关于对抗样本恢复的研究*
2018-12-19蒋凯,易平,2
蒋 凯,易 平,2
(1.上海交通大学 网络空间安全学院,上海 200240;2.上海市信息安全综合管理技术研究重点实验室,上海 200240)
0 引 言
深度神经网络目前已经被应用在各个领域并且取得了很好的效果,尤其是在文本分类[1]与图像分类领域[2]。然而,研究者发现,对于图像精心构造的细微扰动,能有效欺骗神经网络,使其输出
错误的预测结果,这类被扰动后的图像称为对抗样本(Adversarial Examples)[3],这种攻击被称作对抗攻击(Adversarial Attack)[3]。随着深度神经网络越来越广泛地应用于一些诸如癌症检测(Cancer Detection)[4]、智能驾驶(Self-driving)[5]等安全领域,对对抗攻击防御的研究变得尤为重要。
当前,已经有很多对抗防御方法被提。Akhtar等人将对抗防御方法分为仅检测(Detection Only)与完全防御(Complete Defense)两类[6]。在很多应用场景中,仅仅检测出图像是否为对抗样本是不够的,还必须知道对抗样本对应的真实分类,而完全防御可达到此目的。然而,完全防御方法往往需要大量的训练数据作支撑,以训练一个更鲁棒的分类模型或者根据学习到的信息改变对抗样本,可行性较差。因此,本文提出了两种不需要额外数据的防御方法,可以在已知图像为对抗样本的情况下将其正确分类,称之为对抗样本恢复方法。本文中,“恢复”的意思是指将分类模型对对抗样本的错误分类输出恢复为正确分类输出,而非将对抗样本逐个像素恢复为原来的图像。
将对抗样本恢复方法组合成恢复系统主要是基于三方面的考虑。一是本文提出的两种对抗样本恢复方法既不需要改变分类模型,也不需要改变输入图像,因此很适合组成一个恢复系统;二是单种恢复方法容易对某种特定攻击产生的对抗样本产生误判,尤其是最近一种基于混淆梯度(Obfuscated Gradients)的对抗攻击方法[7],成功使得7/8的ICLR会议的防御方法产生误判;三是对于某些扰动过大的图像,其真实标签本身就具有辩证性,在此种情况下认为恢复系统可以采取不恢复的策略,以降低恢复的错误率。
本文主要致力于研究对抗样本的恢复问题,主要贡献如下:
(1)提出两种不需要额外数据的对抗样本恢复方法,而目前还没有有关对抗样本恢复的概念被提出;
(2)设计了一个对抗样本恢复系统,可以将多种恢复方法组合在一起共同防御对抗攻击;
(3)将对抗样本恢复方法应用于恢复系统进行测试,发现通过调整不同的系统参数可以得到不同的系统性能。
本文结构组织如下:第1部分介绍相关的理论背景与研究现状,包括对抗样本的实质、图像的范数度量、将要使用的五种经典对抗攻击方法以及当前对对抗样本防御的现状;第2部分主要介绍提出的两种对抗样本恢复方法,包括基于CLEVER距离的恢复方法和基于第二概率的恢复方法;第3部分主要介绍设计的恢复系统;第4部分为实验部分,介绍了实验环境、结果度量指标,并分别在不同的对抗攻击下测试提出的恢复方法和恢复系统。最后,在第5部分进行总结。
1 理论背景与研究现状
1.1 对抗样本的实质
Szegedy等人首次指出了对抗样本的存在[3]。给定一个输入x和一个已经训练好的分类器f,有可能找到一个在某种度量下与x非常相近的x´,使得:

通常,攻击者总是尽可能小地扰动原始图像来生成对抗样本[8]。一方面,对原始图像扰动过多有可能较容易被检测出来;另一方面,扰动过多的图像可能已不是对抗样本,因为其实质会发生变化。Goodfellow等人认为,分类器过于线性才会导致对抗样本的存在[9],而在真实边界与分类器边界之间的区域则被称作对抗区域(Adversarial Regions)[10]。对抗样本的示意图如图1所示,其中直线代表模型的分类边界,曲线代表真实边界。若图像b轻微越过模型的分类边界,处于对抗区域,则为对抗样本;反之,若图像扰动过多,越过了对抗区域,则不是对抗样本。然而,真实边界往往很难精确确定。

图1 对抗样本
1.2 图像距离的度量
根据之前对对抗样本的定义,必须要有一种度量来衡量原始图像与对抗样本之前的距离。当前主要有3种范数的度量:L0、L2和L∞。可以将其写为Lp范数,则Lp距离可以被写为||x-x´||p,其中p范数被定义为:

具体地说,基于L0的攻击会尽可能扰动更少的像素,某些情况下甚至只扰动一个像素即可成功欺骗分类模型[11];L2范数衡量的是两张图像的欧几里得距离,是一种较为综合的度量方法;L∞范数则是度量像素的最大扰动,基于L∞的攻击方法总是轻微地扰动几乎所有像素。
1.3 经典对抗攻击算法
当前已经有很多种对抗攻击算法,本文选择其中五种经典攻击算法进行简要介绍并在后续用于测试,而这五种攻击算法涵盖了三种常用的距离度量。需要指出的是,很多攻击有多种范数版本,但这里只考虑其原始论文中的版本。此外,对抗攻击也可以被分为有靶向(Targeted)攻击和无靶向(Untargeted)攻击,或者白盒攻击和黑盒攻击,但本文只讨论无靶向白盒攻击。
(1)JSMA
JSMA(Jacobian-based Saliency Map Attack)[12]是一种基于L0范数的攻击。该算法一次修改原样本的一个像素,并监视对输出结果的影响,通过计算输出的变化梯度(即雅可比矩阵)获取显著性图。一旦计算出显著图,算法将可选择改变最有效的像素来欺骗网络,然后重复这个过程,直到在对抗样本中改变的像素到最大允许值或欺骗成功。
(2)DeepFool
DeepFool[8]是一种基于L2范数的攻击。这种算法对样本不断添加扰动,使得样本越过分类器的决策边界。在每次迭代中,通过一个小矢量来扰乱图像。该小矢量的方向是将样本所驻留的区域的边界进行线性化而获得近似边界的垂直方向。当扰动图像越过分类器的决策边界而改变其标签时,总扰动就是最终扰动。
(3)CW
CW[13]是一种基于L2范数的攻击。Carlini和Wagner设计了一个函数,其在对抗样本中有较小的值,但在正常样本中有较大的值,因此可以通过最小化这个函数搜寻到对抗样本。CW的优化的函数可以简写为:

其中,c是选定的正常量,D为选取范式下的欧式距离(样本点到加扰动后的样本点间的距离)。
(4)FGSM
FGSM(Fast Gradient Sign Method)[9]是一种基于L∞范数的攻击。基本思想是对图像中每个像素都添加扰动,从而最大化图像在正确类别中的损失函数,诱导模型分类错误。具体公式如下:

其中Xadv表示对抗样本,X表示原图像,函数J表示图像X在类别y中的损失函数。由于这种方法是用L∞范式限制扰动的,因此使用了sign函数。
(5)BIM
BIM(Basic Iterativa Method)[14]攻击也是基于L∞范数的攻击。该算法的主要思想是对样本迭代地使用FGSM,且把扰动的大小控制在预设的L∞范围内,具体公式如下:

BIM相较于FGSM的优势在于迭代的过程可以对样本点周围的损失函数空间有一个更精确的描述,极大地提高了攻击的成功率,然而其对抗样本的生成速度远远低于FGSM。
1.4 对抗攻击防御现状
当前,研究者们主要致力于对抗样本的检测,并且取得了很好的成果[15]。然而,在很多应用场景中,仅仅检测出对抗样本是不够的,还需要知道对抗样本的真实分类。例如,在智能驾驶中,如果安全系统只是检测出路边的限速标志为对抗样本,盲目停车是很危险的,此时如果能识别出对抗样本真实的分类,则可以避免很多事故的发生。
将对抗样本的真实分类正确识别的防御方法称作完全防御(Complete Defense)[6]。目前,已有多种完全防御方法被提出。对抗训练(Adversarial Training)[9]通过将对抗样本加入训练集进行训练,提高分类模型的鲁棒性,使其对一部分对抗样本“免疫”。Song等人[16]发现对抗样本与正常样本的分布不一致,于是首先学习正常样本的分布,然后将对抗样本向正常样本分布方向移动,以达到净化(Purify)对抗样本的目的。当前,完全防御方法极大地依赖于额外的数据,其实用性较差。
此外,完全防御方法要么改变原分类器的分类模型,要么改变对抗样本[6],因此很难将多种方法结合起来形成一个系统进行对抗防御。
2 对抗样本恢复算法
2.1 基于CLEVER距离的恢复方法
图像之间主要有三种距离度量。为了简化问题,先只讨论基于L2范数的距离度量,即欧几里得距离。基于L2范数的恢复方法也同样作用于其他范数的对抗攻击,且基于L∞范数的恢复方法和基于L2范数的恢复方法恢复率比较接近。
如图2所示,对于多分类问题来说,如果对抗样本a´处于分类A中,但距离分类B的边界最近,则认为对抗样本a´实际上属于分类B。
实践中,最关键的问题在于如何找到对抗样本到各个分类边界的距离。为了评估模型的鲁棒性,Weng等人[17]提出CLEVER方法来评估正常样本变为对抗样本所需要的最小扰动,这种最小扰动被称作CLEVER距离。CLEVER方法主要是基于极值定理,并且不限于攻击的种类。因此,本文将应用CLEVER度量的距离来恢复对抗样本。

图2 基于CLEVER距离恢复方法
根据CLEVER方法,对于p范数的最小扰动距离βp可以写成:

其中f为多分类器,fi为f可微的分量,c=argmax1≤i≤Kfj(x0)为多分类器对于x0的预测结果。Lq,x0为函数fj(x0)-fc(x0)在以x0点为圆心的球体中的利普西茨常量,该球体可以写为:

为了计算利普西茨常量,应该计算这个圆中的最大值。然而,当维度变高时,这是非常困难的。因此,Weng等人运用了极值定理来估计利普西茨常量。极值定理可以保证最大值只会服从三种极值分布中的一个,且可以极大地简化运算。
本文运用CLEVER方法来计算对抗样本到其他所有可能的分类的边界距离,并且找出最近的一个边界,认为其所对应的分类即为对抗样本的真实分类。由于计算CLEVER距离时不需要额外的数据,因此恢复对抗样本标签的过程中也不需要额外的数据。具体地,分别计算了基于L2范数和L∞范数的CLEVER距离,用于恢复对抗样本的真实标签,这种方法称作基于CLEVER距离的恢复方法。
2.2 基于第二概率的恢复方法
当一张图片通过已经训练好的神经网络分类器时,分类器通常会输出一个一维的向量来指示分类结果,并且选择该向量中最大的值所对应的分类作为分类器对该图像的分类结果。如果神经网络的最后一层包括softmax函数,则输出向量中的各个数字可以分布被解释为与之对应的类别的概率。
对抗攻击在每一次迭代中总是尽可能轻微地扰动输入图像,然后观察分类器的输出。一旦成功欺骗到分类器,攻击就会停止。也就是说,分类器对于真实类别的输出概率将会越来越小,直到它不再是最大概率。幸运的是,发现对抗样本真实类别总是对应分类器的第二大概率。
基于第二概率的恢复方法即寻找分类器输出的第二概率所对应的类别,并将此作为对抗样本的正确类别。显然,这种方法也不需要额外的数据。
3 对抗样本恢复系统
恢复系统的简图如图3所示。设恢复系统中共有n种恢复算法,记作Ri(1≤i≤n)。当对抗样本通过恢复系统时,系统中的每种恢复方法都尝试输出它们认为该对抗样本真实属于的分类。设output_i为恢复算法Ri输出值的OneHot编码,WRi为算法Ri的权重,C为管理员设定的一个常数(0<C≤n),则指示值Judge_R可以被写为:
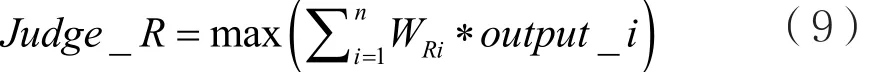
如果Judge_R<C,则系统拒绝对该对抗样本进行恢复,不得不将对抗样本送给人工判断或者丢弃。反之,恢复系统将把对抗样本的真实标签恢复为:

有可能会有多个分类标签同时符合式(10)的要求,则恢复系统将随机选取其中一个分类标签作为系统的恢复结果。

图3 恢复系统
很显然,设定一个合理的参数C很重要。C越大,系统越不容易作出判断,但一旦作出判断,可能会有更低的错误率,因此会直接影响到系统的恢复率和错误率。对于每种恢复方法的权重WRi,可以将恢复率较大的恢复方法设置一个较大的权重,也可以将经评估不易被攻破的恢复方法设置较大的权重。本文暂不讨论这个问题,在后续的实验中将所有的权重都设置为1。
4 实验与分析
4.1 实验环境
实验中所用的数据集为MNIST手写数据集,其中包括了60 000张训练图像和10 000测试图像。使用一个和Carlini等人[13]相同的七层类AlexNet网络进行测试,该模型可以达到99.1%的分类准确率。运用前文提到的五种经典攻击分别攻击训练好的模型并生成对抗样本,每种攻击生成1 000张对抗样本。由于L2范数和L∞范数有很大不同,因此将基于L2范数和L∞范数的CLEVER距离恢复方法视作两种恢复方法,分别记作L2-dis和L∞-dis,用Prob表示基于第二概率的恢复方法,即实验中有三种恢复方法。
4.2 实验参数及评估标准
4.2.1 实验参数
设每种恢复方法的权重都为1,则之前介绍的参数C也为整数,且可以被看作系统需要做出决定所需要的最少票数。在本次实验中,共有3种恢复方法,因此参数C可以取1、2、3。
4.2.2 评估标准
实验中主要有两个评估标准:错误率和恢复率。设A为通过恢复系统的对抗样本总数目,R为系统正确恢复的对抗样本数目,W为系统错误恢复的对抗样本数目(A≥R+W),则系统错误率Err及恢复率Rec可以记作:

一般来说,错误率Err越低,系统鲁棒性越好;恢复率Rec越高,系统的可用性越好。
4.3 五种经典攻击下恢复方法及系统的表现
图4展示了原始图像与用五种对抗攻击分别生成的对抗样本的对比,在这里所使用的攻击参数和之后测试时是一样的。可以看到,对抗样本和原始图像非常接近,尤其是对于DeepFool和CW攻击生成的对抗样本。

图4 原始图像与对抗样本的比较
使用五种经典的攻击分别生成了1 000个对抗样本。表1中第二行是原图像与对抗样本的平均距离,其所用的距离范数为与之对应的对抗攻击所使用的范数。表2为本文提出的三种恢复方法对各种对抗攻击的恢复率,可看到恢复方法对由DeepFool与CW生成的对抗样本表现最好,可以达到98.9%以上的准确率;对由JSMA攻击生成的对抗样本恢复最差,恢复率最低为66.2%。

表1 各种攻击生成的对抗样本与原始图像的距离

表2 三种恢复方法对于对抗样本的恢复率
将三种恢复方法组成恢复系统,分别测试了不同参数C下系统的错误率和恢复率,并与单独的恢复方法错误率和恢复率的平均值进行对比,结果如图5、图6所示。

图5 恢复方法与恢复系统对经典攻击的恢复错误率
从图5可以看到,相较之下,单种恢复方法的恢复错误率较高,将恢复方法组合成恢复系统可以有效降低恢复错误率。随着系统参数C的增加,恢复系统的错误率还在不断降低。从图6中可以看到,当C=1时,系统恢复率较单种恢复方法的平均更高;当加大参数C的取值时,系统的恢复率将不断降低;当C=3时,系统恢复率最低。
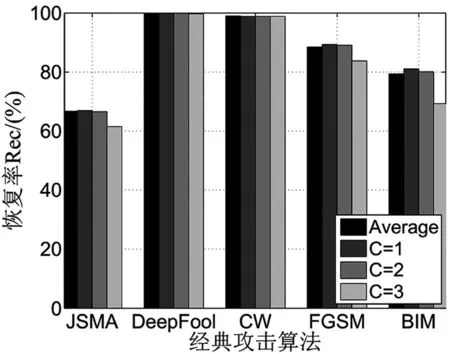
图6 恢复方法与恢复系统对经典攻击的恢复率
由于提出的恢复方法对于DeepFool或CW攻击生成的对抗样本已经达到了很低的错误率和很高的恢复率,因此将其组合成恢复系统其性能提升并不明显。此外,恢复系统尽管可以降低系统错误率,但对于JSMA攻击生成的对抗样本,当C=3时,依然有24.8%的错误率,这是因为JSMA在MNIST数据集上扰动过于明显。图7为C=3时恢复系统恢复错误的JSMA生成的对抗样本,其中第一行为与之对应的原始图像。不难看出,由于扰动过大,部分对抗样本已经发生了质的改变,和与之对应的原始图像已经不再属于同一类别。

图7 由JSMA生成且当C=3时系统错误恢复的对抗样本
4.4 实验结果分析
根据实验结果可以看到,本文提出的恢复方法对于经典攻击生成的对抗样本都有一定的恢复效果。其中,对于由DeepFool生成的对抗样本可以达到99.7%以上的恢复率,具有一定的实用价值。
根据实验结果柱状图不难看出,当系统参数C=1时,系统的错误率低于单种恢复方法错误率的均值,且系统的恢复率大于单种恢复方法恢复率的均值。由此可以知道,当系统参数C=1时,恢复系统性能优于单种恢复方法的平均性能。
此外,当增大系统参数C时,系统错误率将不断降低,但同时恢复率也在不断降低。因此,可以通过调整系统参数C来获得不同的系统错误率和恢复率,以满足不同的实际应用。以智能驾驶为例,当安全系统发现对抗样本时,如果不是在紧急情况下,则可以设定一个较大的参数C,以降低系统错误率,防止系统误判。对于系统无法恢复的对抗样本,可由驾驶员人工判断;当处于紧急情况时,由于驾驶员没有任何反应的时间,因此可以设定一个较小的参数C,以达到一个较高的恢复率。
5 结 语
对抗样本的存在必然给神经网络带来了极大的安全挑战,仅仅检测图像是否为对抗样本是不够的,而完全防御方法又需要大量的额外数据。本文提出了两种不需要额外数据的对抗样本恢复方法,可以在已知图像为对抗样本的情况下将对抗样本正确分类。由于本文提出的两种恢复方法既不需要改变分类模型,也不需要改变图像本身,因此很合适系统化。本文设计了一个对抗样本恢复系统,并且将提出的恢复方法组成系统进行测试。实验结果表明,提出的恢复方法具有较高的恢复率;在特定参数下,恢复系统的恢复性能优于单种恢复方法的平均值;通过设置不同的系统参数,可以获得较低的错误率或者较高恢复率,以满足不同的应用场景。
