离散花朵授粉算法求解多目标柔性车间调度
2018-12-19黄海松初光勇
黄海松,刘 凯,初光勇
(1.贵州大学 现代制造技术教育部重点实验室,贵州 贵阳 550025; 2.铜仁职业技术学院 工学院,贵州 铜仁 554300)
0 引言
随着生产力的不断进步,生产调度在制造企业中的地位越来越重要。在工作效率、成本、加工质量等方面,生产调度成为影响企业的关键因素[1],调度方案的优劣会直接影响资源消耗和污染排放。因此,调度是生产计划的制定、资源合理利用中最重要的一环,也是先进制造和环保制造的研究方向[2]。
传统的作业车间调度问题对加工工序可以使用的机器进行了限制,柔性作业车间调度问题(Flexible Job-shop Scheduling Problem, FJSP)解除了机器选择的限制,是在传统问题上的扩展,其为典型的NP-hard问题,并且柔性作业车间调度更符合目前实际的生产状况[3]。相对其他算法而言,智能优化算法在求解FJSP上具有独特的优势,是目前的主流算法,如遗传算法、粒子群算法、蜂群算法等。前人在这些算法上取得了很多成果,例如:Rahmati等[4]针对车间调度中的完工时间以及机器负载问题,通过融合两种不同的排序方法改进传统的遗传算法求解问题;张超勇等[1]针对交货拖期、生产成本、最大完工时间和设备利用率等目标,采用改进的非支配遗传算法(Non(dominated Sorting Genetic AlgorithmⅡ,NSGA-Ⅱ)求解问题;朱传军等[5]针对提高车间调度算法的稳定性和鲁棒性,将工件状态、机器故障特点和调度策略结合,改进了混合重调度策略;Li等[6]针对最大完工时间、机器的总工作量和关键机器工作量,通过融合多种局部搜索来提高算法的寻优能力,提出了混合洗牌蛙跳算法;Luo等[7]针对流水车间,提出考虑不同电价的优化调度算法;刘爱军等[8]针对最大客户满意度和最大完工时间,提出一种纵横改进的多种群遗传算法;徐华等[9]针对最大完工时间、生产成本和生产质量,提出一种混合蝙蝠算法;李俊青等[10]针对最大完工时间、设备负荷及低碳环保等目标,提出一种混合禁忌搜索算法;Karthikeyan等[11]提出混合离散萤火虫算法求解以完工时间、机器工作量为目标的优化问题。
花朵授粉算法(Flower Pollination Algorithm, FPA)是剑桥大学Xin-She Yang教授[12]受自然界花朵授粉的启发下提出的。自从该算法提出以来,已经有许多学者将FPA应用于各个领域,如整数规划[13]、函数优化[14]、产品序列拆装[15]等,并取得了满意的效果。FJSP问题是一个NP-hard问题,目前很少有学者将FPA应用在FJSP问题上。综合以上所述,针对车间调度的多个优化目标,包括最大完工时间、生产成本、加工质量和能量消耗,本文提出一种离散花朵授粉算法(Discrete flower pollination algorithm, DFPA)对多目标车间调度进行求解:首先利用轮盘赌策略指派机器,避免初始种群的非可行解,其次提出改进FPA进行优化,最后使用机器序列算法求解目标值。与其他智能算法相比,本文算法的优点有:生成较高质量的初始种群,采用两种不同搜索方式避免算法的早熟收敛,使用机器序列算法同时计算多个目标。
通过实验验证并和其他算法比较,证明DFPA可以用于求解多目标柔性车间调度问题(Multi-Objective Flexible Job-shop Scheduling Problem, MOFJSP)。
1 问题描述与模型建立
多目标FJSP模型建立如下:n个加工工件集合J={J1,J2,J3,…,Ji,…,Jn}(i∈[1,n]),m台加工机器集合M={M1,M2,M3,…,Mj,…,Mm}(j∈[1,m]),有以下约束条件:①工件的每一道工序都可以在第x台机器上加工,x为可用机器集合,但只能被一台机器加工完成;②工序在加工过程中不会被外力干扰,即机器不会出现停工现象;③机器在任何时刻可以停工,其最多只能加工一件工件。
为了之后的公式表达,引入以下符号,如表1所示。

表1 数学符号定义
本文的调度模型考虑生产时间(T)、生产成本(C)、加工质量(Q)和能源消耗(E)4个优化目标,表示为min(T,C,Q,E)。各优化目标的具体计算方法如下:
(1)加工时间 最大加工时间
(1)
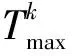
(2)加工成本 加工成本分为材料成本和加工成本两部分,其中:
1)材料成本
(2)
式中mci为第i个工件的原材料成本。
2)加工成本
(3)
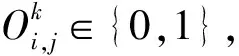
因此,最终的加工成本
C=MC+PC。
(4)
(3)加工质量 一台机器的性能优劣由该机器生产成品的不合格率反映,不合格率越高,机器的加工质量越差。并且随着工件的不断加工,后期出现不合格工序所造成的损失大于前期,故加工质量
(5)
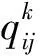
(4)能源消耗 能源消耗包括启动能源消耗、加工能源消耗、空载能源消耗,即
E=∑Es+∑En+∑Ep。
(6)
式中:∑Es表示启动能耗;∑En表示空载能耗;∑Ep表示加工能耗。
2 离散花朵授粉算法
原始的FPA应用于求解连续函数极值上。本文通过重新定义FPA的两种授粉方式,提出了离散的FPA。
2.1 编码与解码
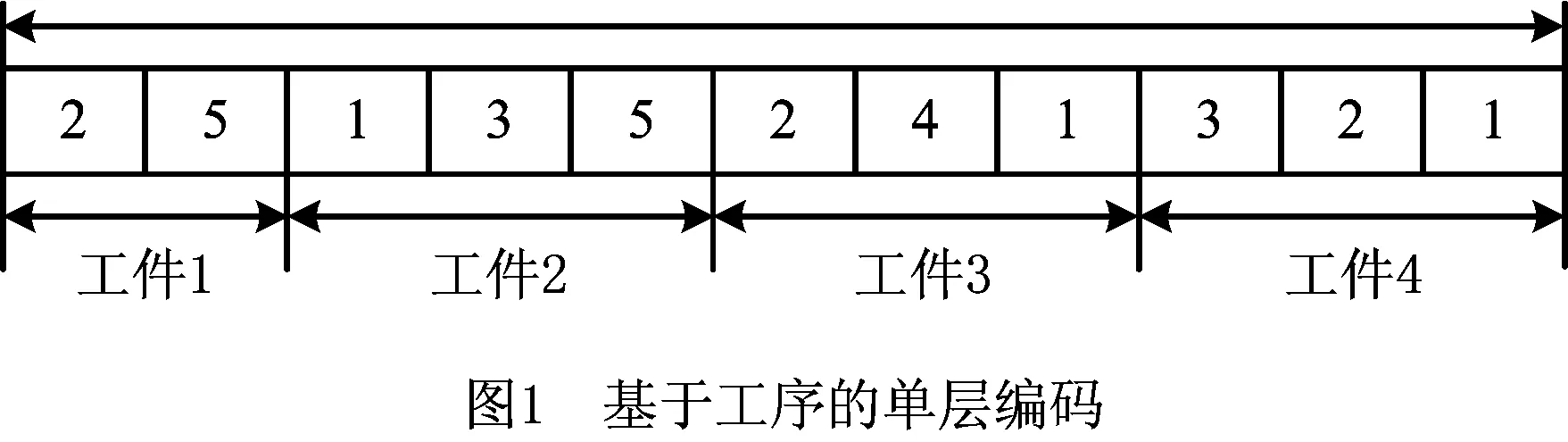
求解MOFJSP首先需要进行编码,编码方式的选择直接决定算法运行的速度和准确性。传统算法大多选择双层整数编码方式,但工序层的编码序列经FPA更新迭代后因产生大量非可行解而难以处理,增加了算法的复杂度,不适用于本算法。本文采用基于工序的单层编码[9],编码的形式为
O={M1,M2,M3,…,Mλ}。
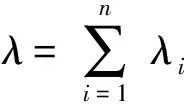
例如,一个基于工序的单层编码入图1所示,图中共有4个工件和5台机器,每个工件的待加工工序的数分别是2,3,3,3,其中的一个工序编码为O={2 5 1 3 5 2 4 1 3 2 1},由编码序列和每个工件的工序数可以得到11道工序,即O序列的长度。工件1共有2道工序,O(1)=2,O(2)=5表示工件1的第1道工序在2号机器上加工,工件1的第2道工序在5号机器上加工;工件2有3道工序,O(3)=1,O(4)=3,O(5)=5表示工件2的第1道工序在1号机器上加工,工件2的第2道工序在3号机器上加工,工件3的第3道工序在5号机器上加工。以此类推。
完成编码后需要进行解码操作,解码的结果存入矩阵PT中。矩阵PT为4×n的矩阵,n为总工序数,O的解码矩阵

式中:第1行表示工件号;第2行表示工序号;第3行表示加工机器号;第4行表示该工序在对应机器上的加工时长。例如第1列表示工件1的第1道工序在2号机器上加工,时间为1;第2列表示工件1的第2道工序在5号机器上加工,时间为2,以此类推。
2.2 轮盘赌均值派选
调度目标值的优劣取决于编码序列的优劣,提高初始种群的质量不仅可以缩短求解目标值的运行时间,还可以增强算法的搜寻能力,因此机器的选派对解的质量起至关重要的作用。因为柔性车间调度具有所产生的编码为非可行解,以及编码和结果不存在明显映射关系的特性,所以使用混沌序列方法产生的部分编码为非可行解,而反向搜索需要考虑非可行解与可行解的关系,其过程过于复杂。轮盘赌策略既满足了剔除非可行解、快速生成初始种群的要求,又保存了所有可用机器被选中的可能性,满足了初始种群的多样性。综上,本文提出一种平均值与轮盘赌算法相结合的方法构建初始种群解。
2.2.1 工序指派
对于任意两个工件i,j(i≠j)且λi=λj,在第λ道工序上有
(7)
(8)
(9)
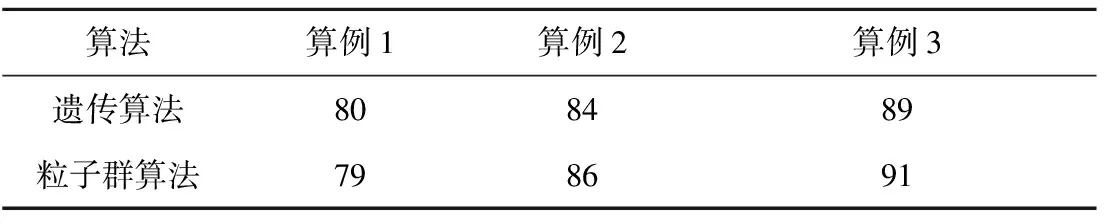
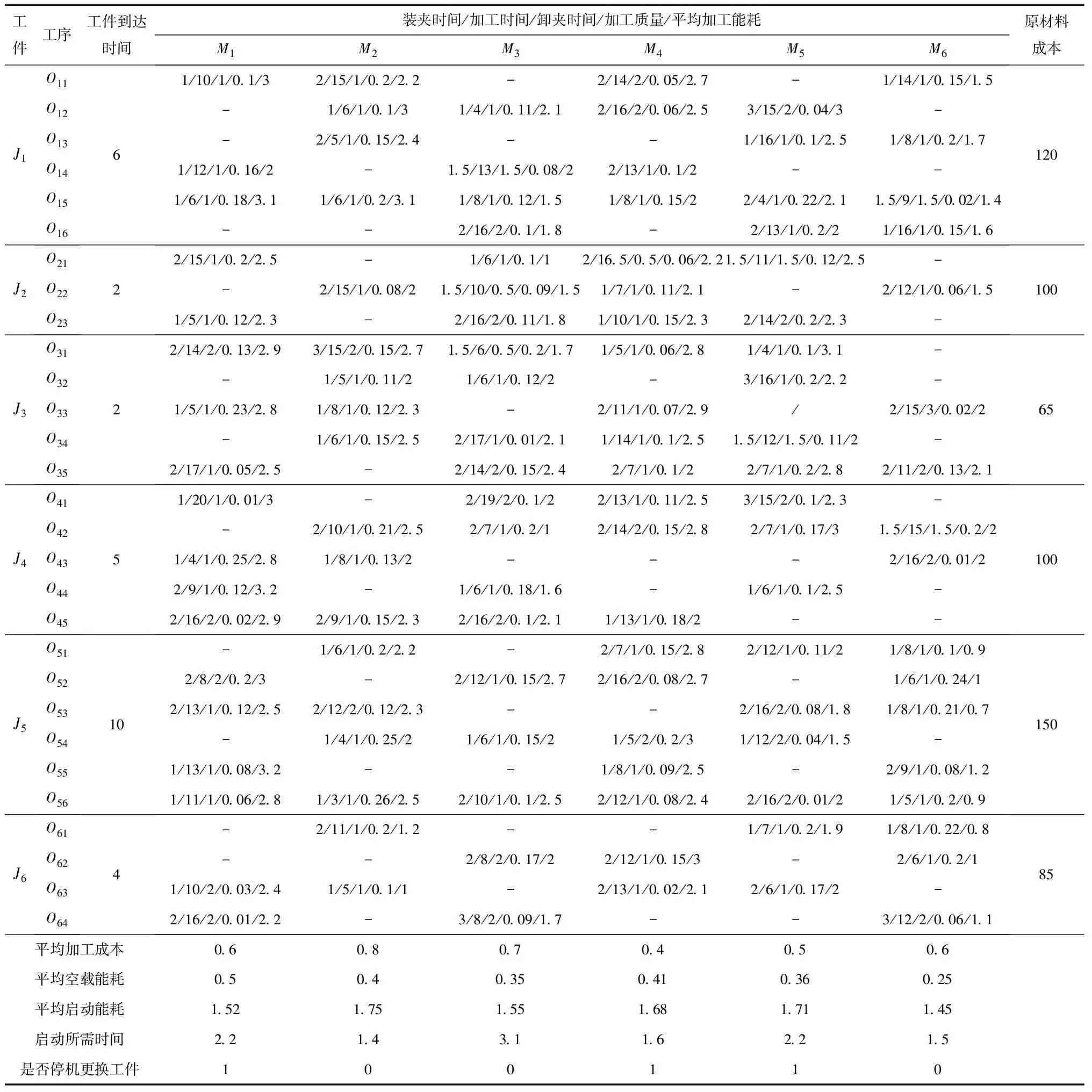
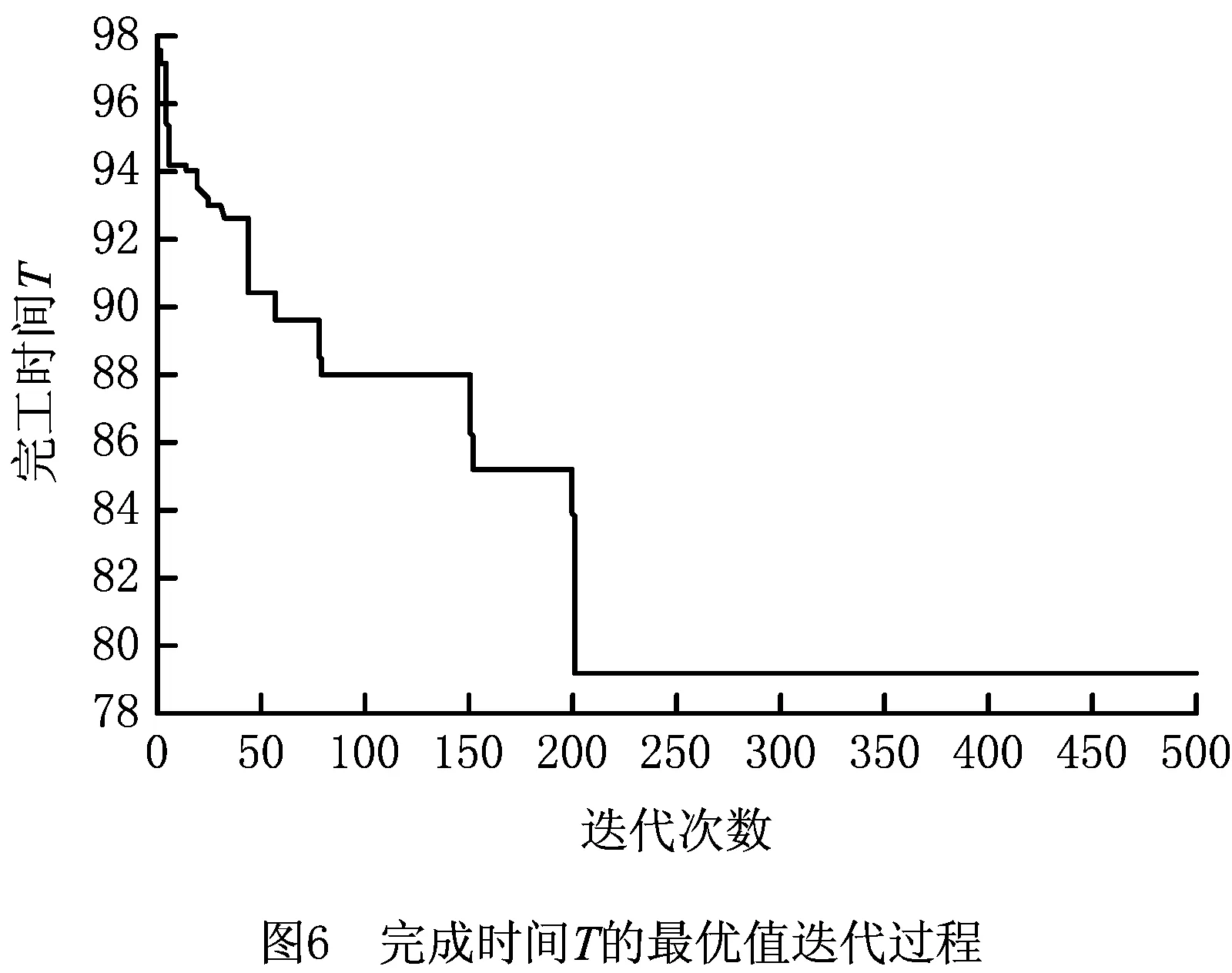
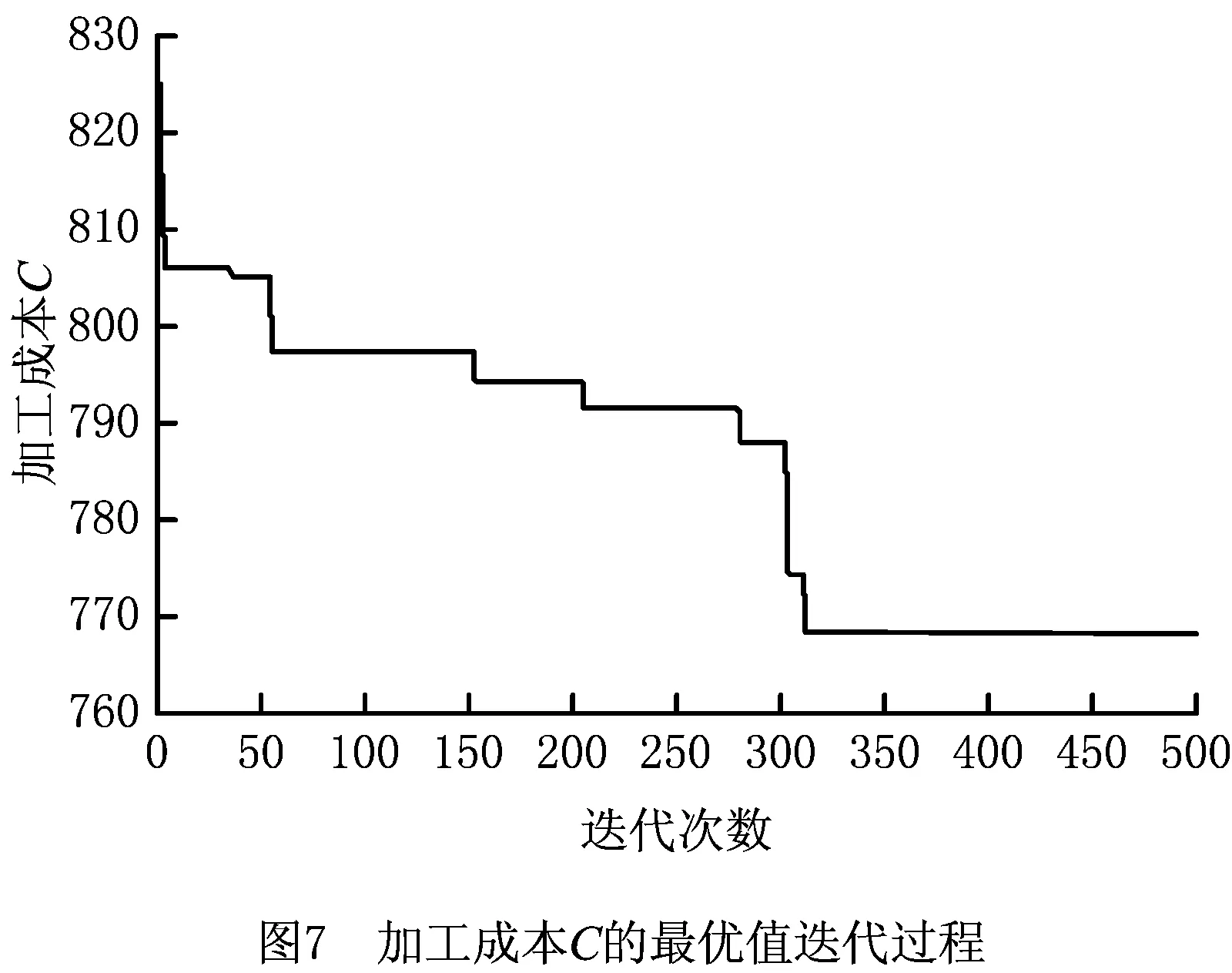
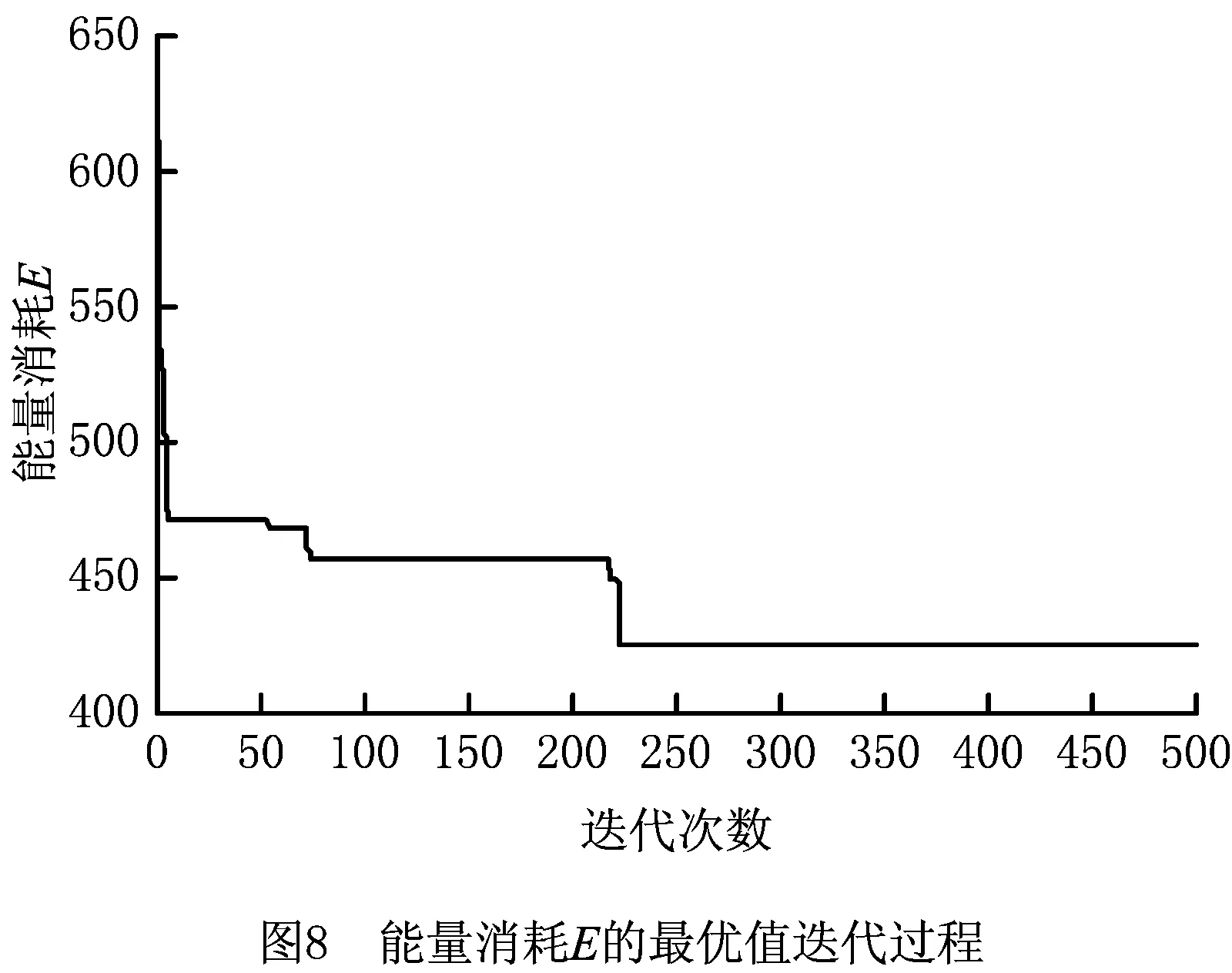
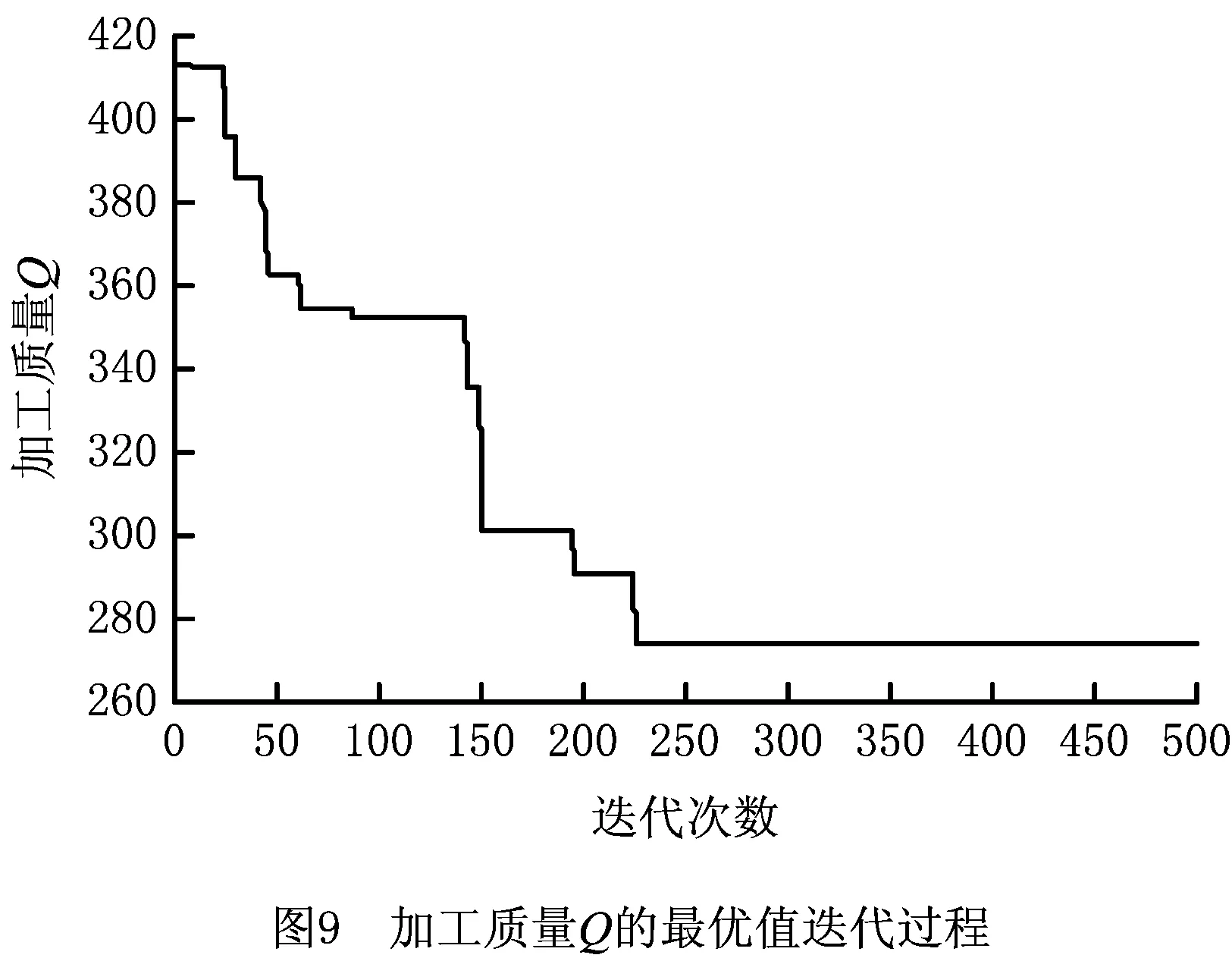
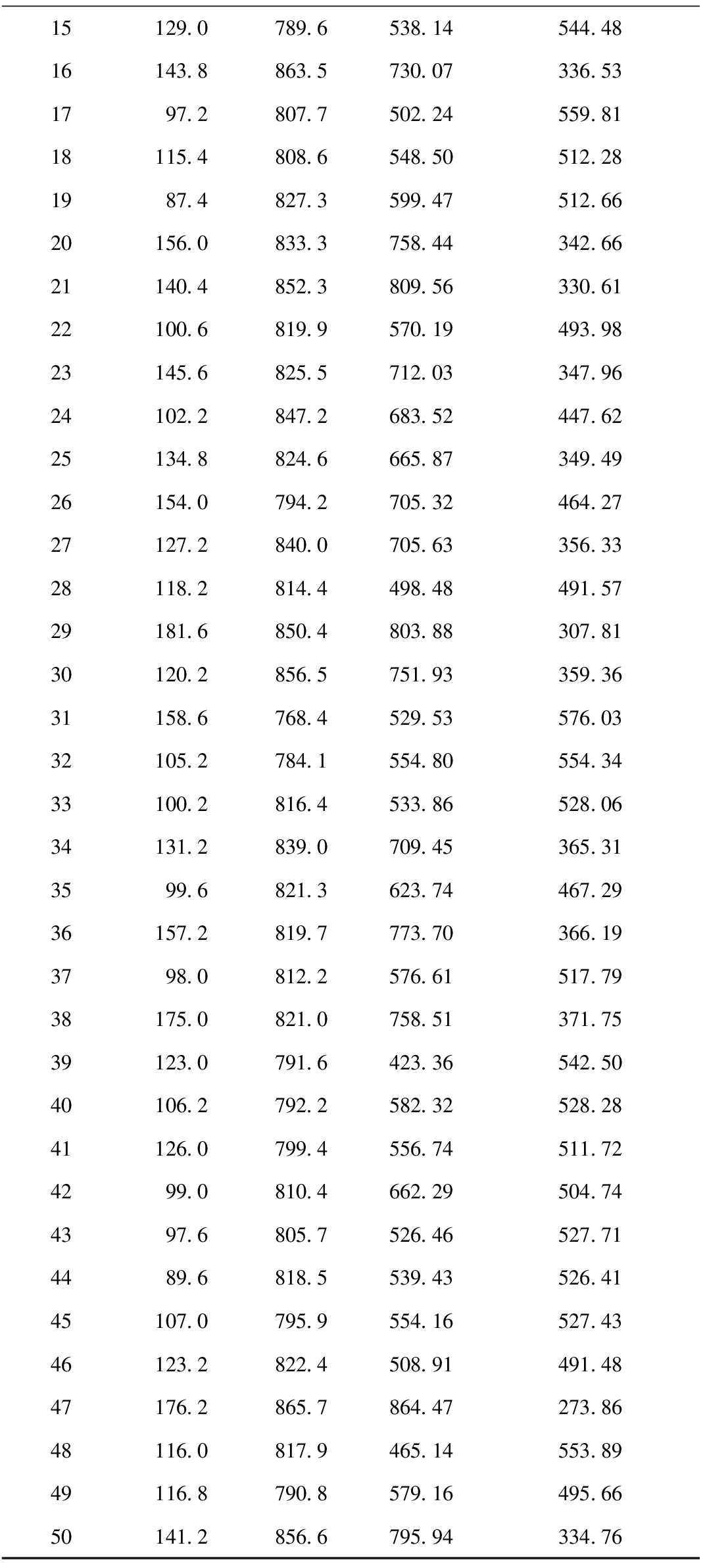
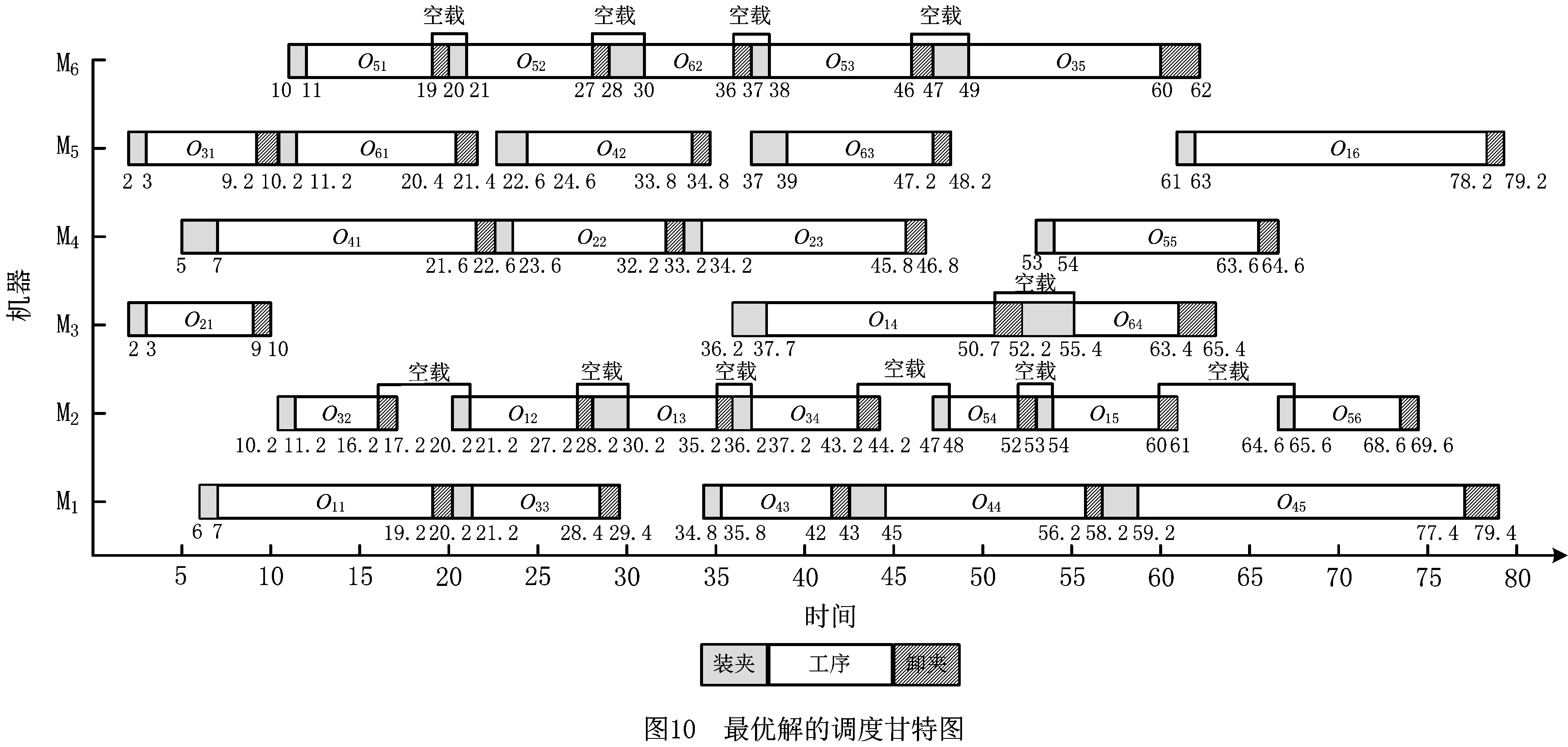
此时生成一个随机数p∈(0,1),若0 其中:ti,tj分别是工件i,j在第λ道工序上可使用的机器数量;Mi,λ(k),Mj,λ(k)表示工件i,j第λ道工序的第k台加工机器。 指派的基本思想是,先计算出可以加工该工件、工序的所有机器加工时间的总和,再分别求出工件对应的概率,最后生成一个随机数p,p落入哪个区间,就优先加工该区间对应的工件工序。指派原则是优先加工平均值较大的工序。 2.2.2 机器指派 工序确定后,为了避免出现二次编码现象,通过轮盘赌的方式选取机器。以3台机器为例,具体流程如下: (1)将表2中的加工时间从小到大排序,相应地调整第1行机器号码的次序。 表2 二维机器编码 (2)计算全部加工时间的总和∑Tj和每个工件j所占的比例pj, (10) (3)产生一个随机数g并满足g∈(0,1),如果0 由以上可以得出:2号机器不能加工该工序所以是0,故不会被指派。并且由式(10)可知用时越短的机器所占的比例越大,被指派的概率也越大,同时保存了其他可执行机器被选中的可能,满足初始种群的多样性并且不会产生非可行解。 多目标问题与单目标问题的最大区别在于多目标存在非支配解。本文采用适应度函数与聚集距离选择非支配解。 2.3.1 适应度计算 为了评价编码的优劣程度,引入带有权重系数的适应度函数,将每个个体的各个目标值与随机权重系数结合,然后线性组合得到个体的适应度,计算公式为 (11) 2.3.2 个体选择 对所得到的种群按照从大到小的顺序进行选择,适应度相同的个体需要通过一定策略进行筛选。本文采用聚集距离策略,该策略的优点是群体具有多样性。聚集距离的计算公式为 (12) 为维持种群多样性,聚集距离大的个体将参与下一次迭代。 FPA的基本步骤如下: 步骤1参数初始化,包括花朵初始种群的规模、转换概率p等。 步骤2计算种群里每个变量的解,并求出当前种群中的适应度值和所对应的解。 步骤3生成随机数rand,如果p>rand,则按式(13)处理,否则按式(14)处理。 (13) (14) 步骤4计算新解对应的适应度值,若新解对应的适应度较优,则用新解和对应的函数值替代当前解和当前解得的函数值。 步骤5通过前文的选择策略更新外部精英解集。 步骤6判断迭代次数。若达到结束条件,则退出程序,输出最优解和最优值,否则转步骤3。 对于MOFJSP这种离散问题,求解的难点在于花朵个体的定义,以及两种授粉规则不能直接用于处理编码更新。因此,本文构建一种DFPA重新定义花朵的个体及两种授粉方式,方法如下: (1)定义花朵 为了便于之后运算和比较,将种群中的花朵定义为一条编码 X=[M1,M2,M3,…,Mi,…,Mλ]。 (2)定义授粉方式 这里涉及两个序列的加减,即编码里每个位置的数对应相加减。例如:假设A=(1,2,3,4),B=(4,2,2,3),则C=A-B=(1,2,3,4)-(4,2,2,3)=(-3,0,1,1),D=A+B=(1,2,3,4)+(4,2,2,3)=(5,4,5,7)。 因此两种不同的授粉方式改为: (15) (16) 对产生的新解可行性进行判断和处理,处理方法如下:①对编码进行扫描并剔除不能使用的机器编号或不在机器集合里的编号;②使用上文所述的机器指派原则将编码补充完整,保证加工该工序的机器大概率为性能较好的机器。 确定编码并安排各个工件的工序先后顺序之后,需要计算各个目标值,因为本文共有4个优化目标,所以提出一种可一次性计算出编码序列4个目标值的机器序列算法,具体内容如下: 首先生成一个9×l×m机器矩阵,其中l为总工序数,m为加工机器数。将编码进行扩展,生成一个扩充矩阵,矩阵包括加工时长、能量消耗、加工质量等系数。一次读取扩展矩阵里的信息,并将信息填充进机器矩阵中。最后检索机器矩阵,输出4个目标值。 机器序列算法的伪代码如下: l//工序编码序列 pi//机器第几次执行加工 ST//记录工序时间 MT//机器矩阵 SizeX//计算编码长度 begin 输入编码序列x X//将其变成扩展矩阵 for i=1 to sizeX X(:,i)//读取扩展矩阵数据 a1=X(1,i)//记录工件号 a2=X(2,i)//记录工序号 a3=X(3,i)//记录机器号 If(p<2)//判断该机器是否为第一次执行 MT=X//将X的信息按照前文公式计算后赋值给MT,包括成本、质量系数、能耗 If(a2 ST(a1,a2)=MT(4,pi,a3)//完成时间作为下一道工序的开始时间 end else if (ST(a1,a2) ST(a1,a2)=MT(4,pi-1,a3) end MT=X//将X的信息按照前文公式计算后赋值给MT,包括时间、成本、质量系数、能耗 If(a2 ST(a1,a2)=MT(4,pi,a3)//完成时间作为下一道工序的开始时间 end end end 根据矩阵MT计算目标值 输出完工时间、加工成本、能源消耗、加工质量 end 其中:lo为工序存储序列,是l×n矩阵,n为工件数;pi为机器加工记录矩阵,记录机器第几次使用,是l×m矩阵,m为机器总数;ST为工序时间,是n×l矩阵,行数表示工件编号,列数表示工序编号;MT为机器矩阵,是9×l×m矩阵,第1~9行分别记录工件、工序、开始装夹时间、开始加工时间、开始卸夹时间、完成时间、成本、能耗、质量系数;X为编码序列扩展矩阵,是9×L矩阵,Len为编码序列长度,第1~9行分别记录工件、工序、加工机器、装夹时长、加工时长、卸夹时长、成本、能耗、质量系数。 参数初始化包括花朵种群的规模N、授粉方式转化概率p和最大迭代次数MaxIter。FPA流程图如图2所示。 本文算法采用MATLAB软件编程实现,计算机硬件条件:处理器为Core i5 2.5 GHz,内存为4 GB。下面分别从初始种群验证、关键参数设定、测试DFPA求解FJSP的性能、实例测试4个方面进行说明。 采用Kacern算例中的8×8算例,对比不同的初始种群生成策略,结果如表3所示。 表3 初始种群生成策略结果对比 由表3可以看出混沌序列的可行解为3,原因是一条序列中任意一个编码选择错误,这条序列就是非可行序列,故其可行解较少。虽然采用反向搜索和轮盘赌策略的运行结果均为120,但是反向搜索策略需要对非可行编码进行处理,而轮盘赌策略不需要考虑非可行解,因此反向搜索较为复杂,性能不如轮盘赌策略。 种群规模和迭代次数参考文献[15],3个参数中对结果影响较大的参数是转换率p,设置不同的p值并运行20次的结果如表4所示。 表4 不同P值的实验结果 从表4可以看出,当p=0.5时,无论算法的收敛性如何,寻优性都达到最好。DFPA初始参数如表5所示。 表5 离散花朵授粉算法初始参数设置 为了验证本文算法的性能,采用经典文献中的算例作为样本,并将运算结果与文献中的结果进行对比。 算例1数据来源于文献[16],有3个待加工工件和6台执行机器。本文的DFPA对算例1进行计算,得到的最小完工时间为123,对应最优解的甘特图如图3所示。 算例2数据来源于文献[17],分别有6个待加工工件和6台执行机器,得到的最小完工时间为200,对应的最优解的调度甘特图如图4所示。 算例3为了比较本算法的性能与其他算法的性能,采用标准算例Kacern中的一个8×8标准算例进行实验,并与最新研究成果对比,结果证明DFPA可以找到全局最优解14,调度甘特图如图5所示。 通过表6可以得出本文DFPA找到的最优解优于前两个文献的结果,且最优解比文献[16]的算法提高了8.2%,比文献[17]的算法提高了11.8%,第3个算例的解与目前最新研究成果相同。表7所示为本文算法求解3个算例的运行时间和达到最优结果的次数。通过表8与经典算法的运行时间对比,得出在时间复杂度方面FPA与经典算法相差不大。综上得出,本文所提DPFA在求解MOFJSP上是可行的,并且性能不差于经典文献的算法。 表6 3个算例结果比较 表7 算法得到的最优计算时间和迭代次数 表8 经典算法运行时间 实例来源于文献[20],其中加工工件数n=6,加工机器数m=6,工序的加工时长、装夹时长等具体数据如表9所示。 文献[20]给出加工时间、加工成本、加工质量和加工能耗的最优值分别为89,782.4,292.38,444.65。运行相同的算例,本文DFPA求得的最小最大完工时间为79.4,最小加工成本为768.4,最优加工质量为273.681,最小加工能耗为423.363。通过对比相同优化目标的最优值可以得出,本文DFPA在求解调度问题上优于文献[20]的算法。图6~图9分别表示完成时间、加工成本、加工质量和能源消耗的迭代过程。 图6~图9终止收敛次数不同的原因如下: (1)优化目标不同,不同优化目标最终的收敛次数可能不相同。虽然能量消耗和成产质量终止次数相近,但是由图8和图9可以看出其优化过程完全不同。 (2)因为FPA的授粉方式有两种且存在编码修补的随机性,所以迭代结果会产生差异。运行20次实例,由于有4个目标,共80次结果,收敛次数如表10所示,通过表10验证了之前的结论。 表9 实例数据 表10 收敛次数统计 收敛次数0~200200~300300~400400~500结果165122 通过删除重复个体,最终得到包含50组解的解集,如表11所示。 表11 最终得到的50组解集 续表11 算法的最终结果为车间调度提供一系列的不同解。在实际生产中,决策者根据不同的生产要求对4个优化目标设置不同的权重,本文沿用文献[20]提出的权重系数,令T,C,Q,E的权重系数分别为0.5,0.3,0.1,0.1。从表7得出第3组解为最优解,目标值为完工时间79.4、加工成本795.1、能源消耗561.402、加工质量555.927。对应的调度甘特图如图10所示。 本文以最大完工时间、加工成本、能源消耗和加工成本为优化目标,改进了FPA。为了使算法运行更加有效,选择基于工序的单层编码方式;为了解决所生成初始种群质量较低的问题,采用轮盘赌机器派选方式。重新定义了FPA中的两种授粉方式,并采用可以同时计算多个目标值的机器序列算法计算目标值。最后通过算例验证了DFPA的基本性能,实例证明该算法可以求解实际问题。未来将针对生产工厂分布的分散性和生产过程的不确定性改进FPA的算子,研究分布式车间的调度策略。
2.3 选择操作
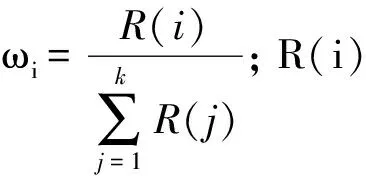
2.4 面向MOFJSP的花朵授粉算法
2.5 机器序列算法
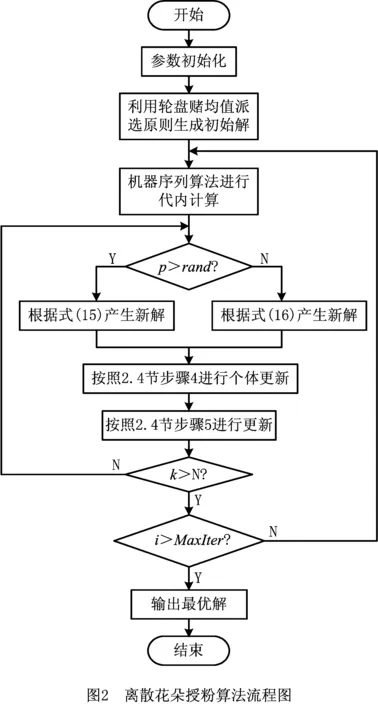
2.6 算法流程
3 实验仿真与分析
3.1 初始种群验证

3.2 关键参数设定


3.3 算法性能测试
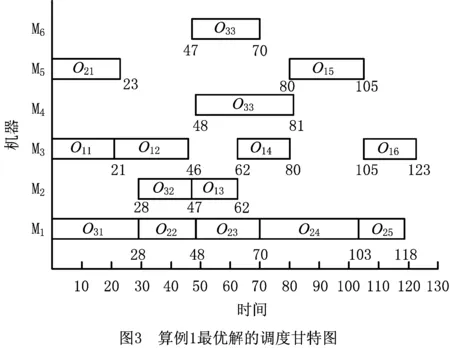
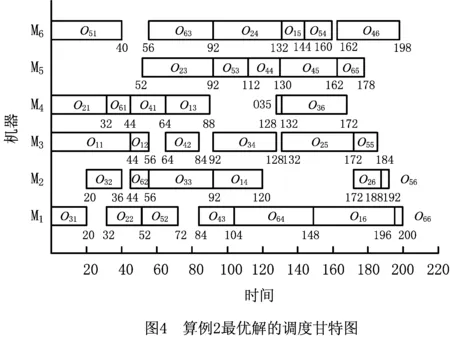
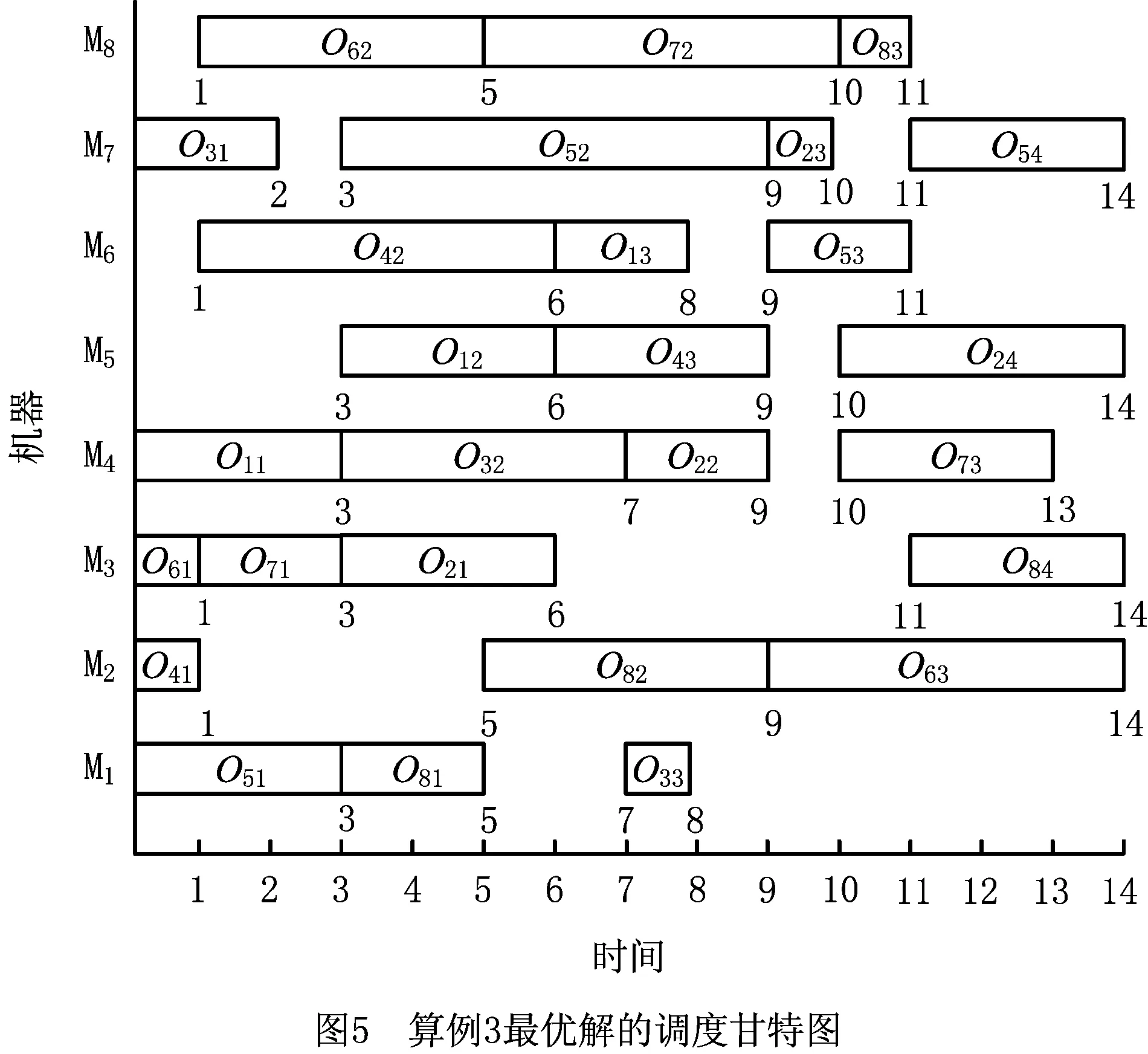

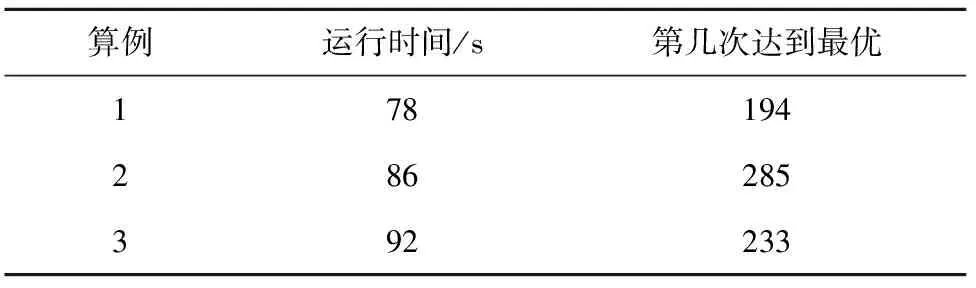
3.4 实例仿真


4 结束语
