第三十一讲 在科技开发工作中神经网络应用案例比对解读
2018-12-07徐静安吴芳汪焰
徐静安 吴芳 汪焰
20多年前,在和上海化工研究院自动化研究所所长徐亚强讨论时涉及人工神经网络,也算是对神经网络的道听途说,但新奇的名词和功能已暂存脑细胞记忆库中。2012年笔者带教的研究生陈玉岩尝试在精馏18O稳定同位素中应用神经网络对ASPEN模拟结果进行建模优化,教学相长,倒逼我跟进学习。陈玉岩帮我下载了《MATLAB遗传算法工具箱及应用》,我又向都丽红教授借阅《人工神经网络导论》。2013年我买了一本《计算智能——人工神经网络·模糊系统·进化计算》。2014年获赠《DPS数据处理系统——实验设计、统计分析及数据挖掘》。2015年吴芳硕士帮我下载了《数据挖掘中的新方法——支持向量机》,还促使我在2016年买了本《MATLAB神经网络43个案例分析》,其中,对案例分析花了点功夫学习。
当然,我们的注意力集中在科技开发中如何引入、应用神经网络方法,提升开发水平。2017年读到的《均匀设计法优化芥菜多糖的提取工艺及其神经网络模型的研究》一文,针对科技开发工作中有限的实验样本量的制约,很有特色,可作探索性学习和解读。
一 均匀设计安排实验+二次多项式逐步回归建模
根据专业知识,原文考察植物提取的4个影响因素及其变化范围。纤维素酶的酶提时间X1:20~130 min,酶浓度 X2:1.0%~6.5%,料液 pH X3:4.0~6.0;提取温度X4:45~60℃,响应Y为多糖提取率。
原文案例作为实验室小试阶段的应用性技术开发,采用均匀设计和二次多项式逐步回归建模,由此获得多糖提取的优化工艺是合理而有效的。由于四个变量波动范围不同,受pH及提取温度控制精度的制约,不宜水平间隔太小,所以案例采用混合水平均匀设计U12(122×62)。对于混合水平均匀表,水平数之间存在整数倍、约的关系,如12水平表尚可安排6水平、4水平、3水平、2水平的变量。实验安排及结果见表1。

表1 U12(122×62)实验安排及结果
二次多项式逐步回归算法计算结果如下:

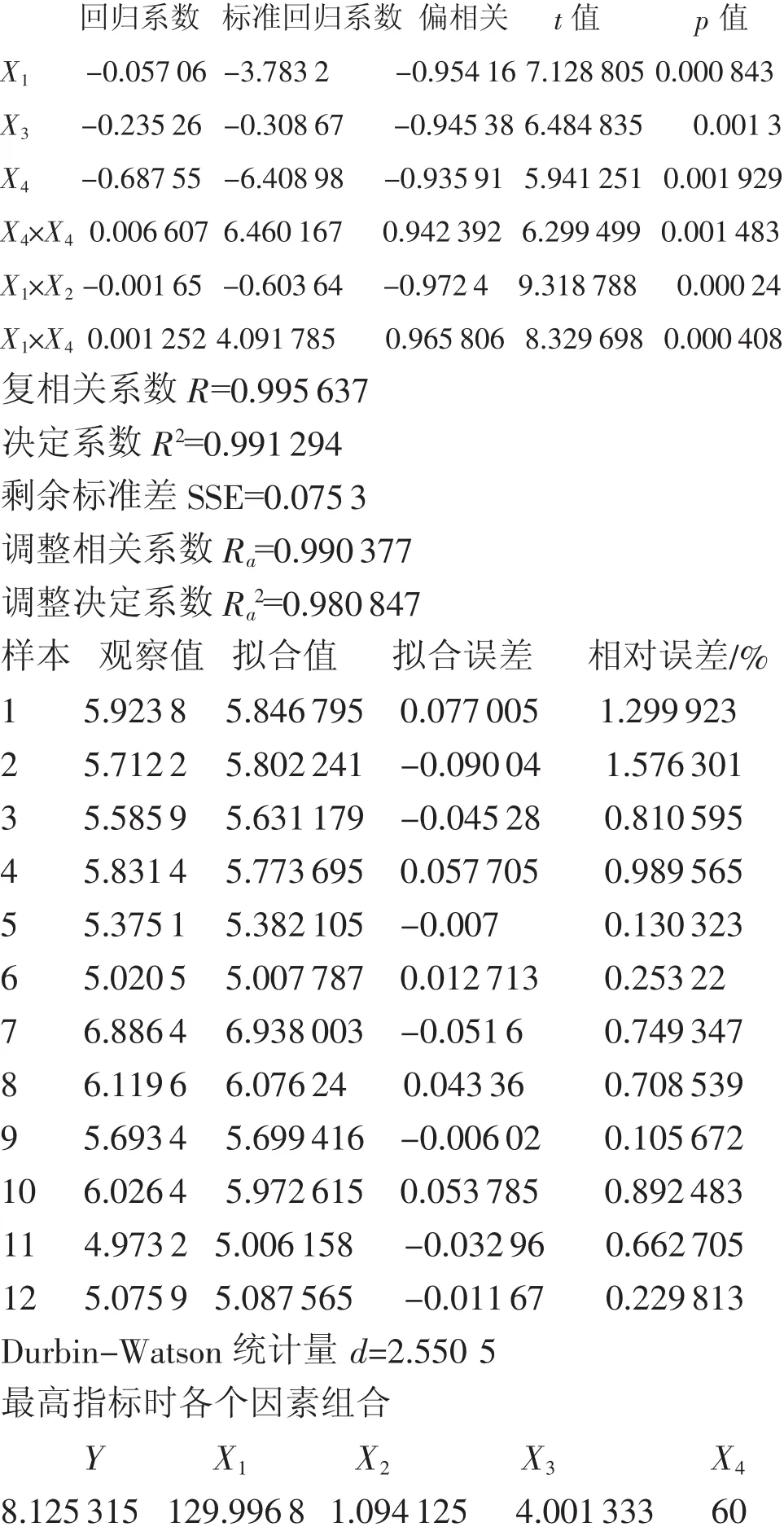
对表1数据进行了DPS新老版本及MINITAB软件的计算,比对基本相同、略有差异。新版DPS在逐步回归某项进入、剔出模型时直接显示该项的p值,而不是F值,使人机对话更直观,减少失误。以显著性水平p=0.05为界,原文把p=0.34357不显著项引入统计模型,预报最高指标时的响应Y=8.8464%,可能造成“过拟合”,本文列出了规范的计算过程和结果。
二 验证实验及分析
模型拟合各项统计量检验显著,进一步对预报进行验证实验,结果见表2。
模型拟合的相对误差<1.6%,而由表2可见,模型预报相对误差达到15.37%,也就是说拟合、预报相对误差之间有数量级差异。出现这种现象的可能原因:一是模型质量,二是验证实验误差过大。对于生物提取一般来说数据的误差会大一些,但对于技术开发而言,这样的预报质量还是难以接受,应积极寻求改进的方法。
在技术开发过程中,发现模型拟合、预报异常,常用而有效的方法是:(1)重复可能是异常的实验;(2)补充实验序贯地修整模型(见《上海化工》2017年10月出版的第十八讲关于统计模型稳定性的分析评估)。
由于本文的工作在解读,没有实验的可能,主要是计算分析。先判断验证实验的数据质量。试验设计的主体实验往往要对响应产物提纯、表征,计算、建模,再进行优化到验证实验,时间间隔较长,有可能带入新的误差,因此,应对实验原材料的一致性、实验环境条件的一致性给以充分重视。
对验证实验数据质量的判断,除了上述拟合、预报误差分析外,还可把U12(122×62)表1的结果和验证实验表2数据合并建模,计算过程略,对计算统计量进行比对分析,见表3。
从理论分析,样本量的增加对统计建模是有利的。但表3显示,U12+验证的N=13组的模型统计量毫无改善,也就是说验证实验合并建模对统计量不仅没有改善,SSE等统计量变差了,由此怀疑验证实验数据带入过大的误差。所以一般验证实验要求n=3,即重复3次,以降低误差的影响。
三 对U12(122×62)实验数据PRESS交叉检验
在难以追加实验的条件下,要对统计模型的质量及预报性能作出评价,可用留一法PRESS检验(见本讲义“关于留一法PRESS统计量的应用讨论”)。模型主体结构采用本文二次多项式逐步回归结果,变换成线性项共6项输入,采用线性全回归方法建模,输入格式及响应Y见表4。
计算机轮番留一个数据,其他数据建模,将留一数据视作预报值,可计算得到预报残差,轮番求出全部的残差平方和,即为PRESS值。

表4 两个模型统计量比对
在DPS中操作“多元分析-回归分析-线性分析”,得到:
方差分析表:
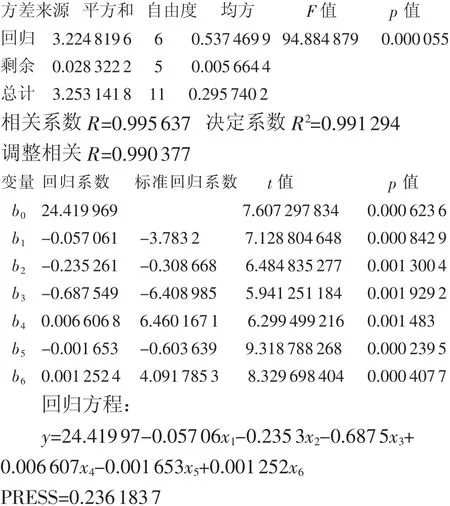
剩余标准差SSE=0.0752625
预测误差标准差MSPE=0.2173401 Durbin-Watson d=2.550521
采用MINITAB软件计算,结果几乎一致,部分结果如下:

上述4个变量的二次多项式逐步回归计算结果和6个线性变换后变量的全回归计算结果应该是一样的。差异是DPS线性变换后计算输出给出了模型的 PRESS,以及预测误差的标准差 MSPE,而MINITAB线性变换后计算PRESS外,还给出了RSq(预测)值,其实质是完全等价而且可以互换的。

本案例样本量N=12,线性变换因子项数P=6,两个软件预测的R2为:

PRESS留一法交叉检验表明,统计模型在拟合各项统计量有显著意义的基础上,预报R-Sq=92.7%也是有显著统计意义的。需要强调的是,N=12的模型拟合SSE=0.0753,而交叉检验预报MSPE=0.217 3,二者之比MSPE/SSE没有显著差异。
解读至此,表明案例基于均匀设计法安排的实验及二次多项式逐步回归建模,通过PRESS交叉检验,优化模型是有统计意义、是可以认可的。从技术开发流程分析,作为本阶段的完整性,尚需补充验证实验。
原文为了寻求更好的统计模型,探索性地引入BP神经网络。
四 BP神经网络优化
原文案例由于在使用DPS进行表1二次多项式逐步回归计算时,将P>0.05的不显著变量项留在统计模型内等原因,模型优化预报及验证实验结果见表5。

表5 原文案例的预报及验证
原文二次多项式逐步回归模型预测相对误差(8.846 4-6.876 8)/8.846 4=22.26%,由此分析,认为研究对象芥菜多糖的提取比较复杂,二次多项式模型不足以描述提取过程的内在规律,原文作者转向通用型的BP神经网络。笔者认为,转向的实践是原文的探索,值得学习、讨论。
1 BP神经网络的一般概念
BP神经网络的拓扑结构由图1所示,图中包含多个隐含层,具备无限逼近、处理线性不可分的能力。BP采用误差反向传播的算法进行节点连接权值的调整。
隐含层采用Sigmoid函数作为传递函数,多层多节点的隐含层设计有助于从有限的数据中挖掘更多的信息,但要付出更多的学习训练计算时间,以及可能处于过拟合状态。此外,BP网络学习算法修改调整权值采用最速下降法(梯度下降法)优化效率较高,但有可能陷入局部极小值的缺陷。

图1 BP神经网络的结构
2 基于均匀设计的BP神经网络参数优化
影响BP神经网络的稳定性及泛化应用能力的参数很多。本案例选定允许误差为0.001,为避免过训练,最大迭代次数为1000次。选用U10*(108)均匀设计表的1,3,4,5,7列考察安排5个参数,用表1中的12组数据作为训练集,结果见表6。
表6中5个考察参数均是DPS神经网络参数设置对话框需要输入的,训练结果的直观分析为表6的NO.6,参数优化组合的平均相对误差最小为0.257%。
原文对表6数据分析认为NO.3、NO.7方案“陷入局部极小值”,采用剩余8组数据进行二次多项式逐步回归建模,优化的网络参数组合见表7。用均匀设计、二次多项式逐步回归建模,优化网络参数是原文探索的亮点。
对表7参数作简要分析,训练速率大,权重调整变化大,收敛快,但易引起系统计算振荡,在DPS中训练学习速率会自动调整,一般选择最小训练速率0.9。
动态系数经验性选择为0.6~0.8。
Sigmoid参数调整神经元(节点)的激励函数形式。
激励函数通常选取S函数f(x)=1/(1+e-x/θ),其中θ为Sigmoid参数,一般取0.9~1.0。
隐含层层数在大部分应用场合单个隐含层即可满足要求,可以通过适当增加神经元节点的个数实现任意非线性映射。
隐含层节点数对BP神经网络性能的影响很大,一般较多的节点数可以从输入数据中提取较多的信息,但可能训练学习时间过长和“过拟合”。目前没有一个解析式可以合理地给出节点数。有初步研究表明,对于样本量为N的BP神经网络,隐含层节点数H,输入层节点数I,输出层节点数O,构成网络的总权重数 M=(I+1)H+(H+1)O,为了避免过拟合和欠拟合,以 1.8<(ρ=N/M)为宜。当ρ≥2.2 时,网络隐含层H节点过少,不能充分提取输入数据信息,欠拟合。当ρ≤1.8时,或样本量N偏少,或网络隐含层H节点过多,拟合了输入数据的噪声信息,过拟合,造成网络模型不稳定。考虑到科研开发工作样本量的制约,放宽ρ<1.8的范围。有资料建议可在ρ>1.0范围内进行H的优化选取。
表6和表7的计算、对比表明:(1)BP神经网络参数的优化很有必要,表6中NO.3参数组合的平均相对误差10.909%显然是过大的拟合误差,不可接受。(2)除了表6中NO.3与NO.7两个组合的参数,其他组合平均相对误差均小于1%。多项式模型优化预报参数组合平均相对误差Y=0.24%,而表6直观分析优化Y6=0.26%,在平均相对误差小于1%的前提下,这些数字上的差异对技术开发的价值不大,所以不再深入地计算校核。(3)BP神经网络参数优化,普遍采用的还有遗传算法,另行专题讨论。案例采用二次多项式模型预报的优化网络参数组合见表7。

表6 均匀设计因素安排表及训练结果

表7 优化的网络参数
3 BP神经网络的交叉检验
对于有限的样本数据,外加不可能补充追加实验,为了检测所建立的神经网络的性能,可以采用交叉验证的方法。本文前述PRESS的留一法思想和方法,可移植应用到本案例中;而本案例采用留二法,对表1的12组数据,轮番取2组为测试集,其余10组为训练集,利用优化的BP网络参数,进行66组测试,结果见表8。
从表8的简要分析可看出,留二法从12组数据中取2组为测试集,共有66个组合,训练平均误差可看作BP网络训练后的拟合平均误差、测试平均误差可看作模型预报平均误差,其总的训练平均误差的平均值为0.213%,测试平均误差的平均值为6.154%。BP网络拟合训练效果总体好于预报测试结果。前面分析案例采用二层隐含层、均为15个节点的多层多节点BP网络结构,存在“过拟合”的缺陷,即使结构参数优化,训练、测试平均误差之间从数理统计角度分析相差显著。尽管测试平均误差的平均值为6.154%,技术开发是可以接受的,但表8中测试平均误差为0.640%~17.594%,也就是说波动过大,在“过拟合”的参数下,交叉检验表明,模型预报性能并不理想。

表8 神经网络模型的训练与测试平均相对误差
从交叉检验角度分析,从N个样本中选取m个样本留作测试集,组合算法为 N![m!×(N-m)!]。留一法共有12/1=12个组合;留二法共有66个组合;如果采用留三法,则有个组合。考虑到计算工作量,原文案例采用留二法并列出交叉检验结果表8,直观地演示66个组合训练、测试结果及其波动,这是很有价值的探索性实践。
但是原文进一步的处理值得商榷。原文从表8中选择66组中NO.51计算实验为误差和最小的最优模型作为交叉检验的结果,不妥。
交叉检验的概念上显示:(1)所有的样本均用于训练、测试,因此最接近原始样本分布;(2)交叉检验过程没有人为、随机因素干扰,检验结果训练平均误差和测试平均误差的总平均结果比较可信。也就是说交叉检验总体结论才具有数理统计意义。
从交叉检验的方法上,从本文留一法PRESS计算结果可以看出,无论是DPS还是MINITAB软件预测误差的标准差MSPE、预报R-Sq均是计算、表征总体结果,而不是选用交叉检验的某个优化模型。原文选用表8中NO.51模型,采用二次多项式逐步回归优化工艺,X1=130,X2=1.0,X3=4.0,X4=60,预报芥菜多糖提取率Y=7.1911%,甚为不妥。规范的做法是,表7中BP网络计算验证的模型是经12组数据训练而得的模型,并经交叉检验后表征其预报平均误差为6.154%的模型进行优化预报。交叉检验能避免随机划分训练、测试集出现的“偶然”相关结果,具有统计应用意义。BP网络的模型是隐含在计算程序之中的隐性模型,与二次多项式逐步回归统计建模获得的显著性模型不相同,但可与遗传算法结合,寻求最优工艺,将另行讨论。
五 讨论
(1)本文比对解读的逻辑框图(见图2)。

图2 比对解读的逻辑框图
根据图2得出以下结论:
①采用混合水平均匀设计U12(122×62),因为提取温度在45~60℃范围内,步长间隔<2~3℃,现有温控水平难以达到。
②N/M=12/4=3首先考虑采用二次多项式逐步回归,统计建模。
③模型预报最优工艺条件。
④通过模型拟合误差、验证预报误差判断模型统计意义上的显著、有效性。如果是NO,模型需要修整。一般情况是补充实验,二次多项式逐步回归合并建模。
若补充实验有困难,可通过PRESS留一法计算评估模型预报功能。
若效果仍不好,才考虑采用非线性映射的人工神经网络。
⑤人工神经网络的结构、参数选择,对计算精度有影响,进行计算优化用均匀设计有普适性。
⑥由于均匀设计U10(105)本身具有一定的优化功能,可直接直观分析选择“好点”参数组合,本例采用N=8个好点进行统计建模寻优,深度挖掘。
⑦对结构参数优化组合进行BP神经网络计算验证,规范。
⑧对于神经网络计算分析,本例属小样本,不得已将12组实验数据分为10组训练集,2组为测试集。留二法分组穷举:产生66个BP模型交叉检验。
⑨由于神经网络建立的是隐性模型,除了平行地建立二次多项式逐步回归模型,提取最优工艺条件外,可用遗传算法寻优。
(2)在科技开发工作中,采用试验设计、二次多项式逐步回归建模,大多数情况下获得的近似、逼近函数具有良好的拟合、预报功能。对于复杂的研究对象,应探索应用BP神经网络进行非线性系统建模。但小样本条件下,BP神经网络的优势难以显示,可进一步探索应用SVM(支持向量机)非线性回归。
(3)交叉检验在有限样本条件下通过计算分析,表征统计模型的拟合、预报功能,应合理地计算应用。
(4)验证实验对于科技开发工作尤显重要。如果说基础研究是解决可行性问题,应用研究的科技开发需要解决优化、稳定性问题。模型预报的优化工艺应通过验证实验给以稳定的验证。
结合本案例,验证实验略显薄弱,一组数据还存有疑点,如果重复n=3就更有说服力。
(5)在BP神经网络应用中,网络参数优化、初始权重选取、网络模型最优工艺寻求都可采用GA遗传算法,应予以关注。
原文在科技开发工作中应用BP神经网络,采用均匀设计优化网络参数;采用留二法交叉检验评估模型拟合、预报性能;采用二次多项式逐步回归模型的最优工艺来验证BP网络优化的预报效果等,在这些方面作了有益的探索。但在二次多项式逐步回归建模时的回归分析;在BP隐含层多层多节点设置、应用留二法交叉检验结果及加强验证实验方面尚可进一步完善。尽管原文存在不完善、不妥之处,但我们尊重原文的探索实践,多次计算分析外,又购置了《MATLAB神经网络原理与实例精解》进行学习。
引用微软创始人比尔·盖茨的一段话共勉:为成功进行庆祝并没有什么不好,但从失败中汲取教训更为重要。
