大数据实时流计算的高铁转向架数据过滤算法研究
2018-12-20彭清畅刘光俊
赵 珂,彭清畅,刘光俊
大数据实时流计算的高铁转向架数据过滤算法研究
赵 珂1,彭清畅2,刘光俊2
(1. 昆明理工大学 城市学院,云南 昆明 650051;2. 中车青岛四方机车车辆股份有限公司,山东 青岛 266111)
为解决高铁转向架数据过滤在大数据流计算中受多工况影响的计算效率低下和精准度不高的问题。在高铁大数据实时流计算中使用多判据因子方差斜率算法进行特征提取多工况数据,并结合交路线上相应GPS坐标点上的权重参考值进行数据过滤。通过高铁实际项目运行验证:该方法能有效降低数据干扰,提升数据过滤准确率到95%以上,实现准确监控和预测高铁转向架故障,大幅降低了高铁转向架的检修工作量,提高了检修效率;同时能满足实时流计算每秒上百万的计算效率。
高铁;数据过滤;多判据因子;转向架;流计算
0 引言
在高铁、飞机等交通工具的高速运行中,故障管理和检测是系统运行保障的重要环节[1],为监测高速交通运行设备的健康度需要进行传感器数据采集、数据解析、算法运算、安全监控、预测挖掘、分析统计等大数据处理。其中,在高铁动车组故障监控和预测中转向架、车轮等核心部件是系统健康运行监测系统的重要对象[2],动车转向架传感器数据由于其外部的工况随时在变化(如:京广线的高铁在夏天运行过程中要经过40℃~50℃的高温,也会经过10℃~20℃的低温,温湿度和海拔等也在随车变化),采用单一轴温阀值监控系统运行健康度,会导致错误报警率较高。为提高系统监测精度,需结合多系统多工况进行大数据实时分析处理。在高实时性要求的设备安全监控业务场景中,需要秒级完成海量数据运算,这个过程首先需要对大数据中的高价值数据进行快速、准确地计算和监控,并实时进行清洗、容错处理。同时实时流计算的过滤算法需要简单、实用、高效,但简便的算法不能保障数据过滤精度,采用复杂的计算又需要更多的计算资源。
在大数据的流计算中,常用的数据过滤和数据特征提取方法有匹配过滤、偏最小二乘法、线性判断分析等方法。罗元剑等[3]提出了基于有限状态机的RFID流数据过滤与清理技术;贾连锁[4]提出的数据过滤方法是基于静态匹配表的查找过滤;刘健男等[5]提出基于布隆过滤器的数据过滤方法以减少内存的查询时间,提高了流计算的实时性;但文献[3-5]的数据过滤技术都不适用于多工况的实时大数据过滤处理。姜文超等[6]提出了一种基于相似度过滤的大数据保序匹配与检索算法,主要适用于预测平稳系统,利用归约后数据计算相似度后过滤,该方法不适用于突变数据检测系统和故障数据预测。延婉梅[2]提出了基于网格LOF离群点检测算法对动车数据进行清洗,这种算法适合在部件系统内部进行健康监控,而无法达到故障预测的业务多工况因素分析要求。文献[7-10]提出了几种基于特征提取、分类集成的聚类算法识别高铁工况数据的方法,但这些方法都是基于实验室的选择,也是采用基于时间窗口的聚类算法,在实际高铁运行系统中此类方法都会影响流计算中的业务效果和计算效率。文献[11-12]提出了鲁棒性增量主成分的分析法,通过在线特征提取、滑动窗口数据更新动态,针对过滤后的异常数据点进行增量主成分的分析,实现了满足大数据处理的实时性及一定精度的要求。文献[13]提出了用权重法对主成分回归分析进行补偿后动态监测数据的方法。这些方法不能解决高铁轴温多工况的数据有效过滤和精度要求。本文在大数据流计算中提取各种复杂工况数据特征,分析了上千列高铁的转向架轴温异常数据,采用离线训练得到的GPS坐标参考值结合流计算中的多判据因子权重算法的方法,既能实现所有实时运行的高铁在多工况下的数据高效过滤处理,又能提高数据过滤的精度。
1 多工况实时数据特征
基于大数据平台的数据采集发现,高铁在不同的天气、海拔、速度、内外温度等多工况的情况下,转向架传感器轴温数据不定时出现数据帧跳变如表1中温度突变数据所示,跳变数据可能是传感器故障引起,也可能是多工况导致的正常跳变数据,或者是需要向系统报警的高价值有用数据。因在实时流计算中常出现数据帧跳变,如果采用较复杂算法会增加系统资源额外开销,影响实时处理效率。
表1 转向架轴温数据跳变示例
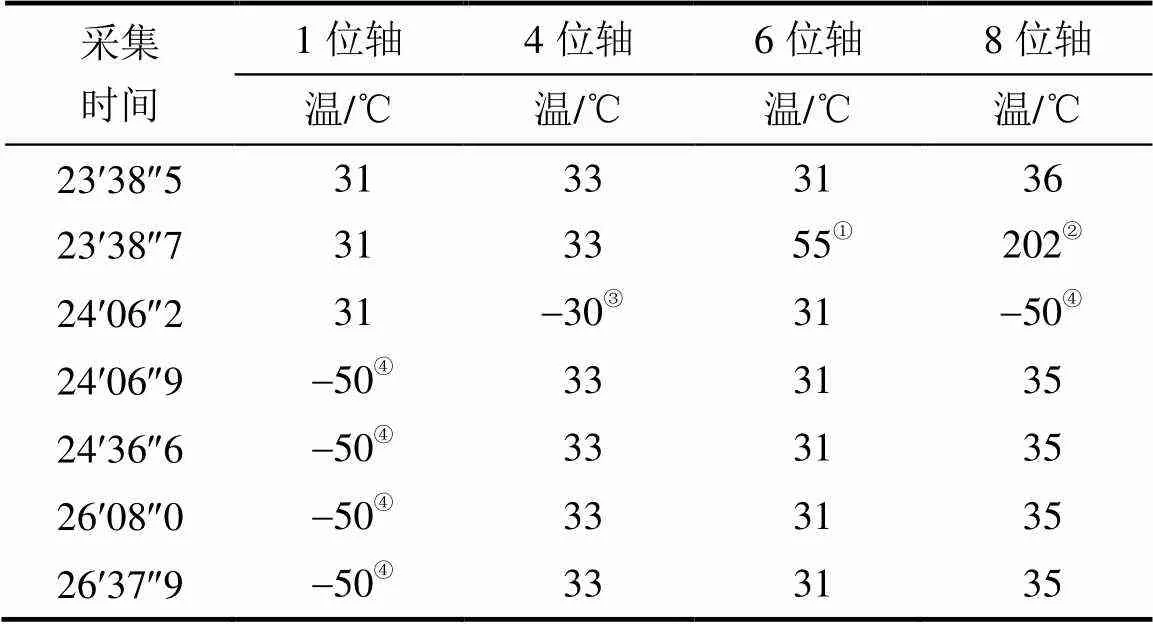
Tab.1 Example of jumping data of bogie axle temperature data
表1中采集的转向架传感器轴温数据样本采集时间精确到200毫秒,正常轴温数据处于30~38℃,由于多工况与传感器故障等情况的干扰,高铁回库后,检修人员在实际业务数据论证后发现表1中温度标记为①③是错误数据;标记为②是工况异常导致的转向架传感器温度跳变,业务上属于应报警处理的数据;标记为④的是传感器故障导致出错数据,也属于应报警处理的数据。可见多工况实时数据具有数据量大、复杂性高、难辨识等特征,需要依据多工况业务经验结合特定算法来辨识数据价值,不能采用单一算法或固定阈值进行监控处理。
2 过滤算法设计
多工况的实时数据过滤首先使用方差斜率算法,基于离线数据的主成分回归分析训练的GPS坐标多工况判据因子权重列表,在实时流计算中使用多工况权重算法进行计算,才能满足高铁数据过滤的效率与精度要求。
2.1 多工况判据因子选择
大数据平台实时流计算需要采集上千个传感器和开关数据,每个数据包含转向架定子轴温、小齿轮轴箱温度、大齿轮箱温度、速度、加速度、天气温度、轴振动频率、交流电压、直流电压、风压、海拔、GPS坐标等多工况数据。判断轴温健康监控数据,采用多判据因子实时权重的方法过滤工况干扰项,其主要判据因子权重比例见表2。
表2 轴温多判据因子权重表

Tab.2 Multi factor weighting table for axle temperature
在高速运行的高铁转向架健康监控中,由于列车线路不同、工况不同,导致每列动车采集的传感器轴温有所差异,因此需要按照交路运行的GPS坐标点划分交路点Ln和判据因子权重比UY才能进行计算,一般动车数据过滤选择表2中前八个工况作为判据因子,高寒动车需增加湿度和海拔判据因子权重。各个判据因子的权重比需要结合列车线路的实际路况,采用统计学和机器学习算法反复训练,并结合历史数据经验参考值得到合适的权重比以保证实时数据过滤的精准度和设备监控及健康预测管理的业务效果。
2.2 实时方差斜率算法
在计算资源有限的条件下,大数据流计算中选择复杂的数据过滤算法会导致数据积压,不能满足实时监控的秒级应用。在实践应用对比以后,使用方差斜率算法结合实时轴温监控算法的主成分多判据因子计算,计算0与1两个时间点的传感器方差值与时间的斜率作为基础判据主因子算法,如图1所示。
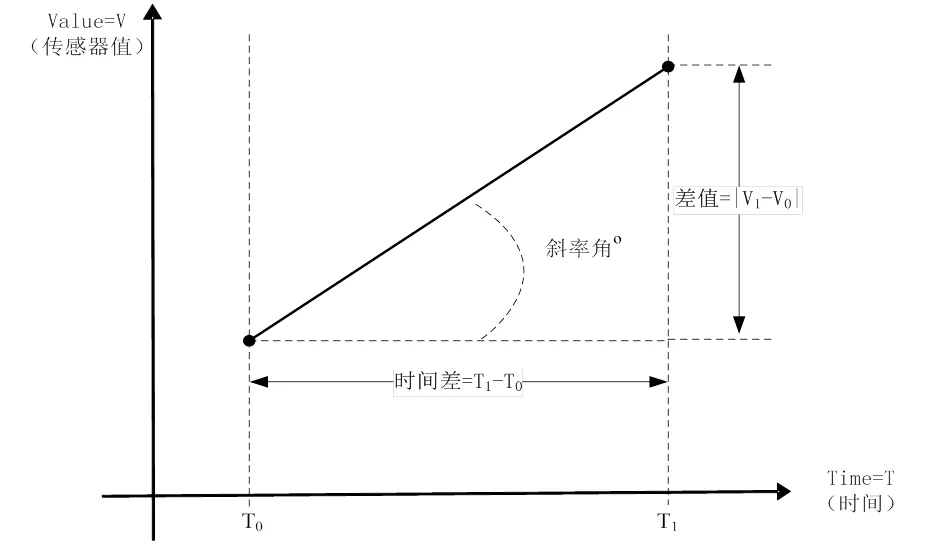
图1 方差斜率示意图

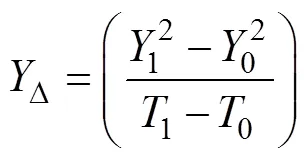
2.3 离线权重训练
通过使用Flume方式采集离线全量数据,并写入hadoop的hdfs,使用hive转换成Map和Reduce的任务进行传感器数据包的合并、解析、split拆分、集合分类、数据连续性稽核、最后根据交路GPS点的特征使用主成分权重算法得到实时流计算过滤所需要的权重值,计算流程见图2。
图2中实际运行需要根据交路上的所有列车运行的实际站台、岔口、海拔、桥梁、隧道、弯道等交路特征选择每日归档的全量工况数据才能进行主成分回归分析,并结合业务经验反复训练和验证得到合理的权重值。交路特征变化小的情况下列车匀速运行,其工况表现变化较小,但在遇不同交路特征时工况差异变化较大,因此需要将多工况离线权重值与交路线GPS坐标点进行标注关联,实时流计算中直接根据GPS坐标点读取多工况权重值进行数据过滤处理。
2.4 多工况权重算法
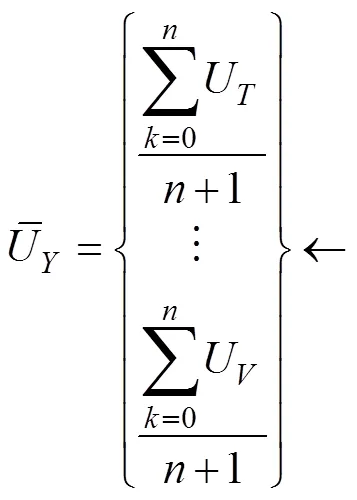
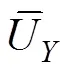
将表2中排名前几位的工况判据因子作为主要因素用于计算实时多工况权重C0,见公式3:
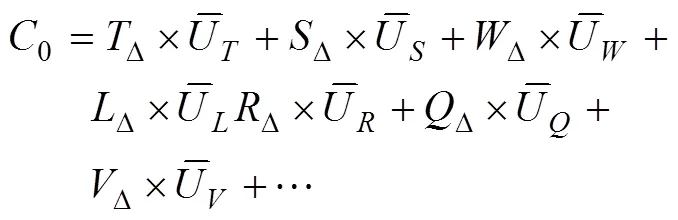
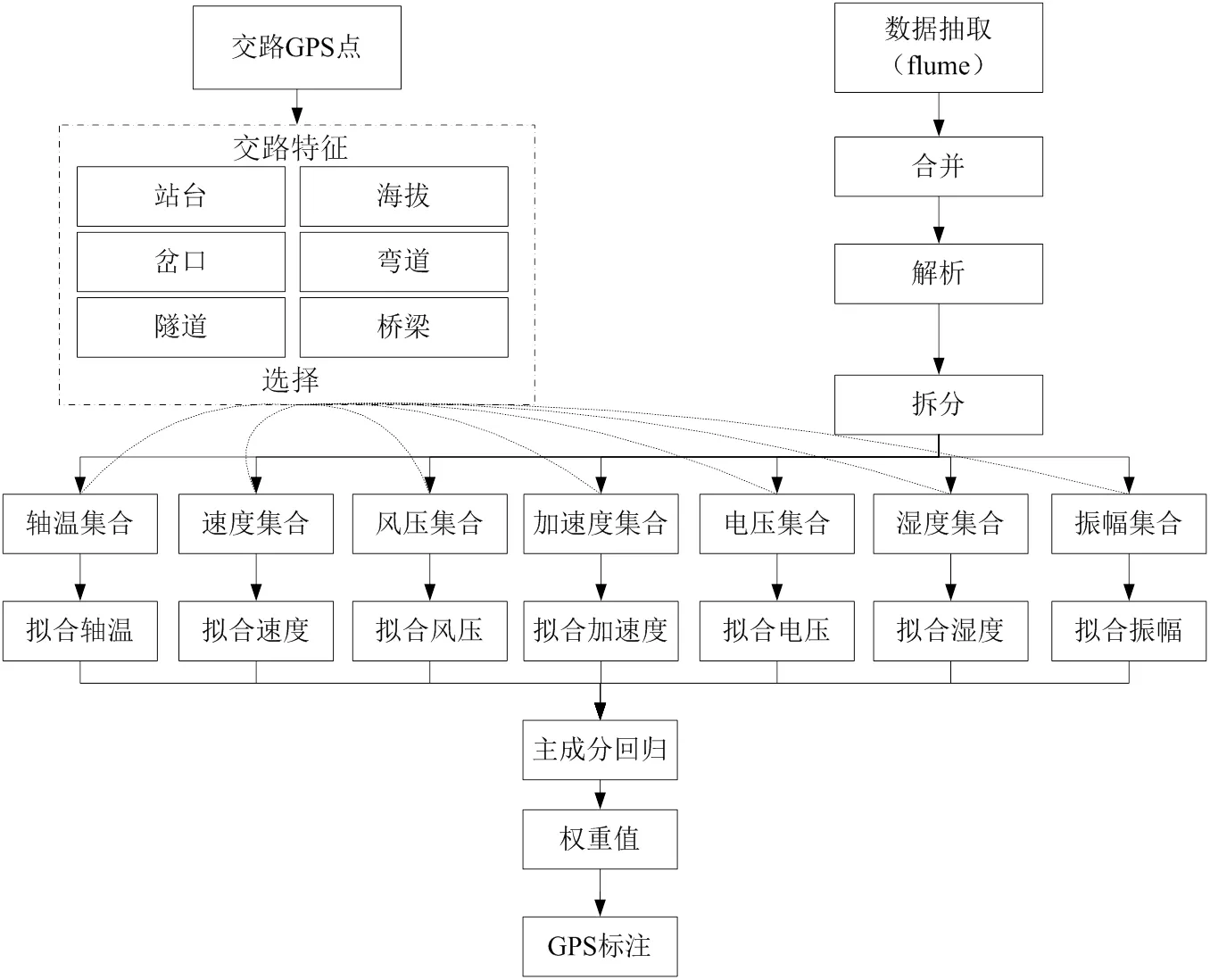
图2 离线经验值大数据训练流程图
在实时流计算中列车运行到这个点的时候动态选择相应的多个工况权重值,多工况的算子和权重标注示例如图3所示。
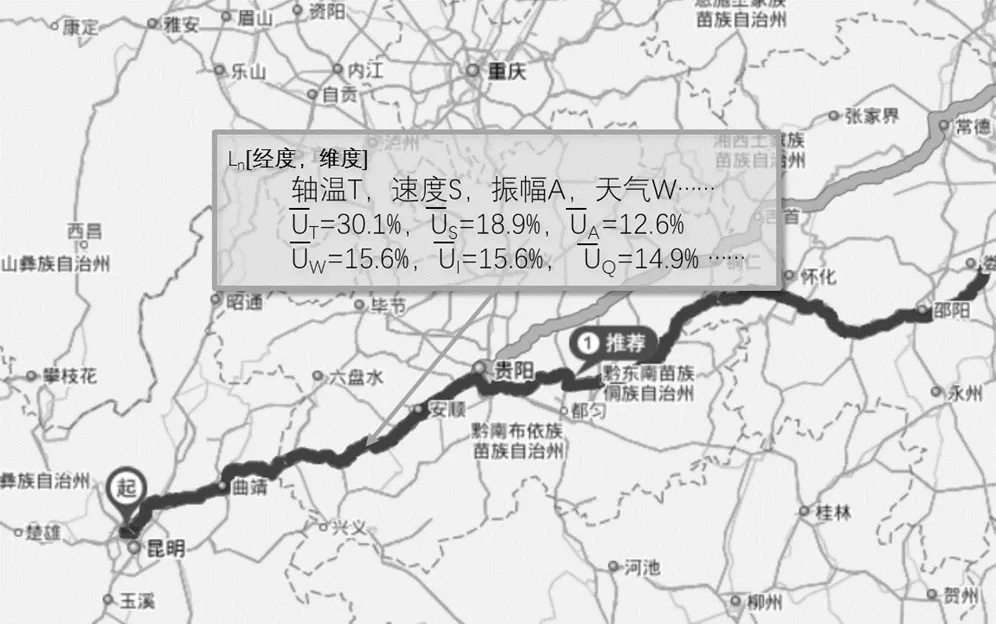
图3 交路GPS坐标Ln点判据因子与权重标注图
3 权重值拟合训练
3.1 训练方法
数据实时计算过程中如果使用海量多工况判据因子数据,会导致计算效率低下。因此只能使用离线训练的多工况判据因子数据的过滤权重值,并需结合高铁运行工况样本数据反复训练验证分析。项目通过高铁1年离线数据经过上百次的主成分回归分析训练和修订,得到能满足实时流计算精度要求的判据因子权重值列表。
采用支持向量机(Support Vector Machine, SVM)算法训练模式[14-15]能发现数据的工况原因和机理原因,但很难保障数据过滤精度,因此只能将各种判据因子作为机器学习的算法训练方式,迭代补充判据因子算法,确保算法更加精准、高效。
3.2 验证过程
训练验证数据过滤算法的有效性和高效性需要在流计算中固定算法处理逻辑,其验证程序实现逻辑流程见图4。
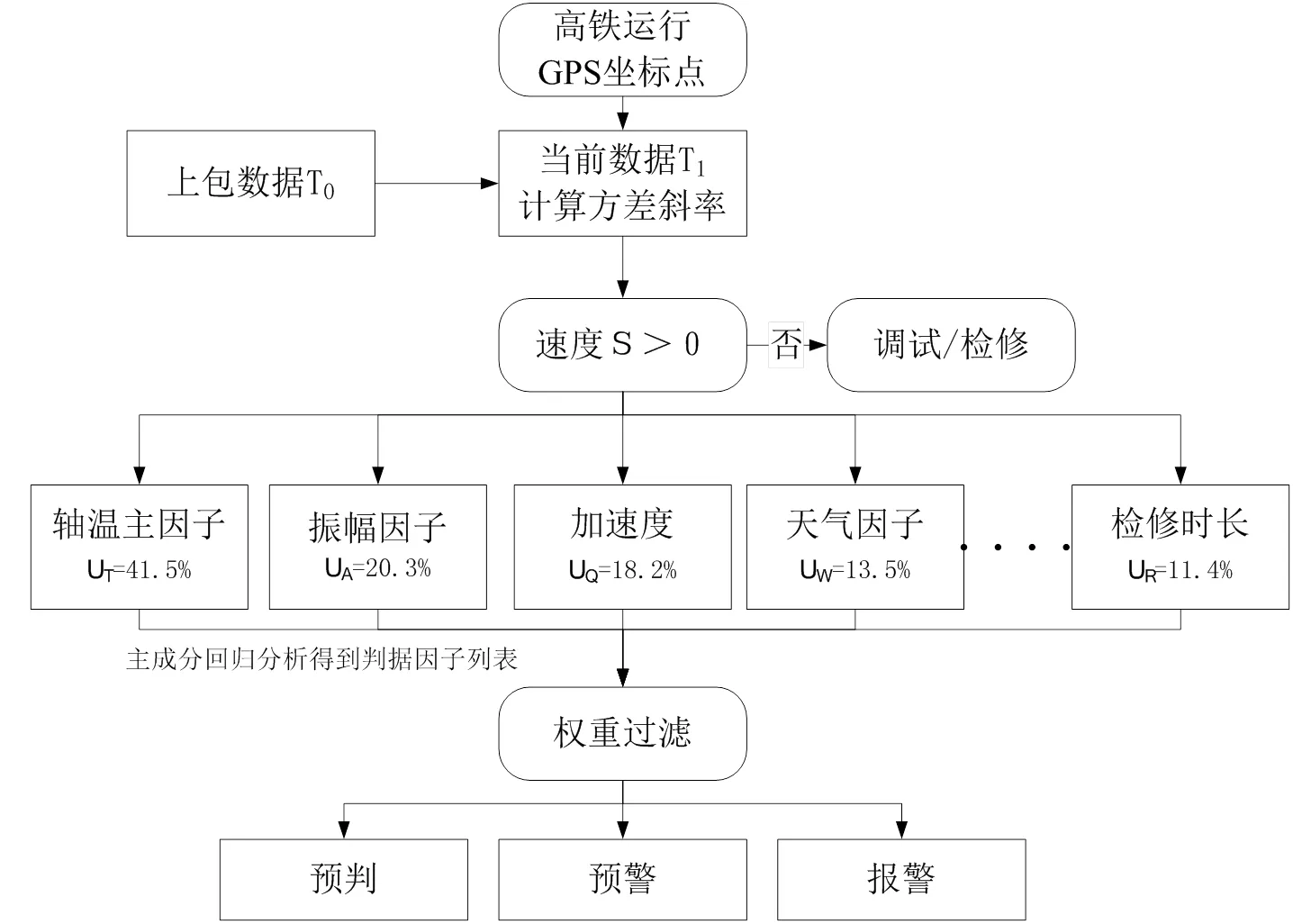
图4 线路上GPS坐标点的实时程序流程图
实时采集列车运行到交路GPS坐标的传感器数据,采用大数据的流计算技术,计算当前数据T1与上包数据T0方差斜率。如果是高寒动车交路线上,其天气因子的权重将自动排名靠前,根据图4的程序流程得到多工况判据因子主成分回归分析排名等权重值列表。最后计算相关因子权重占比,从而过滤出高价值的预判/预警/报警。
3.3 权重值列表训练
轴温交路的权重经验值是基于前一日的离线全量数据,采用主成分回归分析法[18]进行训练,最小二乘法回归算法主要用于主成分累计贡献率的残差推导。在不考虑长编组和连挂的情况下,1列车8节车厢,每节车厢36个轴温传感器,以200毫秒1个数据包来计算,1天数据量=8节×36个×24小时×60分钟× 60秒×5包/秒=1.244亿个轴温样本,剔除检修调试数据最少有几千万的样本,在进行经过离线大数据模型算法筛选后标记进交路的GPS坐标上,形成交路的轴温工况权重算法参考值数据。
为保障高铁在不同工况的轴温健康监控的准确率,需要对轴温斜率算法和参考值进行长期训练与优化,通过多轮算法与实际应用论证,基于交路坐标上采用主成分回归分析算法训练多工况数据的累计贡献率,通过降维后对多工况的不确定因素使用最小二乘法回归进行推导得到排名靠前的多工况因子权重列表。
步骤1:利用主成分回归分析拟合1年内所有列车在相同GPS点的轴温与多工况因子数据集合。
对个自变量进行主成分回归分析,假设表2中轴温相关的速度、加速度、外温、海拔等个样本值,聚合1年所有高铁经过这个GPS坐标指标集合为,得到所有坐标的主成分累计贡献值集合:
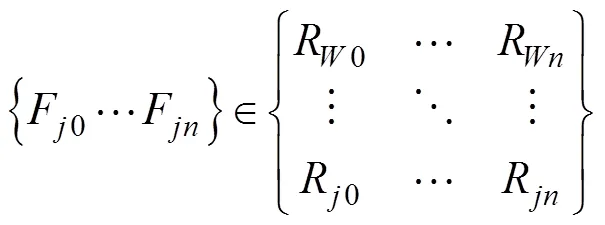
=,,,, …,(4)
公式4中代表GPS坐标序号,根据贡献值排名得到因子的主成分列表,由于排名靠后的因子对轴温的影响累计贡献率比较低,因此在这个GPS点上不作选择,而当GPS坐标发生变化时,由线路特征和工况发生变化,其因子的选择列表也会自动根据累计贡献率进行调整。所有历史数据进行主成分回归分析,并将所有主成分累计值进行均值运算,再进行排名提取因子列表,这样保证列车的主成分的因子成分贡献率的稳定性。
步骤2:采用最小二乘法回归算法对因变量进行多元线性回归计算:
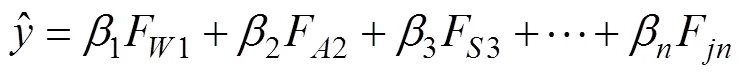
步骤3:流计算中将各个判据因子方差斜率与GPS坐标的影响因子权重值列表进行权重值占比拟合训练。对比分析业务故障机理原因,推导出合理的权重占比值列表,采用权重值之和大于90%以上的判据因子列表作为数据过滤条件。
4 验证与分析
全国两千多列高铁因建造时间不同,车上传感器种类不同、敏感性不同,采集的数据会存在差异。故每列车的机理模型还需根据具体列车特点推导、训练和验证。选择京广线上1列标动为例,根据交路工况特点在流计算中动态调整机理模型,进行数据和算法拟合验证故障预测效果。多工况机理模型需要采用高铁运行速度≥330 km/s的相同情况下,在固定的运行交路进行推导和验证。
4.1 单一算法与多工况权重算法对比
实验前期采用了很多单一算法进行验证分析(如:同侧轴温均值算法,温升斜率算法,线性回归算法,小波分析算法等等)都很难提升精准度和满足业务部门要求的数据预测,其系统实现的多工况单一算法机理分析如图5、6所示。

图5 轴温与速度单一算法机理分析系统效果图
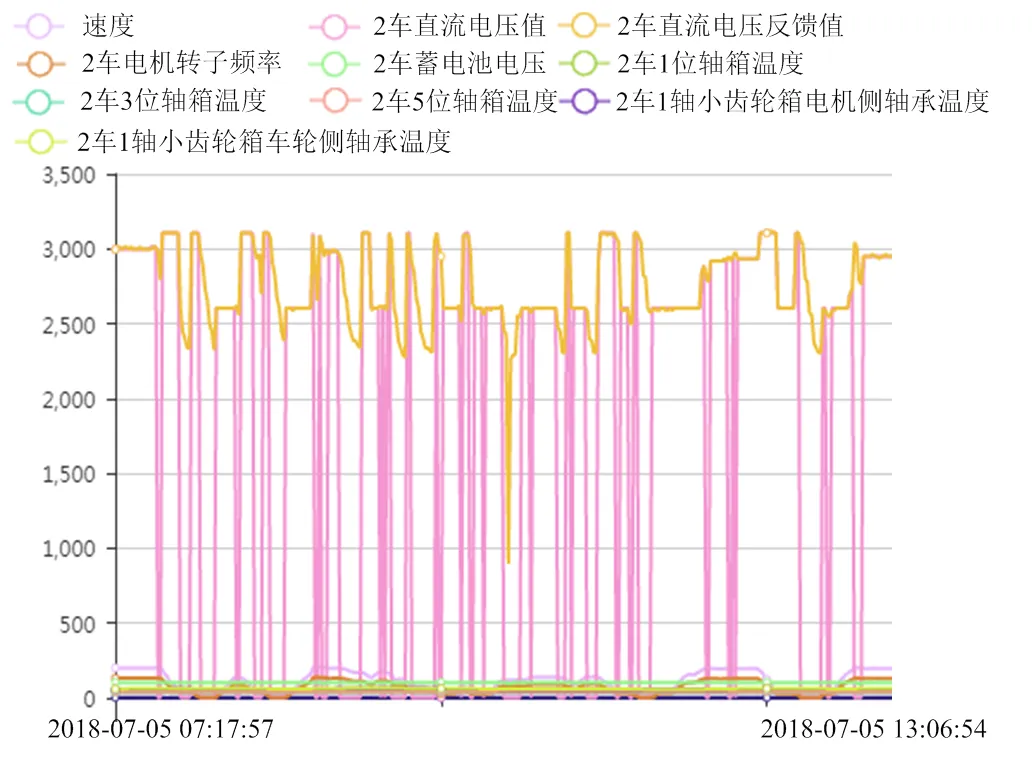
图6 多工况的单一算法机理分析系统效果图
在图5、6中是高铁监控与故障预测系统中流计算使用单一过滤算法的系统效果图,单一算法只能对标注点进行监控提示。因每种工况机理表现和数值都不一样,单一算法无法进行数据拟合和多工况因子针对性选择,只能分析机理现象。单一算法的标注提示后需要工程师通过业务经验进一步寻找故障发生时的机理原因,故障监控/预测不够准确,也容易增加检修工作量。
采用交路GPS坐标的多工况权重分析能解决业务部门转向架的数据分析难度,并有效提升效率。为验证算法的精准性,使用多种机器学习算法进行对比验证,其效果如表3所示。
表3 孤立森林模型估计结果
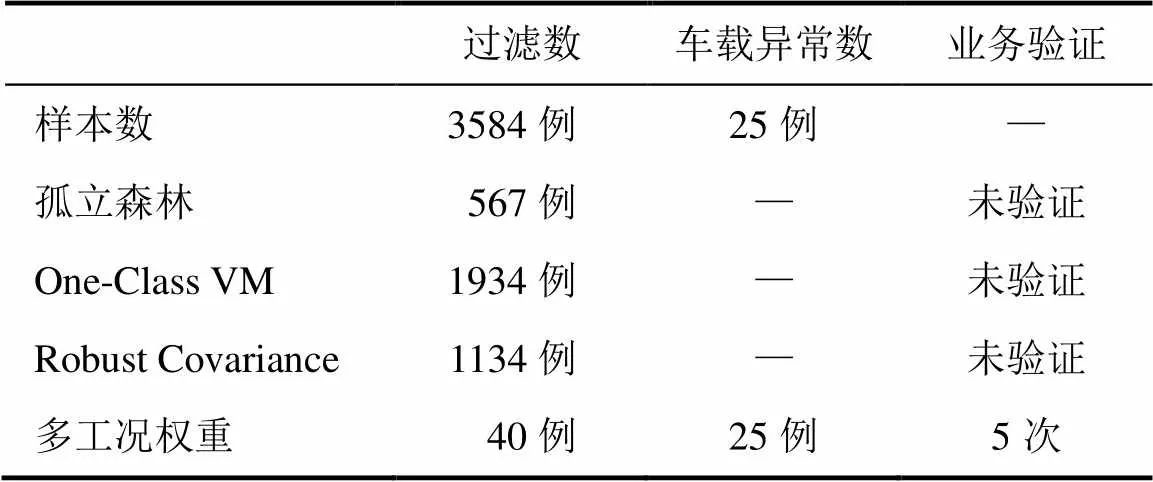
Tab.3 Estimation results of isolated forest models
在表3中采用3584例样本,其中车载异常数25例。采用孤立森林算法过滤出567例异常数据,One-Class SVM算法过滤出1934例异常数据,Robust Covariance算法过滤出1134例异常数据。使用多工况权重算法仅过滤出40例异常数据,进一步通过业务确认出全部25例真实异常数据。随机派单的5例异常数据中,权重比例之和全部达到95%以上,回库检修部门核查原因是转向架齿轮箱黄油过量导致轴温与其它工况出现数据异常,属于检修不合规导致异常,转向架正常没有故障,清理过多黄油后故障隐患排除。
可见前三种机器学习算法过滤出较多的非标 记异常数据,采用多工况权重算法有效数据过滤提升明显。
4.2 实时多工况权重算法验证
实时多工况权重算法在某列车某日16点48分52秒发生车载轴温报警的情况下,车载轴温预警分析如表4。
表4 轴温预警故障数据

Tab.4 Axle temperature warning fault data
表4中为体现轴温变化差异性,将数据按照30秒频率进行初步过滤对比,车上预警的控制策略是轴端温度大于100℃,车载预警模型发出预警故障。异常温度值只结合外温、不间断温升、最大温差、连续温升等轴温相关因子并不能准确预测故障。轴温故障预警需综合多工况因素考虑分析。多工况权重拟合多工况运行到这个GPS坐标点轴温相关工况因子原始数据见表5。
针对列车运行到16点48分52秒的数据表进行实时流计算,参照离线主成分回归训练的多工况权重值列表如表6。
根据业务权重数据过滤规则,此时表6中多工况权重值合为62.84%<90%,流计算中报警过滤标记为0。业务经人工实际验证以后没有故障,因此流计算中多工况权重算法计算结果是正确的,车载预警标记为预警故障是不准确的,实验证明使用多工况权重算法可以减少了检修部门很多无效工作量。
表5 轴温多工况原始变化表
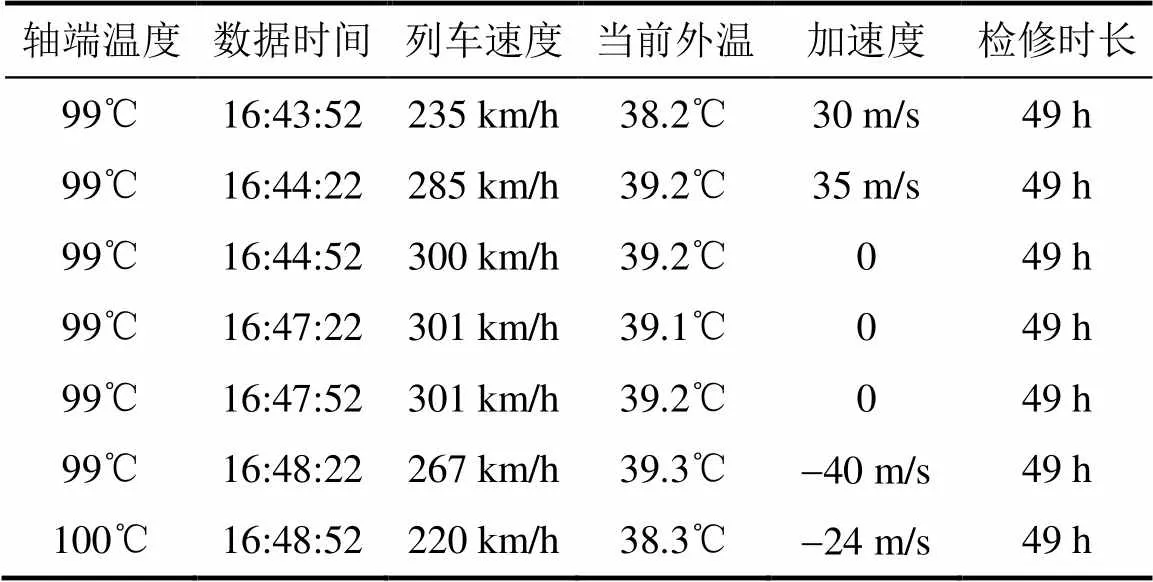
Tab.5 Original table of axle temperature and multiple working conditions
表6 车上轴温多工况权重算法验证表

Tab.6 Verification table of weight algorithm for axle temperature and multi working conditions
5 结论
在高铁转向架轴温的大数据实时流计算中,数据过滤算法的精度受限于不同工况环境中的影响,本文采用多判据因子方差斜率算法结合离线主成分回归分析训练的多工况权重值列表进行实时流计算处理,得到以下结论:
(1)数据过滤计算效率既能满足高铁轴温过滤的秒级性能指标要求,又能从上千列高铁全天9.96亿条多工况传感器数据中过滤出高价值数据。
(2)在实际项目运行测试中转向架健康监控和预测数据的精准度从85%提升到95%左右,有效减少了动车的实时监控运营误判率,降低了10%的检修运维工作量。
因受集群规模和计算资源的影响,实时数据过滤的难度主要在于简单的算法在海量历史数据中进行在线计算很难实现简单高效的计算,实验发现数据量越大,算法复杂度和运算效率是一对矛盾体,因此多工况的大数据过滤需要反复训练和调整算法,才能保障运算效率和过滤精度。
[1] 张春. 基于大数据的动车组故障关联关系规则挖掘算法研究与实现[D]. 北京: 北京交通大学, 2017
[2] 延婉梅. 动车组大数据清洗关键技术研究与实现[D]. 北京: 北京交通大学, 2015.
[3] 罗元剑, 姜建国, 王思叶. 基于有限状态机的RFID流数据过滤与清理技术[J]. 软件学报, 2014, 25(8): 1713-1728.
[4] 贾连锁. 一种数据过滤方法: 中国, 201610877127. 0[P]. 2016-12-21.
[5] 刘健男, 黄晓峰. 一种用于流计算的数据处理方法与设备: 中国, 201410679749. 3[P]. 2016-06-22.
[6] 姜文超, 林德熙, 孙傲冰等. 一种新的基于相似度过滤的大数据保序匹配与检索算法[J]. 计算机工程与科学, 2017, 39(7): 1249-1256.
[7] 饶齐, 杨燕, 滕飞等. 基于多视图加权聚类集成的高速列车工况识别[J]. 中国科学技术大学学报, 2018, 48(1): 35-41.
[8] 郭超, 杨燕江, 永全等. 基于多视图分类集成的高铁工况识别[J]. 山东大学学报(工学版), 2017, 47(1): 7-14.
[9] 陈云风, 王红军, 杨燕. 基于聚类集成的高铁故障诊断分析[J]. 计算机科学, 2015, 42(6): 233-238.
[10] B. Zhang, H. Wang, Y. Tang et al. Residual Useful Life Prediction for Slewing Bearing Based on Similarity under Different Working Conditions[J]. Experimental Techniques, 2018, 42(3): 215-227.
[11] 孔宪光, 章雄, 马洪波等. 面向复杂工业大数据的实时特征提取方法[J]. 西安电子科技大学学报(自然科学版) , 2016, 43(5): 70-74.
[12] Nicholas Tsagkarakis, Panos P. Markopoulos, George Sklivanitis et al. L1-norm Principal-Component Analysis of Complex Data[J]. IEEE Transactions on Signal Processing, 2018, 66(12): 3256-3267.
[13] Zhengshun Fei, Kangling Liu. Online process monitoring for complex systems with dynamic weighted principal component analysis[J]. Chinese Journal of Chemical Engineering, 2016, 49(6): 775-786 .
[14] Xiaochen Zhang, Dongxiang Jiang, Te HanRotating et al. Rotating Machinery Fault Diagnosis for Imbalanced Data Based on Fast Clustering Algorithm and Support Vector Machine[J]. Journal of Sensors, 2017, 57(2): 1-15.
[15] Optimization of Multi Kenerl Parallel Support Vector Machine based on Hadoop[C]// PROCEEDINGS OF 2016 IEEE ADVANCED INFORMATION MANAGEMENT, COMMUNICATES, ELECTRONIC AND AUTOMATION CONTROL CONFERENCE. New York: IEEE Press, 2016: 1602-1606.
[16] 杨连报, 李平, 薛蕊等. 基于不平衡文本数据挖掘的铁路信号设备故障智能分类[J]. 铁道学报, 2018, 40(2): 60-66.
[17] 李兆兴, 马自堂等. 面向批量处理的大数据检索过滤模型研究[J]. 计算机科学, 2015, 42(9): 70-74.
[18] 王惠文, 王劼, 黄海军. 主成分回归的建模策略研究[J]. 北京航空航天大学学报. 2008年6月(6): 661-664.
Data Filtering Algorithm for High Speed Bogie Based on Real-time Data Stream Computation
ZHAO Ke1, PENG Qing-chang2, LIU Guang-jun2
(1. City College, Kunming University of Science and Technology, Kunming 650051, China; 2. China Railway Rolling Stock Corporation Qingdao Sifang Co. LTD, Qingdao 266111, China)
In order to solve the problem of low efficiency and low accuracy of data filtering for high-speed railway bogie, which is affected by many working conditions in large data stream calculation. Multi-criterion factor variance slope algorithm is used to extract multi-condition data in the real-time stream calculation of high-speed railway large data, and the data is filtered by combining the weight reference values of the corresponding GPS coordinate points on the routing. Through the actual operation of high-speed rail projects, the method can effectively reduce data interference, improve the accuracy of data filtering to more than 95%, achieve accurate monitoring and prediction of high-speed rail bogie faults, greatly reduce the maintenance workload of high-speed rail bogies, and improve the maintenance efficiency. At the same time, it can satisfy the computation efficiency of real-time computation of millions of streams per second.
High-speed rail; Data filtering; Multiple criteria factor; Bogie; Stream computing
TP273.5
A
10.3969/j.issn.1003-6970.2018.11.021.
赵珂(1978-),女,硕士,讲师,主要研究方向:信号与信息处理、大数据挖掘;刘光俊(1993-),男,本科,助理工程师,主要研究方向:数据统计分析,大数据挖掘;彭清畅(1985-),男,本科,信息工程师,主要研究方向:软件工程、大数据架构。
赵珂,彭庆畅,刘光俊. 大数据实时流计算的高铁转向架数据过滤算法研究[J]. 软件,2018,39(11):88-95
