基于EMD-IGA-SELM的池塘养殖水温预测方法
2018-12-04袁永明李光辉张红燕
施 珮 袁永明 匡 亮 李光辉 张红燕
(1.中国水产科学研究院淡水渔业研究中心, 无锡 214081; 2.江南大学物联网工程学院, 无锡 214122;3.江苏信息职业技术学院物联网工程学院, 无锡 214153)
0 引言
水温是水产养殖中影响鱼类生长状况、生长质量的关键因素之一,在工厂化养殖中水温的作用更为突出[1]。高密度的养殖环境、大量的饵料和狭小的养殖空间对水质、水温的要求更为严格。水温的突变会对水体中pH值、溶解氧、氨氮等产生影响,影响鱼类适宜的生存环境[2]。
为了对水体温度进行准确预测,近年来很多学者进行了相关研究[3-6,8-12],其预测方法包括传统数理统计法和人工智能方法。基于水温机理的数理方法对影响水温变化的机理和因素进行了分析,研究不同水层条件、时空分布、流速、流量等对水温的影响[3-4],利用传热传质理论、水文气象理论、二维和三维模型等构建水温预测模型[5-6],这些方法虽然能够对水库、水槽的水温进行有效预测,但预测模型复杂,参数多且难获取,在水产养殖上难以应用。基于数据挖掘的非机理方法一般通过大量数据构建数学模型,获得水温与相关影响因子的关系,捕捉水温变化规律。而针对大量数据样本构建的数学模型较多使用机器学习算法,包括贝叶斯算法、支持向量机、神经网络等[7]。贝叶斯算法能够处理不确定性的信息数据,但需要有处理目标的先验知识,获取目标的先验分布[8-9];支持向量机(SVM)能够较好地拟合处理非线性系统问题,且泛化性能较强,但算法复杂,参数较多且难以确定[10-11]。传统的神经网络与SVM相似,适用于处理非线性问题,其缺陷也表现在算法复杂度和参数设置及核函数确定等问题上[12]。极限学习机(ELM)不同于传统的神经网络,其结构较为简单,拥有快速学习能力和强泛化能力[13],已广泛应用于各类预测、分类和识别问题中[14-16]。然而单一的ELM预测精度有限,在初始参数和激活函数上仍有优化和改进的空间。
在前人研究的基础上[12,17-18],本文提出基于EMD(经验模态分解)-IGA(改进遗传算法)-SELM(改进极限学习机)的池塘水温预测模型。该模型利用EMD对水温原始数据进行不同尺度的分解,挖掘数据特征,利用改进的遗传算法获取最优初始参数,避免组合优化算法的抖振问题和寻优过程的早熟问题,使用模型新的激活函数,在EMD分量中进行模型训练和预测,叠加后最终获得水温预测结果。
1 材料与方法
1.1 研究区域
实验地点无锡市位于东经120.18°、北纬31.34°。在该养殖区域内选取长110 m、宽45 m、水深约1.5 m的池塘作为实验池塘。在池塘内搭建3个高密度水泥槽,每个水槽长9 m、宽3 m,投放5 000尾罗非鱼鱼苗,鱼苗长度约3 cm。在高密度水泥槽中使用工厂化循环水养殖技术,并采用微孔曝气增氧和气提式推水装置进行增氧。
1.2 数据采集
实验数据采集装置使用淡水渔业研究中心智能渔业物联服务中心研制的水产物联服务远程监控系统平台采集工厂化池塘养殖中的水质数据和自动气象站监测数据,其系统架构图如图1所示。该系统对溶解氧含量、水温、pH值、气温、气压、湿度、雨量等水产养殖的水质环境数据进行在线监测。通过系统的感知层采集数据,经系统传输层传输至系统应用层。水下传感器放置深度为0.5 m,气象环境监测传感器集成在自动气象站中,所有获取的数据在应用层进行分析和处理,为用户的控制决策提供依据。
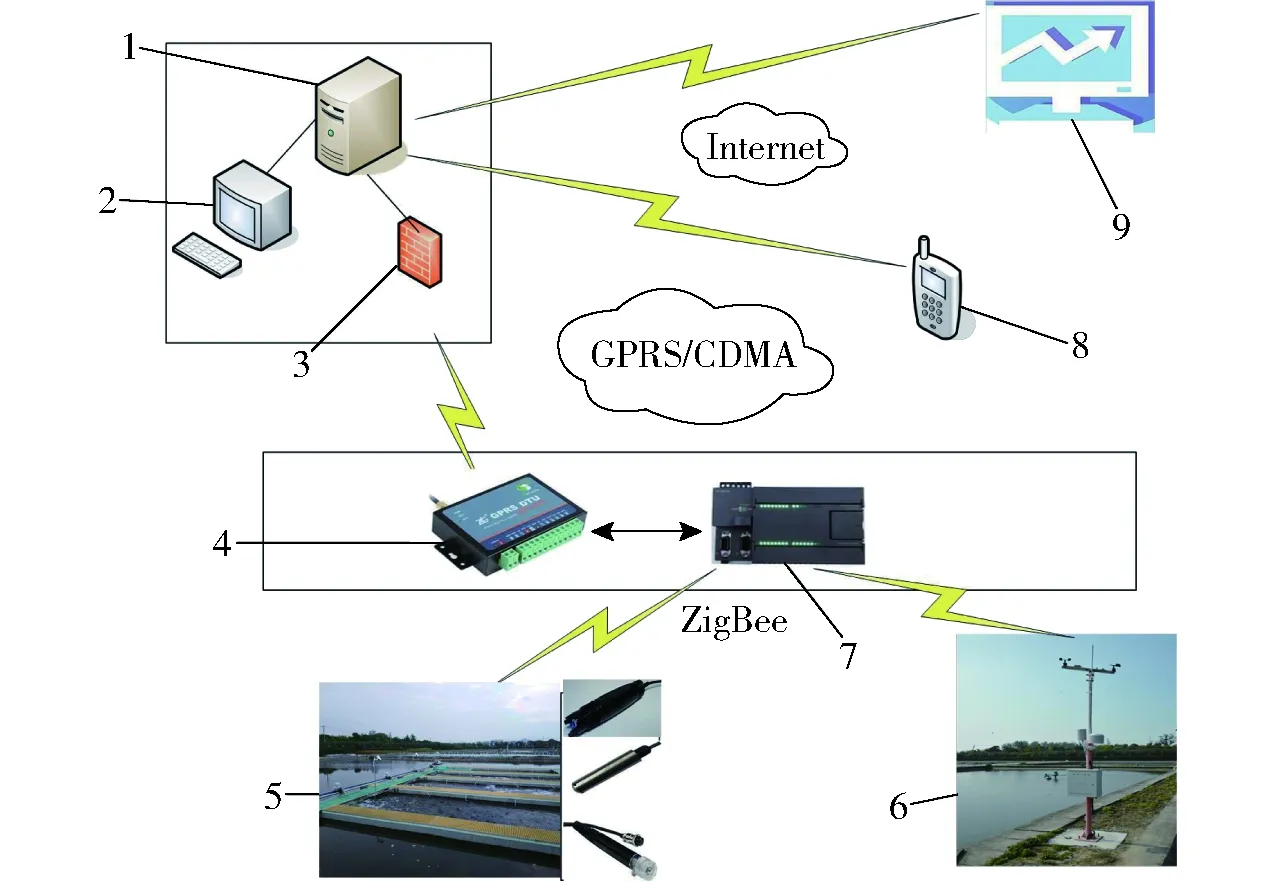
图1 系统架构图Fig.1 Structure diagram of monitoring system1.服务器 2.监测系统 3.防火墙 4.DTU数据传输单元 5.池塘水质传感器节点 6.自动气象站 7.PLC控制器 8.手机终端 9.PC终端
1.3 研究方法
1.3.1经验模态分解
EMD通过将信号分解成一系列简单的本征模态分量(Intrinsic mode function,IMF)和残量r,各IMF分量之间相互独立,从而获取信号的特征,并广泛地应用在非平稳信号的分析处理中[19]。在实际应用中,对池塘水温序列{x(t)|t=1,2,…,T}(t表示时间序号)的EMD算法步骤如下:
(1)对于x(t)序列,首先获得它的极大值点和极小值点。利用三次样条插值法将所有极大、极小值连接,形成上包络线xmax(t)和下包络线xmin(t)。
(2)计算xmax(t)和xmin(t)的均值m(t)和差值h(t)。将h(t)作为一个获取的新数据序列,重复k次步骤(1),计算得到hk(t),当满足Rk小于设定阈值时,则hk(t)成为一个IMF,公式为
(1)
(3)计算得到第1个IMF分量后,从原始水温序列x(t)中减去它,获得差值序列r1(t)。重复上述步骤,依次获得各IMF分量和余项rn(t)。rn(t)为一个单调函数,且小于设定的阈值,公式为
(2)
式中Fi(t)——各IMF分量
1.3.2改进的遗传算法
遗传算法(Genetic algorithm, GA)是一种模拟自然界遗传机制和生物进化论而形成的并行随机搜索最优化方法[20]。该算法主要通过选择、交叉、变异等遗传操作,使群体逐代进化,直到满足进化终止条件才结束。传统的遗传算法在全局寻优过程中都是基于交叉操作和变异操作,且变异操作是在交叉操作的基础上进行的。本文将混沌系统的随机性[21]引入交叉和变异操作中,将生物进化看作为随机性和反馈作用的结果,提出改进的遗传算法(Improved genetic algorithm, IGA),改进内容如下,以期避免遗传算法的早熟问题。
(1)交叉操作
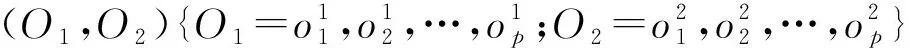
(2)变异操作
本文中,根据设定的变异率,随机获取2~p-1之间的两个正整数c、d。对c、d对染色体上相应位置的基因进行变异操作,利用混沌序列把c、d位置上的基因换成新的基因值,获得新的染色体。
改进的遗传算法将变异操作与交叉操作拨离开,使二者独立并列进行,并在具体遗传操作中,引入混沌序列来确定交叉点,利用单点交叉的低改动性,削弱和避免遗传算法组合优化问题中的寻优抖振问题。利用混沌序列完成染色体中的多基因变异过程,进而避免遗传算法的寻优早熟问题。
1.3.3改进激活函数的极限学习机
ELM是一种前馈神经网络学习算法,算法具有很好的全局搜索能力[22],且算法的参数一经确认,则训练过程中无需调整。与其他机器学习算法相比,ELM具有学习效率高、泛化性能好等优点。
在本文的池塘水温训练样本(xi,yi)中,设ELM有u个输入节点,L个隐含层节点,q个输出节点,激活函数为g(x),则xi=[xi1xi2…xiu], 网络输出可表示为
(3)
式中wj——第j个隐含层节点与输入节点的权值向量
bj——第j个隐含层节点的阈值
βj——第j个隐含层节点与输出节点间的权值向量
N——样本个数
激活函数g(x)是ELM中影响网络性能的关键因素,适宜的激活函数能够提高ELM的精准度和泛化性。Sigmoid函数是ELM中传统的隐含层激活函数,它是一种采用双侧抑制的判别函数。然而当遇到广义Hop-world问题时,其函数逼近值为单调的,则双侧抑制方式会增加废运算[23],此时则需要单边抑制来完成值的判别。修正线性函数作为一种新型激活函数正在被广泛地应用于深度学习领域[24]。其产生的修正线性单元(Rectified linear units, ReLU)被定义为
g(x)=max(0,x)
(4)
ReLU函数为分段函数,该函数形式简单、运算快,泛化性较Sigmoid更好,但函数的稀疏性会减小函数的预测能力,降低网络平均性能[25]。文献[26]中提出了Softplus函数,该函数为ReLU的非线性平滑表示。Softplus函数是非线性连续可微的,且相比较于Sigmoid函数更接近生物学激活模型,能较好地避免ReLU的强制稀疏性,提高网络的平均性能。在本研究中,选用Softplus函数作为ELM的激活函数,函数定义为
g(x)=ln(1+ex)
(5)
2 EMD-IGA-SELM的池塘养殖水温预测模型
2.1 数据预处理
由于水质传感器常年放置在水下环境中,受到水体腐蚀作用和其他环境因素作用,会使得传感器在数据采集过程中发生偏差,传感器精度受到影响。同时,网络的传输也会产生数据的延迟和丢失,这些问题都会使得采集到的数据发生丢失和数据异常,针对这类问题,需要进行数据预处理来提高数据质量。
2.1.1数据校正
对短时间内发生丢失问题的数据,使用线性插值法[27]来完成缺失数据的插补,公式为
(6)
式中xk、xk+j——第k和第k+j时刻采集的传感器数据
xk+i——第k+i时刻传感器丢失数据
基于相似时间段内天气条件相似概率较高,水体的温度在相似天气条件下也具有一定规律,故以相似时间相似天气为评价对象,将监测系统采集的气象指标:大气压强、空气相对湿度、空气温度、空气中CO2浓度、照度、光合有效辐射度、辐射照度、风速和风向等9项指标建立评估体系,采用因子分析法评估综合天气指数
(7)
其中
Fij=∑xiMaMj
式中Windex——综合天气指数
Wj——因子分析中提取的公共因子的方差贡献率
Fij——各公共因子得分系数
xiM——第i个公共因子在第M个天气指标上的实际值
aMj——第M个天气指标在第j个公共因子上的得分系数
利用水质监测数据和气象环境数据在时间上的连续性,设定这些采集数据任意时刻前后差值超过10%时,判定传感器发生偏差,数据需要进行误差校正[28]。遵循综合天气指数临近原则,将这些发生偏差的数据替换为综合天气指数相近条件下对应的水质数据,并保证替换后的数据前后差值不超过10%。另外,对长时间丢失的数据,选择相似时刻、天气指数临近的对应水质数据插补丢失数据,同时确保插补数据满足差值不超过10%的条件。
2.1.2数据归一化
为了消除不同度量标准的数据间的量纲差异问题,对所有经过校正的数据进行归一化处理,在M个指标的数据集中,利用Z-score数据标准化方法对N组数据进行对应标准化处理,即
(8)
式中Zmn——归一化后数据
xMN——校正数据

SN——xMN的数据标准差值
2.2 池塘水温预测模型
2.2.1预测指标体系构建
由于水体环境因子和气象环境因子对水温的变化均具有一定的影响,本文选择监测指标中水温、pH值、大气压强、空气相对湿度、空气温度、空气中CO2浓度、照度、光合有效辐射度、辐射照度、风速和风向等11项指标进行关联分析。在实验的1008组数据中,采用Person相关分析对这些指标与水温的相关性进行分析。经计算后可得,水温与pH值、大气压强等10项指标的相关系数分别为0.512、0.597、-0.445、0.601、0.435、0.112、0.181、0.105、0.203和-0.134。由此可知水体环境因子和气象环境因子与水体温度均具有一定的关联性,故选择这10项指标构建池塘水温的预测模型。
2.2.2预测模型设计
由于传统的ELM网络模型的初始参数存在随机性,且在激活函数的选择上并未考虑适宜性,而改进的遗传算法能够解决寻优抖振和早熟问题,确定最佳权值、阈值,Softplus函数提高ELM泛化性。同时,针对原始监测数据构建的预测模型易同质化监测数据的不同尺度信息特征,不能充分发现时序数据的时频特征,影响预测模型的性能。本文将EMD、IGA和ELM 3种算法结合起来,提出基于EMD-IGA-SELM的池塘养殖水温预测模型。
在建模的过程中首先采用EMD对池塘水温时序序列进行自适应地多尺度分解,获得不同频率的信号分量和余项;然后在分解后的各分量中采用IGA-SELM进行建模预测;最后将各分量预测模型的预测值进行叠加获取最终预测值。其预测流程图如图2所示,基于EMD-IGA-SELM的池塘水温预测步骤如下:
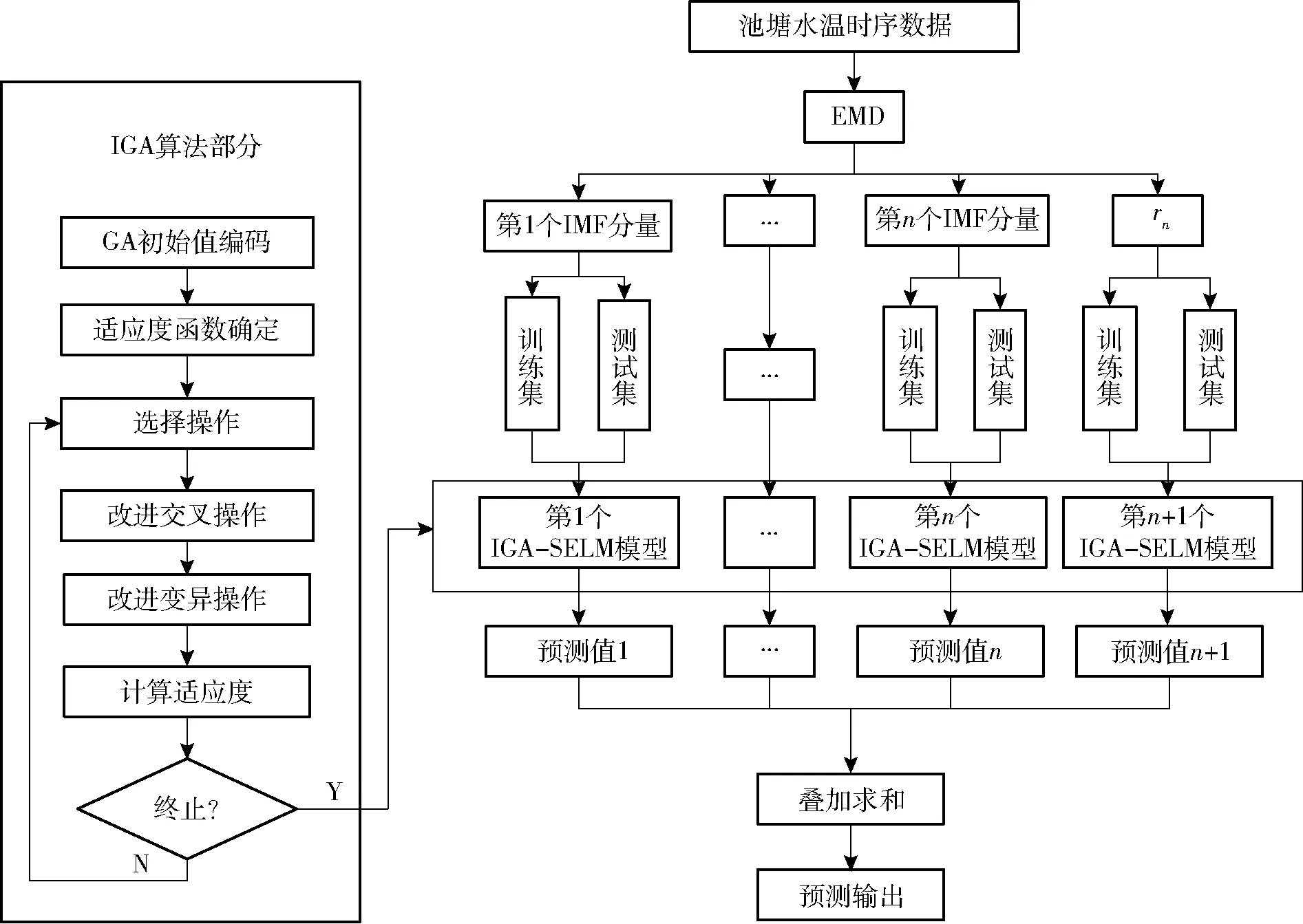
图2 EMD-IGA-SELM预测流程图Fig.2 Flow chart of EMD-IGA-SELM prediction model
(1)池塘水温时序数据分解。利用EMD对x(t)进行分解,获得n个IMF分量和一个余项rn。
(2)构建训练、测试样本集。在IMF分量中,构建各分量训练样本集、测试样本集的输入量和输出量。
(3)构建各分量的优化极限学习机训练、预测模型。在改进的遗传算法中,计算改进遗传算法中的适应度函数;设置初始种群规模size和最大进化代数maxgen,对种群中的个体进行选择、改进的交叉和变异等遗传操作,最终确定全局最优的适应度;利用最优适应度获得最优权值abest和阈值bbest;设定ELM网络的激活函数为Softlus,由abest和bbest计算ELM的输出矩阵H和输出权值β,确定SELM网络结构;利用IGA方法对每个SELM模型参数迭代寻优,在每个IMF分量和余项rn内建立最优参数的SELM拟合预测模型,获得各分量的预测结果,公式为
(9)

(10)
(11)
式中yi(t)——t时刻的实际值
H+——输出矩阵H的广义逆

Y——输出矩阵
(4)预测结果输出。对各IMF分量和余项rn的预测结果进行累加求和,获得池塘水温的最终预测结果。
2.2.3模型参数设置
在EMD-IGA-SELM预测模型中,分别对改进的遗传算法部分和ELM神经网络参数进行如下设置。
(1)遗传算法部分。设置IGA算法的初始种群规模为10,迭代次数为50。依据多次运行均方误差最小的原则,确定交叉概率为0.1,变异概率为0.1。
(2)ELM神经网络部分。对ELM参数进行设置,输入节点数为10,输出节点数为1。为了避免出现“欠适配”、“过适配”的问题,依据“试错法”,最终设置各IMF分量ELM网络的隐含层节点数分别为28、19、23、31、29、31,由此获得各分量ELM神经网络的结构模型。
3 实验结果与分析
3.1 实验数据源
以无锡市南泉罗非鱼养殖基地的池塘水温为研究对象,基于1.2节中物联服务水质监控系统,每10 min采集一组数据,将获取的所有气象站数据和水体环境数据作为预测模型的数据样本。实验数据起始时间为2016年7月1—7日,将前6 d的864组数据作为水温预测的训练集,最后1 d的144组数据组成预测集。在构建的预测体系中,确定pH值、大气压强、空气相对湿度、空气温度、空气中CO2浓度、照度、光合有效辐射度、辐射照度、风速和风向为输入变量,水温为输出量,系统运行环境为Matlab 2014a Microsoft Windows 7, 处理器为3.4 GHz Core(TM), 内存为4.0 GB。
3.2 结果分析
3.2.1基于EMD的水温多尺度分解
按照2.2.2节的EMD-IGA-SELM模型的步骤,以1 008组水温时序数据为对象进行EMD分解,获得5个IMF分量和1个余项,分解图如图3所示。

图3 水温EMD分解图Fig.3 Decomposition of water temperature by EMD
从图3可以发现,池塘水温时序序列有明显的多尺度特征,5个IMF分量呈现高低变化不同波动尺度的信息。其中,IMF1的频率较高,能体现出原始时序数据的随机噪声信息;rn余项频率较低,变化平稳,体现水温时序的周期性和趋势性信息,反映水温总体变化特征。
3.2.2预测结果分析
在EMD分解的基础上,采用IGA-SELM分别对各IMF分量和余项构建预测模型,得到EMD-IGA-SELM的池塘水温预测结果。同时,为了对预测模型的性能有清晰的了解,本文设置了对照实验。将IGA-SELM、GA-SELM和GA-ELM作为参照模型,分析和对比EMD、IGA和SELM对预测性能的影响。在IGA-SELM中设置其隐含层节点数为28,激活函数为Softplus,IGA算法的参数设置同2.2.3节中遗传算法部分;GA-SELM和GA-ELM均使用标准遗传算法,GA-ELM中激活函数设置为Sigmoid,其他参数设置相同。各模型的预测值与实际值对比结果如图4所示。

图4 各模型预测值与实际值对比Fig.4 Comparison of original data and predictive values of three models
图4显示,各预测模型均能在不同程度上较好地实现池塘水温的预测,水温的预测变化趋势与实际值变化趋势较为一致,但预测效果存在一定的差异。就整体预测结果而言,EMD-IGA-SELM的预测结果比其他3种模型的拟合效果更好,变化起伏更小,预测效果更稳定,全局看来无较大起伏的波动点。EMD-IGA-SELM与IGA-SELM的预测趋势较为相近,二者曲线变化方向较一致,这两个预测模型均使用IGA优化算法,且激活函数相同。而GA-SELM与GA-ELM也有较大程度的一致趋势,二者在ELM均使用标准算法,但激活函数不同。从图中还可以发现,各预测模型均不同程度的在08:00—13:00和18:00—22:00时段内呈现相对较大的起伏,联系实际情况可知,这两个时段分别为光合作用变化较大的时间段,池塘内浮游植物和微生物发生光合作用,水温的变化幅度最大。由于水温随空气温度的变化具有延时性,在变化幅度较大的时间段中,水温预测的难度相对较大。
为了对这4个模型进行综合的性能对比,本文选择均方根误差(Root mean square error,RMSE)、平均绝对百分比误差(Mean absolute percent error,MAPE)、平均绝对误差(Mean absolute error,MAE)和运行时间[22]4项指标进行比较,其预测性能结果如表1所示。

表1 预测模型的预测性能对比Tab.1 Performances comparison of four predictive models
从表1可以发现,4个模型的预测准确率达到了99%以上(MAPE均小于0.01)。EMD-IGA-SELM模型的精度指标MAE、MAPE、RMSE分别为0.123 3℃、0.004 3和0.147 8℃。该模型预测精度与其他方法相比有很大的改进,仅MAPE相比另外3个模型分别降低12.25%、20.37%和39.44%。在运行时间上,EMD-IGA-SELM较其他3种模型分别多耗时4.55、3.43、1.88 s。水温时序数据的EMD分解降低了不同尺度特征信息间的相互干扰,提高了预测模型的精度,但是数据EMD分解的过程也消耗了时间。改进的遗传算法可以有效地避免遗传算法的早熟问题,提高算法的效率。Softplus激活函数能提高ELM的精度和效率,适宜使用在水温的预测模型中。
为了验证本文EMD-IGA-SELM的预测性能,分别采用已经被应用的EMD-ELM和GA-BP模型对池塘水温进行预测。其中,GA-BP中BP的网络结构为10-6-1,训练次数为1 000,训练目标为0.1,激活函数为Sigmoid;EMD-ELM中,ELM的神经元设置、EMD分解后的ELM网络设置同2.2.3节,激活函数为Sigmoid。由此获得3个预测算法的性能,如表2所示。
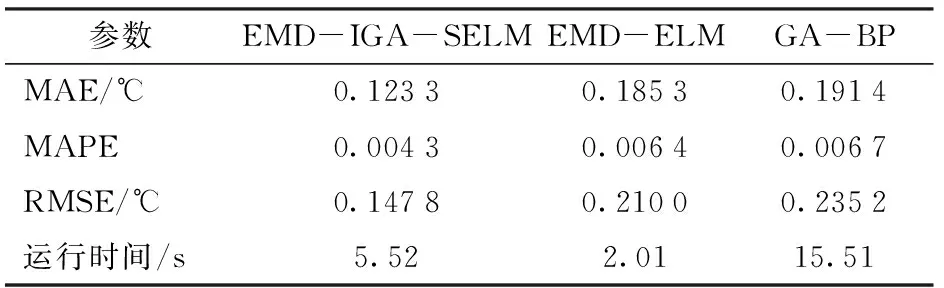
表2 不同水温预测模型的预测性能对比Tab.2 Performances comparison of three existing models
由表2可以发现,EMD-IGA-SELM的预测精度与EMD-ELM、GA-BP相比有明显的提升,在MAE指标上,EMD-IGA-SELM比EMD-ELM和GA-BP分别降低了33.46%、35.58%;在MAPE上,EMD-IGA-SELM比EMD-ELM和GA-BP分别降低了32.81%、35.82%;EMD-IGA-SELM的RMSE比EMD-ELM和GA-BP分别降低了29.62%、37.16%。EMD-IGA-SELM的运行时间较EMD-ELM慢了3.51 s,较GA-BP快了9.99 s。
综上所述,EMD-IGA-SELM的综合性能较好,有一定的优势,能够解决ELM模型中参数随机的问题,可以充分发掘水温数据的多尺度特征。将EMD与IGA、SELM结合在一起可以有效地提高水温预测模型的精度,克服单一模型存在的低精度问题,为工厂化的池塘养殖提供水温预测的方法,为实际生产中的水质监控和管理提供依据。并且在实际生产过程中,可以根据系统预测精度和响应时效要求选择符合生产需求的预测模型完成水温的预测。
4 结论
(1)采用改进的遗传算法对ELM的输入权值和隐含层阈值进行优化,建立IGA-SELM预测模型,在多次实验的基础上确定预测模型的隐含层节点数。改进的遗传算法引入混沌序列,有效地解决了ELM优化模型中寻优抖振,避免出现早熟问题。获得的最佳权值和阈值能够避免ELM随机参数的不稳定性,提高预测模型的准确性。
(2)使用Softplus激活函数替换传统ELM中的Sigmoid函数,不仅提高了ELM泛化能力,还提高了预测精度和效率。
(3)采用经验模态分解对水温时序数据进行多尺度分解,获得多个IMF分量和余项,构建各分量中的预测模型,捕捉到水温数据特征,虽增加了一定的时间成本,但提高了水温预测模型的精度,可根据需求供不同系统选择使用。
