改进稀疏表示的人脸识别在高校管理中的应用∗
2018-11-28刘嘎琼
刘嘎琼
(江苏科技大学海洋装备研究院 镇江 212003)
1 引言
人脸识别是模式识别和图像处理领域一个长期以来的热点问题[1]。它在身份鉴别、人机交互等众多领域发挥着重要的作用。高校信息化建设中人员的信息化管理十分重要,如门禁系统以及人机交互操作等。由此,本文通过研究稳健的人脸识别技术以将其应用于后续的高校信息管理系统。一般的人脸识别方法主要包括两个关键部分,即特征提取和分类器设计。常用于人脸特征提取的方法包括主成分分析(Principal Discriminant Analysis,PCA)[2~3],线性鉴别分析(Linear Discriminant Analy⁃sis,LDA)[4],流形学习方法[5]以及局部纹理特征[6~8]等。分类器则是基于提取的特征判断人脸的类别。随着模式识别和机器学习技术的快速发展,大量的先进分类器在人脸识别中得以成功运用,如K近邻分类器(K-Nearest Neighbor,KNN)[11],支持向量机(Support Vector Machines,SVM)[2~9]、稀疏表示分类器(Sparse Representation-based Classification,SRC)[10]以及卷积神经网络(Convolutional Neural Networks,CNN)[11~13]等。
本文提出结合全局和局部稀疏表示的人脸识别方法。传统的SRC是基于全局字典求解稀疏表示系数进而根据各类的重构误差大小判断目标类别。这种全局字典的重构误差主要反映了测试样本与各个类别的相对匹配度,各个类别的独立表示能力并不能充分发掘。实际上,对于正确的类别,其训练样本对测试样本的重构更为精确。因此,分别在各个类别构成的局部字典上重构测试样本可以充分考察各个类别对于测试样本的描述能力。通过结合全局字典和局部字典各个类别的重构误差,可以有效提高目标识别的稳健性。本文线性加权融合的方法对其进行决策层融合并基于融合后的结果判定目标类别。为了验证提出方法的有效性,AR和Yale-B人脸数据集上进行了验证实验。
2 稀疏表示分类器
2.1 基于全局字典的稀疏表示
稀疏表示分类认为来自于某一类的测试样本可以由该类训练样本线性表示,且线性表示系数具有稀疏性。传统的稀疏表示分类器作用于各类目标共同构成的全局字典,记为 A=[A1,A2,…,AC]∈ Rd×N,其中 Ai∈ Rd×Ni(i=1,2,…,C)代表来自第 i类的Ni个训练样本。对于待识别的测试样本y,采用式(1)对其进行稀疏重构:

其中α代表稀疏表示系数,ε是可允许的重构误差。在求得稀疏表示系数α̂后,按照式(2)计算各个类别的重构误差。

式中 δi(α̂)表示仅保留 α̂中对应于第 i类的系数;r1(i)(i=1,2,…,C)代表各个类别的重构误差。根据最小重构误差判断目标类别如下:

可以看出,在稀疏表示分类中,最核心的部分是稀疏表示系数的求解。由于式(1)涉及的l0范数优化一个NP-hard问题,研究人员通过将其近似为l1范数转化为便于求解的凸优化问题[10]或是采用基于贪婪机制的算法,如正交匹配追踪算法(Or⁃thogonal Matching Pursuit,OMP)[14]。
2.2 基于局部字典的稀疏表示
全局字典下的稀疏表示主要体现了各类训练样本对于测试样本的相对描述能力。然而,各个类别对于测试样本的独立描述能力并没有充分利用,即此时各个类别对于测试样本的重构并不是最优的。通过在局部字典上分别对测试样本进行重构,从而评价各个类别对于测试样本的绝对描述能力,可以为目标识别提供有益的信息。
基于局部字典的表示主要是为了体现各个类别对于测试样本独立进行表示的能力。同一类别的训练样本表示能力强,因此重构误差较小。采用式(4)基于局部字典上的稀疏求解。
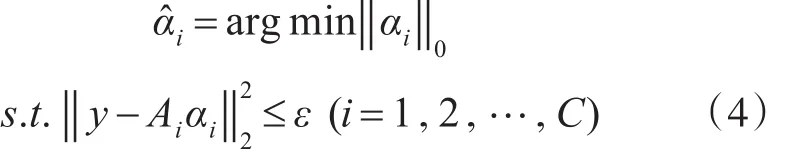
式中αi(i=1,2,…,C)代表各类局部字典上的稀疏表示系数,根据各类局部字典上求解的稀疏表示系数计算各类的重构误差如下:
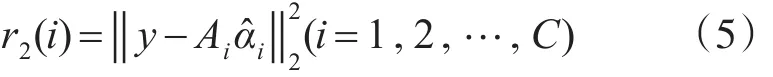
3 结合全局和局部稀疏表示的人脸识别
为了有效结合全局和局部表示的分类结果,本文首先将两者的重构误差转换为归一化的相似度以便于后续的决策融合,具体如式(6)所示。

式中 r(i)(i=1,2,…,C)代表各个类别的重构误差;s(i)代表测试样本与各类的相似度,某一类的重构误差越小,测试样本与其相似度越高。记全局和局部稀疏表示的相似度矢量分别为s1(i)和s2(i),采用线性加权融合[15]得到最终的相似度如下:
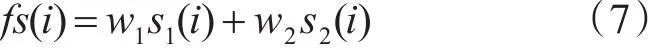
式(7)中w1和w2代表权值,fs(i)为融合后的相似度。本文中认为w1=w2=0.5,即两者具有同样的重要性。图1显示了本文人脸识别方法的基本流程。具体实施中,采用经典的PCA方法进行特征提取。求解稀疏表示系数时,本文依照文献[9]采用l1正则化方法。

图1 本文识别方法的流程

图3 Yale-B数据库的部分样本
4 实验与分析
4.1 实验数据集
本文选用AR和Yale-B人脸库来验证提出算法的有效性。AR人脸库是由西班牙巴塞罗那计算机视觉中心建立,包含了不同光照,面部表情,遮挡物等条件下的结果,共120人,每个人有26幅图像,图像大小40×50;Yale-B人脸库是由耶鲁大学计算视觉与控制中心创建,共有10个研究对象,每人45张图片,包含了不同光照条件下的成像结果,图像大小为32×32。图2和3分别显示了来自于AR数据库和Yale-B数据库的部分样本示例。
对于AR数据库中的每个对象,选取前13幅图像为训练样本,剩余13幅图像为测试样本。在Yale-B数据库上,选取每个对象的前20个图像作为训练样本,剩余的25个样本作为测试样本。为了充分验证提出方法的有效性,选取了几类经典的人脸识别方法进行对比实验,包括基于KNN的方法,基于SVM的方法以及基于全局SRC的方法。为了与提出方法保持一致性,这些对比方法均是对PCA特征矢量进行分类。
4.2 实验结果与分析
图1和图2分别显示了各类方法在AR和Yale-B数据库上基于不同维度的PCA特征的识别结果。可以看出,本文方法在各个特征维度上均可以取得最高的识别率,充分验证了其有效性。为了更为直观地比较各类方法的性能,将图1和图2总结为表1和表2,包括最高识别率以及选取的各个维度的平均识别率。
由表1的结果可知,本文方法具有最高的识别率以及平均识别率,显示了其相比其它算法的优越性。由此可知,本文提出的方法对于表情、光照、遮挡物等变化具有一定的鲁棒性。相比基于全局SRC的方法,本文方法的识别性能有了较为明显的提升,证明了结合局部稀疏表示的优势。
由表2的结果可知,相比于AR数据库上更为复杂的情形,在Yale-B数据库上提出算法可以取得更佳的识别性能。同样,本文算法的最高识别率以及平均识别率均高于其它方法,证明了其对于光照变化具有更强的稳健性。

图4 各类方法在AR数据库上的识别性能

图5 各类方法在Yale-B数据库上的识别性能

表1 AR数据库的实验结果对比

表2 Yale-B数据库的实验结果对比
5 结语
本文提出了结合全局和局部稀疏表示的人脸识别方法。测试样本分别在各类目标组成的全局字典以及各类的局部字典上进行稀疏表示。基于线性加权融合的方法对全局和局部稀疏表示的重构误差矢量进行决策融合,从而得到更为稳健的识别结果。基于AR和Yale-B数据库的结果表明提出的方法对于表情,有无遮挡物等变化具有一定的鲁棒性,对于光照变化能具有较强的稳健性。实验结果充分证明提出方法在现实条件下的应用价值。本文提出的方法后续将在高校人员管控等方面进行应用,进一步验证其有效性。
