一种基于XGBoost的恶意HTTP请求识别方法
2018-12-21徐迪
徐迪
(中移(杭州)信息技术有限公司,杭州 310012)
现如今,互联网已成为人们家庭与工作生活的重要组成部分。网站的功能也是日新月异,增加了更多的互动功能,以提供更好的用户体验。这些业务极大的流行,使得75%以上的网络攻击都瞄准了Web,而随着Web应用类型的丰富,Web攻击也丰富起来[1]。
日益频繁和多样化的Web攻击使运营者意识到Web安全面临的巨大风险,网站自身及客户的数据泄露风险巨大,网站的声誉极易受损,网站可用性难以保障,业务中断带来的经济损失巨大[1]。
Web应用防火墙(简称WAF)通过精细的配置将多种Web安全检测方法连接成一套完整的解决方案,能够对网站的HTTP请求进行检测,识别恶意请求[1]。但是市面上大部分WAF均基于静态规则对HTTP请求进行检测,规则的提炼基于对各类攻击语句进行提炼,构造正则匹配,或者识别请求中是否包含敏感文件、路径及命令等。基于规则的恶意HTTP请求识别对一些基础攻击请求能起到一定的识别作用,包括SQL注入、XSS注入、远程命令执行、文件包含等,但是规则也非常容易被绕过,不能覆盖住比较隐藏或者深度构造的恶意请求,同时规则数量的增加对系统性能影响非常大,但是随着攻击方式的逐日更新,必须定期更新规则,这样给性能带来很大的挑战。综上,传统的基于规则的恶意HTTP请求识别已经不能满足现阶段WAF的需求,因此将机器学习、数据挖掘等方法应用到恶意HTTP请求识别中,已经成为现阶段研究热点之一。
目前,国内外针对基于机器学习的恶意HTTP请求识别取得了一定的成果,其中具有代表性的有基于统计的学习模型和基于聚类模型。文献[2]对Web用户的HTTP请求速度、请求的响应负载流量等设定相应的正常用户的流量阈值,从而进行异常检测。文献[3]引入有监督的朴素贝叶斯(Nauce Bayes, NB)机器学习方法进行流量分类与应用识别,使用核密度估计对朴素贝叶斯进行改进。基于统计的学习模型的难点在于阈值并不好确定,容易造成误报率高[4],比较适用于网络环境较稳定的统计模型,应用不够广泛[4]。基于机器学习的恶意HTTP请求识别基于训练集建立模型,能依据训练结果,提高识别率及效率,具有较好的范化识别能力和多种可选的聚类算法。
本文基于机器学习方法,提出一种基于词袋与TFIDF特征点聚类的异常HTTP请求识别方法。对URL解码后的HTTP请求进行特征提取,将提取的特征向量进行XGBoost分类算法进行分类,通过分类器识别恶意的HTTP请求,在提高检测率的同时,降低了检测时间。
1 恶意HTTP请求识别流程
恶意HTTP请求识别流程包括两个阶段,训练阶段和识别阶段,如图1所示。
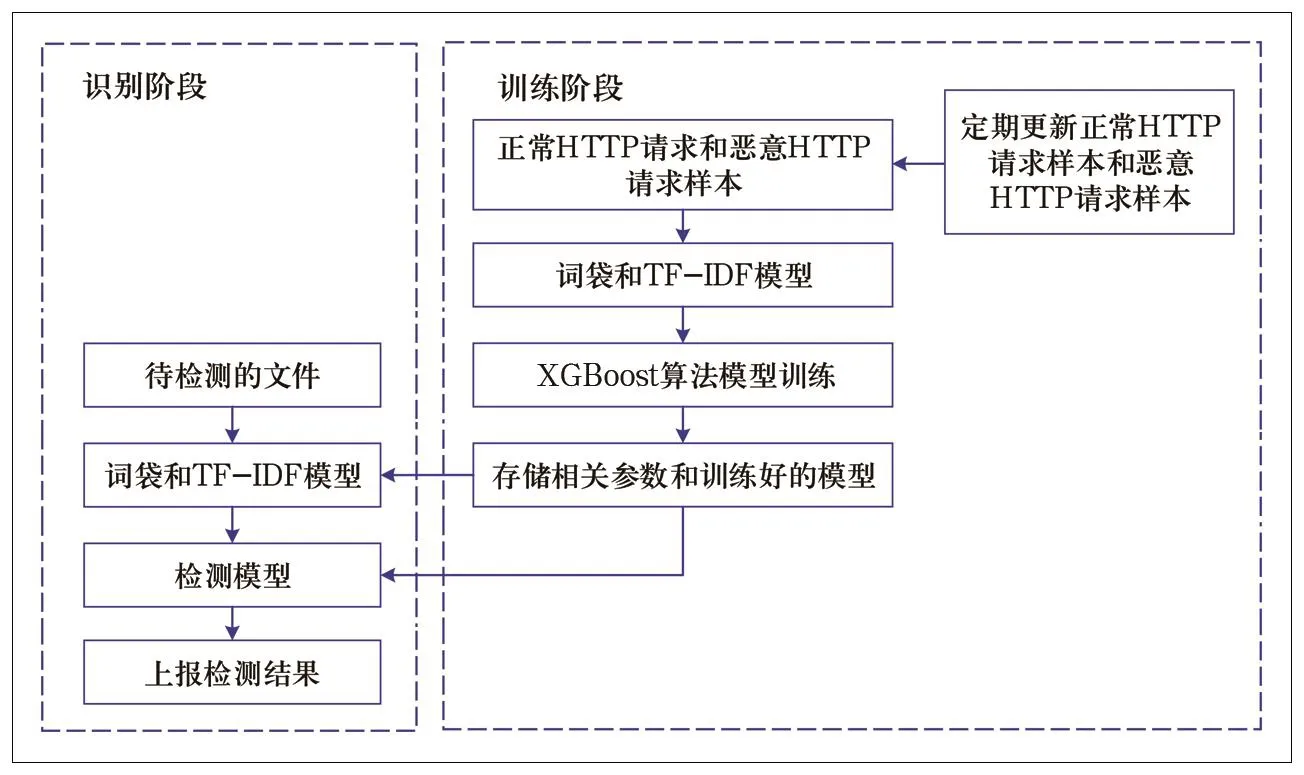
图1 恶意HTTP请求识别流程
1.1 训练阶段
首先进行训练阶段,训练阶段可离线进行。主要流程包括如下。
(1)收集正常和恶意的HTTP请求样本。
(2)对样本进行特征提取,使用的是词袋和TFIDF模型。
(3)利用XGBoost算法进行模型训练。
(4)存储特征提取时词袋相关参数以及训练好的分类模型,用于恶意HTTP请求检测。
同时将定期离线更新最新的Webshell样本和PHP文件样本,重新训练模型,使得模型能够经常得到更新。
1.2 识别阶段
对Web的HTTP请求进行实时识别,主要流程包括如下。
(1)若有待检测的HTTP请求,首先利用存储的相关参数进行词袋和TF-IDF模型特征提取。
(2)将提取的特征输入存储的训练好的分类模型,得到检测结果,并且上报。
2 特征提取
2.1 URL构成
在介绍样本数据的特征提取之前,首先介绍一下统一资源定位符的组成。在互联网上,每一信息资源都有统一的且在网上唯一的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位符),它是WWW的统一资源定位标志,就是指网络地址[5]。URL由3个部分组成:资源类型、存放资源的主机域名、资源文件名。URL的一般语法格式为:
protocol://hostname[:port]/path/[;parameters][?query]#fragment,
其中带方括号的为可选项。Protocol指定使用的传输协议,最常用的是HTTP协议。hostname是指存放资源的服务器的域名系统主机名或 IP 地址。Port是指端口号。path是由零或多个“/”符号隔开的字符串,一般用来表示主机上的一个目录或文件地址。parameters是用于指定特殊参数的可选项。query用于给动态网页(如使用 CGI、ISAPI、PHP/JSP/ASP/ASP.NET等技术制作的网页)传递参数。fragment用于指定网络资源中的片断[5]。
本文采用的样本数据为包括path在内的后续请求内容,正常样本示例为:
/includes/functions_kb.php?phpbb_root_path=http://cirt.net/rfiinc.txt?,
恶意样本示例为:
/cgi-bin/search.pl?form=../../../../../../etc/passwdx00。
将样本数据进行URL解码,然后利用词袋模型和TF-IDF模型进行后续特征提取。
2.2 词袋模型
文本特征提取主要包括两个非常重要的模型:词集模型和词袋模型。词集模型是单词构成的集合,集合中仅统计单词是否出现,次数并不关心;词袋模型在词集的基础上,统计其出现的次数。两者本质上的区别在于,词袋是在词集的基础上增加了频率的维度,词集只关注有无,词袋需加上次数[4]。
把一个HTTP请求作为一个完整的字符串处理,首先对请求进行URL解码。本方法使用的是n-Gram提取词袋模型。所谓n-Gram是词袋模型的一个细分类别,即每n个字符作为一个处理单元。将相邻的n个字符划分到一个组中,同时统计该组在字符串样本中出现的次数,以此表示字符串样本。在词组切分完成后,每个字符串样本都被表示成一个组频向量。本文n取值范围为1~3,即相邻的1个字符、2个字符、3个字符均划分为组,并计算组频作为特征向量。
2.3 TF-IDF模型
TF-IDF为词频与逆向文件频率模型。TF-IDF的主要原理是如果某个词或词组在一篇文档中出现的TF高,且在其它文档中却没有,则认为此词或者短语具有很好的类别区分能力,适合用来对文档进行分类。其中,TF指的是某个词或词组在某篇文档中出现的次数,IDF则是词或词组“权重”的度量[6]。如果某个词在多篇文档中TF低,但却频繁出现在某篇文档,则这个词IDF值越大。相对地,某个词越常见,IDF越低。将某个词或者词组的TF值和IDF值相乘即得到TF-IDF值。当这个值越大时,表明该词在该文档中越具有代表性,越重要[6]。
使用TF-IDF算法处理字符串词频矩阵,将获得能够反映各个词组重要程度的特征矩阵。公式如下:

将组频向量通过TF-IDF模型,得到每个组的重要程度的特征向量,作为该HTTP请求的特征,用于后续进行分类。
3 XGBoost算法
本方法采用XGBoost分类算法进行分类,与普通的进行恶意HTTP请求检测的分类算法相比所需耗费的内存得到了降低,同时能够支持分布式的集成,能够有效的提高分类的性能。
3.1 算法原理
XGBoost是梯度提升决策树算法(GBDT)的高效实现,它继承了GBDT并加以改进,其核心思想如下[7]。
(1)在目标函数中加入了正则化项,正则化项与树的叶子节点的数量和叶子节点的值有关,如公式(4)﹑(5)所示[8]。
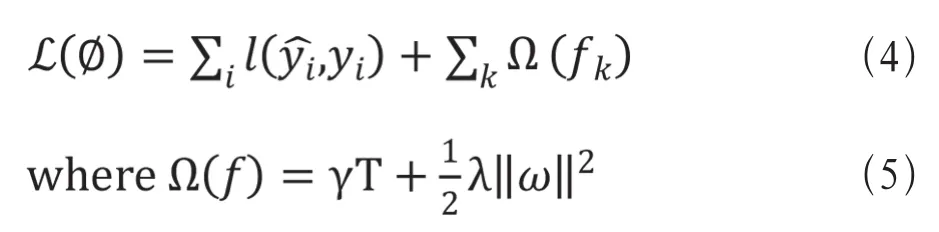
(2)在计算伪残差的时候,不仅仅使用到了一阶导数,还是用了二阶泰勒展开,如公式(6)所示,其中g为一阶导数,h为二阶导数[8]。

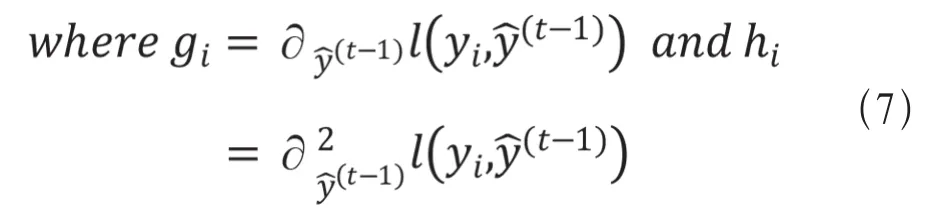
(3)使用与正则化项相关的lamda、gama作为分割点的标准,如公式(8)所示[8]。

3.2 算法优势
XGBoost分类算法是基于Boosting的一种集成学习方法,相比传统的集成学习GBDT算法,XGBoost主要有以下8大优点。
(1)传统的GBDT基分类器是基于CART,而XGBoost算法也支持线性分类器。
(2)XGBoost分类算法在优化时利用的是二阶泰勒展开,相比于传统GBDT只有一阶导数,还增加了二阶导数,提高了准确性。
(3)XGBoost分类算法在代价函数里面加入了正则项,能够降低模型的方差,简化模型,去除过拟合。
(4)为了使模型更加泛化,增大后面过程的学习空间,XGBoost算法每次迭代一次以后,会将结果即叶子节点的权重乘以一个参数相当于学习速率,降低影响。
(5)为了防止过拟合,减少计算量,XGBoost算法支持列抽样。
(6)针对特征有缺失的部分样本,XGBoost能够自动学习其分裂方向。
(7)XGBoost算法支持并行。由于XGBoost算法每一次迭代都需要用到上一次迭代的数据,所以并行并不是在tree粒度上进行的,而是在最耗时的确定最佳分割点的时候。方法是在开始训练之前,会预先对数据进行排序,并且保存为块结构,后续进行节点分裂时,需要选择增益最大的特征进行分裂,就可以基于这个结构,从而实现并行,缩短时间[7]。
(8) XGBoost提出了一种可并行的近似直方图算法,用于节点分裂时,当数据量过大无法全部载入内存时,可以高效率计算所有的分裂增益,选取最佳的分割点[7]。
4 实验与评估
4.1 模型评估
混淆矩阵又名错误矩阵,常用语监督学习用来展示算法的效果。混淆矩阵包括4个重要的指标: TP (True Positives, 真阳性),表示本身是正例,也识别为正例的比例;FP (False Positives, 假阳性),表示本身是负例,却被识别为正例的比例;FN (False Negatives,假阴性),表示本身是正例,却被识别为负例的比例;TN (True Negatives, 真阴性),表示本身是负例,也识别为负例的比例。
基于以上指标,监督学习常用的评估指标如下。
准确率(Accuracy):
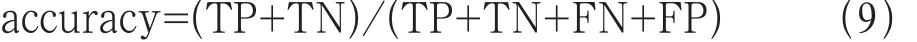
精确率(Precision):预测正确的正样本数占被预测为正样本的数目的比例。

回召率(recall):预测正确的正样本数占本身就是正样本的数目的比例。

F1值是利用精确值和回召率来计算调和均值。

本文将使用以上4个评估指标对提出的恶意HTTP请求识别算法进行评估。
4.2 实验描述
特征提取使用词袋和TF-IDF模型,利用XGBoost算法进行分类,完整的训练流程如图2所示。

表1 不同模型的实验结果对比
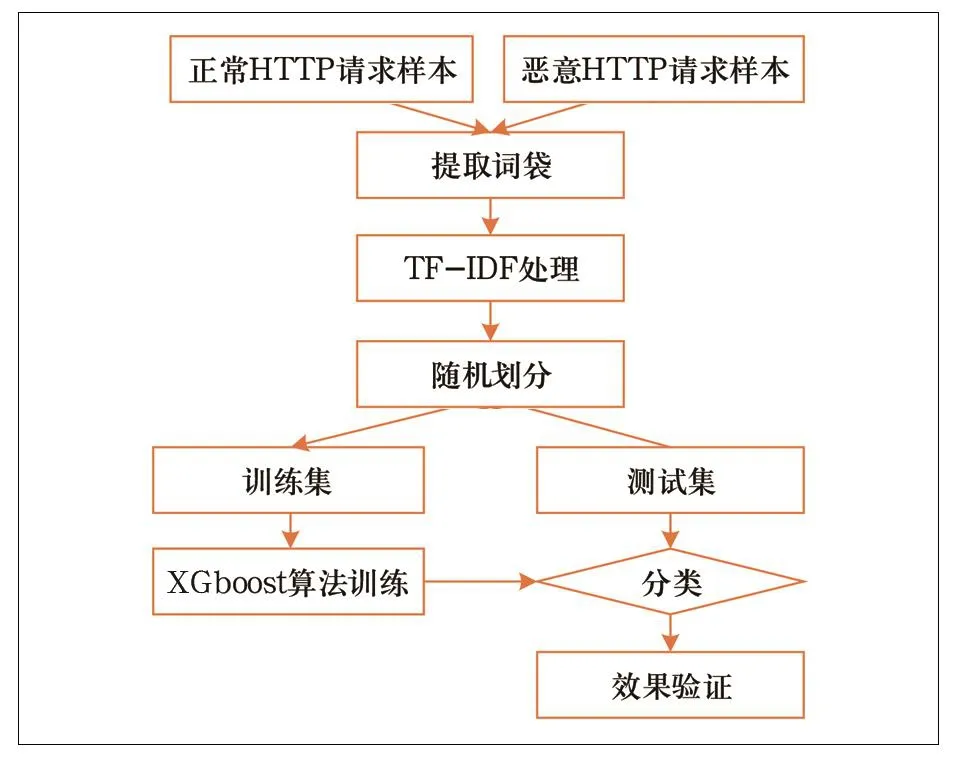
图2 特征提取使用词袋和TF-IDF模型的XGBoost算法训练流程
(1)准备白样本以及黑样本:白样本为正常的HTTP请求样本,共收集白样本1 265 974个。黑样本即异常的HTTP请求样本,共收集黑样本44 532个。
(2)读取样本,提取词袋:读取全部样本,将每一个样本进行URL解码,表示成一个可读字符串,并附上标签。恶意请求标签为1,正常请求标签为0。使用n-Gram提取词袋模型,我们以每1~3个字符作为一个处理单元,设定最大的特征数为5 000。提取词袋模型后,所有的样本字符串被表示为一个1 310 506×5 000的词频矩阵。1 310 506为所有的样本数目,5 000为最大特征数。矩阵中的数字表示对应位置单词组在该样本中出现的次数。
(3)TF-IDF处理:采用TF-IDF算法对词频矩阵进行词频分析,以获得每一个词组在该样本中的重要程度,计算结果仍然表示为1 310 506×5 000的矩阵。
(4)随机划分为训练集和测试集:其中测试集的比例设置为0.3。
(5)使用XGBoost算法在训练集上训练,获得训练好的模型数据。
(6)使用模型数据在测试集上进行预测。
(7)验证XGBoost算法预测效果:使用准确率、召回率等对模型进行评估。
4.3 结果比较
将得到的实验结果与其它常见的分类模型进行比较,其中特征提取方案均采取的是词袋模型与TF-IDF模型,得到表1。
我们将基于词袋和TF-IDF的XGBoost模型与随机森林、支持向量机、逻辑回归进行对比,可以发现本文提出的方法在准确率,精确率,召回率方面整体具有一定优势。
4.4 实验结论
本算法有以下技术优点。
本文提出的基于XGBoost的恶意HTTP检测有效的提高了检测的准确率。
利用XGBoost算法,在提升检测模型准确率的同时也保证了高性能,所需耗费的内存得到了降低,同时能够支持分布式的集成,能够有效的提高分类的性能。
利用机器学习的方法使模型的检测具有更强大的泛化能力,能对未知的恶意HTTP请求起到一定的检测作用。
5 结束语
本文基于词袋模型与TF-IDF模型,利用XGBoost算法对恶意HTTP请求进行识别,能够进一步提高识别准确率、效率,并具有一定的泛化能力。
