基于脚部惯性传感数据的人员运动速度识别方法*
2018-12-26吴建超
吴建超,刘 昱
(天津大学微电子学院 天津 300072)
随着微机电系统MEMS(Micro-Electro-Mechanical System)的迅速发展,组合了加速度计和陀螺仪的惯性传感单元IMU(Inertial Measurement Unit)被学者建议固定在人体的不同位置来进行人员航位推算PDR(Pedestrian Dead Reckoning)[1]。其中的一种步长-航行系统SHSs(Step-and-Heading Systems)已经被学者广泛用于对行人进行运动轨迹的追踪。SHSs的主要基础包括:识别单步数据子集、估计单步步长、估计单步航向或航向变化[2]。由于人员运动速度与步长呈正相关,且相关性十分显著[3]。所以人员运动速度无疑是SHSs系统中的一个重要参数,识别运动单步的速度对于提高SHSs系统的精度有重要作用。
由于人员在行进过程中下肢会经历一个周期性变化[4],所以许多利用IMU进行速度估计的方法建议将IMU固定在人员下肢,利用步态周期中的关键阶段,例如脚掌着地、小腿竖直等来估计相应的行进速度[5]。当前利用固定在下肢的IMU进行速度估计的方法主要有两类:①利用人体步态模型[6];②直接积分[7]。利用预先定义好的人体步态模型来估计速度是一种被广泛采用的速度估计方法,这种方法根据固定在下肢的IMU获得的惯性数据来确定下肢的运动学信息,结合人体步态模型间接的获得步长。例如根据固定在下肢的IMU获得一条腿的臀部前后摆动的周期,采用倒立摆模型估计速度[8],该方法的速度估计结果严重依赖于步态模型的设计,并未被学者广泛采用。第2种直接积分的方法是首先利用固定在下肢的IMU获得IMU坐标系的惯性数据,然后将IMU坐标系下的加速度转换到地面坐标系下,最后通过直接积分地面坐标系下的加速度获得估计速度[9]。该方法近年来也被广泛用于室内定位与导航之中[10]。
基于脚部惯性传感数据对人员运动时的速度进行估计主要采用的是直接积分的方法,采用该方法针对低速行走的行人可以获得较高的速度估计准确性。当行人以0.6m/s至1.6m/s的速度慢速行走时,速度估计的最大均方误差RMSE(Root Mean Square Error)为0.14m/s[5]。但当人员运动速度增加,处于快速行走以及跑步状态下时,人体的步态模型会发生改变[11],脚掌着地的时间会随着速度的增加而减小,加之消费级IMU自身存在的传感误差[12],继续采用直接积分的方法估计人员运动速度会产生较大误差。所以,当行人运动速度增加至快速行走后,运动速度的估计需要采用其他方法。
由于同一人员行走(Walking)、慢速跑步(Jogging)、快速跑步(Running)3种状态的步长会产生显著差异[13]。所以本文的主要研究范围需要覆盖快速行走、慢速跑步、快速跑步。针对这3种状态进行速度区间细分,识别不同运动状态下的单步运动速度。识别结果可用于进一步探究行人运动速度与步长之间的关系,并可用于进一步提高SHSs的精度。
本文提出了一种基于单步统计特征进行速度识别方法。此方法首先利用固定在脚部的IMU获取人员在跑步机上以1.5 m/s~4 m/s的不同的速度运动的惯性传感数据,其次采用峰值检测的方法对采集到的大量惯性传感数据进行单步数据单元划分,然后从每个单步数据单元中提取指定的65维统计特征,最后采用机器学习分类算法对每种速度的特征进行学习,使用训练获得的模型识别不同的单步惯性传感数据所对应的速度。
1 人员运动速度识别方法
本文提出的识别方法整体流程如图1所示。首先利用脚部IMU采集人员运动时IMU坐标系下的三轴加速度和三轴角速度数据。其次根据三轴加速度信息使用峰值检测的方法对运动过程进行单步的划分,定义每两个峰值之间的数据为一个单步[14],获得每一个单步的起始位置和终止位置。然后取出每一个单步起始位置和终止位置之间的三轴加速度和三轴角速度信息即为单步惯性数据。接着我们从每个单步惯性数据中提取选定的65维统计特征用来表征当前单步的速度,将65维统计特征输入到利用大量单步统计特征-速度数据训练好的识别模型之中即可以获得速度识别结果。
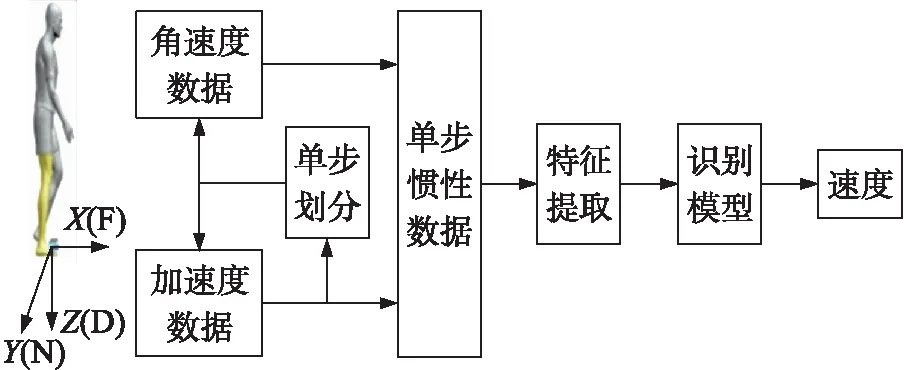
图1 基于脚部惯性传感数据的人员运动速度 识别方法流程图
关于识别模型的训练方法,该方法要求制作一个足够大的单步统计特征-速度数据集。即采集不同人员在不同速度下的惯性数据,利用加速度数据峰值检测单步划分之后,将从单步惯性数据中提取的65维统计特征与该单步对应的实际速度对应,利用该数据集训练速度识别模型。采用最小二乘法(LS)分类器、支持向量机(SVM)分类器、k近邻(KNN)分类器、线型贝叶斯正态分类器(LDC)4种常见机器学习分类算法对以上数据集进行训练并验证其识别准确性,寻找其中最佳的识别方法。
1.1 脚部惯性数据的获取及单步划分
本文的数据采集选取Xsens公司的MTw组件作为获取惯性数据的IMU。

图2 IMU固定位置
如图2所示,将IMU固定在右脚脚背上进行数据采集,并通过配套的软件实时记录获取的惯性数据。固定时注意将IMU坐标系的x轴指向运动前方,y轴指向人员正右侧,z轴指向地心。设定IMU的采样频率为100 Hz。获取到的数据主要包括三轴加速度信息:
(1)
三轴角速度信息:
(2)
式中:k代表采样点的样本,k=1,2,3,…N。B代表IMU坐标系。
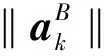
(3)
图3展示的是行人在跑步机上以4 m/s的速度前进时第2 000个采样点至第2 500个采样点(第20 s到第25 s)之间的峰值检测效果。每两个星号之间定义为一个单步。从峰值检测的结果中获取每一步的起始位置和终止位置,返回惯性数据中取出每一步的三轴加速度数据和三轴角速度数据。不同速度下的单步惯性数据均按照上述方法获得。
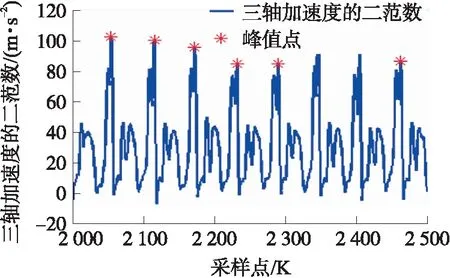
图3 峰值检测分步效果样例
1.2 单步统计特征提取
由于当人员以不同的速度前进时其步频会发生变化,即使人员以相同的速度前进,其每一步的持续时间也会发生变化[16]。为了保证人员以不同的速度前进时能够获得相同维度的特征以表征其速度特性,该方法需要从每一单步中提取指定维度的统计特征。
特征选取的目标在于选择最小数目的特征来获取最佳的识别准确性。这就要求我们设计的特征提取模块不要使用过多过于复杂的特征量,这样才能够尽量降低计算复杂度,同时减小内存、能量的消耗。本文选取的65维特征如表1所列。表1中的特征,均值、最大值、最小值表征数据的集中度趋势,理论上来讲,随着行人运动速度的增加,加速度和角速度的单步均值、最大值、最小值会相应的增加;标准偏差、平均绝对偏差、四分位距表征数据的分散规律,也就是用来分析数据是相互接近还是分散,理论上来讲,随着行人运动速度的增加,其数据分散程度会增加;信号幅度区域、平方和(也称之为能量)的特征类似于均值特征,随着行人运动速度的增加,其数据的能量、信号幅度区域将会增加。总体来讲,使用统计特征进行速度估计是因为它们的计算复杂度较低[15],对内存的需求不高,可以满足我们对特征提取模块的要求,同时提高速度估计的效率。

表1 速度识别的统计特征
注:①四分位距:用于确定信号中第三四分位数与第一四分位数的区别,具体定义如下:
IQR=Q3-Q1
(4)
②信息熵:将待求信息熵的单步信号均匀等分,求出每段出现的概率,利用信息熵的定义求出单步信号的信息熵。
③自回归系数:采用4阶Burg算法求出AR模型的各阶系数。注意此特征仅对三轴加速度信号进行提取。
④相关系数:用于确定信号之间的线性线性相关程度,注意此特征仅对三轴加速度信号进行提取。具体定义如下:
(5)
1.3 识别方法的选择
随着近些年来机器学习技术的发展,机器学习中的分类方法已经越来越多的被用于各种识别问题。常见的机器学习分类技术由两部分组成:训练阶段和评估阶段。训练阶段利用训练集产生离线的分类模型,评估阶段利用另外独立的数据集进行性能评估。所以在进行分类识别之前,有必要将通过之前步骤制作的单步统计特征-速度数据集随机划分两个相互独立的数据集,按照机器学习中传统的测试集-训练集划分方法,首先将其中80%划分为训练集,其余20%划分为测试集。为了进一步的验证识别方法的可靠性,进一步扩大测试集数量同时降低训练集数量,将单步统计特征-速度数据集的70%划分为训练集,其余30%划分为测试集进行识别性能验证。
常见的有监督机器学习分类算法有KNN、SVM、决策树、随机森林、朴素贝叶斯等方法。针对相同的数据集,每种分类方法拥有不同的准确性性能。本文采用LS分类器、SVM分类器、KNN分类器、LDC4种常见分类算法进行对比验证,对比各自分类器的识别准确性,从中寻找出识别率最高的分类算法用于基于脚步惯性传感数据的人员运动速度识别。
2 实验方法和结果分析
2.1 实验方法
该文章将通过一组实验来获得单步统计特征-速度数据集。12位志愿者(年龄23~28周岁,身高168cm~182cm)参加了此次数据集的制作。每位实验者均按照图2所示的固定位置将IMU固定在右脚脚背上进行实验,然后依次按照表2所示的要求在跑步机上进行实验。实验过程中参与实验人员均采用自己的鞋进行实验,且每次实验前IMU人为的固定在指定位置。
由于同一人员行走、慢速跑步、快速跑步3种状态的步长会产生显著差异,对应的单步步长分别为0.74m、1.01m、1.70m,相对于行走状态,单步步长的改变程度分别为0%、36%、130%[13]。所以本文的主要研究范围包括快速行走、慢速跑步、快速跑步。当运动速度增加至2m/s后,行人开始跑步状态。我们将行人以1.5m/s和1.75m/s运动表征快速行走状态,以2m/s~2.75m/s表征行人慢速跑步状态,以3m/s~4m/s表征快速跑步状态。
由于实验人员的运动速度会逐渐加快,当运动速度大于3m/s后,每组之间安排休息时间,在休息时间内停止跑步机,使实验者在跑步机上站立休息。每种速度下持续运动120s,截取第2min内的惯性数据作为该速度对应的有效惯性数据存储。因为跑步机的加速需要一个过程,应当记录的是实验者运动速度稳定后的数据。每位实验者的实验时长大概40min。从每位实验者数据中获取的有效数据时长660s左右。经过以上过程,12位实验者共获取的有效数据时长为11 071s,约184.52min。
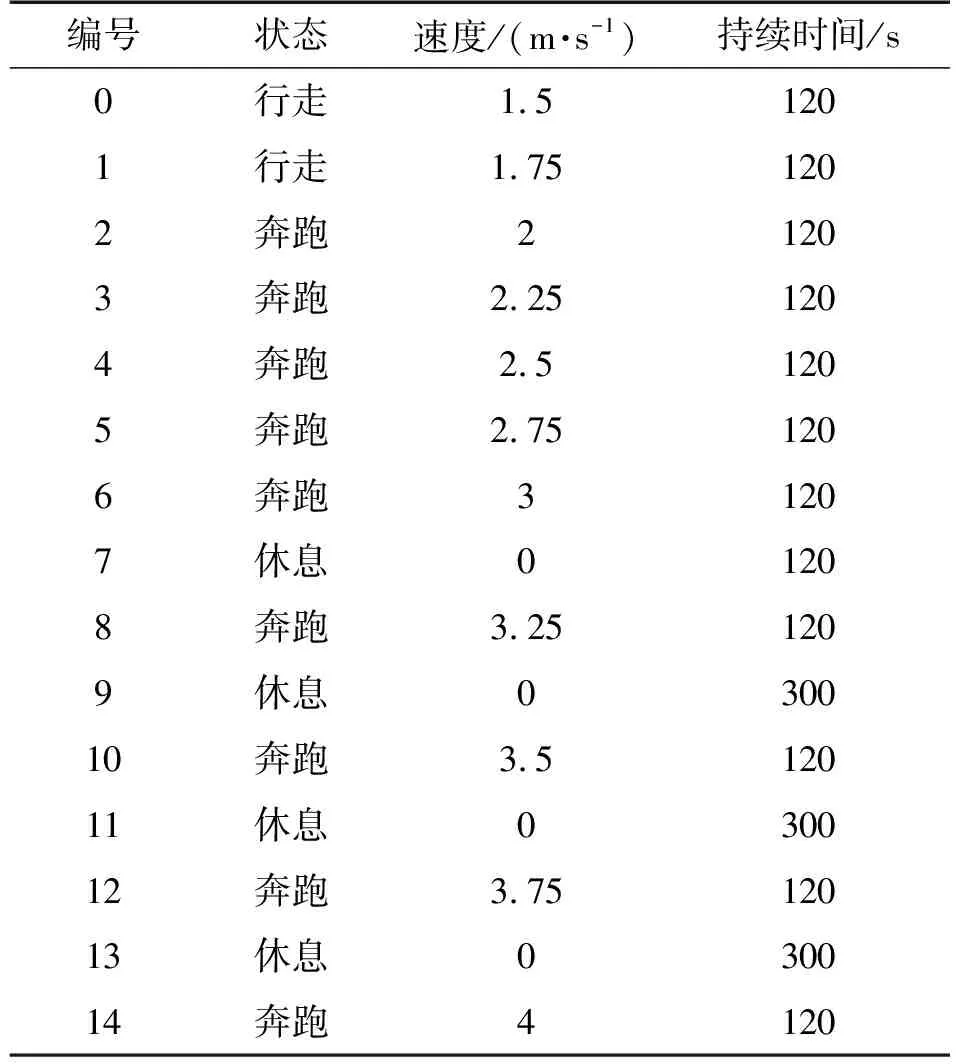
表2 实验数据获取过程
在进行分步之前,首先对原始数据使用截止频率为20 Hz的3阶巴特沃斯低通滤波器进行滤波处理,去除其中的高频噪声。之后采用峰值检测方法对每位实验者在每种速度下的有效数据进行单步划分并存储,共获得11 739步的有效数据。然后对每一步的惯性数据进行65维的统计特征提取,将65维的特征与该单步所对应的真实速度一一对应保存在数据中。也就是通过以上步骤获得了11 739×65维的速度特征数组,以及11 739×1维的速度标签数组,且它们是一一对应的。那么单步统计特征-速度数据集就制作完成。
依据本文提出的方法,试验前需要随机将数据集划分为训练集以训练识别模型,和测试集以测试模型的识别效果。据前所述,首先随机将整体数据集的80%(9 391步)用来训练识别模型,其余20%(2 348步)的数据用来测试模型的识别准确性。然后随机将整体数据集的70%(8 218步)用来训练识别模型,其余30%(3 521步)的数据用来测试模型的识别准确性。通过两次互相独立的测试,以此确保选定的方法可以有效的用来对人员运动速度进行识别。接下来分别采用LS分类器、SVM分类器、KNN分类器、LDC 4种分类算法对以上数据集进行速度识别测试。比较4种算法在两种不同训练集-测试集划分情况下的识别准确性,识别准确性最高的算法即为最佳分类算法。
实验采集到的数据的滤波处理、峰值检测、特征提取、分类算法的实现均是由MATLAB R2014a编程实现。
2.2 实验结果及分析
根据以上提出的方法,在确定每种分类算法的最优参数之后,使用划分好的两种训练集-测试集对每种算法分类准确性进行测试,准确性结果如表3所示。
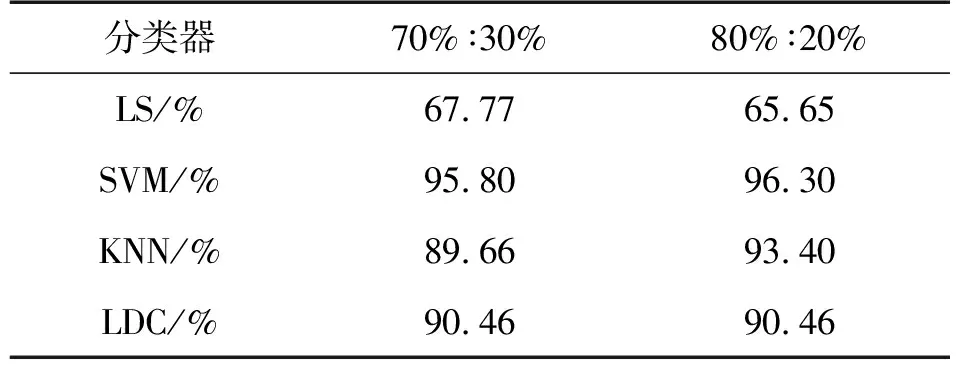
表3 分类器的识别准确率
从表3中可以看出,4种分类算法中SVM分类器的识别准确性最高,在两种训练集-测试集划分方法下其识别准确性均高于95%。为了进一步分析SVM对每种速度下的单步识别性能,表4展示的是以70%。
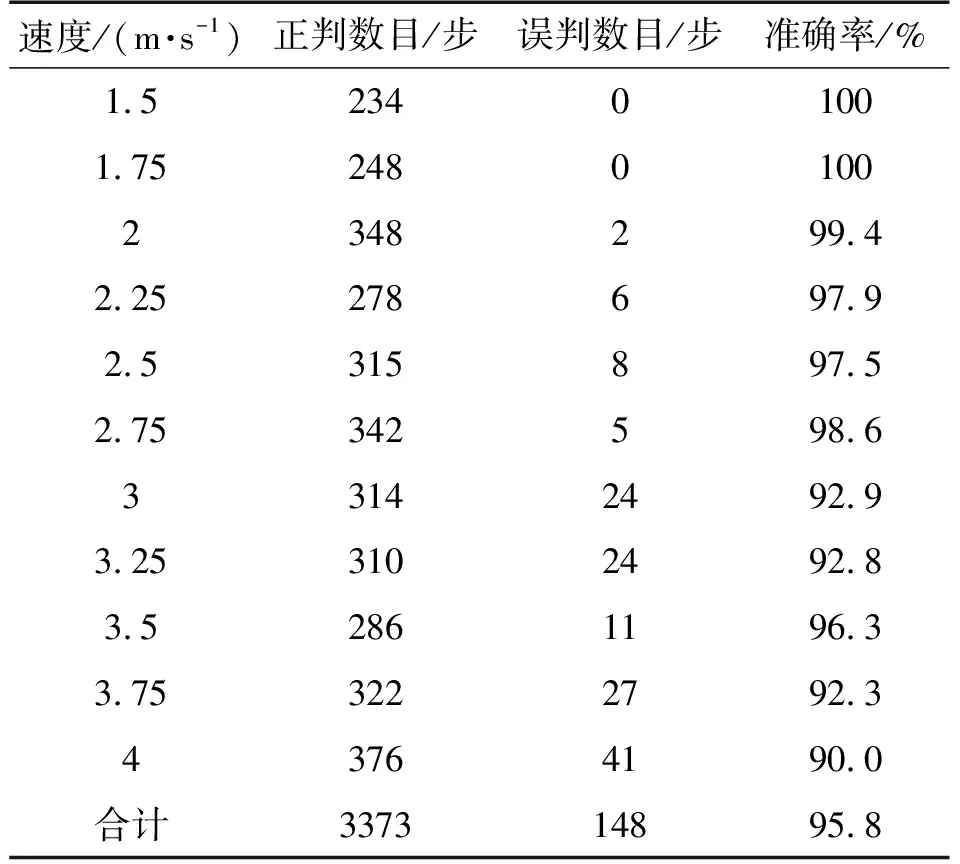
表4 70%∶30%情况下测试集识别结果
30%划分训练集和测试集的情况下SVM分类器对测试集的识别准确性分析,表5展示的是以80%:20%划分训练集和测试集情况下SVM分类器对测试集的识别准确性分析。

表5 80%∶20%情况下测试集识别结果
从表4以及表5中我们可以看到,采用SVM分类器识别单步运动速度时,针对人员行走状态的识别准确性相对较高,采用本文提出的方法,可以将人员以1.5 m/s和1.75 m/s快速行走状态的单步从数据集中区分出来。理论上分析是因为人员处于行走状态时,即使是快速行走,脚部触地的时间相对跑步状态脚部触底时间相对较长,其特征值相对较稳定。另外,从表4与表5中的数据我们还可以看到,当人员运动速度大于3 m/s后,其单步速度误判相对低速运动出现显著波动。理论上分析是因为当人员运动大于3 m/s后,脚部触地的时间出现显著地减少,数据的波动增大,本文所选取的特征出现波动,从而影响分类器的识别过程。
但是从整体上来讲,无论是以80%∶20%划分训练集和测试集,还是以70%∶30%划分训练集和测试集,采用SVM分类器针对本文创建的数据集的速度识别准确率均高于95%,最高达到了96.3%。
3 结论
目前基于脚部惯性传感数据进行人员运动速度识别的方法大多采用直接积分的算法对慢速行走的行人进行速度估计。但是当行人运动速度增加至快速行走或者奔跑时,继续使用该方法进行速度估计会出现显著偏差。所以本文提出了一种基于脚部惯性传感数据、利用单步统计特征对行人运动速度进行估计的方法。
本文的主要贡献在于将IMU固定在脚部,采用SVM分类器识别单步运动速度,当行人在1.5 m/s~4 m/s内运动时,我们认为单步运动速度识别误差将小于0.25 m/s。本文提出的方法存在一定的误差。但是由于同一人员运动状态改变时步长会发生显著变化,且已证明运动速度与运动步长之间有强相关关系。本文提出的方法存在一定误差,但是利用本文提出的方法,针对存在速度剧烈变化的运动过程,可以根据识别的单步运动状态改变行人的运动步长,相对于用户输入步长固定值,将有助于提高SHSs的追踪精度。
