基于协同过滤算法的电影推荐系统的设计
2018-11-29梁永恩
梁永恩
(广东白云学院大数据与计算机学院,广州 510450)
0 引言
在当今信息过载的时代,如何从海量的电影中发现感兴趣的电影,是每个电影爱好者(用户)关心的问题。在已有明确需求的情况下,用户可以借助互联网搜索引擎通过搜索关键词获取到较好的筛选结果。但是,如果用户没有明确的需求时,没法提供合适的关键词,就难以通过这种方式获得自己感兴趣的电影。当然,用户可以通过电影网站的各类排行榜获得热门电影的推荐,但这种推荐往往由于推荐的种类和内容有很大的局限性,新颖性不足,难以满足用户的个性化需求。
个性化推荐系统是这个问题的有效解决方案,本文通过分析用户的历史观看电影数据,挖掘用户的个性化需求,为用户提供个性化的电影推荐信息服务。
1 推荐系统现状分析
根据实现算法的不同,当前主流的推荐技术可分为三种:基于内容的推荐、基于关联规则的推荐和基于协同过滤的推荐[1]。①基于内容的推荐是根据内容本身的属性(特征向量)所作的推荐。②基于关联规则的推荐是基于物品之间的特征关联性所作的推荐。③基于协同过滤是根据用户已有的历史行为作分析的基础上而作的推荐[2]。三种推荐算法各有优缺点,基于内容的推荐的优点是不需要其他用户的数据,可通过列出推荐物品的内容特征,解释为何推荐那些物品,缺点是要求内容具有良好的结构性,并且用户的兴趣要能够用内容特征形式来表达。基于关联规则的推荐的优点是查准率较高,其缺点算法复杂,容易生成无效的规则。基于协同过滤算法的优点是算法简单、查准率较高,能发现读者新的阅读兴趣,缺点是存在数据稀疏、冷启动等问题。
协同过滤算法[3]是目前最流行的推荐方法,在学术界和业界都得到了广泛应用。它的最大优点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影等。协同过滤算法分为两类:基于用过户的协同过滤和基于物品的协同过滤算法。就电影推荐系统来说,由于电影的数量大大超过用户的数量,同时电影数据相对稳定,因此计算电影的相似度不但计算量小,同时不必频繁更新。本文正是采用基于物品的协同过滤算法实现电影推荐系统。
2 基于物品的协同过滤的电影推荐系统
基于物品的协同过滤算法(简称ItemCF算法)不利用物品的内容属性计算物品之间的相似度,它通过分析用户的行为记录来计算物品的相似度,该算法基于一个假设:物品A和物品B具有很大的相似度是因为喜欢物品B的用户大多数也喜欢物品B。如表1所示,喜欢物品A的用户a和用户b都喜欢物品D,可以认为物品A和物品D具有很大的相似度,故将物品D推荐给同样喜欢物品A的用户b。
ItemCF算法分为两步:(1)计算电影之间的相似度;(2)根据电影的相似度和用户的观看历史,生成用户推荐列表。这里以MovieLens网站的MovieLens 1M数据集作为实验数据,该数据集包括了6040名用户对3900部电影的评分记录,一共有1000209条电影评分记录。基于这个数据集,实现Top-N推荐。
2.1 计算电影之间的相似度
令N(i)表示喜欢电影i的用户数,令N(j)为喜欢电影j的用户数。建立矩阵C,其中C[i][j]记录了同时喜欢电影i和电影j的用户数,将矩阵归一化可以得到电影之间的余弦相似度矩阵W。
C#的代码如下:


2.2 生成推荐列表
得到物品相似度后,再使用如下公式来度量用户u对电影j的兴趣程度Puj:
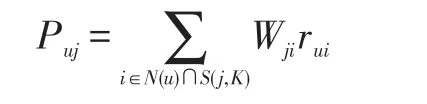
式中,N(u)是用户喜欢的电影的集合,S(j,K)是和电影j最相似的K个电影的集合,Wij是电影j和电影i的相似度,rui是用户u对电影i的兴趣(这里以用户u对电影i的评分来计算)。
C#的代码如下:


测试结果如图1所示。
3 结语
本文介绍了推荐系统的研究现状,结合电影推荐系统的特点,利用基于物品的协同过滤算法实现了个性化的电影推荐系统,后期可以混合专家推荐和标签推荐的方式提高推荐的效果。

图1 ID为3用户的电影推荐结果
