轨道交通线网大数据的建模和存储方案
2018-12-13陈莉莉张赛桥
陈莉莉 张赛桥 胡 波
(南瑞集团(国网电力科学研究院)有限公司 江苏 南京 210032)
0 引 言
随着城市轨道交通建设的加快,各个城市的地铁线路逐渐向线网化发展,轨道交通的线网数据类型越来越多,数据量也越来越大,海量的数据汇集到轨道交通指挥中心。在轨道交通领域,如何有效地收集、整理、存储、处理和分析这些结构化和非结构化数据,进行深度的数据挖掘和数据分析,挖掘其中有价值的信息,从而提高轨道交通的运营水平,提升科学决策、信息服务和安全保障能力,增加效益降低成本,已日益成为业界关注的重点。
目前轨道交通指挥中心的已有数据仓库建设案例还比较少,而且都采用MPP架构的数据仓库进行结构化数据存储。但是随着数据量的增大和数据类型的增多,MPP的价格高昂、扩展成本太高、不能存储非结构化数据、不能进行流处理的弱点暴露出来。Hadoop平台有着不同于MPP的架构和数据处理方式,它的结构更灵活,存储的数据量级更大,支持高并发和实时处理,易于扩展,而且实现成本相对较低。但是Hadoop的数据存储中没有索引,底层数据块比MPP大很多,所以数据精准查询、表与表相组合查询的速度比MPP要慢。以往在轨道交通线网中心的MPP数仓,采用比较多的是基于三范式建模的数据建模方法。Hadoop平台的特点是相对廉价,适合做批量数据查询,但少量精准查询和复杂的多表联合查询效率低,所以三范式建模不能照搬到Hadoop平台。因此要针对Hadoop平台的特点,选用合适的组件,对轨道交通的线网大数据中的结构化数据,设计以维度建模为主的数据建模方法,规避Hadoop平台的缺点并最大限度发挥其优点,从而实现线网大数据的安全和高效的存储和访问。针对此特点,星形模型得到了比较多的应用。
对于以往的轨道交通指挥中心的非结构化数据,比如视频、图像、语音、日志文件、页面抓取等,都采用磁盘阵列,只实现存储备份功能,无法实现全文检索以至于进一步的分析。在轨道交通运营中,需要分析非结构化数据,即进行数据的内容检索和处理,本文引入了Hadoop平台取代磁盘阵列的存储模式。
本文描述了一种轨道交通指挥中心的海量线网大数据的数据建模和存储方法,实现高效的轨道交通指挥中心的线网大数据的数据存储和即席检索,以及进一步的数据挖掘和数据分析,进而指导轨道交通运营的功能。
1 结构化数据模型
如图1所示,线网指挥平台把从数据源采集的结构化数据,其中大部分为时序数据,先作为临时数据存入HBase;再经过数据清洗转换,存入基础数据区;公共层数据存在Hive里;面向应用的数据集市层,比如指标分析、客流分析、设备维护等,存在Hive里。
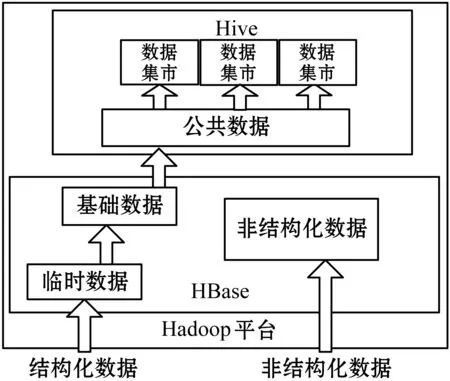
图1 线网大数据的数据组织和存储结构
在数据的概念建模阶段,Hadoop和MPP并没有不同。从线网数据中抽象出来的主题和关联方式都相似。我们列出轨道交通的各个主题:路网、设备、行车、票务、渠道、事件、OD、当事人等。
1.1 HBase的RowKey组织型式
把轨道交通各个线路采集来的各个子系统的结构化的时序数据,汇集到线网指挥中心的大数据平台,平台采用Hadoop架构。对输入数据以小文件的方式组织起来,采用Avro格式存入HBase中的临时数据区。
临时数据区的小文件是不同的线路集成商送上来的每条线路的数据。先要对临时数据进行格式规整,以统一格式存入历史数据区。对历史数据,参照它的具体应用,采用范式建模的方法,以近源的格式存储到HBase中。
线网大数据中的结构化数据有两类:一类是设备点变化的时序数据,另一类是客流进出站的OD时序数据。
对于设备点变化的时序数据,HBase的RowKey以输入数据点的全线网唯一性索引和该数据点的数据变化时间组合而成。对于前者是以字符串作为关键字建模,RowKey的组织形式为:

线路车站应用设备点类型点变化时间
前面6个区拼成的字符串是每个数据点的索引值,最后一个区是点变化时间。这样的分级组成方式,易于理解又实现了全线网的统一,方便进行数据扩展和新线接入。而且变化时间在长期上会呈现均匀分布的形式,容易实现把数据平均分布存储于不同的数据节点,保证各数据节点间的压力平衡。
轨道交通指挥中心的指标分析中有大量的对点的一段时间内变化进行批量读入的需求,这种存储格式可以一次性读入时间序列在一段时间内的变化数据,实现高效的数据访问。
类似的情况,对于客流进出站的OD时序数据,RowKey的组织形式为:

卡号进出站时间
1.2 Hive建表型式
历史数据经过数据治理后,根据轨道交通指挥中心的具体数据应用,设计各自的数据集市,这些数据集市的表存储到Hive中。对这些数据集市提炼出共同的通用数据作为中间层,这些数据也存入Hive中。Hive中表的数据模型按照Hadoop本身的特点设计,采用维度建模方法设计,对数据进行降范式处理;在线网中,把原有线路数据模型中分小表存储的不同的属性的数据,根据具体需求整合到一张大表中重复存储,以增大数据存储空间换取有效缩短读取时间。采取的方法有:
1) 对于ISCS数据,把线路中以点为中心的建表方式改为线网中以设备为中心的建表方式,即把每个设备的所有点都集中存在一张表里。
2) 对于客流数据,把OD和相关列车运行时刻表组合存储为一张表。
3) 对于行车数据,把列车实际运行图和计划运行图、司机信息、列车状态信息、满载率等相关信息组合存储为一张表。
2 结构化数据实施方案
轨道交通各线路采集的各子系统的采样数据,其实是一种结构化的时序数据,汇集到线网指挥中心的大数据平台。图2中,线网指挥中心的Hadoop平台通过Kafka总线获取线路端的数据,作为实时流处理的输入,通过Spark Streaming在线处理后,直接输出到展示平台。
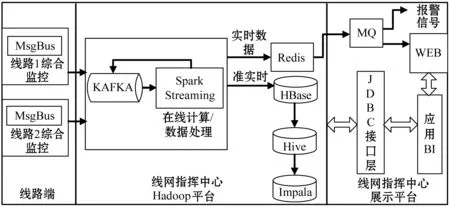
图2 Hadoop平台的流处理方案
对于输入的数据,可以分为以FTP方式上传的批量数据,或从Kafka总线接收实时流数据,实时流数据经过整理后和FTP方式上传的数据存入临时数据区。每一条时序数据用Json串的方式存储每个数据点的索引、变化时间、值和状态,一段时间内的数据变化组成一个文件。输入数据以小文件的组织方式存入HBase中的临时数据区。
临时数据区存储的数据来源是城市轨道交通的不同线路,而线路集成商不相同造成数据格式的不同。因此首先要对这些数据进行格式规整,再存入基础数据区长期保存。HBase的RowKey以输入数据点的线网唯一性索引和数据变化时间的组合。各个输入点是以字符串作为关键字的线网级统一的数据模型,比如:南京三号线浮桥站BAS应用的1号风机,它的转速是个数字量类型的点,在2017年7月18日12∶35∶55的236 ms这个时间发生了一次变化,于是RowKey就记为:
njl3.fq.bas.fj1.dig.zs#20170718123555236。
这样的存储方式充分考虑线网数据的扩展性,支持线网全数据接入。
经过数据治理后的历史数据,针对轨道交通指挥中心的数据应用,对每个应用设计各自的数据集市,存储到Hive中。再提取出每个数据集市的通用数据,建表存入Hive中。
按照Hadoop本身的特点设计存储表,对数据进行降范式处理,采用大宽表的方法,避免表与表之间的Join操作。通常一个设备有几十个采集点,将这些不同数据点聚合到一张大表中存储,每个点的不同属性以结构体的方式组织到大表中。对客流数据的OD分析的中间结果,每一张地铁卡对应卡号为索引的进出站记录,以及和列车时刻表结合时计算出的这位乘客于某个时间从某个闸机进入某站,然后于某个时间乘某趟列车,在某个换乘站转车,转了几次车后到达终点站,到达时间,从某个闸机出站,上述所有的信息,都聚合成一条记录存储。
比如,图3的BAS专业的废水泵设备,表征这个设备属性状态的有一系列数字量和模拟量点。这些点在MPP的点表里逐行存储,在Hadoop里把它合并进一张设备表里。

图3 设备和点的对应关系
数据存入Hive,可以利用Impala和Solr等组件,采用NOSQL技术,加快对数据的访问。
3 非结构化数据存储
针对轨道交通指挥中心的大量非结构化数据,其类型大致有视频、音频、图片、档案文件、日志文件、网页抓取等。轨道交通领域的这些文件都不太大,即便是视频文件,由于轨道交通指挥中心建设有线网CCTV中心存储视频,线网指挥中心的视频都是小段,文件基本上均小于100 MB,因此,都可以存储到HBase中,并在HBase中另外建表存储元数据,实现对非结构化数据的进一步检索和内容分析。
这些非结构化数据和文件存储,操作瓶颈不在CPU,而在磁盘IO和内存,所以采用Snappy技术做文件压缩,以CPU运算减少内存和磁盘IO操作。
由于文件数量多,所以存储的分区目录组织方式为文件来源应用,分为五类:历史档案、应急指挥、系统日志、报表、网络抓取内容,如表1所示。按照具体应用分类,对后四种每半年为一期实现文件归档,用于对非结构化数据的进一步检索和内容分析。

表1 非结构化数据分类方法
4 结 语
数据中心是线网指挥中心的重要组成部分,有效利用线网中生成的海量数据,提高轨道交通的运营管理水平,帮助地铁企业充分发掘潜在的数据价值,是线网指挥中心的重要功能。
Hadoop平台具有廉价、灵活、易扩展等特点,将在线网数据中心得到广泛应用。本文将Hadoop平台应用于轨道交通线网数据中心,在数据建模和数据存储方面的独特之处做了介绍。概括说来就是时序数据的标准化,以及以维度建模为主,采用空间换时间的方法,用宽表和冗余存储方法来获得高效的数据查询和数据分析结果。本文描述的建模和存储方法,在实际搭建轨道交通大数据中心平台的验证过程中,满足了实时性和大批量存储的要求,取得了令人满意的效果。
