基于Django框架的智能图书推荐系统
2018-11-28贾昆霖蓝机满
周 君,贾昆霖,蓝机满,宋 艳
(1. 惠州工程职业学院,广东 惠州 516001;2. 中南大学 软件学院,湖南 长沙 410075)
目前,使用传统管理方法的图书馆面临着全面的转型与彻底的变革,全面数字化和自动化的图书馆管理方法正在逐步取代传统的图书馆管理技术[1-3]。然而,在转型过程中最新的管理方法和技术并不一定适应时代与社会的发展,图书馆管理技术的发展也需要不断地进行调整、优化与加强。所以,如何设计和实现人性化、智能化的图书推荐系统,成为了众多高校和科研单位的图书馆关注的问题[4-10]。
为了完成智能图书推荐系统的设计,本文首先全面分析了图书推荐系统的设计需求。在此基础上,以高等院校的历史借阅信息作为基础数据,引入了协同过滤算法,在Django框架平台上综合使用amCharts图表和D3.js可视化数据库等多种技术,设计了一个具有推荐排行、个性化推荐和数据同步等多项功能的智能图书推荐系统。同时,本文对该系统进行了详细的测试和验证。结果表明,该系统的所有功能,包括推荐、数据同步、管理和展现等均运行正常,且还具有较好的兼容性和稳定性。
1 需求分析
一般而言,一个智能化的图书推荐系统必须实现4个方面的功能,即系统内核、数据同步、前端面板和后台管理。
1.1 系统内核
图书推荐系统需要使用具有强大功能的系统内核,完成系统中图书的分类、排行等多种推荐功能。在本文中,图书推荐系统的内核需要实现热门图书排列、中图分类排行和智能化推荐。其中,热门图书排列功能主要指推荐系统需要精确统计借阅记录最多的100本图书,并显示排序结果;与之类似,中图分类排行功能是指系统需要将某一类别中借阅记录最多的10本图书列举出来,并显示该排序结果;智能化推荐功能包括两方面的内容:(1)系统需要读取和分析每个用户的借阅情况,为该用户推荐个性化的书籍;(2)系统需要对所有用户进行相似性分析,使用列表为用户推荐其可能感兴趣的书籍。
1.2 数据同步
在系统的所有功能中,数据同步功能需要实现借阅记录、用户信息、图书信息和数据整理存储等一系列的功能。其中,图书推荐系统与图书馆信息管理系统保持一致,定期更新所有图书的借阅记录和状态信息。同时,定期增加图书馆新增用户的信息,删除注销用户的信息,并将更新后的信息存入推荐系统的关系型数据库中。
1.3 前端面板
在系统的所有功能中,前端面板主要负责展示图书馆的中图分类示意图、图书借阅情况和图书用户关系图。其中,中图分类示意图是一种树状的图形。主要展示图书馆藏书的分类和体系,方便读者的查找与借阅;图书借阅情况主要展示图书的总借阅量、借阅记录、书籍信息等;图书用户关系图主要被用于显示读者的借阅记录、借阅数量和日志等。
1.4 后台管理
在图书推荐系统中,后台管理的功能主要包括中图分类、借阅情况、图书和用户等项目的管理。其中,中图分类管理是编辑和查询馆藏图书的中图分类信息;借阅情况管理主要是编辑、查询用户的图书借阅信息与记录。
2 架构设计
针对系统需要实现的所有功能,本文对图书推荐系统进行总体设计。根据上面对系统的需求分析,将推荐系统划分为系统内核、数据同步、前端面板和后台管理4个子模块。
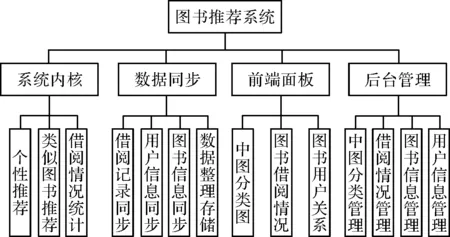
图1 图书推荐系统架构图
在此架构下,文中引入了基于Python语言开发的Django应用框架。该框架是一个优秀的开源平台,集合了消息传递、系统和用户管理等多种复用站点组件,减小了系统所需编写的代码数量,并大幅简化了网站的开发过程。另外,Django框架还将分离了系统的逻辑实现和前端展示,这进一步提高了系统开发的代码编写速度。
2.1 Django框架
开源的Django框架使用了比较常见的模型-模板-视图模式,也被称为MTV模式。使用该模式的目的在于控制系统内多个组件的耦合关系,保证各个组件的设计不影响其他组件的运行。其中,“M”、“T”和“V”分别是“Model”、“Templates”、“Views”的缩写。在该模式的作用下,Django框架的结构如图2所示。
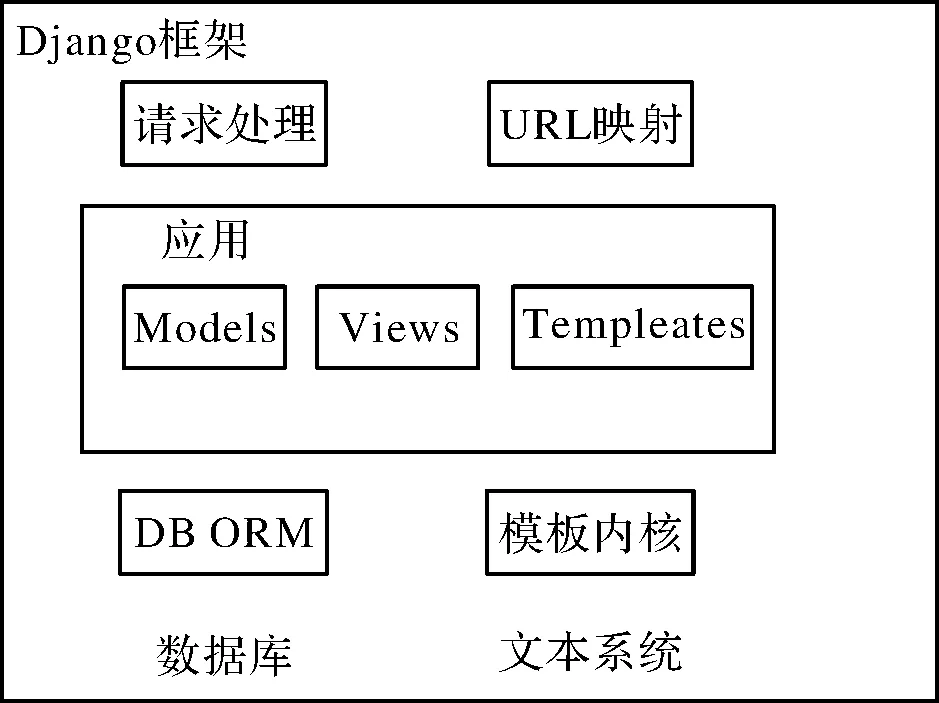
图2 Django框架结构图
由于Django框架是基于Python语言平台开发的,因此Django框架拥有功能多样的数据接口,设计者可以使用ORM机制定义具体的数据模型,从而大幅减小了数据库开发的编程压力。Django框架使用分发的方法设计URL映射,避免了系统乱码的出现。另外,该框架在系统内置的模板中增加了扩展功能,开发者能够自主设计页面样式、控制等系统的编码方式。该框架的网络请求处理,如图3所示。
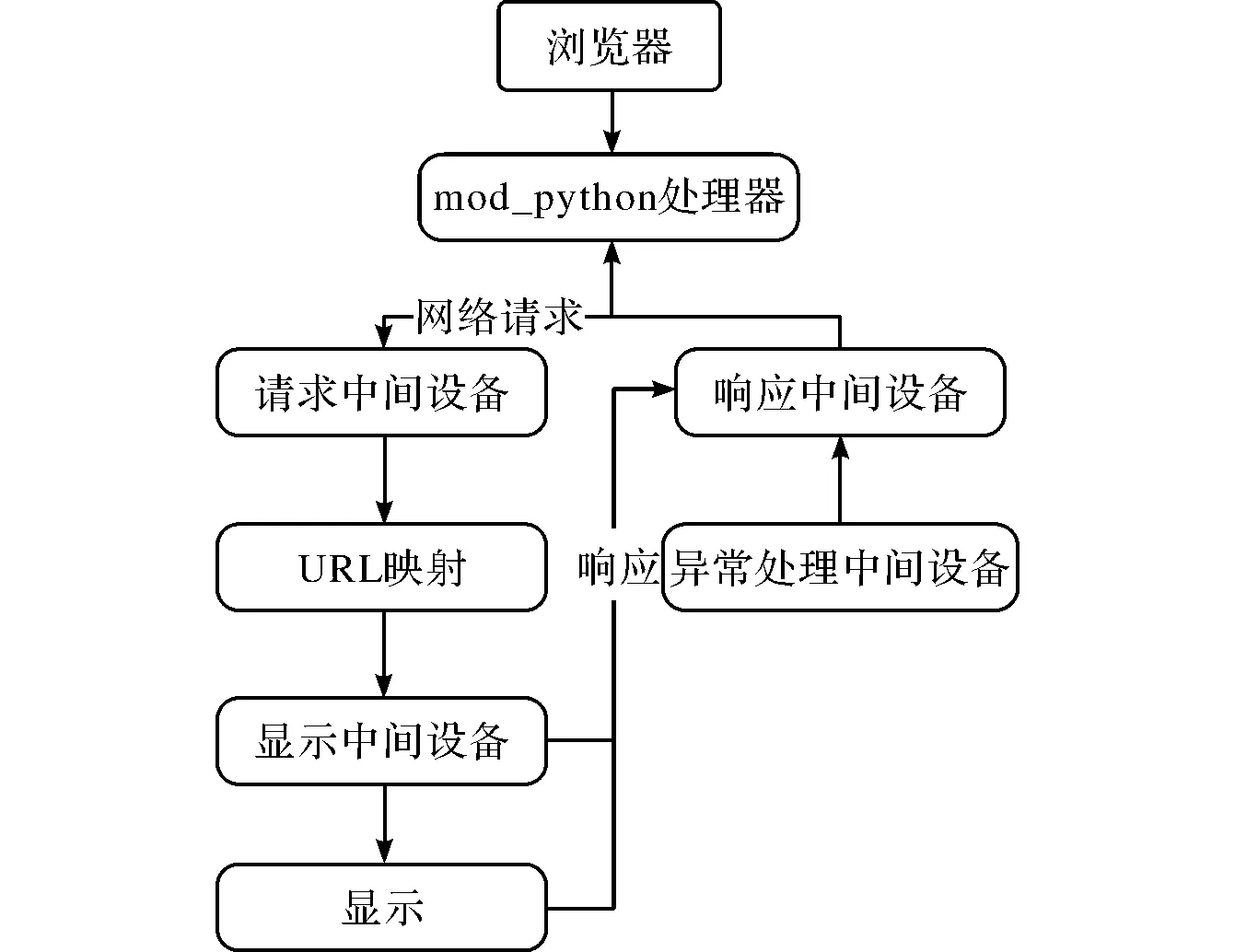
图3 系统的网络请求处理流程图
由图3可知,系统的用户使用浏览器提出网络请求,mod_python处理器对这些请求进行处理,同时发送到请求中间设备、URL映射、显示等设备进行具体处理。无法执行的请求提交异常处理中间设备进行判断,同时反馈给响应中间设备进行处理,再返回到mod_python处理器进行集中处理。
2.2 信息可视化
信息可视化是利用具有交互功能的计算机展示抽象数据的过程,这项技术涉及到心理学、语言学和计算机等多门学科,其核心内容主要包括视觉设计与人机交互。在本文中,主要使用了D3.js和amCharts组件完成信息可视化的功能。D3.js组件被广泛应用于信息可视化的领域中,D3表示“Documents”、“Driven”和“Data”,即文件、驱动与数据。D3.js组件能够将对应的数据发送到文档对象的模型,进而使用SVG和CSS等多种技术处理这些数据完成驱动的转换,最终实现抽象数据的可视化。该种组件具有三个优点,即计算资源需求少,运行效率较高、代码编写量较少,适用于大规模数据的可视化。
amCharts组件也是一种被广泛应用的信息可视化组件,是一个可视化的图标库,可以使用多样的形式展示大规模的数据。其形式包括但不限于面积、扇形、柱状等形状的图形。另外,该组件属于独立的JavaScript库,可以利用矢量图形的技术,完整实现渲染图标的功能,兼容IE、Opera和Firefox等多种主流浏览器。
3 系统实现
在完成图书推荐系统的设计之后,本文在PyCharm3.0开发平台上,使用Python语言完成了具体的编程,从而实现了完整的智能图书推荐系统。由于前端面板和后台管理模块只需要在Django框架上进行简单的修改,故在此对这两个模块的实现不再做详细介绍,重点叙述系统内核和数据同步的实现方法。
3.1 系统内核的实现
在图书推荐系统中,系统内核即推荐系统引擎,是系统最核心的模块。系统内核需要处理图书馆中图书的借阅数据,从而计算得到面向用户的推荐信息。本文在系统内核中使用了混合推荐算法,其流程图如图4所示。
在图书推荐系统内核工作时,对没有借阅数据的用户,协同过滤和内容过滤的算法均不能较好地发挥作用,系统将根据用户的归属信息查询该用户所属单位其他用户的借阅数据,得到借阅数量较多的图书信息,从而推荐给用户;对借阅数据比较少的用户,协同过滤算法难以产生准确地推荐信息,系统内核只能使用基于内容的推荐算法,详细地分析图书信息,建立所有图书的关键词和属性数据库,并利用大规模的数据分析用户的借阅习惯,使用余弦相似性的方法计算出相应的推荐信息,完成相应的推荐;对借阅数据比较多的用户,系统便可采用协同过滤算法计算用户的推荐信息。一般而言,系统将首先使用Jaccard相似度的方法计算图书之间的相似度,并根据相应的计算结果再将相似度较高的图书推荐给相似度较高的用户。
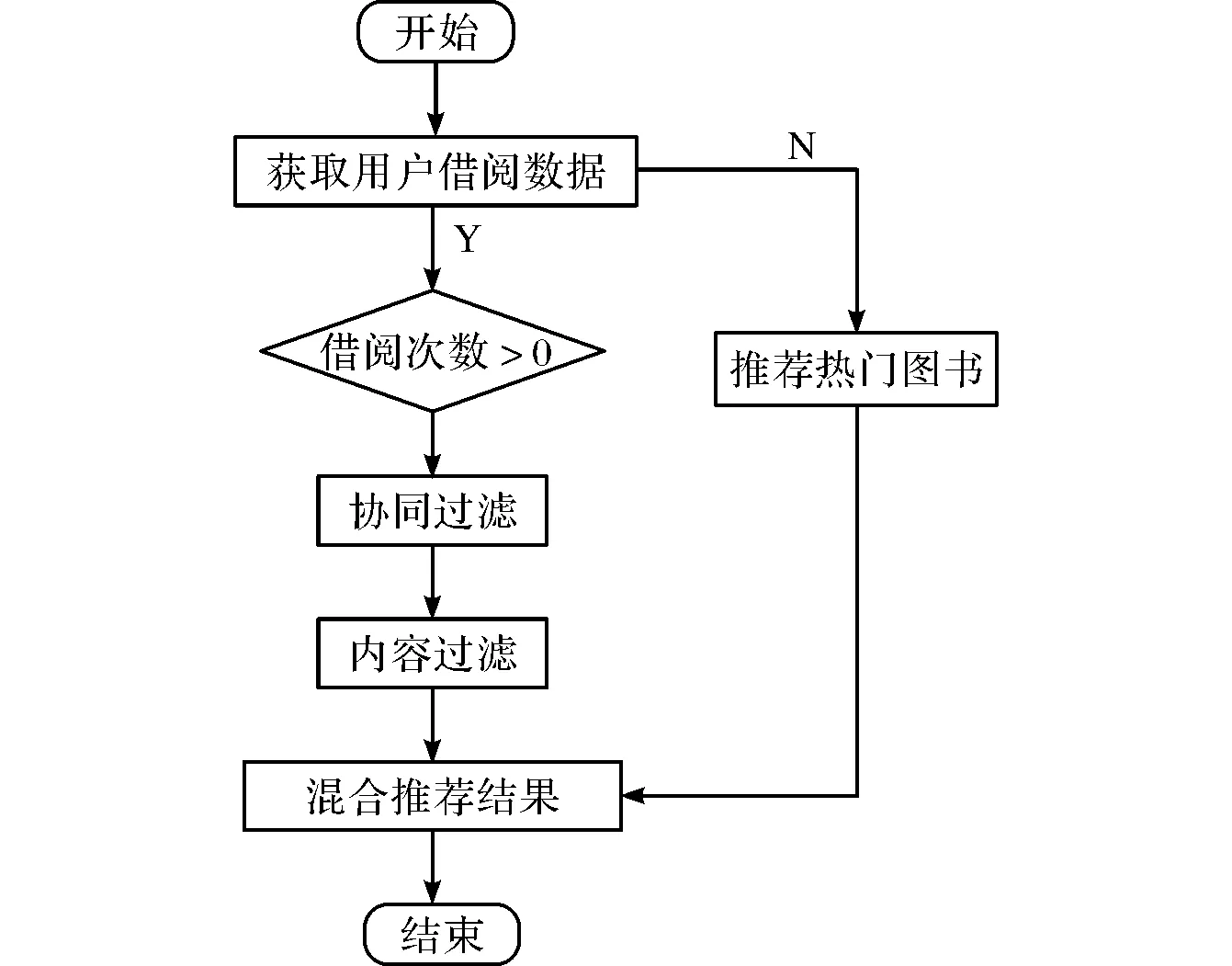
图4 图书推荐系统内核流程图
3.2 数据同步的实现
根据系统的需求分析,数据同步是指获取所有图书的管理信息,从而建立系统的推荐算法的数据基础。在本文中,使用了定时器完成系统的数据同步。一般而言,图书馆需要严格管理馆藏图书的多种信息,包括还书时间、图书题名、编号、版本等。以某高校图书馆的信息系统为例,其馆藏图书的部分信息记录如表1所示。

表1 某高校图书馆的馆藏图书部分信息
根据以上格式,系统可以精准地获取所有图书的准确属性,这些信息也是系统数据同步模块的操作对象。为了提高数据同步的运行效率,系统使用表2的格式采集馆藏图书的属性信息。

表2 馆藏图书属性采集格式
此外,本文还引入了新浪云的数据库引擎存储图书属性等数据。该数据库引擎是一种分布式的键值型引擎,具有海量的存储空间和快速的读写速度,适用于图书推荐系统的数据管理。
4 结束语
为了设计智能化的图书推荐系统,本文全面分析了系统的多项需求,通过引入Django框架和信息可视化等多项技术,设计了一个利用混合推荐算法的推荐系统,使用协同过滤和内容过滤等算法对该系统进行了实现。
