推导出一种基于权重的最大似然估计算法。
2.1 基于Probit模型的最大似然估计(Probit-MLE)
式(1)可以看作是dk,i条件概率的Probit回归模型,即
式中:Φ(·)是标准正态分布的累积分布函数,且γk,i根据最大似然估计原理,可以从测量值{dk,i}中得到w0的估计值,即基于Probit模型的最大似然估计器的解为:
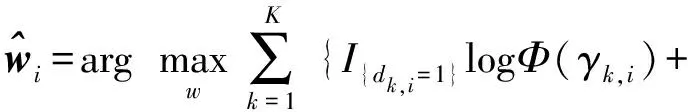
(4)
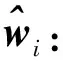

2.2 基于权重的最大似然1比特RLS算法
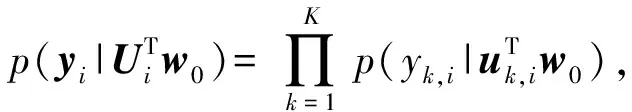
(5)

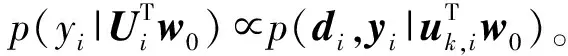
(6)
随后把数据{yj}作为隐藏变量,并通过EM算法解决问题(P2)。
2.2.1EM算法
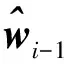
E步:
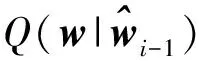
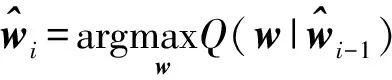
式中:Ey[·]表示对{yj}的数学期望。在E步中,利用(5)和(6)之间的等价关系,可得

(7)
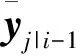
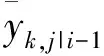
(8)
根据式(7),M步可以简化为
(9)
式中:
Ri
(10)
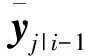
由于事件dk,j=-1和dk,j=1是互补的,且分别等效于事件yk,j≤τ和yk,j>τ,因此,从定义式(8)可以得到
引理给定一个具有标准正态分布的随机变量v和一个常数a,v和v2的条件期望满足:
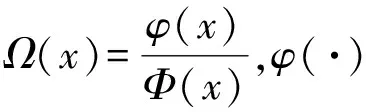
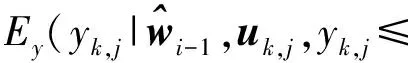
式中:γk,j|i-1同样地,可以推出τ以上两种情况可以统一表示为
2.2.3OB-RLS算法的总结
(11)
并结合矩阵求逆引理[22]来实现逆矩阵Pi的循环更新。然而,根据定义式(10),矢量bi不满足类似(11)的更新规则,且随着迭代次数i的增大,矢量bi的计算量也将越来越大。为此,可以利用近似(10)中的从而获得这是由于与作为w0的估计值通常近似相等,并且当j接近i时,两者相差越来越小,使得与也近似相等,并且当j接近i时,两者相差也逐渐减小。即使当j远小于i时,可能与有所差异,但由于权值λi-j的存在,这种差异的影响会随着i-j的增大而减小。因此,即可得到
(12)
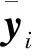
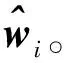

OB-RLS算法初始化:令^w0=0,P0=δIM。算法迭代:在每个时刻i,FC获得从 K个传感器节点发送过来的1比特数据流{dk,i},并且按照下列步骤更新参数估计值^wi:(A1)时间循环^wi=^wi-1,Pi=λ-1Pi-1(A2)节点循环for k=1,2,…,Kyk,i=uTk,i^wi-1+dk,iσkΩdk,iuTk,j^wi-1-τσk()sk,i=Piuk,i1+1KuTk,iPiuk,i^wi←^wi+1K(yk,i-uTk,i^wi)sk,iPi←Pi-1Ksk,iuTk,iPiendi=i+1,返回(A1),直至收敛。
3 性能仿真分析
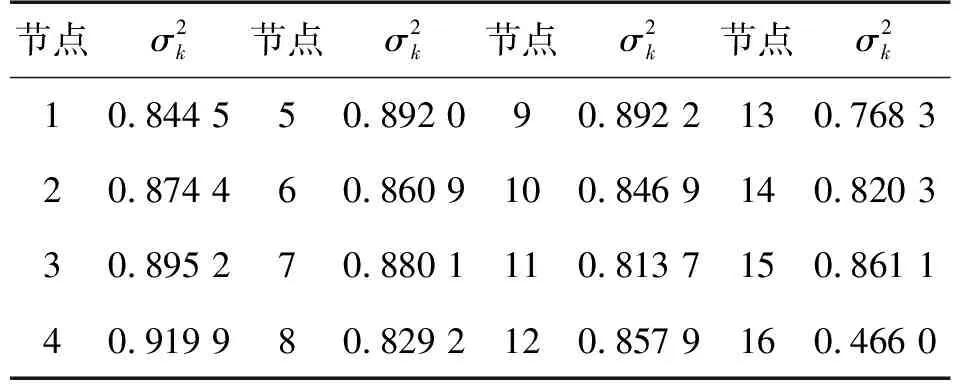
表1 所有传感器节点的噪声方差
图1给出了OB-RLS算法的瞬态MSD与迭代次数i的关系,并且考虑了设置不同的阈值情况。从图中可以观察到,虽然OB-RLS算法仅使用了1比特量化测量值,但在稳定状态时仍能达到和传统RLS算法几乎相同的估计精度。另外,从图1中还可以看出,OB-RLS算法的收敛速度比传统RLS算法慢,但是设置较小的阈值(绝对值)有利于提高收敛速度。
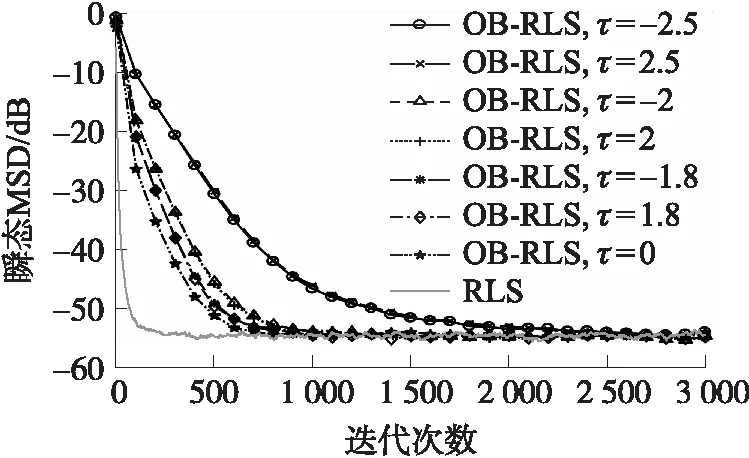
图1 传统RLS和OB-RLS的瞬态MSD
图2对比了4种算法的瞬态MSD。这4种算法分别是:符号滤波算法(3)、Probit-MLE算法(4)、传统RLS算法(使用未经量化数据yk,i)以及本文提出的OB-RLS。设置传统RLS和OB-RLS算法的遗忘因子 λ=0.98,Probit-MLE和符号滤波算法的步长分别为0.03和0.3。从图中可以看到,Probit-MLE算法的估计精度比符号滤波算法高,但两者的精度都比本文所提出的OB-RLS算法低。
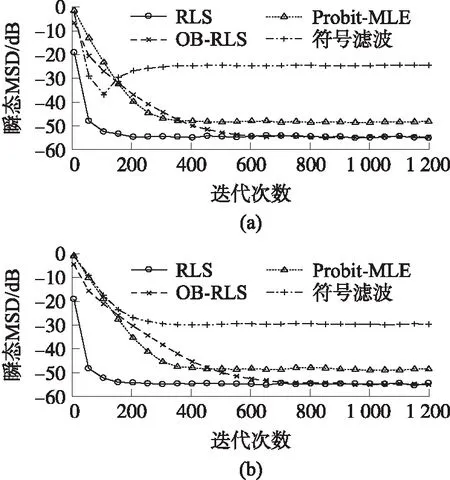
图2 4种算法的瞬态MSD对比
图3进一步显示了在不同阈值下,3种算法的稳态性能。设置OB-RLS算法的遗忘因子λ=0.98,Probit-MLE和符号滤波算法的步长分别为0.03和0.3。从图中可以观察到,当阈值τ由-2.5增加到2.5的过程中,符号滤波算法的性能波动较大,对阈值τ比较敏感,而OB-RLS算法和Probit-MLE算法的估计性能比较稳定,并且在这个过程中,本文的OB-RLS算法始终有更低的估计误差。
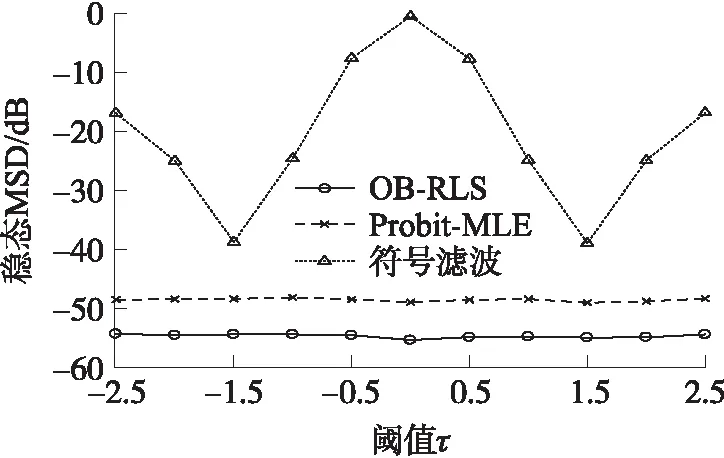
图3 不同阈值下的稳态MSD
4 结论
本文研究了基于传感器网络的自适应参数估计问题,提出了一种利用传感器节点1比特测量值的OB-RLS算法。为了降低各节点的能耗、存储资源,以及到中心处理器的通信带宽,首先将各节点采集的测量信号压缩为1比特数据,然后再发送给中心处理器。在中心处理器中,采用文中所提出的OB-RLS算法来获得对感兴趣参数的自适应估计。该算法结合了期望最大化的思想和递归最小二乘方法,相比符号滤波算法和Probit-MLE算法有较低的估计误差和较好的稳定性,且和传统RLS算法估计精度相当。论文通过MATLAB仿真实验,验证了算法的性能。
