基于Android平台的音视频监控系统的设计
2018-12-13杨志勇李卫锋
杨志勇 李卫锋 张 盛
(清华大学深圳研究生院 广东 深圳 518055)
0 引 言
近年来人工智能技术的快速发展,语音识别技术逐渐成熟,同时随着Android智能手机和移动互联网的普及,人们可以随时随地接入互联网。如何通过手机实时查看家中的情况,以及家中出现各种状况时能够及时地通知到我们,成了大家迫切希望解决的问题。因此开发基于Android平台的音视频监控系统对改善人们的居住条件具有重大意义,未来发展空间巨大。
本文介绍了一种基于Android平台的音视频监控系统[1],该系统分为数据采集端和用户手机APP监控端。数据采集端可以安装在各种带有摄像头和录音功能的Android终端上,用户能够通过语音唤醒系统,然后控制摄像头的打开与关闭,同时还可以接收其他语音指令并通过云端服务器发送到用户手机APP监控端。在用户手机APP监控端可以对收到的语音指令做出对应的响应,同时也可以发送消息给数据采集端。因此,本系统可以非常方便地在数据采集端与手机APP监控端进行互动,大大增强了传统监控系统的功能,同时可以根据需要随时打开和关闭视频监控,节约服务器资源和网络带宽,为监控系统提供了一个非常好的解决方案,其主要具有以下几个特点:
1) 数据采集端可以直接安装在Android移动终端上,不需要专用设备,可以很好地利用家中的平板电脑、手机等设备,做到灵活使用,一机多用。
2) 支持语音识别功能,能够在数据采集端与用户APP端进行消息互动,可根据需要开关监控设备。
3) 采用RTMP协议进行音视频传输,Red5作为流媒体服务器,支持高清视频,能够动态设置是否在服务器上保存音视频数据。
1 总体方案设计
监控系统主要是由数据采集端、云端服务器和手机APP组成。数据采集端主要负责音视频数据的采集和语音指令的识别处理;云端服务器则负责音视频流媒体的传输、各种控制指令的解析和转发;手机APP负责UI展示、消息接收、音视频的解码播放等功能[2-3],其总体框架如图1所示。

图1 智能监控系统总体框架图
在数据采集端用户通过语音与设备进行交互,设备检测到人的声音后会进行识别处理,然后执行相应的指令,采集端可以是手机、平板电脑等Android设备,通过连接路由器的Wi-Fi热点或4G网络等接入Internet,然后与服务器进行通信。手机APP通过网络获取服务器中的音视频和各种指令数据,同时也可以发送指令到服务器上,进而转发到对应的采集端。
2 系统软件设计
监控系统的数据采集端和手机APP均采用Android系统开发,云端服务器采用Red5作为流媒体服务器,业务逻辑服务器使用Apache MINA网络应用框架。
2.1 数据采集端
数据采集端是监控系统的核心模块,主要包括指令识别以及音视频的采集和推送功能。指令识别包括文本指令和语音指令。文本指令主要是指用户通过手机APP发送过来的操作指令。语音指令一般为采集端通过麦克风获取到的语音,然后转换成对应的文本指令,其功能主要分为:针对采集端的内部指令和针对用户APP的用户指令。如果是内部指令如打开、关闭摄像头等,则采集终端会执行相应的动作;如果是外部指令则发送给服务器,进而转发到APP端由用户进行处理。本系统语音指令采用百度语音识别技术,其具有识别率高、基础服务免费、接入流程简单等优势。采集端指令识别的工作流程如图2所示。

图2 指令识别处理流程
采集终端上电启动后,会检查是否有接收到用户的文本指令,如果有则首先执行文本指令,如果没有则初始化语音识别服务,等待唤醒。当检测到特定的唤醒词后,开启指令识别功能,然后判断指令是内部指令还是针对用户的外部指令,如果是内部指令则直接执行,否则就发送到服务器,进而转发给相应的用户APP端。
音视频的采集主要是获取麦克风和摄像头的音视频数据,使用H.264进行编码,然后对其进行RTMP协议封装,最终发送到Red5流媒体服务器。在Android系统上Mediacodec类封装了H.264的各种硬编解码功能,它是Android在4.1中加入的API,是一种低级别的API,可以非常方便地访问设备的媒体编解码器,因此系统采用Mediacodec将音视频编码为H.264格式。音视频传输采用RTMP(Real Time Messaging Protocol) 即实时消息传输协议,它是Adobe公司开发的为Flash播放器和服务器之间进行音视频传输的一种开发协议,其运行在TCP协议之上,能够支持点播、直播功能,并且具有低延迟的特点,其在视频监控领域被广泛使用。
2.2 云端服务器
云端服务器包含业务逻辑服务器和流媒体服务器。业务逻辑服务器主要负责处理用户的注册登录、设备的上线、指令消息的转发、消息推送等功能。流媒体服务器主要是进行音视频的保存和转发。
业务逻辑服务器采用Apache MINA框架[4],它是一种帮助用户开发高性能和高稳定性的网络应用框架,支持TCP和UDP传输,具有异步的、非阻塞的、事件驱动的API,同时还支持Java NIO特性,能够非常方便地扩展各种功能的数据过滤特性,在整个网络通信中能够与应用程序互相隔离开来,客户端和服务器只需要处理相应的业务逻辑即可。
流媒体服务器使用Red5[5-6],其为Java 语言开发、开放源代码的Flash流媒体服务器,与Macromedia公司的Flash媒体服务器兼容,支持Linux、MacOS、Windows平台。它的设计比较灵活,采用了插件的方式,可以非常方便的集成,能够对FLV、MP3文件进行流化,目前已经有成千上万的公司开始使用RED5,包括亚马逊和Facebook等。在本系统中数据采集端和用户APP监控端与云端服务器的交互流程如图3所示。

图3 采集端、APP和服务端通信框架图
数据采集端设备启动后会通过业务逻辑服务器进行设备的上线注册,获取流媒体的RTMP地址和消息的发送与接收,然后打开摄像头推送视频流到流媒体服务器。手机APP用户登录后,可以绑定采集端设备并获取设备信息,如设备ID、RTMP地址等,从而可以向流媒体服务器获取视频流数据,同理也可以与业务服务器进行消息的发送与接收。
2.3 用户APP端
用户APP监控端的主要功能为实现用户注册登录、获取设备信息、查看数据采集端设备发送过来的监控视频等功能[7]。其操作流程如图4所示。
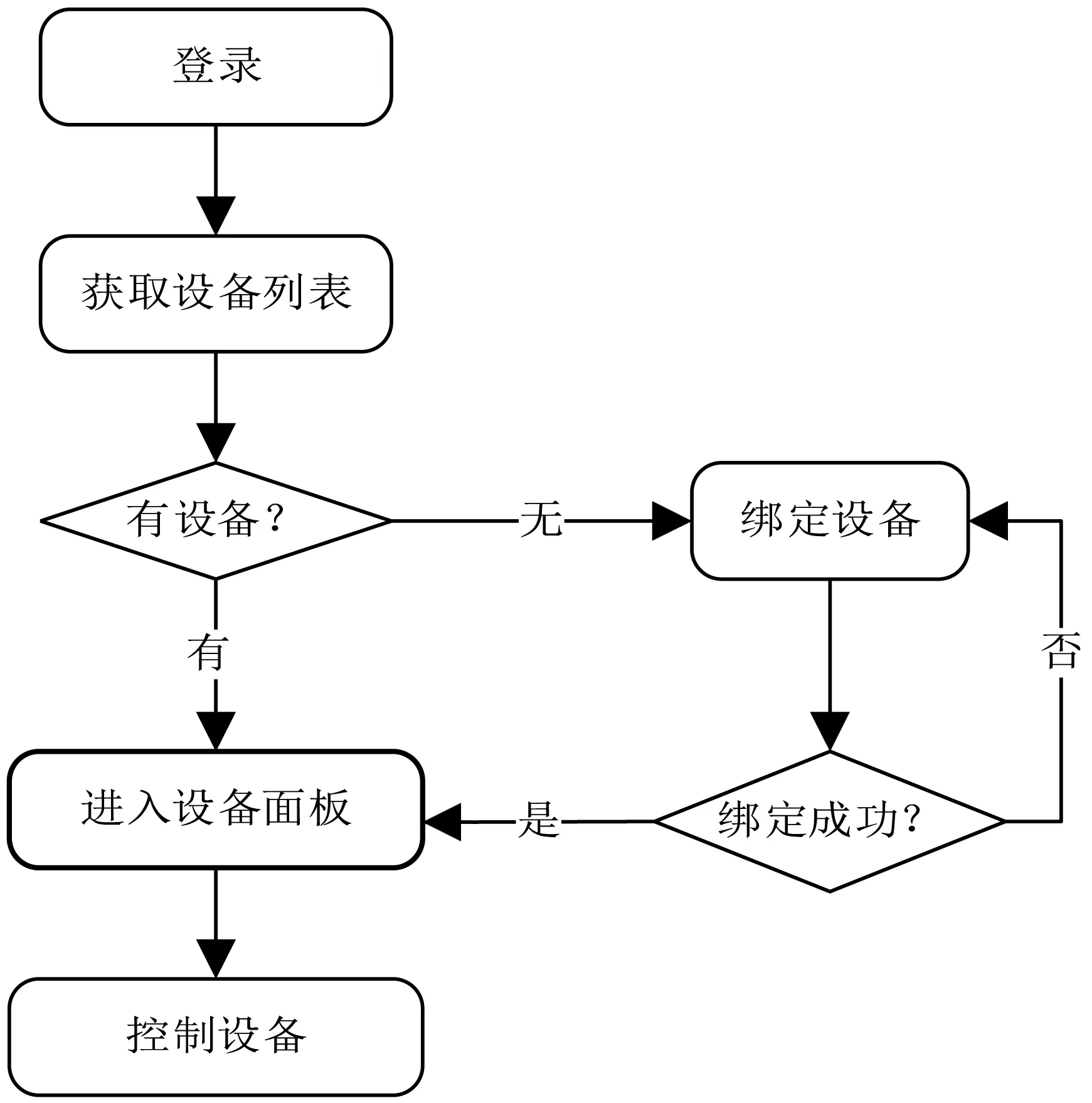
图4 用户APP处理流程
用户注册登录后会从服务器同步绑定的各种设备并展示在主界面上,如果没有获取到设备,则进入绑定设备列表进行绑定,绑定成功后会显示设备图标及名称,点击设备图标会启动一个新的Activity进入到设备的控制面板,从而可以执行针对设备的各种控制操作。图5为注册登录及设备控制面板界面。

图5 用户APP登录及设备控制面板
在设备的控制面板可以查看从数据采集端接收到的各种指令消息,点击“查看监控画面”即可打开流媒体播放器,播放采集端传输过来的音视频数据。
3 技术难点及解决方案
系统中语音的正确识别、解析、转发和执行是体现系统灵活性的关键。数据采集端将获取的音视频数据进行编码封装并发送到流媒体服务器,以及如何在手机APP上进行播放给系统的实现带来了挑战。
3.1 语音识别功能
语音识别功能主要是通过对语音信号进行采集、特征提取、模式匹配等技术将其转换为相应的文本消息,然后采用自然语言处理技术对文本消息进行语义解析[8-9],最终转换成能够被机器识别和理解的文本指令。系统中采用百度语音SDK进行开发,它集成了语音采集、语音预处理等功能,并且支持离在线融合技术,能够根据网络自动判断使用本地引擎还是云端引擎。其采用的自然语言处理技术支持三十多个领域的语义理解,可以满足大部分的语音交互场景,目前的识别准确率可以达到97%以上。数据采集端通过语音SDK获取文本指令,然后根据其内容进行内部处理或者通过网络发送到服务器进而推送到用户APP端,同时用户APP端也可以发送控制指令到服务器,然后推送到对应的采集端设备,达到了双向通信功能。其内部实现流程如图6所示。

图6 APP与数据采集端通信
服务器收到用户APP端和数据采集端的指令后,都需要对指令进行解析、重组,并将信息同步到MySQL数据库中进行保存记录,然后再发送给对应的接收方。
3.2 音视频采集及播放
系统的音视频编码器分别采用AAC和H.264格式进行编码。AAC是针对音频数据而设计的一种压缩格式,其具有非常高效的编码算法,支持多声道,具有很高的数据压缩比,在网络传输中应用非常普遍。H.264是MPEG4之后开发的新一代数字视频压缩算法,具有码率低,支持高质量的图像数据,并且具有非常好的网络适应能力和纠错恢复功能,同时在大多数Android系统上能够通过MediaCodec进行硬编码。
在Android系统上音频数据通过调用AudioRecord进行采集,采样率使用44.1 kHz,音频格式使用ENCODING_PCM_16BIT,音频通道使用CHANNEL_CONFIGURATION_STEREO。在录音之前首先调用new AudioRecord初始化AudioRecord。然后新建一个AudioRecordThread线程,在此线程中开启录音操作,然后把录取的音频数据发送到回调函数onRecvAudioData中进行编码处理,核心代码如下:
//初始化AudioRecord
mAudioRecord=new
AudioRecord(MediaRecorder.AudioSource.MIC,sampleRate,audioChannel,audioFormat, buffsize);
//开启录音线程进行录音
AudioRecordThread=new Thread(new Runnable() {
public void run() {
//开始录音
mAudioRecord.startRecording();
audioData, 0, dataSize);
//获取audioData音频数据
……
//编码音频数据
onRecvAudioData(audioData)
}
});
视频数据的采集通过调用Camera接口的回调函数onPreviewFrame获取,其部分实现代码如下:
Public Camera.PreviewCallback
getPreviewCallback() {
return new Camera.PreviewCallback() {
public void onPreviewFrame(final byte[] data, final Camera camera) {
//data为摄像头图像数据
}
};
}
RTMP协议主要用来在FLV(Flash Video)和服务器之间进行音视频通信[10],因此编码后的音视频数据需要封装成FLV可以识别的数据格式。FLV格式分为Header和Body二部分,而Body则由一个个Tag组成,所以在发送数据时需要先发送Header。以下为RTMP初始化的部分代码。
rtmp=RTMP_Alloc();
//分配RTMP实例
RTMP_Init(rtmp);
//进行RTMP初始化
//设置RTMP连接超时时间
rtmp->Link.timeout=timeOut;
//设置RTMP的URL
RTMP_SetupURL(rtmp,(char*)url.c_str());
//使能写功能
RTMP_EnableWrite(rtmp);
//开始连接RTMP服务器
if (!RTMP_Connect(rtmp, NULL)) {
return -1;
}
//连接RTMP流
if (!RTMP_ConnectStream(rtmp, 0)) {
LOGI(″RTMP_ConnectStream error″);
return -1;
}
由于RTMP的流媒体服务器不对音视频数据进行解码和播放,在发送数据之前,需要将音视频的编码信息发送到流媒体服务器,因此首先需要获取音视频的编码参数。而编码参数SPS(序列参数集)、PPS(图像参数集)正好包含在MediaCodec编码后的前二帧视频数据中,同时也是FLV视频中Body数据的首个Tag,因此调用pushSpsPpsData函数先提取SPS和PPS进行发送。同理对于AAC音频数据通过调用pushAudioInfo函数发送其编码信息到流媒体服务器。最终都是调用RTMP_SendPacket(RTMP*r,RTMPPacket*packet,int queue)函数进行发送,其内部基于TCP协议进行实现。
在本监控系统中,用户可以根据需要选择是否在流媒体服务器上保存数据,因此在设备采集端RTMP初始化时可以选择live、record、append三种模式,其中live模式为不保存数据,record模式为保存数据,append为追加模式保存数据。如设置live模式则设置对应的标志位rtmp->Link.lFlags |=0x40; record模式为0x80,append为0x100。
在用户APP端视频的播放采用Google开源的ExoPlayer播放器,其能够支持HTTP动态自适应流,能够非常方便地自定义设计和扩展。整个音视频的采集播放流程如图7所示。

图7 音视频采集播放流程
4 系统测试及结果
系统的测试中,云端服务器采用阿里云的Linux平台服务器,配置为CPU 1核,内存1 GB,网络为1 Mbps,数据采集端和用户APP端分别在Wi-Fi和4G网络的情况下,发送音视频可以非常流畅的显示,其数据采集端和用户APP端的监控画面显示如图8所示,左边手机为采集端,通过摄像头获取音视频数据,右边手机为用户APP端,正常获取到了采集端的音视频。

图8 采集端(左)和APP端(右)
5 结 语
随着移动互联网、人工智能技术的发展,语音识别、图像分析技术变得越来越成熟,这些技术引入到视频监控领域会大大增强监控系统的功能。通过增加语音识别功能,改变了传统监控系统只能单方面通信的功能,而引入云端服务器、用户监控端可以让用户随时随地查看监控系统,增加了监控系统的可用性,提供了一个非常有效的解决方案。
