文本向量化表示方法的总结与分析
2018-12-06冀宇轩
冀宇轩
随着计算机技术的深入发展,由于计算能力的大幅提高,机器学习和深度学习取得了长足的发展,因此我们在自然语言处理领域的研究越来越多的应用了机器学习和深度学习的工具,在这样的情况下,文本的向量表示就是一个非常重要的问题,因为良好的文本向量可以更好地在向量空间中给出一个文本空间内的映射,从而使得文本可计算。在近些年出现了许多的文本向量生成方法,本文主要介绍了文本向量化的发展过程,并对常见的文本向量生成方式进行了对比。
1.概述
1.1 研究背景
正如图像领域天然有着高维度和局部相关性的特性,自然语言处理领域也有着其自身的特性,其主要体现在以下几方面:
(1)由于计算机系统本身的硬件特点,任何计算的前提都是向量化,而自然语言处理领域的空间难以直接向量化,其不像图像与语音领域,信息可以直接被向量化,在自然语言处理领域的文本难以直接被向量化。
(2)自然语言处理领域中存在着多种高级的语法规则及其他种类的特性,具体体现为语法上的规则、近义词,反义词等。乃至于自然语言本身就体现了人类社会的一种深层次的关系(例如讽刺等语义),这种关系给自然语言处理领域的各种工作带来了挑战。
而文本信息的向量表示作为自然语言处理中的基本问题,其应当尽可能地包含原本空间内的信息,因为一旦在空间映射时丢弃了信息,则在后续的计算中也无法再获取到这些信息了。
1.2 研究意义
如上所示,在自然语言处理中,文本向量化是一个重要环节,其产出的向量质量直接影响到了后续模型的表现,例如,在一个文本相似度比较的任务中,我们可以取文本向量的余弦值作为文本相似度,也可以将文本向量再度作为输入输入到神经网络中进行计算得到相似度,但是无论后续模型是怎样的,前面的文本向量表示都会影响整个相似度比较的准确率,因此,对于自然语言处理的各个领域,文本向量化都有着举足轻重的影响。
2.模型简介及分析
2.1 词袋模型
2.1.1 One-hot Representation
最早的一种比较直观的词向量生成方式称为One-hot Representation,这种映射方式是通过先将语料库中的所有词汇汇总的得到N个词汇,并将语料库中的每个文档个体生成一个N维的向量,在每个维度就体现了该文档中存在多少个特定词汇。这种方式是一种较为简单的映射方式,其产生的向量表示体现了词频的信息。
2.1.2 TF-IDF模型
上述方式的模型仅考虑了词频,并且会造成长句子和短句子的向量长度不一致的情况,因此又有一种考虑了文档词汇中的逆文档频率的映射方式:TF-IDF(term frequency-inverse document frequency)模型,在这种方式中,首先对词频进行了归一化,即使用词出现的频率而非次数代表词频,表示为公式如下:

另一处改进为统计了每个词的逆文档频率指标,并使用该指标作为词罕见程度的度量值,以更好地刻画文档的生成向量。逆文档频率的模型如下:
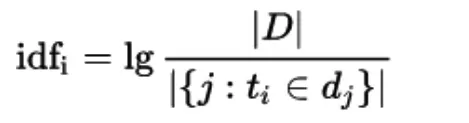
这两种模型的共同的缺点在于其二者的向量长度都非常大,对于一个有着30W词汇量的语料,每个文档的映射向量长度将都是30W,这意味着产出的矩阵非常稀疏,并且在计算时也会非常复杂。
2.1.3 潜语义分析模型
因此,我们引入降维的方式来对高维度的文档向量进行处理,其主要的模型为潜语义分析模型(Latent Semantic Analysis),这种模型通过数学方法,将文档之间的关系、词之间的关系和文档与词之间的关系都纳入考虑中(Deerwester,S.,Dumais,S.T.,Furnas,G.W.,Landauer,T.K.,& Harshman,R.(1990).Indexing By Latent Semantic Analysis.Journal of the American Society For Information Science,41,391-407.10)。
具体来讲,潜语义分析模型使用了主成分分析的方式来进行降维,即通过抽取向量空间内分布方差最大的若干个正交方向来作为最后的表示方向,并对其余的方向的内容进行丢弃即得到了每个样本的低维表示,该表示是有损的,即丢失了在丢失维度上的分布细节。
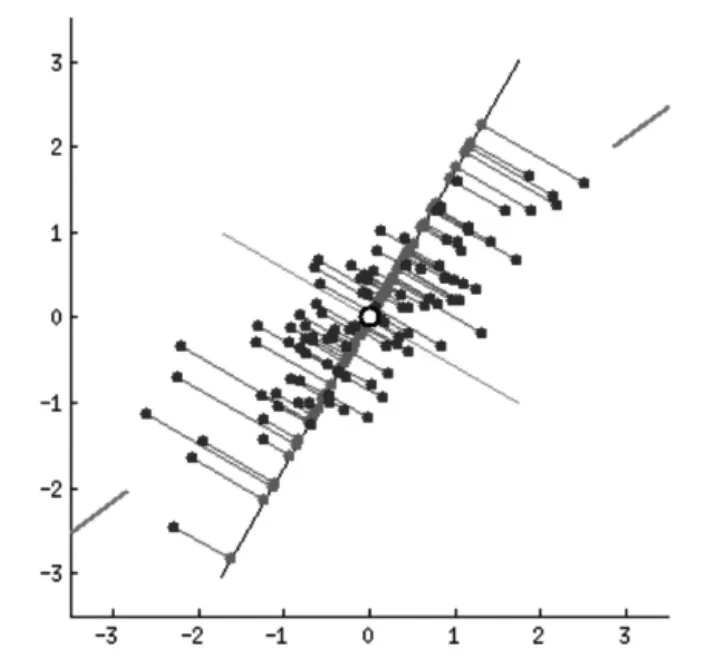
图1 二维向量分布的主成分分析
潜语义分析模型将这种将高维的向量表示转换为低维的向量表示的方法解释为文档的词向量空间转化为语义级别的向量空间,由此实现了一个有意义的文本降维的工作,即在更低维度上,一个维度并不再代表原来的一个词的信息,而是代表原来的几个词的一个混合信息,这被称为“语义维度”。被丢弃的维度上的分布也被认定为是一种“噪音”,对其丢弃可以更好地使用低维度的信息来表达原文本的语义信息。
值得被关注的是,上述的模型均为词袋模型,其基本的特点即为忽略了文本信息中的语序信息,即不考虑段落中的词汇顺序,仅将其反映为若干维度的独立概念,这种情况有着因为模型本身原因而无法解决的问题,比如主语和宾语的顺序问题,词袋模型天然无法理解诸如“我为你鼓掌”和“你为我鼓掌”两个语句之间的区别。因此基于上述模型的文本模型无法获取到原文本中语序所带来的信息。
2.2 基于神经网络的文本向量化模型
深度学习出现以后,逐渐被应用于自然语言处理领域,在文本向量化上也有着许多的进展,其中很多的成果已经成为了自然语言处理领域的基础部分。
2.2.1 Nerual Network Language Model
2001年,来自蒙特利尔大学计算机教授Yoshua Bengio给出了一种生成词向量的方式,即通过一个三层的神经网络、softmax分类及反向传播算法实现了词向量的映射(Bengio,Yoshua,et al.”A neural probabilistic language model.”Journal of machine learning research 3.Feb(2003):1137-1155),在这种映射中,词向量本身包含了语义的信息,即通过向量的分布信息可以得知其对应词的相互联系,其基本结构如下:

图2
其输入层为中心词附近的多个词的向量表示,并将这些向量进行拼接得到隐藏层,并通过softmax函数得到输出层,即可以通过梯度下降的方式来训练输入向量与权重参数,在这里需要注意的是在这个模型中,我们所需要的是模型产出的词向量而非权重参数。
2.2.2 word2vec与doc2vec
2013年,来自Google的Mikolov.Tomas等人发表了《Efficient Estimation of Word Representations in Vector Space》,提出了两种词向量映射模型(Mikolov,Tomas,et al.”Distributed representations of words and phrases and their compositionality.”Advances in neural information processing systems.2013),不仅简化了NNLM模型,也提升了训练的准确度,在训练得到的词向量中。同年,Google公司开源了可以在百万词典和千亿级别语料数据上进行计算的word2vec工具,并分享了基于分布式计算框架在千亿级大规模新闻语料中训练得到了词向量结果,极大推动了自然语言处理的发展。

图3
其使用两种模型结构,分别是CBOW模型和Skip-gram模型,CBOW模型的主要思想是使用中心词附近的词去预测中心词,而Skipgram模型主要是使用中心词去预测中心词附近的词。其二者的区别主要在于CBOW模型某种意义上属于一种词袋模型,一定程度上忽略了文本的语序顺序,并且由于模型结构的不同,其二者反向传播进行参数调整的方式不同:CBOW模型的中心词会共享一次反向传播的梯度下降,而Skip-gram则不存在这种共享关系。除此之外,word2vec的方法还提出了两种方法来加速词向量的训练速度。
在word2vec词向量方式出现以后,很多学者开始了基于word-2vec的文档向量化方法的研究。其中主要有以下两种主要方法:第一种是简单的向量加和取平均值,这种方法的特点是速度快,但是由于完全忽略语序信息,因此效果比较差,另一种方式是基于语法规则树来建立文本向量,但是其局限性在于其性能较低且仅适用于句向量的生成,效果同样不是很好。2014年,Mikolov.Tomas提出了一种新的基于神经网络的段落文本生成方式,是一种良好的端对端的文档向量化方式(Le,Quoc,and Tomas Mikolov.”Distributed representations of sentences and documents.”International Conference on Machine Learning.2014)。
其中,PV-DM算法主要沿用了word2vec 中cbow的方法,通过一个单层的简单神经网络来构建模型,在构建隐藏层时将段落向量也加入隐藏层,并且与其他的词向量一起获得反向传播的梯度,这样在多轮迭代后就可以:
Distributed Memory version of Paragraph Vector (PV-DM)
该算法大致上沿用了word2vec CBoW的方法,即通过一个单层的神经网络结构来建立模型,在这个模型的训练过程中得到副产物段落向量,其不同点在于在这里另外增加了一个向量作为段落的向量表示,与词向量共同拼接或加和作为输入进入网络,网络通过梯度下降的方式进行优化,当需要给出一个新的段落向量表示时,在预测阶段,模型的参数(包括词向量和模型中的softmax参数)都是固定的。
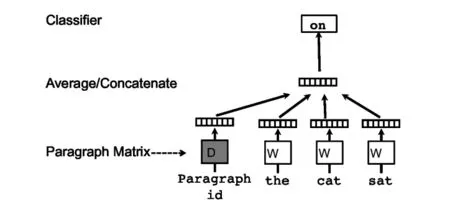
图4
Distributed Bag of Words version of Paragraph Vector (PV-DBOW)
这种算法大体上也是沿用了Word2vec中的Skip-gram的方法,即以文档向量作为输入,以最大化输出为文档中的词作为目标进行训练,这种方式也可以获得文档的向量表示。

图5
以上两种方式均可以通过Hierarchical Softmax或者Negative Sampling简化模型训练,从而提升训练效率,除此之外另有Glove等方式用于词向量表示(Pennington,Jeffrey,Richard Socher,and Christopher Manning.”Glove:Global vectors for word representation.”Proceedings of the 2014 conference on empirical methods in natural language processing(EMNLP).2014)。
基于神经网络的文本向量化方式的特点主要包括以下几个:
(1)基于神经网络的文本向量化方式可以更多地利用激活函数及softmax函数中的非线性特点,这种特点为模型带来了更多的拟合能力,使得模型可以学习到更多的文本特性,生成的文本向量是更好地文本向量化表示。
(2)基于神经网络的文本向量化方式很大程度上保留了语序信息,其利用了文本相邻的特性,这种特点在词袋模型中往往是直接忽略掉了的。
(3)基于神经网络的模型在语料规模和训练复杂度上也有着更高的要求,这意味着只有在计算能力和文本数据量达到一定程度的时候才可以开展,近些年的深度学习的发展也是源于信息爆炸和计算能力的飞速发展。
3.总结与展望
在过去的主要文本向量化方法中,早期的模型主要是基于统计的,其计算相对简单,但是效果也相对较弱,随着深度学习的发展,基于神经网络的模型开始出现在自然语言处理领域,也极大地提升了文本向量化的质量,由于文本向量化本身的重要性,在未来一定会有更多优秀的模型可以用于这个领域,我们应该更加努力地学习相关知识,以期有所建树。
