黑盒威胁模型下深度学习对抗样本的生成
2018-12-20孟东宇
孟东宇
(1.上海微系统与信息技术研究所上海200050;2.上海科技大学信息学院,上海201210;3.中国科学院大学北京100029)
近年来,深度学习及相关技术高速发展,在众多领域取得了重大的突破[1]。在机器视觉[2-3],语音识别等领域[4],基于深度学习的方法将原有方法的功能极限向前大幅推进。而随着硬件性能优化和软件模型设计的进步,深度学习在很多实际生产生活场景中也得到了应用,自动驾驶汽车[5],人脸识别验证[6]等等技术称为了新的热点。
这些场景中,计算机系统的功能正确性对相关人员的生命财产安全起决定性作用。因此,如何有效地对深度学习系统的安全性做检测和验证成为了重要的研究课题。此前,研究人员已经发现,即使对于在正常测试样本上表现十分出色的神经网络模型,只需在正常测试样本上叠加一个非常小的恶意噪声,就可以导致神经网络出现错误。这样由正常样本叠加微小恶意噪声而生成的数据样本被称为对抗样本。对抗样本的存在对基于深度学习技术的人工智能系统造成了巨大的安全威胁。
由于深度学习技术的相关理论研究依然处于起步阶段,人们无法形式化地解释深度神经网络的工作机制,也就无法通过形式验证的方法确保大型深度神经网络的正确性。因此,借鉴其他软件安全研究方法,找到某一特定神经网络模型的对抗样本就有了巨大的实际安全评估研究价值。对神经网络进行攻击产生对抗样本是得到一手安全威胁的重要指标,也是评估、研究、乃至解决这一安全问题的第一步。
此前关于针对特定网络产生对抗样本的方法多集中在所谓白盒威胁模型下[7-9]。在此模型中,攻击者掌握了目标网络的模型结构及参数。然而,此模型在实际威胁建模中并不常见,更为广泛的应用场景实际是黑盒攻击模型,即攻击者能对受攻击网络做出请求,给出输入样本,得到目标网络的输出,但攻击者对网络本身的结构设计和参数内容并不知情。许多实际应用如视频网站查重检测、在线病情诊断等在服务器不被入侵的情况下就面临此类威胁。因而,对黑盒模型下对抗样本产生方法的研究就尤为重要。
文中针对于此,以图像分类网络为例提出了一种在黑盒模型下针对深度神经网络模型的攻击方法。该方法借助黑盒优化方法,不需要借助网络的具体结构和参数内容,仅需向网络发起查询即可产生攻击。本文所提出的对抗样本产生方法对深度神经网络的安全评估有推动作用。
1 深度学习和对抗样本
1.1 深度学习简介
深度学习是一类深度神经网络学习方法。通过大量样本的端到端训练,神经网络模型能够自动抽取训练所用数据集的有效特征,达到非常好的效果。
一般而言,认为深度神经网络是对一个高维空间中复杂函数的逼近。训练过程中,通过计算当前函数给出的估计值和标定的真实值之间的误差,反向求导进行随机梯度下降优化,从而更新网络权重达到函数逼近的效果。
深度学习类方法自2012年以极大优势赢得ILSVRC比赛重新回到公众视野中之后[10],迅速在多个领域取得了重大的突破,包括图像处理,自言语言处理等领域。深度学习方法也在自动驾驶汽车,监控摄像等应用场景下进入了我们生活。
1.2 对抗样本及其分类
对抗样本(adversarial examples)是一种针对深度神经网络的特殊攻击形式。其一般形式为在生产环境下,控制深度神经网络的输入,使其具有幅度极小人类难以注意的恶意噪声,从而达到使神经网络产生错误处理的效果。具体而言,研究人员在原本神经网络可以正常处理的样本的基础上叠加一个极小的经过计算得到的恶意噪声,就能够使得神经网络对输入的处理发生变化;于此同时,人类很难区别两次输入的区别。
对抗样本一般根据生成所依据的模型和具体算法来区分。常见的威胁模型分为3类:白盒模型,黑盒模型,和转移模型。白盒模型中,攻击者可以利用网络结构和参数的所有知识产生攻击;黑盒模型中,攻击者可以利用对模型的询问得到输入输出对,但无法获知模型内部信息;转移模型中,攻击者不能向模型发起查询请求,对模型内部信息也不知情,但了解模型所要解决的具体问题是什么[11]。
当前较为主流的白盒攻击方法包括Carlini攻击[8],FGSM攻击[7],以及PGD攻击[12]等。其主要的攻击思路为依据神经网络产生输入对输出结果影响的梯度,再根据梯度更新输入图像,逐步迭代从而产生最终的攻击样本。
在黑盒模型中,无法直接利用网络模型内部结构与参数进行反向传播计算,因而也无法直接得到生成对抗样本所需的梯度。
2 黑盒EM优化算法
为了对黑盒威胁模型下的输入针对输出所具有的梯度进行计算,文中的方法采用了黑盒优化算法,在对模型内部结构和参数内容不知情的情况下对所需梯度进行估计。文中采用的黑盒优化模型为最大期望算法(expectation-maximization)。
具体而言,想要在某项参数的可采样分布中优化目标函数,可以首先给出对参数的初始估计,然后迭代如下过程:在当前估计状态周围采样,选取采得样本中目标函数表达较优的样本,对参数估计进行再次拟合。
这一方法可以在不获取网络结构和参数的条件下,快速得到近似的优化结果。非常适合深度神经网络中黑盒模型的对抗样本产生问题。
3 设计概览
黑盒样本生成方法将黑盒EM优化方法应用到深度神经网络模型中。本节对具体算法设计进行介绍。
3.1 图像的概率模型表示
文中考虑一般的单通道灰度图像和三通道彩色图像。一般而言,图像具有较高的维度,即使是如手写字体识别数据集这样相对简单的数据集,其单张图像的维度也高达784维。
文中使用简单的多元高斯分布模型来对图像进行建模。以单通道图像为例,对于每一个像素点,将其像素值表示为一个高斯分布,即用高斯分布的均值表示像素值,用方差表示像素可能的变化范围。这样一来,可以用均值、方差两个参数对某一像素点进行描述。
对于整张图像而言,基本模型假设任意两个像素之间没有关系,即任意两个像素之间的随机变量相互独立。这一假设忽略了图像内容上的空间相关性,是一个简化的基本模型。通过后面的试验表面,即使在这样简单的模型下,对抗样本生成方法也能够获得很好的优化效果。
由于图像内容有其丰富而复杂的内在结构,通过对这些空间结构的表示,能够降低维度,得到更为精炼的图像表示。将在后文介绍这一更为优化的表示方法。
3.2 优化目标
优化目标由两部分组成,第一部分对应于当前样本能否成功欺骗目标网络,这是对生成样本的功能性保证;第二部分对应于生成样本与原样本间的距离,我们希望生成的对抗样本与原样本有尽可能小的差别,从而使人类观察者无法察觉到图像的异常。
对第一项优化目标,用概率归一化前一层对应元素的数值与第二大的数值之前的差距作为具体的优化函数。当对应项是当前概率最大的一项时,该项数值为正值,且差距越大,数值越大;当对应项数值不是概率最大的一项时,我们将其值设为零,即只要生成的的样本能够成功欺骗目标网络,就不再考虑第一项在整个优化目标中的作用。
对于第二项优化目标,采用当前样本与初始样本之间的欧几里得距离。希望得到的样本在能够成功欺骗目标网络的情况下尽可能与初始样本相似。
为了平衡两项的关系,在实际使用时可以给第一个优化目标设定相较于第二项更大的权重,从而在保证优先完成第一项优化目标的情况下尽可能完成第二项优化目标。希望同时最小化两项优化目标。
3.3 算法描述
黑盒对抗样本的生成方法流程图参见图1,
包括以下几个主要步骤:
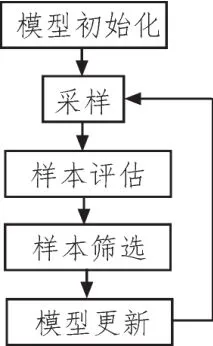
图1 对抗样本生成流程图
1)模型初始化:对抗样本常常以正常的图像数据为蓝本,作为初始值,在其基础之上进行恶意噪声叠加,得到对抗样本。对应到我们的图像表示方法中,我们将初始状态下的模型均值设为正常数据的值,再统一设定其方差,作为模型的初始化方法。
2)采样:以当前所估计的参数为生成模型进行多次随机采样。
3)评估:对于每一个采样得到的图像,首先将它像送入神经网络模型中进行处理得到输出结果,以此判断它是否能够成功欺骗目标网络,进而得到优化目标的第一项。紧接着,计算当前采样图像与初始样本的欧几里得距离,以此得出优化目标的第二项。综合两项的内容,能够计算出这一采得图像的效用值。
4)筛选:依据步骤3得到的效用值对步骤2所采样得到的样本做排序,效用值越小,就认为采样样本的质量越好。从采得样本中取效用最好的一部分(如十分之一)供后续处理使用。
5)参数更新:有了较优的部分样本,就可以对图像的生成模型进行更新。具体而言,用当前一次采得较优的样本的均值替代原均值,用其方差替代原方差。
6)重复步骤2)~5)一定次数。由于得到可以成功欺骗目标网络的对抗样本后,还可以继续通过原有目标函数进一步降低对抗样本与初始样本的距离,因此本文不推荐在第一次采得能够欺骗目标网络的时候就停止优化,而是应该以迭代次数作为终止条件。
3.4 算法改进
前文提到,可以用过对描述图像的概率模型进行改进从而提高本文所提算法的效率。一个可行的方法是通过主成分分析[13]或自编码器[14-17]对图像进行降维,再在映射得到的较低维空间中进行建模、采样和计算。这样一来,算法的运行效率可以得到较大的提升。
4 实验与评测
此处内容介绍对所提出算法进行的实验数据、实验方法以及实验结果。
4.1 实验数据集
文中采用经典的两个实验数据集:MNIST(手写数字识别数据集)和CIFAR-10(小型物体识别数据集)来进行测试。
对于MNIST数据集,选出55 000个训练样本和1 000个测试样本。训练得到的目标分类器在正常的测试样本上能够得到的正确率为99.4%。
对于CIFAR-10数据集,选出45 000个训练样本,10 000个测试样本。在此数据集上训练得到的目标分类器的正确率达到了90.6%。
训练得到的两个模型都有很高的正确率,并且能够取得非常好的泛化效果。
4.2 实验方法和评价方法
实验中,希望对目标分类器产生对抗样本,即我们在任意选出的正常测试数据上,运算得出并叠加一个小的恶意噪声,使得原本能被分类正确的样本被错分为其他类别。
测试中,文中提出的对抗样本生成方法会向目标模型发起查询,但对模型内部的结构与参数均不知情。测试中的所有初始样本均为可以被目标分类器分类正确的样本。
从生成对抗样本成功率以及对抗样本与初始样本的平均距离对本文所提出的算法进行评价。
4.3 实验结果
文中提出方法在MNIST和CIFAR-10数据集上对抗样本生成的成功率、平均噪声距离以及平均生成用时见表1。

表1 对抗样本生成实验结果
从表中数据可以看到,在两个测试数据集上,本文提出的黑盒模型下的对抗样本生成都达到了100%的成功率,其成功率甚至高于部分白盒对抗样本生成方法[18-20],且平均噪声很小。
图2展示了一组初始样本与本文所提出的方法生成的对抗样本之间的对比关系。图2的左侧图为初始样本,右侧图为生成的对抗样本,左图可以被目标网络正确分类为0,而右图会被错分为类别1。
5 结论

图2 初始样本与对抗样本对比图
文中详尽调查研究了现有的神经网络对抗样本生成方法,发现当前所提出方法对黑盒模型的重视程度不足。因而,文中提出了一种新的基于黑盒威胁模型的深度神经网络对抗样本的生成方法。文中所提出的方法利用黑盒优化方法,对不可直接求梯度的神经网络做梯度估计,可以在不了解神经网络模型结构和参数的情况下以高成功率快速生成高质量对抗样本,填补了之前研究在这一方向上的空白。
