Adaboost算法原理在实时道路危险预测的应用研究
2018-12-06魏娟
魏 娟
(江西服装学院 商学院,江西 南昌 330201)
0 前言
近年来,随着我国经济不断崛起,交通道路得到逐渐扩建,机动车辆的数量也不断增加,道路的交通事故和伤亡情况呈现出一种上升态势.根据道路交通事故统计,2002年发生道路交通 事故造成109 381人伤亡,2016年,发生道路交通 事故造成21.284 6万人伤亡,相比2014年有所上升.到2017年,我国的交通事故造成伤亡人数有6.3万,虽然道路交通事故有所下降,但是我国交通事故年伤亡人数依然高居世界第二.因此,做好对道路危险预测,挖掘道路事故的形成规律,协助控制道路交通安全,采取合理的应对道路危险事故的策略,是当前极其重要的研究课题[1].过去,对于道路交通危险事故预测,都是基于长期的历史数据进行研究,包括:交通事故同环境、车辆特性、交通流特性和驾驶员特性这 4 个方面因素,对他们之间的关系,以及交通危险事故的发展趋势进行分析,但是该研究的短板就是无法反映出交通事故的发生和实时交通特性的内在联系.有国内研究者提出以车速的标准差当做特点变量要素,构建起更小总风险准则的贝叶斯预先测定模式,但考虑到我国国情,要收集到交通流数据与事故的详细数据极其不易,难以实时采集交通数据,因而无法采用仿真实验去验证方法是否真的有效可行.当前,随着计算机技术朝着智能化、数字化与系统化方向的发展,利用Adaboost算法,可以实现对道路危险进行实时的预测.
1 道路交通危险事故实时预测方法
预测顾名思义是预先推测或者是测定,基本含义是指在掌握现有信息的基础条件上,按照客观事物的发展趋势和变化规律,对事情未来发展的过程与结果进行推断与判断.道路交通事危险故预测是指在掌握已知某一地域的道路交通危险事故程度和有关的影响要素状况采取科学有效的推测和判断.道路交通危险事故的预测本身与预测结果是科学决策的重要前提,通过对道路交通危险事故的预测,发现危险事故的发展趋向、变化特征、将来状况特征等有关指标,以达到对将来交通安全情况有一个充分的了解,并采取有针对性的预防措施,从而达到减小到位交通危险事故的发生[2].道路交通危险事故的实时预测主要有三种情况,分别是正常情况、危险情况、过渡情况.正常情况说明交通状况良好无事故,用记号(ξ1)表示;危险情况说明交通状况存在可能发生的阶段了,且随着T-φ时段不断增长,直至T时段交通事故发生,用记号(ξ2)表示;过渡情况说明交通事故发生以后到正常情况之间的过渡交通状况,用记号(ξ3),表示.具体如图1所见.
Yu R., Abdel-Aty M与WANG L,ABDEL-ATY.M对交通事故预测采用了贝叶斯理论、logistic 回归等方法对高速公路上实时交通数据处理,同时也证实了各种类型的交通情况,可以采用特定时间中的交通数据予以表征.下面,借由相对不变的道路信息和能实时采集的交通流数据对(ξ1)和(ξ2)进行表征.各种交通情况的特点向量记为(1)式:
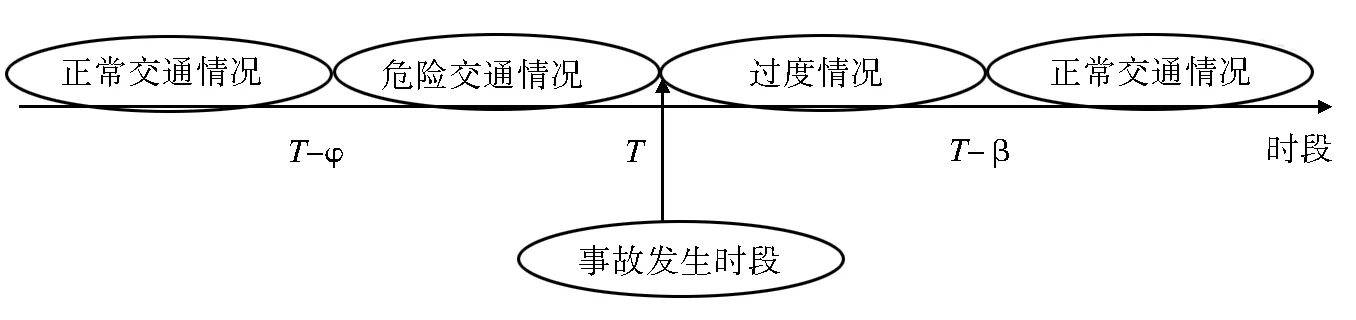
图1 交通状况划分
Xi={Ti,Li,Ci,Wi,Fi}T,其中i=1,2,…,N
(1)
式中,T代表样本数据记载时间,L代表样本数据记载经纬度地点,C代表记载时间的平均气温,W代表记载时间的天气情况,天气情况可以是晴天、雨天、下雪和雾天等天气,F代表实时收集的交通流特点,交通流特点还包含在特定时段尺度Δt中的速度用(v)表示、占有率用(o)表示、车流量用(v)表示,最后式中的N表示的是样本数量.这样道路危险事故的实时预测就改变成对各种类型道路交通状况的分门别类分析了,借助分类器p(x)对某时间段i的特征向量xi采取分类方法,以达到对该时间段交通危险事故的实时预测,其公式(2):
(2)
当认定x属于ξ2也就确认是危险交通情况,那么可以采取合理的办法预防危险事故的发生.关于分类器的交通危险事故实时预测流程,如图 2 所见.

图2 实时交通危险事故预测流程
其具体流程如下:首先,全面收集交通事故及其有关的流量数据,进行数据预处理,然后选择合适特点变量样本数据,最后是利用样本数据设计Adaboost分类器,并将该设计进行实际应用,并获得实时数据,以识别交通情况,实现对事故的预测[3].需要注意的是,随着道路交通事故的数据增加,该设计在实际的应用中可以动态调整特点变量并训练新的分类器,以实现对预测的准确度提高.
2 道路交通数据准备和处理
道路交通数据收集包括交通事故数据和交通流数据,但是在构建的系统中,两者的作用略有区别.虽然在开始设置分类器时均有发挥作用,但是在使用分类器时,只有交通流数据发挥作用.
2.1 道路交通数据的收集和预处理
将江西南昌二环路上2017年11月18日到11月28日的交通流数据和该时段中道路交通危险事故数据作为收集对象.在实际的道理交通流数据的收集过程中会收到环境、检测工具故障等影响,使得记载的数据失去、数据时间点顺序错乱、数据精度发生偏差等错误或异常现象.所以,为了确保数据的准确度,在道路交通数据应用之前就需要做到预处理.主要包括这些方面:一是参数的合理范围和精度的设定.如车辆的平均速度的适宜范围的设定,应该是在 0速度与地点限定速度的1.5 倍范围里,时间占有率的设定是 0 到100%.对出现不符合设定要求的数据要做好修正工作.二是每一组交通流数据的记载段检验,数据正确性会出现在 0到 719范围,对出现乱序数据要求再一次排序修正,并对重复数据进行删除.三是丢失数据和其他异常数据要做好填补工作,填补工作可以根据数据多少,时间段的不同采取不一样的估值,如果是个别数据出现异常,可应用邻近数据平均值进行添加,若是某一段时间出现异常,可应用同一时段的以往数据平均值进行添加.
2.2 道路交通情况特点选择
综合考虑交通流数据,将速度、占有率、车流量的平均值和标准差当作备选特点.特点变量选取的对划分正常交通状态与危险交通情况影响非常大.选取不好对设计分类器会造成很大困难,选取合适可以很容易实现对两种交通情况进行分类.
2.2.1 道路交通情况特点选择办法
将正常交通状态与危险交通情况进行明显区分是特点选择的可分性判据,也是特点选择的准则,采用Adaboost分类器的错误率作为准则是最直接的方式.但是在交通事故实时预测中,因为正常交通情况和危险交通情况的样本概率密度函数是未知的,从错误率来计算就行不通.这就需要采用与错误率有关联,且便于计算的准则,而与错误率有密切关系的是概率密度函数.概率密度函数可应用关于概率分布的可分性判据,根据交通状况特点显示密度的重叠大小预判其可分性.而联合概率密度函数本身具有未知性,用Parzen 窗法对各候选特点的概率密度函数估算.整个流程如图3所示.

图3 特点选择
2.2.2 Parzen窗密度函数推算
上文提到,概率密度函数可应用关于概率分布的可分性判据,但是对各种交通情况的样本了解不全,其密度函数的形式也不可能事先给出,这就要应用非参数估计法来推算各交通状况各个维特点的概率密度函数.具体是用Parzen 窗法予以推算:当样本数据从N →∞阶段,利用Parzen 窗法予以推算,概率密度函数会约束到真实概率密度函数[4].Parzen窗推算方法有矩形窗和高斯窗,接下来,将采用使用频率最高的高斯窗.在一维状况下,高斯窗表达公式如下(3)所示:
(3)
采用高斯窗对道路交通状况的几个候选特点变量进行推算,以获取各候选特点的概率密度函数.通过推算所得的最终概率密度函数如下(4)所示:
(4)
公式中:zΔt表示各种 Δt下速度、占有率、车流量的标准差或者平均值特点.需要注意的是计算获得的结果是根据正常交通状态(ξ1)与危险交通状态(ξ2)实施分别推算,其获得的结果表示为:p(z|ξ1),p(z|ξ2).
2.2.3 关于概率分布的可分性判据
概率分布的可分性判据,通常需要分析交通中的正常情况(ξ1)与危险情况(ξ2)的概率分布间的交叠大小,以得到某一特点下两种交通情况的可分程度.假设所有特点都是p(z|ξ1)=p(z|ξ2),说明两种交通完全不可分.假设所有特点存在一类交通p(z|ξ1) ≠0,另一类交通p(z|ξ1)=0,说明两种交通情况完全可分.对于概率分布间的交叠大小,可以采用p(z|ξ1),p(z|ξ2)两者之间的距离来计算.由此,我们推知:各种距离函数只需符合非负、两种不重叠时选最大值、两种分布密度一样时选零这些要求,都能用类分离性的概率距离计算.
同时分类中还有个很主要的距离计算,则是概率密度函数的似然比,后来,人们又在似然比的基础上有所发展,将其定义为散度距离计算,如下(5)公式所示:
(5)
通过该公式计算获得,当JD越大,说明其可分性更好,接下来将运用散度度量作为概率距离的度量,利用JD式对各种Δt下 6 个特点的类条件密度依次计算,从而确定哪些特点在选定 Δt下越能反映各种交通状态的差异.
3 AdaBoost算法对交通情况分类设计
AdaBoost算法是一类机器学习算法,是通过T个简单的、精度比随机猜测略好的粗糙推算(也就是为弱学习准则h1,…,hT)以此构建出一个精度高的估计.功能上就是把弱分类器增加成为强分类器,其强弱就是识别率高低[5].因为不需要弱学习器性能的先验知识,使得AdaBoost 算法很方便的在实际问题中运用.但是在以往的AdaBoost级联架构中,是将一定数量的弱分类器简单串联,同时弱分类器会存在一定的误判概率,这样会造成整个分类器的识别率差[6].针对以往AdaBoost算法问题,在对交通情况分类设计中,提出了一种关于样本在权重中的分布来调整权重的方法,以达到缓解退化现象.
选择的AdaBoost算法应用在交通情况分类设计中,主要是利用分类器区分两种交通状态,用0代表正常交通情况,用1代表危险交通情况,并用各种训练集训练多个弱分类器,将各分类器有序组合形成一个最终版强分类器[7].本研究主要采用分类和回归决策树(CART)的弱分类器对两类交通情况进行分类.当特点变量选择好以后,样本数据就确定了,这时就可以训练弱分类器.但是在训练弱分类器的过程中要每次弱学习后再次改变样本的空间分布,并再次改变整个样本的权重,被错误分类和被正确分类的样本权重分别对应出现了增强和减弱的两个极端分化,最终得到弱分类器的加权组合,其权值代表了弱分类器的功能.具体操作过程:
第一,开始训练样本的权重,如(6)公式所示:ξi=1/N;i=1,2,…,N.
(6)
第二,采用加权获得的样本,在m次迭代构建弱分类器fm(x),并在实施分类的同时,算出分类不正确率em,如(7)公式所示:令cm=lb((1-em)/em)
(7)
第三,样本权值的更新,如(8)公式所示:令ξi=ξiexp〔cml(yi≠fmyi≠fm(xi))〕
(8)
归一化使其公式如(9)所示:
(9)
其中如(10)公式所示:
(10)
第四,反复执行第二、第三步骤,当获得最大迭代次数M停止.
第五,对于分类样本x,分类器h(x)的输出如(11)公式所示:
(11)
在完成分类器训练后,需开展实时样本数据分类,从公式(2)可知,假设某一时间段被认定成危险交通情况,则可采取切实有效的办法以规避交通事故.在现实环境中,交通数据是持续累积增加的,因而需要对当前收集的数据进行处理,并对分类器进行更新,达到动态调节,增强分类的准确度.

表1 各类特点最大散度距离
4 实验方案的应用和结果
4.1 数据的准备
数据的准备阶段首先是要进行数据的收集,地点是江西南昌二环路上2017年11月18日到11月28日的交通流数据和该时段中道路交通危险事故数据,有159个固定检测装置,间隔时间2 min进行一次记载.道路交通事故数据记载的是南昌市全部出现交通事故的地方和时间,对数据进行预处理,获取471 组正常道路交通数据和679 组危险道路交通数据,每组数据涵盖的信息也非常多,包括特点变量的时间、发生地点、平均气温和气候状况,同时还包含了每组数据中该地点车辆驶入驶出 4 个方向的交通流数据,以及事故地点4个方向上 22 min 中的速度、占有率和车流量数据.道路危险交通情况数据选择的是事故发生时和前20 min内的交通流数据,正常交通情况数据选择的是事故发生前 50 min 时和前 20 min 内的交通流数据.归一化处理之后,从道路危险交通情况数据和正常交通情况数据中各自选择了370 组数据,共计 740 组数据,并用作训练样本,其余的410 组则用作成测试样本.
4.2 特点选择
首先是对候选特点估算,使用的是Parzen窗推算法实施概率条件密度估算,对各种类型道路交通情况特点类条件密度的散度距离进行对比,以确定适当的时间尺度和特点.候选的道路交通流特点涵盖了车辆驶入1、驶入2和驶出1、驶出2这几个方向,以及各个方向上的 6 个变量.预选过程中,从 2 min 至22 min一起选定10 个时间尺度,分别对道路危险交通情况和正常交通情况进行推算,总共有480次,最后对各种道路交通情况的散度距离计算.如表 1 所示.各类特点最大散度距离.
从表1中不难看出,标准差高于平均值,在各类交通情况下,道路交通流量数据平均值差异性小,对各类交通情况特点无法有效反应,所以需采用差异性大的标准差当作特点变量,下面就是通过每个时间段尺度标准差特点推算获得结果,如下图4所示.
从图4坐标趋势波动变化获知,4个方向上在时间尺度上速度、占有率、车流量的选择都不一样.分别为:Δt1={2,2,2},Δt2={2,8,6},Δt3={2,2,4},Δt4={2,2,2}.基于上述结果,依次提取训练样本和测试样本,继而算出标准差特点.
4.3 分类结果
分类利用的是AdaBoost 分类器,以实现对测试样本的分类,而测试样本里面ξ1的样本数是151 组,ξ2样本数是 172 组,获得的分类结果如表2可知.
从表2获知,分类器最大迭代次数不断增加,虽然分类结果会不同,但是到达一定的迭代次数后,分类结果会收敛.平均值特点收敛是在迭代次数3 000阶段,标准差特点收敛是在迭代次数3 600阶段.两者相比较,标准差特点分类结果较好,可见所选特点较为符合实际.其中,危险交通情况的分类正确率是67%,正常交通情况的正确率是56.1%,总正确率比平均值特点的正确率要高8.1%.

图4 各时间段尺度标准差特点散度距离

特点迭代次数ξ,错误分类数误警率/%ξ,错误分类数漏报率/%总错误率/%平均值标准差1 0008056.06942.648.92 0007753.86942.647.93 0007552.46741.446.64 0007552.46741.446.62 0007049.06439.543.93 0006847.65936.441.63 6006344.15534.038.74 0006344.15534.038.7
通过以上实验,得出利用AdaBoost算法预测道路交通事故的发生是可行的,必须要注意的是当训练数据变多,则训练分类器过程中,其迭代次数也相应地变多,训练时间亦随之变大,这就需要做好训练分类器,以最大限度地减少每个测试样本分类结果的输送出时间.通过以上研究发现,我们可以获得410个测试样本的平均输送出时间是15.225 s,其中每个样本是48 ms.所以在道路交通实时预测中,可采用任何时间段更新的以往数据训练分类器,将计算后的实时采集的相关数据输送至分类器,就可以实现对道路交通危险结果的及时预测.
在研究中发现:特点变量选择有着非常重要的作用.在今后的实验中,还可将交通情况更多的影响要素加入到交通情况特点变量中,以进一步提升道路交通分类预测的准确性,从而实现更有效的道路交通危险预测.
