实体—属性抽取的GRU+CRF方法
2018-12-08王仁武孟现茹孔琦
王仁武 孟现茹 孔琦

〔摘 要〕[目的/意义]研究利用深度学习的循环神经网络GRU结合条件随机场CRF对标注的中文文本序列进行预测,来抽取在线评论文本中的实体—属性。[方法/过程]首先根据设计好的文本序列标注规范,对评论语料分词后进行实体及其属性的命名实体标注,得到单词序列、词性序列和标注序列;然后将单词序列、词性序列转为分布式词向量表示并用于GRU循环神经网络的输入;最后输出层采用条件随机场CRF,输出标签即是实体或属性。[结果/结论]实验结果表明,本文的方法将实体—属性抽取简化为命名实体标注,并利用深度学习的GRU捕获输入数据的上下文语义以及条件随机场CRF获取输出标签的前后关系,比传统的基于规则或一般的机器学习方法具有较大的应用优势。
〔关键词〕实体属性抽取;GRU;循环神经网络;条件随机场;命名实体识别
DOI:10.3969/j.issn.1008-0821.2018.10.009
〔中图分类号〕TP391.1 〔文献标识码〕A 〔文章编号〕1008-0821(2018)10-0057-08
〔Abstract〕[Purpose/Significance]The study used the recurrent neural network GRU combined conditional random field CRF to predict the annotated Chinese sequence text to extract the entity-attribute in the online review text.[Method/Process]Firstly,according to the designed annotation specification to a text sequence,the paper made name entity annotations for entities and their attributes after the segmentation of corpus,and got word sequence,part of speech sequence and annotation sequence;Then the word sequence and part-of-speech sequence were converted into distributed word vector representation and used for input of GRU recurrent neural network;finally,the output layer used the conditional random field CRF and the output label was the entity or attribute.[Result/Conclusion]The method in this paper simplified entity-attribute extraction to named entity annotation,and used GRU to capture the contextual semantics of input data and conditional random field CRF to obtain the output label context,which had a larger application advantage than the traditional rule based or general machine learning method.
〔Key words〕entity attribute extraction;GRU;RNN;CRF;NER
实体—属性抽取是从非结构的文本数据中抽取有价值的语义单元的重要手段,是信息抽取、觀点挖掘、智能检索、自动问答、知识图谱等构建任务的基础。实体—属性抽取属于自动内容抽取(Automatic Content Extraction,ACE)的研究范畴。美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)组织开展了系列ACE测评会议。ACE会议旨在研究自动抽取出新闻语料中的实体、关系以及事件等内容[1]。ACE的目标是发展包括自动识别和标识文本在内的自动内容抽取技术,以支持对语料库的自动处理[2]。
本文研究的实体是文本中描述的对象,或者说是文本中包含的特定事实信息,例如产品评论中的产品、服务、商家等。与此对应,属性是描述产品或服务的特定属性的特征,例如,属性的一些示例是品牌、颜色、材料、包装、价格、质量等。属性值是赋予属性的特定值。涉及到实体的研究,使用比较多的方法是命名实体识别。在命名实体识别研究中,MUC-6[3]中命名实体类型分为3大类(实体类、时间类和数字类)和7小类(机构名、地名、人名、日期、时间、百分比和货币)。随着研究的深入和社会的发展,一些新的实体类型逐渐成为研究热点,例如医学生物信息、商业信息等。在大数据时代,我们生活中绝大多数的数据都是非结构的文本数据,我们已淹没在非结构化数据的海洋之中。实体识别与实体—属性抽取已经成为非结构化文本理解的一个重要手段。
在本文研究中,我们充分利用循环神经网络捕捉文本上下文语义的能力来抽取文本中的实体与属性。首先利用命名实体标注的方法来标注文本中的实体与属性形成实验语料,然后利用循环神经网络(本文使用GRU)来训练标注好的语料,网络输出层使用条件随机场(CRF),好处是在输出时也能利用标注标签之间的先后关系,提高输出的准确率。本文方法的思路来源于深度学习强大的无监督自主学习的能力,避免了传统机器学习比较耗时且复杂的特征工程。实验表明,本文的实体—属性抽取方法,利用GRU+CRF,可以取得较好的效果。
本文余下部分的结构安排:第1部分相关的研究工作情况;第2部分模型框架;第3部分语料标注;第4部分实验与分析评估;第5部分总结与展望。
1 相關研究
自20世纪80年代开始召开的信息理解会议MUC(Message Understanding Conferences)和自动内容抽取ACE评测会议等多个信息抽取领域的会议极大地推动了信息抽取技术的发展。本世纪ACE评测已经举办了八届,经过多年发展,当前对信息的提取已经有一些研究成果[4],信息抽取的研究方法主要有以下两种:模式匹配方法和机器学习方法。基于模式匹配的方法对知识的表达比较直观、自然,类似于规则,更接近人的思维方式。模式匹配多是面向领域的,准确率较高;基于机器学习方法灵活性较好,不需要太多的背景知识,但是它需要大规模的语料库支持以及手工标注。
在基于机器学习的实体属性抽取方面,Liu H等[5]利用属性值信息和最大熵模型构造属性与标签之间的映射关系,并对实体实例进行标注,然后,将隐马尔可夫模型应用于相关实体属性提取。Li C X等[6]则提出了一种基于实体属性分类的Web实体抽取方法,使用Libsvm分类器对物品的实体与属性进行分类抽取。曾道建等[7]将属性抽取看作是一个序列标注问题,利用百度百科信息框已有的结构化内容来自动产生训练数据,然后使用条件随机场(CRF)作为分类器来从非结构化文本中抽取属性。刘倩等[8]在实体属性抽取的进一步研究中提出了利用全局信息构造神经网络感知器模型来抽取实体属性,整体效果优于传统的CRF。
近年来,随着深度学习在图像领域应用的成功,不少学者开始关注深度学习在信息抽取方面的应用。Zhong B等[9]通过构造深度信念网(Deep Belief Network)来进行实体属性抽取。苏丰龙等[10]将深度学习框架的词语嵌入表示方法(Word Embedding)引入到领域实体属性抽取研究中,方法是采用词的聚类方法,在无监督条件下解决大规模语料、领域实体属性词表人工参与构建代价较高的问题。Gridach M等人[11]使用循环神经网络GRU结合CRF进行了推特文本中的法文文本的命名实体识别,而Huang Z等人[12]则研究利用循环神经网络BiLSTM结合CRF对英文语料CoNLL2000、CoNLL2003文进行NER,都取得了较好的效果。
由于传统的机器学习其分类算法的数据来自有限数据集合L=(X,y),其中X为输入样本并以二维数组形式给出,形状为n_samples×m_features,即n个样本,m个特征;输出值以数组y的形式给出,并以y中的Symbolic(符号)值表示。传统的机器学习的质量严重受制于X数据的获得与处理,需要繁琐的特征工程(即m_features的获得过程)来进行处理,它主要依靠设计者的先验知识,很难利用大数据的优势,而且还不一定能取得好的效果。而深度学习与传统机器学习方法最大不同之处在于它能从数据中自动学习特征。例如,传统的图像分类,要识别图片中的猫,需要设计好的特征,给出猫的胡须、耳朵、眼睛等特征,而深度学习,只需标注图片是否是猫即可,剩下的工作,交给神经网络去调节联结权重,通过输入数据(图片)与调节后权重的矢量乘积的激活,产生是否是猫的预测。
本文在前人研究的基础上,利用Keras[13]的深度学习框架,设计构造了双向GRU[14]循环神经网络,在输出层使用CRF[15],对序列标注的中文在线评论文本进行实体属性抽取。本文的方法将传统的大量依赖映射词表与规则的比较繁琐的实体属性抽取,简化为文本序列标注。充分利用了深度神经网络双向GRU综合学习利用语料上下文的语义关系,以及利用条件随机场CRF在序列标签上的预测能力,提高模型的预测输出效果。尽管语料标注需要一定的工作量,但标注工作本身简单易行,具有较大的应用优势。
2 模型框架
本文使用循环神经网络GRU(输出层使用CRF)对输入的经过人工标注的中文在线评论文本序列进行学习(文本标注的相关内容见第4部分)。
2.1 GRU模型
GRU全称是Gated Recurrent Unit,即门限循环单元,是循环神经网络(RNN[16])的一种。我们知道卷积神经网络(CNN[17])擅长处理空间信息,例如图像,而RNN则擅长处理时间信息,例如语音、文本序列等。GRU则是对RNN存在的比较严重的梯度消失或梯度爆炸问题的改进。
RNN的“梯度消失”是指,如果梯度较小(<1),多层迭代以后,指数相乘,梯度很快就会下降到对调参几乎没有影响(设想一下,0.9的n次方,当n足够大时,值将很小)。“梯度爆炸”则反过来,如果梯度较大(>1),多层迭代以后,又导致了梯度很大(设想一下,1.1的n次方,当n足够大时,值将很大)。尽管在理论上,RNN能够捕获长距离依赖性,但实际上,它们由于梯度消失/爆炸问题而失败[18]。GRU等是RNN的优化,能够解决RNN在梯度上面临的问题。
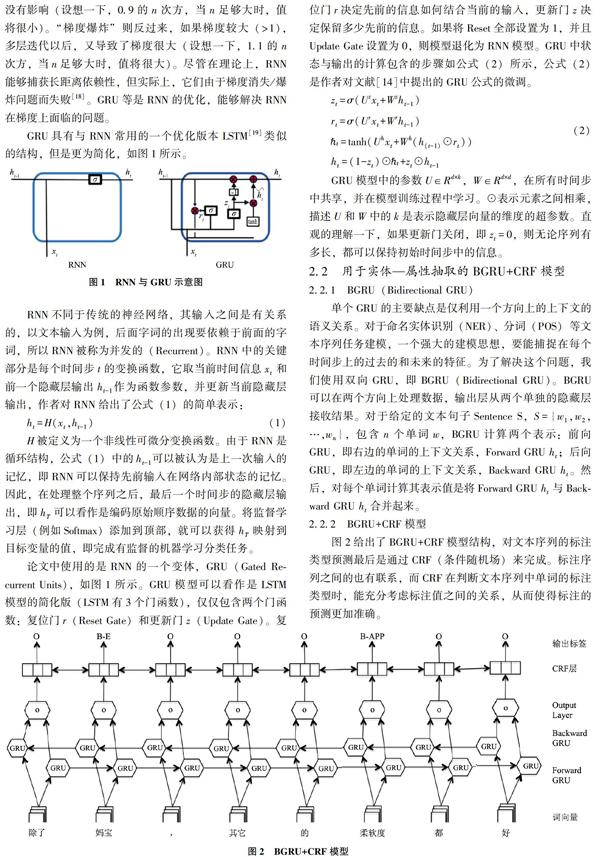
GRU具有与RNN常用的一个优化版本LSTM[19]类似的结构,但是更为简化,如图1所示。
GRU模型中的参数U∈Rd×k,W∈Rd×d,在所有时间步中共享,并在模型训练过程中学习。⊙表示元素之间相乘,描述U和W中的k是表示隐藏层向量的维度的超参数。直观的理解一下,如果更新门关闭,即zt=0,则无论序列有多长,都可以保持初始时间步中的信息。
2.2 用于实体—属性抽取的BGRU+CRF模型
2.2.1 BGRU(Bidirectional GRU)
单个GRU的主要缺点是仅利用一个方向上的上下文的语义关系。对于命名实体识别(NER)、分词(POS)等文本序列任务建模,一个强大的建模思想,要能捕捉在每个时间步上的过去的和未来的特征。为了解决这个问题,我们使用双向GRU,即BGRU(Bidirectional GRU)。BGRU可以在两个方向上处理数据,输出层从两个单独的隐藏层接收结果。对于给定的文本句子Sentence S,S={w1,w2,…,wn},包含n个单词w,BGRU计算两个表示:前向GRU,即右边的单词的上下文关系,Forward GRU ht;后向GRU,即左边的单词的上下文关系,Backward GRU ht。然后,对每个单词计算其表示值是将Forward GRU ht与Backward GRU ht合并起来。
2.2.2 BGRU+CRF模型
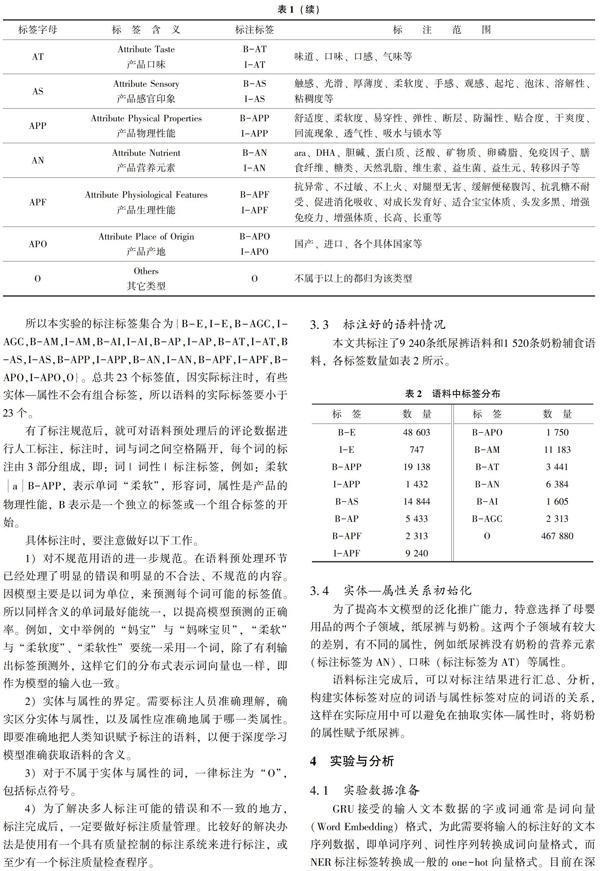
图2给出了BGRU+CRF模型结构,对文本序列的标注类型预测最后是通过CRF(条件随机场)来完成。标注序列之间的也有联系,而CRF在判断文本序列中单词的标注类型时,能充分考虑标注值之间的关系,从而使得标注的预测更加准确。
BGRU+CRF模型说明:
1)模型的第一层是输入层,输入句子中的单词的词向量,处理过程一般是:
①例如,对纸尿裤的原始语料,对妈咪宝贝纸尿裤的一条评论语句分词后为[“除了”,“妈宝”,“,”,“其它”,“的”,“柔软度”,“都”,“好”],进一步可得到每个单词的one-hot向量,维数是字典大小(由实验语料中所有词构成)。one-hot向量的含义是一个向量中只有一个值是1(热值,hot value),其它都是0。
②利用预编译的或随机初始化的词向量(Word Embedding)矩阵将句子中的每个词由one-hot向量映射为低维稠密的词向量(Word Embedding),Embedding的维度可以自行设置,对中文来说可选择100维、200维等。
③设置Dropout去除输入数据的某些维度以缓解过拟合。
2)模型的第二层是BGRU层,其处理过程:
①将一个句子的各个词的词向量序列作为BGRU各个时间步的输入。
②输出前向Forward GRU的隐状态序列。
③输出后向Backward GRU的隐状态序列。
④将前向与后向GRU输出的隐状态序列在各个位置输出的隐状态进行按位置拼接得到完整的隐状态序列。
⑤设置Dropout去除输入数据的某些维度以缓解过拟合。
⑥将隐状态向量从m维映射到k维,k是标注集的标签数,得到自动提取的句子特征。
⑦为单词分类到k个标签计算打分值。
3)模型的第三层是CRF层
CRF层完成序列标注的标签预测,CRF层由连接连续输出层的行表示。CRF层将BGRU输出的状态转换矩阵作为参数,有了该层,我们可以有效地使用标注标签之间的关系来预测当前标签。
3 语料序列标注
3.1 在線评论语料获取与处理
本项目研究以淘宝网主题市场下的“童装玩具/孕产/用品”主题的“孕产”用品中的纸尿裤,以及奶粉辅食的在线评论数据作为研究语料来源。利用Python语言编程采集了花王、帮宝适、好奇、妈咪宝贝等纸尿裤及爱他美、羊奶粉、惠氏、雅培等奶粉辅食近150个品种(作为实体)。评论数据从2017年1月至2018年12月,经过语料数据预处理,去除无效的评论,得到有效评论数据29 807条。语料预处理过程包括数据清洗、分词与词性标注。
数据清洗包括:1)删除不适合本文研究的图片和表情符号;2)删除与评论主题无关的评论;3)删除重复发帖的记录;4)删除店家回复的记录;5)删除淘宝系统自动评论,例如“评价方未及时做出评价,系统默认好评!”等。
分词的质量关键取决于词典,一般的分词软件都不带有领域的词典。所以要想提高特定领域的分词效果,则要先建立该领域用户词典。本项目是母婴用品中的纸尿裤和奶粉,应该先建立该领域词典,因本项目需要人工标注,所以开始并没有建立比较完整的领域词典,而是在标注过程中不断积累需要增加的领域词汇,为后面的模型应用建立领域词典做好积累。例如,在标注过程中,发现“妈咪宝贝”多数用户称作“妈宝”以及“防漏性”,也有些用户称作“防漏”,这些都需要加入领域词典。分词与词性标注需要分词软件,本文采用Python编程语言中的Jieba分词模块进行分词。
3.2 语料标注及质量管理
本项目使用Bakeoff-3[20]评测中所采用的BIO2标注集,即B-PER、I-PER代表人名首字、人名非首字,B-ORG、I-ORG代表组织机构名首字、组织机构名非首字等,O代表该字不属于命名实体的一部分。对母婴用品的各种实体类型,制定如表1的命名实体标注规则。本研究中,产品、服务、商家等文本中谈论的主要对象统称为实体,不做细分。例如,本项目研究的纸尿裤和奶粉的各个品牌,花王、妈咪宝贝、惠氏、雅培等都是实体,属性则是这些实体的某一方面的特征。
所以本实验的标注标签集合为{B-E,I-E,B-AGC,I-AGC,B-AM,I-AM,B-AI,I-AI,B-AP,I-AP,B-AT,I-AT,B-AS,I-AS,B-APP,I-APP,B-AN,I-AN,B-APF,I-APF,B-APO,I-APO,O}。总共23个标签值,因实际标注时,有些实体—属性不会有组合标签,所以语料的实际标签要小于23个。
有了标注规范后,就可对语料预处理后的评论数据进行人工标注,标注时,词与词之间空格隔开,每个词的标注由3部分组成,即:词|词性|标注标签,例如:柔软aB-APP,表示单词“柔软”,形容词,属性是产品的物理性能,B表示是一个独立的标签或一个组合标签的开始。
具体标注时,要注意做好以下工作。
1)对不规范用语的进一步规范。在语料预处理环节已经处理了明显的错误和明显的不合法、不规范的内容。因模型主要是以词为单位,来预测每个词可能的标签值。所以同样含义的单词最好能统一,以提高模型预测的正确率。例如,文中举例的“妈宝”与“妈咪宝贝”,“柔软”与“柔软度”、“柔软性”要统一采用一个词,除了有利输出标签预测外,这样它们的分布式表示词向量也一样,即作为模型的输入也一致。
2)实体与属性的界定。需要标注人员准确理解,确实区分实体与属性,以及属性应准确地属于哪一类属性。即要准确地把人类知识赋予标注的语料,以便于深度学习模型准确获取语料的含义。
3)对于不属于实体与属性的词,一律标注为“O”,包括标点符号。
4)为了解决多人标注可能的错误和不一致的地方,标注完成后,一定要做好标注质量管理。比较好的解决办法是使用有一个具有质量控制的标注系统来进行标注,或至少有一个标注质量检查程序。
3.3 标注好的语料情况
本文共标注了9 240条纸尿裤语料和1 520条奶粉辅食语料,各标签数量如表2所示。
3.4 实体—属性关系初始化
为了提高本文模型的泛化推广能力,特意选择了母婴用品的两个子领域,纸尿裤与奶粉。这两个子领域有较大的差别,有不同的属性,例如纸尿裤没有奶粉的营养元素(标注标签为AN)、口味(标注标签为AT)等属性。
语料标注完成后,可以对标注结果进行汇总、分析,构建实体标签对应的词语与属性标签对应的词语的关系,这样在实际应用中可以避免在抽取实体—属性时,将奶粉的属性赋予纸尿裤。
4 实验与分析
4.1 实验数据准备
GRU接受的输入文本数据的字或词通常是词向量(Word Embedding)格式,为此需要将输入的标注好的文本序列数据,即单词序列、词性序列转换成词向量格式,而NER标注标签转换成一般的one-hot向量格式。目前在深度学习应用中将单词转换成词向量表示,多用Google開源的Word2vec[21]工具。Google公司在2013年开源Word2vec后,目前已有一些基于词向量Word2vec的文本处理方面的研究[22]。
2)为评论单词、词性创建词向量,本实验采用的是300维的词向量。即一个单词或词性由一个300维的向量表示。为NER标签创建one-hot向量,要注意的是,在标注的标签集上,再加一个标签“PAD”对应索引值0,和一个标签“UNK”对应索引值最大值后的值。“PAD”一般用于序列长度不满足长度要求,在序列后填充该值直到符合要求的序列长度,“UNK”用于未知的内容。one-hot向量的含义是一个向量中只有一个值是1(热值,hot value),其它都是0。在机器学习中,对于多分类问题,one-hot是转换目标变量,即多分类标签值的通用方法。
4.2 模型构建与模型训练
我们使用Python编程,在深度学习框架Keras下,后端使用Tensorflow[23],电脑带有GPU的NVIDIA Geforce 940MX显卡,并配置好使用GPU功能。
我们在实验数据上实验了BGRU+CRF模型,作为对比也实验了机器学习中常用的支持向量机模型(SVM)[24],RNN的另一个优化版本LSTM[19](使用双向LSTM,即BiLSTM,采用Softmax激活函数作为输出)和单独的CRF模型(CRF是传统的文本序列标注预测最常用的模型)。4个模型构建与训练的参数设置如表3所示。
BGRU+CRF模型与单独的BGRU模型的参数设置基本相同,不同在于前者的最后一层是CRF(Keras-Contrib中带的CRF模块),而后者使用的是Softmax激活函数,每个词可能取15个标签之一(本实验实际用到了15个标签,用one-hot编码),取最大概率的值。实验使用的词向量是根据本实验的语料生成的,通过多次实验我们选择的词向量维度为300。窗口大小90表示使用的输入句子最大长度是90,即一条评论句子由90个单词构成(包括标点符号),不足部分用4.1中提到的“PAD”填充。实验中,对于BGRU+CRF模型,使用词性和没有使用词性也分别做了实验。
实验中单独的CRF模型使用的是Python支持的Pycrfsuite套件。输入数据是单词和词性的组合数据,为防止过拟合,设置了CRF的惩罚系数L1、L2。
4.3 实验评估与结果分析
以下用3个模型代表BGRU+CRF、单独的BGRU和单独的CRF。
4.3.1 3个模型算法的整体评估
考虑到序列标注的分类预测自身的特点,也即尽管其也是一个多分类问题,但在NER识别中,更关注的是有意义标签的分类的正确性,而不是所有分类标签的正确性。即在评估模型的精度(Precision)、召回率(Recall)和F1值(f1-score)时,不考虑标签O,只考虑标签B、I构成的标签的评估。3个模型的评估结果如表4所示。
通过实验我们看出,CRF模型确实体现了其在序列预测上的能力,单独CRF模型训练速度也较快,实验中同样的数据量,4秒不到就完成训练。BGRU+CRF比单独的CRF模型高几个百分点的原因是其在输入和输出时都利用了上下文关系,因此比较适合做文本的序列分析。单独的BGRU使用Softmax作为输出,只是在输入信息时利用GRU获取了上下文关系,而Softmax输出时,没有利用这些关系,所有评估值都较差。
对于BGRU+CRF模型,我们也对比实验了词性对实验结果的影响。理论上,在已知单词序列上,再增加一个已知词性序列,对求未知的标注序列的分类预测时应更有帮助。但实验结果却是无词性的比有词性的评估效果更好。我们检查了词性情况,发现分词软件在分词时,给单词的词性的质量上还是有问题,我们对比了几个软件,都还有待提高。
4.3.2 3个模型算法的分类评估
本实验中,我们用序列标注的标签值代表实体与属性。对实体与属性的相应标签值的分类实验预测结果分析如表5所示。表中的P值是Precision值。
实验结果表明,使用到CRF模型在实体与属性的标签分类预测上基本上都取得80%以上的评测结果,而且BGRU+CRF模型都要好于单独的CRF模型,同样的单独的BGRU表现都不好。通过对几个评测指标较高和较低的进一步分析,发现样本量对分类预测结果有较大影响,样本量的增加会提升标签分类预测的正确率。例如I-E评估指标较差,原因就是样本中含有组合标签I-E的数量远小于B-E的数量。
4.3.3 模型优化
众所周知,模型的质量取决于2个方面:训练数据的质量和模型算法的质量。对训练语料的质量控制在第4部分已经简单提及,这一块还有较大的提升空间。而影响模型算法质量的因素有很多种,在BGRU中主要是调参。实验中,主要根据表6来调参。我们尝试改变模型构建过程当中涉及到的变量和参数,以期寻找最佳的组合。
实验中,手工改变参数,通过多次实验,表3中的默认值是效果比较好的参数。
4.4 实体—属性确认
通过前面的实验,模型可以以比较高的准确率,抽取出在线评论中实体与属性。下面的任务是要确认每条评论中抽取出的实体与属性是否有对应关系。目前,本文采用的方法是用3.4初始化的实体—属性关系数据来保证实体与属性的对应关系,实际应用时,还需要一定的人工审核。后续的研究计划将利用深度学习自动确认实体—属性的对应关系。
5 总结与展望
本文提出了一种实体—属性的抽取方法,将传统的大量依赖映射词表与规则的比较繁琐实体属性抽取,简化为文本序列标注。然后利用深度神经网络BGRU综合学习利用语料上下文的语义关系,并有效地利用条件随机场(CRF)在序列标签上的预测能力,提高模型的输出效果。相比较单独的BGRU和單独的CRF模型,本文的方法在实体—属性的抽取上取得了较好的效果。
本文模型算法的评估指标还可以进一步提高,而且组合标签的预测准确率还比较低,下一步可考虑加大语料量,同时引入新的深度学习技术,例如迁移学习、注意力机制(Attention)等,探索不断提升实体—属性抽取的效果与质量,同时做好模型的相关应用推广。
参考文献
[1]Doddington G R,Mitchell A,Przybocki M A,et al.The Automatic Content Extraction(ACE)Program-Tasks,Data,and Evaluation[C]//LREC,2004,(2):1.
[2]赵琦,刘建华,冯浩然.从ACE会议看信息抽取技术的发展趋势[J].现代图书情报技术,2008,(3):18-23.
[3]Grishman R,Sundheim B.Message Understanding Conference-6:A Brief History[C]//Proceedings of the 16th Conference on Computational Linguistics-Volume 1.Association for Computational Linguistics,1996:466-471.
[4]黄勋,游宏梁,于洋.关系抽取技术研究综述[J].现代图书情报技术,2013,(11):30-39.
[5]Liu H,Chen C,Zhang L,et al.The Research of Label-Mapping-Based Entity Attribute Extraction[C]//IEEE International Conference on Progress in Informatics and Computing.IEEE,2011:635-639.
[6]Li C X,Chen P,Wang R J,et al.Web Entity Extraction Based on Entity Attribute Classification[C]//International Conference on Machine Vision.International Society for Optics and Photonics,2011:39.
[7]曾道建,来斯惟,张元哲,等.面向非结构化文本的开放式实体属性抽取[J].江西师范大学学报:自然科学版,2013,37(3):279-283.
[8]刘倩,伍大勇,刘悦,等.结合全局特征的命名实体属性值抽取[J].计算机研究与发展,2016,53(4):941-948.
[9]Zhong B,Kong L,Liu J.Entity Attribute Extraction from Unstructured Text with Deep Belief Network[C]//Advanced Science and Technology,2016:429-433.
[10]苏丰龙,谢庆华,邱继远,等.基于深度学习的领域实体属性词聚类抽取研究[J].微型机与应用,2016,35(1):53-55.
[11]Gridach M,Haddad H,Mulki H.FNER-BGRU-CRF at Cap 2017 NER Challenge:Bidirectional GRU-CRF for French Named Entity Recognition in Tweets[C]//Cap,2017.
[12]Huang Z,Xu W,Yu K.Bidirectional LSTM-CRF Models for Sequence Tagging.ArXiv Preprint ArXiv:1508.01991,2015.
[13]Keras中文文档[EB/OL].http://keras-cn.readthedocs.io/en/latest/.
[14]Chung J,Gulcehre C,Cho K H,et al.Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling[J].Eprint Arxiv,2014.
[15]Mccallum A.Efficiently Inducing Features of Conditional Random Fields[J].Computer Science,2003,19(4):1.
[16]Mikolov T,Karafiát M,Burget L,et al.Recurrent Neural Network Based Language Model[C]//INTERSPEECH 2010,Conference of the International Speech Communication Association,Makuhari,Chiba,Japan,September.DBLP,2010:1045-1048.
[17]Lawrence S,Giles C L,Tsoi A C.Convolutional Neural Networks for Face Recognition[C]//Computer Vision and Pattern Recognition,1996.Proceedings CVPR96,1996 IEEE Computer Society Conference on.IEEE,1997:217-222.
[18]Hihi S E,Bengio Y.Hierarchical Recurrent Neural Networks for Long-Term Dependencies[C]//International Conference on Neural Information Processing Systems.MIT Press,1995:493-499.
[19]Gers F A,Schmidhuber J,Cummins F.Learning to Forget:Continual Prediction with LSTM.[C]//Artificial Neural Networks,1999.ICANN 99.Ninth International Conference on.IET,2002:2451.
[20]Zhang S,Qin Y,Wen J,et al.Word Segmentation and Named Entity Recognition for SIGHAN Bakeoff3[C]//Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing,2006:158-161.
[21]Mikolov T,Chen K,Corrado G,et al.Efficient Estimation of Word Representations in Vector Space[J].ArXiv Preprint ArXiv:1301.3781,2013.
[22]王仁武,宋家怡,陳川宝.基于Word2vec的情感分析在品牌认知中的应用研究[J].图书情报工作,2017,61(22):6-12.
[23]Abadi M,Barham P,Chen J,et al.TensorFlow:A System for Large-Scale Machine Learning[C]//OSDI,2016,16:265-283.
[24]Lin X D,Peng H,Liu B.Chinese Named Entity Recognition using Support Vector Machines[C]//International Conference on Machine Learning and Cybernetics.IEEE,2009:4216-4220.
(责任编辑:陈 媛)
