自然语言分析技术在政务热线中的应用
2018-12-04黄强松郑丹青黄凯翔董明昱
陈 辉 黄强松 郑丹青 黄凯翔 董明昱
中国电信江苏号百信息服务有限公司
0 引言
12345热线是市民参与社会管理的重要平台。传统的数据统计分析系统由于功能所限造成了资源的闲置和浪费。为此热线依托科技支撑,利用先进的计算机软件技术,开发了千万量级的智能化大数据平台,实现了受理坐席精细化管理,市民诉求自动化归档、转办和考核,诉求舆情自动分析,办理工作扁平化管理等智能化功能,并且还实现了大数据的自动对比,为前瞻性研判和具体事件的办理提供了数据参考。此项功能走在了全国同行业的前列。
但在数据处理的过程中,我们发现了一些问题。在热线系统中,其系统数据往往分为系统自动生成数据、系统可选数据及接线员记录的描述数据,如表1所示。系统自动生成数据往往为编号数据、时间数据等等,而系统可选数据一般分为热线形式类别、热线内容类别等等,而接线员记录的描述数据往往是记录的详细时间地点人物事件等等。

表1 12345系统数据样例
在进行数据处理时,发现自动生成数据、系统可选数据较好处理成格式化数据,并可以直接参与统计、挖掘及分析,但是接线员人为记录的较多信息很难通过简单的方法将信息准确的提取出来,若这些信息难以提取,则有用信息大大减少。因此,人为记录数据的分析预处理是自然语言处理的重点。
1 自然语言分析技术介绍
所谓自然语言处理就是研究能使计算机像人一样理解自然语言的一门边缘科学。它的主要任务是从语言中提取意义,从而使得计算机能够对所处理的语言材料有更深入的了解,目前这一领域的研究包括:自然语言数据库的构造与查询,自然语言人机接口,自然语言语篇生成与摘要,自然语言文档查阅,智能文本处理,自然语言专家系统,机器翻译,自然语言情报检索等等。自然语言处理的成功可对人类生活产生巨大的影响,如:它可消除人与机器间的语言障碍、人类之间的语言沟通问题和知识瓶颈。
人类自然语言的表述通常有语音和文字两种形式,本文从文字表述的角度来论述自然语言处理。自然语言处理研究包括基础研究、共性技术和应用研究,应用研究当前主要有机器翻译、信息检索和社会计算等几个方面。
自然语言处理的流程如图1所示:
字→词→短语→句子→段落→篇章
针对自然语言的处理过程,可从字词句子段落入手,同时利用最新的分词软件,进行精准分词。

图1 自然语言处理流程图
2 政府数据处理关键技术方法
通常情况下,描述事件的要素为时间、地点、人物、事件。通过分析政府热线数据,我们发现文本数据中的时间较好处理,热线拨打市民的个人情况属于需要保护的个人隐私,无需重点研究,而数据处理的难点是无法精确定位问题的关键词(事件、发生的地点)。因此,本文分析的总体工作为确定发生时间、事件(动作关键词)、地点,而难点工作为确定事件及地点。
2.1 时间解析
政府热线的时间记录样例为:17052923082782785830。对于时间的解析比较简单,观察数字序列可以得出,前两位为年份,第三位至第四位为月份,第五位至第六位为日期,第七位至第八位为小时,第九位至第十位为分钟,第十一位至第十二位为秒,后续为其他编号。根据实际需要,我们重点提取了年份、月份、日期和小时,而分钟与秒的颗粒度太细,意义不大。因此,根据以上规则,时间解析的样例如表2所示:

表2 12345系统时间解析样例
2.2 事件解析
用户的反馈信息多为固定格式的记录信息,形如:某市民来电反映:某某地区某菜市场有小贩使用高音喇叭,噪音十分扰民。请相关部门尽快处理。
对于此类信息,首先去除与主体无关的信息,即去除开头及结尾等固定格式内容,仅留下反馈信息主体。
而后,对信息主体进行分解,将其按标点符号分成多句。而后分别对其进行分词及词性标注。
对于句意及主谓宾等结构完整的语句,如第一句,对分词结果进行遍历,选取动词及之后遇到的名词,多个名词算为一个动词短语,如:使用/v,高音/n,喇叭/n,将提取出的词语放入集合去重。
对于词语过少的语句,如第二句,则同样提取动名词短语或名词动词短语,如:噪音/n,十分/d, 扰民/v,从中提取噪音扰民,同样将结果放入集合去重。
部分信息中可能包含可以表达整个反馈事件的词语,可将其加入词库直接匹配信息,如反馈屋顶、楼上或楼房漏水此类的信息,可直接将“漏水”添加至词库。
对于提取出的词语,可能语义不清晰或根本不成词语,可将其加入过滤词库进行结果修正,以便在结果中去除此类词语。
对于事件解析主要就是针对关键词的提取,基于上述生成的词库,采用TF-IDF算法对生成的词库进行排序。
在TF-IDF算法中, TF代表词频,指的是词语在其对应文本中出现的频率,它对词语出现次数进行了归一化操作,避免它偏向长的文本,对于某一个特定文本里的词语来说,词频TF可以表示为:
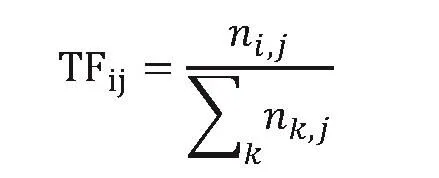
分子是该词在文本里出现的次数,分母是在文本中所有字词的数量之和。
逆向文件频率(IDF)是由总文本数目除以包含该词语的文本的数目,再对得到的商取对数:
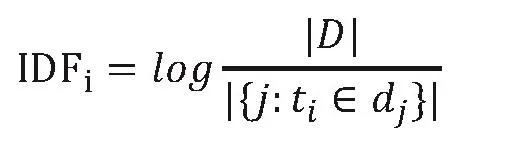
其中|D|是所有的文件总数,j表示包含目标词语文本的数目。

最后计算词频和逆向文件频率的乘积,某一文本内的高词语频率,以及该词在整个文本集中的低文件频率,可以得到较高的TF-IDF值,因此TF-IDF算法可以很好地过滤掉常见的词语,从而保留关键的词语。
通过TF-IDF算法对所有类别的文本进行计算,得到词语的相应TF-IDF值,对于TF-IDF值高的词语,一般代表着这一类事件中的投诉关键点,将会予以保留并进行深度分析。
最后将所有类别的投诉反馈文本信息中TF-IDF值最高的几个进行汇总统计,分析出所有投诉信息中用户最为关心的重点问题。
2.3 地址解析
接线员人工记录语句中,由于热线拨打市民上报地址的习惯不同,地址的记录往往比较随意,具体的情况往往为:(1)某某小区业主来电;(2)某某区市民来电反映;(3)某某镇石桥某某村拆迁户来电反映。
以上内容均为市民在投诉时上报地址的说法,从以上说法实例来看,市民上报的地点往往只上报一个或者两个维度,并不能同时完整地告知接线员自己归属的区、街道(镇)、社区、路、小区等信息,比如市民只告诉接线员自己是某小区业主,或者告诉接线员自己在某某区某某路等等。这样在进行统计和挖掘算法计算时,很难完整地对区、街道等行政区域进行分析。因此,需要建立地址进行树形结构,用树形结构补全市民上报信息,即使市民只上报了某某村或者某某小区,也能将其对应至相应的区或者街道。此种做法的最大好处是可以精确对区或者街道级的问题数量进行分析统计。
对区、街道(镇)、社区、小区进行层级编号,如表3所示:
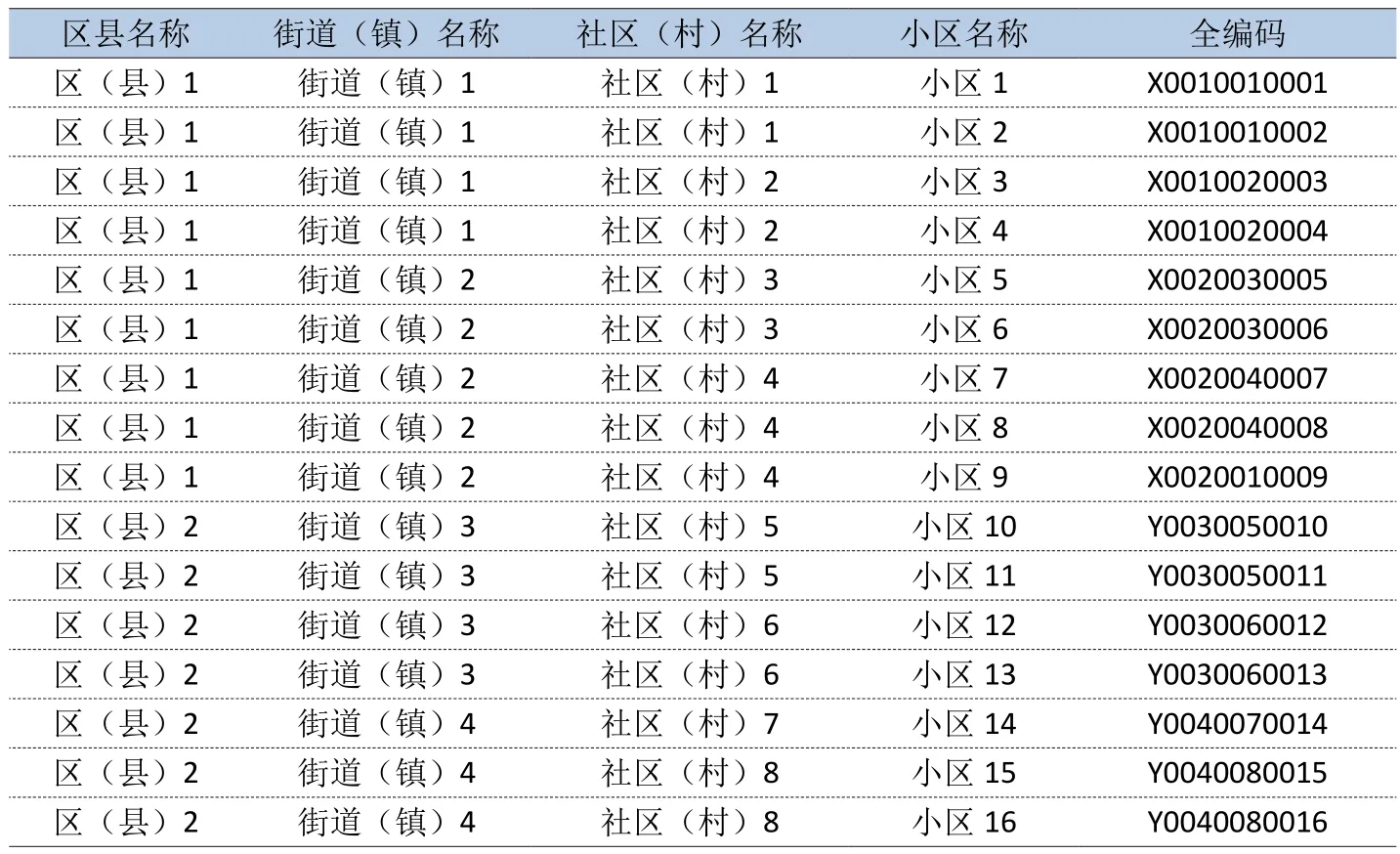
表3 区、街道(镇)、社区、小区层级编号样例
其中11位编号对应关系为:第一位为区(县)编码,第二位至第四位为街道(镇)的编码,第五位至第七位为社区(村)编码,第八位至第十一位为小区编码。
热线数据经过处理后的地址结构化样例如表4所示:
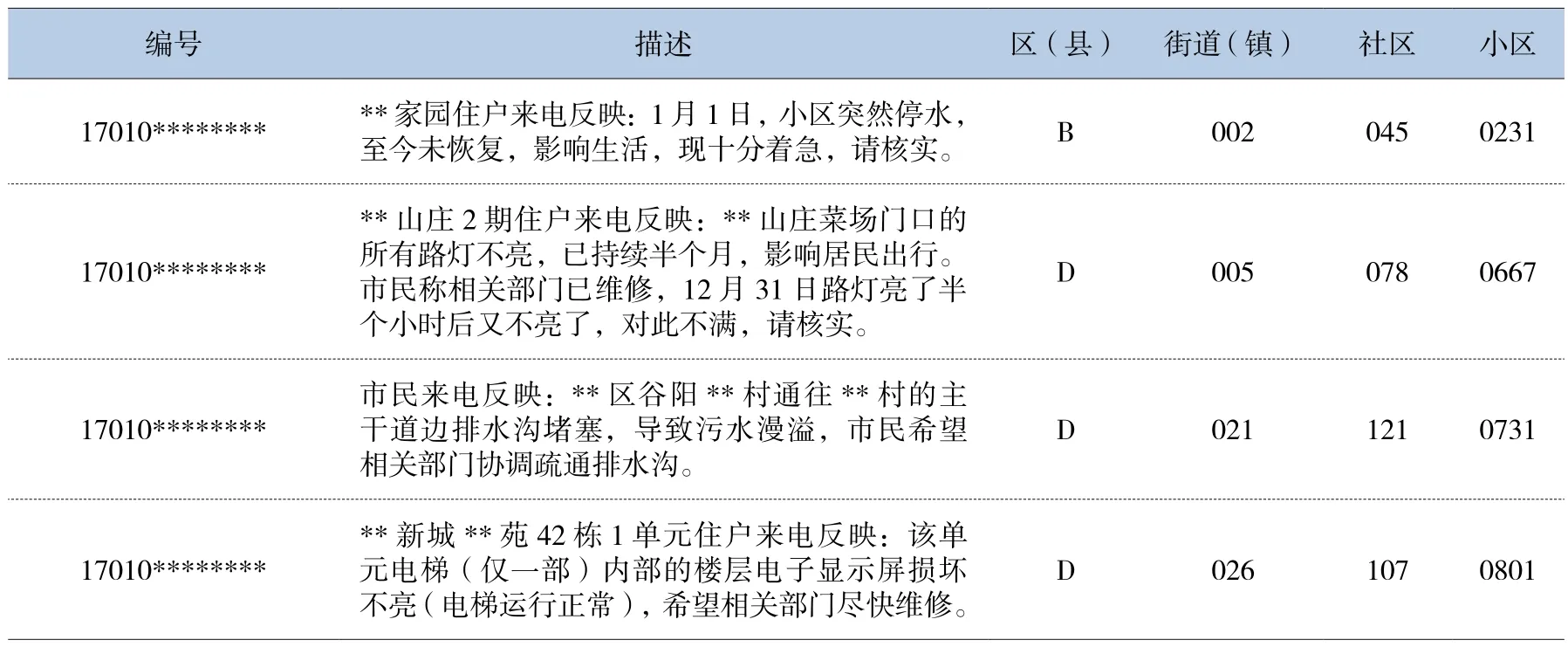
表4 12345系统数据地址结构化处理后样例
通过数据处理,可以清晰定位热线发生或投诉对象的地点。
2.4 统计分析
在完善和提取完所有信息后,数据变为以下表5样式,根据此数据,可以进行相关统计分析和挖掘。
表5 12345系统数据全结构化处理后样例
基于以上数据,可以根据各种维度进行不同分析。下面描述两个具体需求的实现。
统计某某区在某某时段发生的事件排名;根据区域和时段利用SPSS软件建立相应交叉列联表,并根据交叉列联表得出相应的事件排名。
相应的列联表如下表6所示:

表6 某某区在某某时段发生的事件排名
统计某个时段发生某个事件的街道排名:根据时段和街道,利用SPSS软件建立相应交叉列联表,并根据交叉列联表得出相应的排名。
相应的列联表如下表7所示:
表7 某某区在某某时段发生的事件排名
2.5 相关性挖掘
市民反映的问题五花八门,但是在众多的现象背后,肯定有一些问题存在着因果、依存关系。在处理市民的问题时,往往有这样的情形,若一个问题解决,若干个相关的问题得到缓解;一个问题没有解决,若干个问题仍处于待解决的状态。因此,找到问题背后的深层联系显得非常重要。
根据数据特点,将问题细分小类作为主ID,把事件按照发生时段的次数、区域次数等作为特征值,样例如表8所示:
表8 事件相关性挖掘数据源表
对上述变量使用Python进行聚类分析。聚类分析是研究多要素事物分类问题的数量方法.基本原理是根据样本自身的属性,用数学方法按照某种相似性或差异性指标,定量地确定样本之间的亲疏关系,并按这种亲疏关系程度对样本进行聚类。常见的聚类分析方法有系统聚类法、K-均值法和模糊聚类法等。
根据聚类的K-均值法的聚类分析过程及结果如下:
采用K-均值法的聚类方法进行聚类,表8中共有7个问题,即为7个样本;每个样本有8个特征,即为8个特征值,计算这7个样本的聚类结果:
第一步:随机选择K个初始质心,即将所有样本聚到K个分类上,经多次实验取K=4;
第二步:分别计算所有样本到这K个质心的距离;
第三步:如果样本离质心Si最近,那么这个样本属于Si点群;如果到多个质心的距离相等,则可划分到任意组中;
第四步:按距离对所有样本分完组之后,计算每个组的均值,作为新的质心;
第五步:比较新的聚类中心与老的质心之间的距离,若大于设定的阈值,则跳到第二步; 否则输出分类结果和质心,算法结束。经过聚类算法,将7个问题分为了4类,如表9所示。

表9 事件聚类分析结果
3 数据分析结果对于民生改善的案例
3.1 寻找违建点
在1-6月的某某市投诉和举报问题的排名上,违建问题共4733条,其中违建问题(已建成)总件数为2344件,而在建2389件,若和并计算,则为投诉举报第一大问题。
根据在文本中获取的有效地址,并在树形地址库进行匹配,得出违建在建问题和违建已建成问题按照行政区进行分类,发现区1无论建成和在建问题均投诉最多,区2的投诉最少,区3的违建建成问题较为严重。而对街道一级继续进行分析,可以得到每个街道的问题分类。
从绝对数量上可以看到,已建成违建、在建违建问题的解决率最高的地方均为区2,并且其投诉也最少,说明区2在问题总数、问题解决方面均较为优秀。而已建成违建、在建违建问题解决率最低的为区1,而其问题的总数也较多,其投诉总量已达1300条,平均一天就有10条投诉该区的违建问题。究其原因,区1面积大,厂房多,厂房的违建也多,其举报多、拆除难,最终导致了区1的违建问题投诉最多。区1违建的分布区域热力图如图2所示(图2仅为展示用,与实际场景及问题无关)。
图2 违建的分布区域热力图(仅做示意,为随机生成数据)
3.2 寻找噪音问题来源
随着城市的发展,噪音问题变得越来越严重,目前被认为是当今社会第三大公害。通过使用自然语言分析方法,解析动作描述词,得到镇江噪音问题的投诉描述,如图3所示:
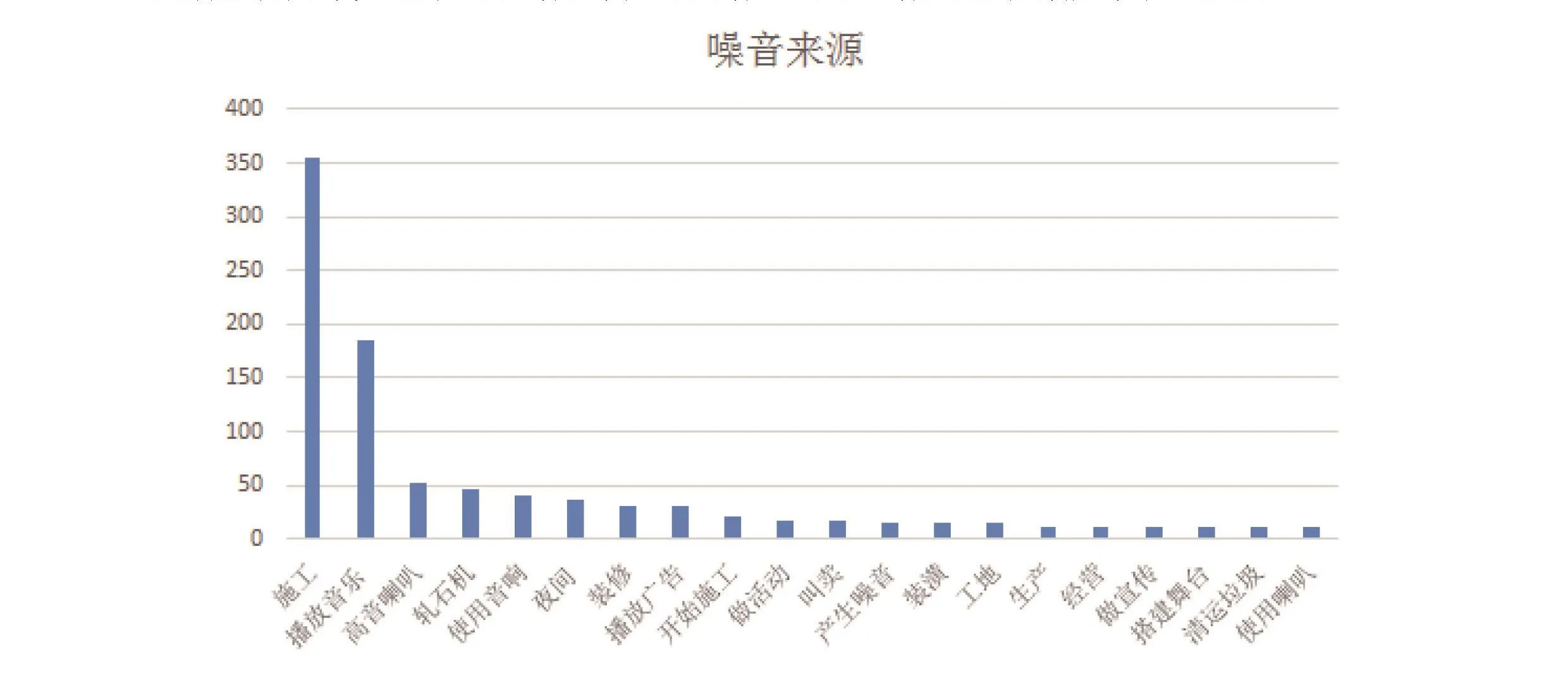
图3 噪音问题的投诉描述
从上图可以看出,通过文本解析投诉内容,施工、播放音乐、高音喇叭、轧石机、使用音响占据了动作关键词。施工、轧石机和施工相关,属于建筑噪音,而播放音乐、高音喇叭、使用音响主要是音响类的噪音,和小区广播、商业经营有关系,属于生活噪音。从投诉的关键词来看,建筑噪音和生活噪音是噪音问题的主要组成部分。
4 结语
本文依据12345热线数据,通过自然语言分析技术,对人工记录的数据进行深度文本分析处理,提取原始数据中的时间、事件、地址以及用户投诉的关键信息,并应用分析统计方法和数据挖掘方法,找出问题,定位问题,找寻不同问题之间的相关性,从而得出典型问题发生的原因,并提供合理的意见建议。本文充分应用了数据分析的技术方法来研究数据背后反映的社会生活问题,从而帮助更准确高效地解决问题,服务于社会。
