反思与超越:科学知识图谱在新闻传播学的知识生产检视
2018-11-23马超
马 超
一、研究起源与背景
如何了解一个学科/领域的全貌,又如何评价一个学科/领域的影响力,上述疑问曾是困扰学术界的经典难题。直到文献计量学诞生,才为这些问题的解决提供了可行方案。[1]作为一种客观定量的实证研究范式,文献计量手段不仅可以揭示文献的分布结构、数量关系和演进趋势,而且也可以确定学科的核心期刊,甚至发掘学科的研究热点[2]。因此,国内外众多学者纷纷将这一方法运用到本学科的研究之中。[3]
然而,随着知识的爆炸性增长和各种类型文献的井喷,传统的文献计量手段在知识管理和知识评价上显得愈发力有不逮。与其他学科一样,新闻传播学界也曾一度被这一问题所困扰。早年间,由于文献计量工具的匮乏,面对庞大的论文数量和复杂的被引关系,新闻传播学界对学科内部“知识地图”的勾勒往往呈现出局部性、碎片化的局面,相关研究也屈指可数。段京肃是本学科内文献计量研究的先行者之一,但其选择的研究时段往往局限于几年之内[4-5],研究样本也仅限于CSSCI数据库收录的文献[注]该作者之所以选择CSSCI数据库的文献作为分析对象,很大程度上是“近水楼台先得月”的缘故:因为其当时所供职的南京大学正好是“中文社会科学引文索引”编制机构,作者与本单位图书情报学领域的研究者合作完成了这一系列论文。。肖燕雄等对新闻传播学科的引证研究虽然在时间上横跨20年,但其具体的分析对象仅为48名学者的论文。[6]徐剑对新闻传播学高被引论文的研究虽然在时间线上延展30年,但也仅限于分析“被引量”这一个指标。[7]放眼大陆之外,苏钥机对中国大陆、香港、台湾、新加坡四地11本新闻传播学期刊的研究是一项规模较大的文献计量分析,研究指标涵盖了作者、机构、发文时间、研究主题、研究方法、引文数量、引文来源等诸多变量。但这项时间跨度并不算大的研究(2006—2011年)却动用了13位研究生才合作完成。[8]
这种“心有余而力不足”的状况不独发生在中国,国际传播学界似乎也面临着同样的问题。鉴于工作量浩大的现实,学界的文献计量分析要么只限于特定时段,要么只针对特定话题,要么仅限于特定期刊。前者如菲力(Feeley)对19本传播学期刊的引证关系进行分析时,将时间段截取在2002—2005年之间。[9]中者如李(Li)和唐(Tang)对国际传播期刊进行元分析(meta- analysis,又称“荟萃分析”,台湾译为“后设分析”)时,只限于和“中国大众传播研究”有关的特定议题。[10]后者如赖斯(Rice)等对《广播电视与电子媒介学刊》(JournalofBroadcasting&ElectronicMedia)这本特定期刊同其他期刊施引与被引情况的文献计量分析。[11]当然还有为数不多的研究者同时对研究时段和研究议题都进行了限制。如菲力(Feeley)等对传播学文章的引证情况进行分析时,议题被严格限定在“健康传播”领域,时间也被严格限制在2006—2008年之间[12]。
在互联网技术迅猛发展的大数据时代,各个领域的信息和数据飞速激增。与商业大数据的快速增殖和积极应用相比,学术领域的科学数据还较少受到关注,人们对于科学数据的利用和创新研究也还远远不够。然而从现实环境来看,当前我国的知识管理研究面临着前所未有的大好机遇:一是自改革开放以来,我国在科学文献数据方面的积累呈指数增长[注]有学者对1980—2014年收录在WoS数据库中的中国文献建立数学模型进行拟合,曲线拟合度的可决系数R2=0.9917。[13]。根据美国国家科学基金会和国家科学委员会2018年1月发布的《科学与工程指标》,2016年中国学者发表的学术论文数量跃居全球第一[14]。丰富的文献数据成为知识计量得以实施的基础。二是随着国内各种数据库的不断创立完善和对西方各类数据库购买引进日益增多,可供利用的学术资源日益丰富,加之各类数据库越来越朝着规范化和标准化方向发展,知识计量的准确性和统一性也大大提高。三是随着数理统计知识的不断发展和各种计量软件的不断开发,为知识组织和知识发现提供了坚实的技术保障。
作为一种新兴的知识组织和知识管理方法,科学知识图谱凭借着揭示海量文献数据中潜藏结构关系的优势,成为当前知识计量学中的主要研究方法,并受到了国内外学界的热捧和广泛运用[15]。那么,科学知识图谱是什么?其究竟有何优势,又有哪些不足?新闻传播学科运用这一方法的现状如何,是否存在着一些问题?接下来本文将就这些问题进行详细探讨。
二、文献回顾:科学计量学的方法论反思
任何一个学科和方法在兴起之初,都伴随着种种问题的困扰,科学计量学自然也不例外。20世纪90年代初,《科学计量学》专刊组织了一场关于科学计量学学科发展问题的讨论。匈牙利情报学家格兰泽尔(Glanzel)和德国马普学会的舍普林(Schoepflin)尖锐地指出了科学计量学面临的种种危机。一是对概念和方法的误用明显。比如一些研究者并没有清晰解释“洛特卡定律”(Lotka Distribution)这些基本的概念,也没有正确地使用“影响因子”“被引率”等概念评价个人或国家的科学成就。二是模糊了基础研究和思辨之间的界限。一些数学家积极地发展量化研究方法,导致该学科变成了“技术的形式主义”(technical formalisms),即科学计量学的研究内容被简化为单纯的数据集呈现。三是人才的退出与流失。一方面由于科学计量学常常不符合社会研究的标准,另一方面仅仅拘泥于技术形式的科学计量学在问题诠释方面的价值十分有限,因此许多社会科学家纷纷退出该领域。四是学科直接被科学政策和规划的利益所左右,基础性的理论和方法探索变少,而为科学政策部门和产业部门搞技术性操作的委托项目多了[16]。这篇文章的发表引发了学界的热烈讨论,促使其他学者开始反思科学计量学发展中出现的种种问题。
麦克格拉斯(McGrath)指出,科学计量学的研究大致可以分为四类,但这四类研究或多或少都存在缺陷。第一类是用搜集的新数据去验证旧定理。然而这种重复验证式的研究并不能推动理论上的实质性进步。第二类是描绘一个学科的知识地图。通常是在一个二维坐标图中展示作者、期刊、机构等变量之间的关系,然而在共被引分析时置信区间过大,容易使人们对研究对象的信度生疑。第三类是影响性的研究。学界通常用“被引频次”这个单一指标来衡量个人、机构或国家的学术表现。然而文章被引用的动机多种多样,单一的指标不能准确测度学术水平。第四类是前三种结合的混合研究,自然也继承了前三种研究中的种种问题。[17]
作为一个跨学科的领域,科学计量学界一度吸引了来自不同学科研究者的加入。[18]埃格(Egghe)指出了科学计量学研究中的两种路径。一种是数学的进路,一种是社会科学的进路。数学研究进路的好处在于研究的质量可以清晰判别:数学建模越复杂,越容易被数学背景的研究者所认可。而社会科学的研究由于没有统一的判断标准,不仅社会学界内部对同一篇文章的评价各不相同,数学界对社会科学界的研究质量也无法评判。为此作者提出,弥合不同学科之间的鸿沟是未来科学计量学的重要任务。[19]
针对数学统计愈演愈烈的趋势,米克尔(Miquel)发问:科学界的一切事物都可以测量吗?科学计量学的指标能够回答不同类型的问题吗?作者给出答案是否定的,他认为科学计量学的一系列指标只能揭示学术社群的表象而非实质。[20]面对此种问题,佩里茨(Peritz)进一步指出,科学计量学不能排斥实证研究中重要的访谈法,因为显现的文献背后反映着文献创造者的思想,知识管理学中提到的“默会知识”(tacit knowledge)必须依赖访谈才能了解到。社会学者擅长发掘现象背后的意涵(implications),而情报学者在知识的深度发掘上常常做得不够。基于此,如果情报学者能够学会关照社会表象背后的问题,那么不仅会提升科学计量学的学科地位,也会赢得更多的受众。[21]瑞普(Rip)同样认为,在运用科学计量方法时,决不能离开定性方法的使用。比如在搜集数据阶段,需要研究者对数据来源进行核实、鉴别和比较。作者举例指出,涂尔干当年在撰写《自杀论》时就存在着数据证据的不严谨的问题——官方公布的自杀数据存在大量漏报瞒报的现象,与实际自杀率存在很大偏误;而且每个地区对自杀的认定标准也不同。涂尔干研究的不足提示我们在数据的定量分析时,首先需要研究者通过比较、对比等方式确保原始数据的真实全面。[22]
科学计量学的自我反思经历了从定性的综述性回顾到应用定量分析方法的演变过程。当今天新兴的科学知识图谱方法出现以后,前人反思的种种问题是否依旧存在?尤其是作为外来学科的新闻传播学界在借用这一知识管理方法时,又会出现什么样的问题?遵循这种批判反思的思路,本文对新闻传播学界采纳科学知识图谱的现状和问题进行分析。
三、科学知识图谱的概念定义
(一)科学知识图谱的定义
关于科学知识图谱(mapping knowledge domains)的概念界定,目前学界引用较多的是大连理工大学刘则渊团队给出的定义:“以科学学为研究范式,以引文分析方法和信息可视化技术为基础,涉及数学、信息科学、认知科学和计算机科学等诸多学科交叉的领域,是科学计量学和信息计量学的新发展。”[23]科学知识图谱具有“图”和“谱”的双重性质:既是可视化的知识图形,又是序列化的知识谱系,显示了知识元与知识群之间网络、结构、互动、交叉、演化或衍生等诸多复杂关系。[24]
科学知识图谱的诞生有三个基础:一是以数理统计和图论为代表的技术手段不断演进,为数据分析和可视化呈现提供了前提;二是以引文分析为代表的文献计量学不断发展,为其奠定了学科理论基础;三是以加菲尔德创立的科学引文数据库为代表的大规模文献数据库的建立,为科学知识图谱提供了充足的数据来源。
(二)科学知识图谱中的常见分析类别和分析单位
上文提到,科学知识图谱诞生的基础之一就是以引文分析为代表的文献计量学。因此,科学知识图谱的分析类型涵盖了传统文献计量学中的基本分析单元,具体包括:
1.文献共被引分析
文献共被引分析的概念由苏联情报学家伊琳娜·玛莎科娃(Irina Marshakova)和美国情报学家亨利·斯莫(Henry Small)于1973年分别提出。他们指出,如果两篇论文A和B同时被后来的一篇或多篇论文引用,那么则认为文献A和B具有共被引关系。同时引用A和B的论文数量为共引度。共引度越大,说明文献A和B之间的关系越密切。[25]
2.期刊共被引分析
简单地讲,当n种(n≥2)期刊的论文被其他期刊同时引用时,则称这n种期刊具有“共被引”关系。期刊的共被引关系反映了它们之间某种学科或专业上的联系,如果共被引频率较高,则说明这种专业关系比较密切,从而为确定学科核心期刊提供了依据。[26]
3.作者共被引分析
1981年,怀特(White)和格里菲思(Griffith)对著者共现现象进行研究后提出了“著者共被引分析”的概念[27]:当n个(n≥2)作者发表的文献同时被别的作者所引用时,则称这n个作者具有共被引关系。[28]著者共被引分析使众多著者按照共被引关系形成一个著者关系群,从而揭示出学科领域专业人员的组织结构和联系程度。若把某专题研究的同行著者联合起来组成协作网,加强彼此之间的学术交流,开展联合攻关,将大大促进该学科领域研究的发展。[29]
4.词频分析
词频是指词语出现的频数。词频分析法就是在文献中提取能够表达文献核心内容的关键词或通过呈现主题词频次的高低分布,来研究该领域的发展动向和研究热点。作为科学计量学中最古老的分析对象,词频分析所依据的理论是“齐普夫定律”。齐普夫研究指出[30],如果一篇文章包含n个词汇,将这些词按其出现频次进行降序排序,那么序号r和其出现频次f的乘积“fr”近似地为一个常数。即fr=C(C为常数),(式中r=1,2,3……)。这一发现揭示了词频分布的基本规律。
5.共现分析
“共现”是指文献特征项描述的信息共同出现的现象。这里特征项包括文献的外部和内部特征,如题名、作者、关键词、机构等。而“共现分析”是对共现现象的定量研究,以揭示信息的内容关联和特征项所隐含的知识。[31]所以共现分析包括关键词共现分析和作者、机构、国家/地区共现分析等。
其中词的共现分析简称“共词分析”,最初是由卡隆(M.Callon)等研究者于1983年提出。[32]共词分析的基本原理是对一组词两两统计它们在同一组文献中出现的次数,然后通过这种共现次数来测度它们间的亲疏关系。[33]其被广泛应用于揭示学科主题之间的关系、呈现学科结构、发掘研究热点等。
作者和机构共现分析主要是对著者的合作关系进行考察。随着社会问题越来越具有复杂性和综合性,跨学科跨领域的研究成为一种趋势。不同机构、不用领域作者之间的科研合作日益成为科学研究的主流方式。自2001年纽曼(Newman)首次采用社会网络方法对合著关系进行分析以来[34],越来越多的研究者采用该方法对不同领域作者的合著网络展开研究[35]。
国家/地区之间的共现分析主要是对跨国/跨地域的科学合作关系进行探究。比如有研究者通过对拉丁美洲学术合作的研究发现,在当今时代的科学研究中,国际合著论文已经成为主流趋势,越来越多的发展中国家科研机构都在积极参与国际合作以增加其合著论文的产出。[36]两位印度学者通过对印度科研机构的研究发现,国际之间的合作不仅有助于增加科研机构的论文产出,而且对科研机构论文的平均影响因子贡献巨大。[37]
(三)科学知识图谱的比较优势
与传统的定性文献综述方法相比,科学知识图谱具有以下三点独特优势:
一是可以最大程度避免研究者在文献判断上的主观性。在传统的定性文献综述中,研究者可能由于自身知识结构的缺陷,很容易忽视学科领域内的重要文献,也可能由于自己研究需要的功利性动机刻意遮蔽或扭曲一些文献。而科学知识图谱则利用信息计量学原理,运用聚类分析、多维尺度分析、社会网络分析等方法揭示作者共被引、关键词共现、文献耦合等信息,既可以避免研究者的前置性预设,也有助于发现研究者本身的一些知识盲点。
二是有利于科学前沿的预测和知识创新。借助科学知识图谱研究一个领域的知识生产、传播与扩散规律,不仅可以掌握该领域的知识基础、知识结构、知识演化与知识涌现过程,而且还有助于实现该领域的知识创新。通过科学知识图谱的方法,不但可以对某一学科领域的知识进行整合,并且还可以揭示既有知识背后隐含的关系、规律和趋势,从而有助于挖掘更多的潜在知识。这既有利于该领域知识的增值,也能够帮助科研人员实现创新。
三是直观性展示和动态化呈现。在信息可视化技术支持下,科学知识图谱的呈现形式既可以是线性的二维图形,也可以是立体的三维图像,各种视觉表征手段的运用,使其具有可视化展示和形象化呈现的特点。此外,科学知识图谱能够通过对不同时间段中的节点关系进行对比展示,以静态的图谱形式揭示隐藏在文献中的动态信息[38]。
(四)科学知识图谱常用工具——CiteSpace软件
自共被引分析理论提出以来,国内外学者纷纷尝试开发不同类型的可视化软件进行文献计量分析。比较有代表性的软件包括加菲尔德开发的HistCite,印第安纳大学研发的SCI2,荷兰莱顿大学开发的VOSViewer和美国陈超美开发的CiteSpace。在诸多科学知识图谱的绘制工具中,美国德雷塞尔大学华裔学者陈超美开发的CiteSpace软件是目前被国内外研究者使用最频繁的可视化软件。这款软件的盛行既离不开版本更新快、支持的数据源多、分析功能强大等内生因素,更重要的是陈超美在科学网博客上对成千上万用户使用疑问的解答,方便了该软件在国内的推广与应用。2006年,陈超美在《CiteSpace II科学文献转型模式存在趋势的探测和可视化》一文中详细介绍了CiteSpace软件的算法原理和应用步骤,并通过“恐怖主义”和“集群灭绝”等案例展示了可视化图谱的成果。该文发表后立即引发学界强烈反响,并得到了上千次引用。近年来,国内一些新闻传播学者也开始陆续引入该方法。
四、科学知识图谱在新闻传播学中的应用现状
(一)研究样本及历时分布
中国知网“文献分类目录”中选择“新闻与传媒”,主题词选择“科学知识图谱”或含“CiteSpace”,时间截至2018年8月1日。在剔除大量图书情报科学的无关文献后,共得到51篇有效文献[注]需要说明的是,本研究采用广义的“新闻传播学”学科定义,将“编辑出版学”的研究纳入研究范围,另外为了保持各论文中分析单元的一致性,本文的分析对象仅为使用CiteSpace软件进行科学知识图谱分析的论文。。
从2013年开始,采用科学知识图谱方法研究新闻传播类议题的文章就正式出现,而后相关研究呈逐步增长态势,但连续数年的研究数量都停留在个位数上。在经过2016年的短暂回落以后,2017年的研究开始出现量的飞跃,一举突破了个位数达到17篇。由于写作时间的限制,截至2018年8月,已经出现13篇相关研究,但从拟合趋势来看,到2018年底还会产生更多文章。见图1。
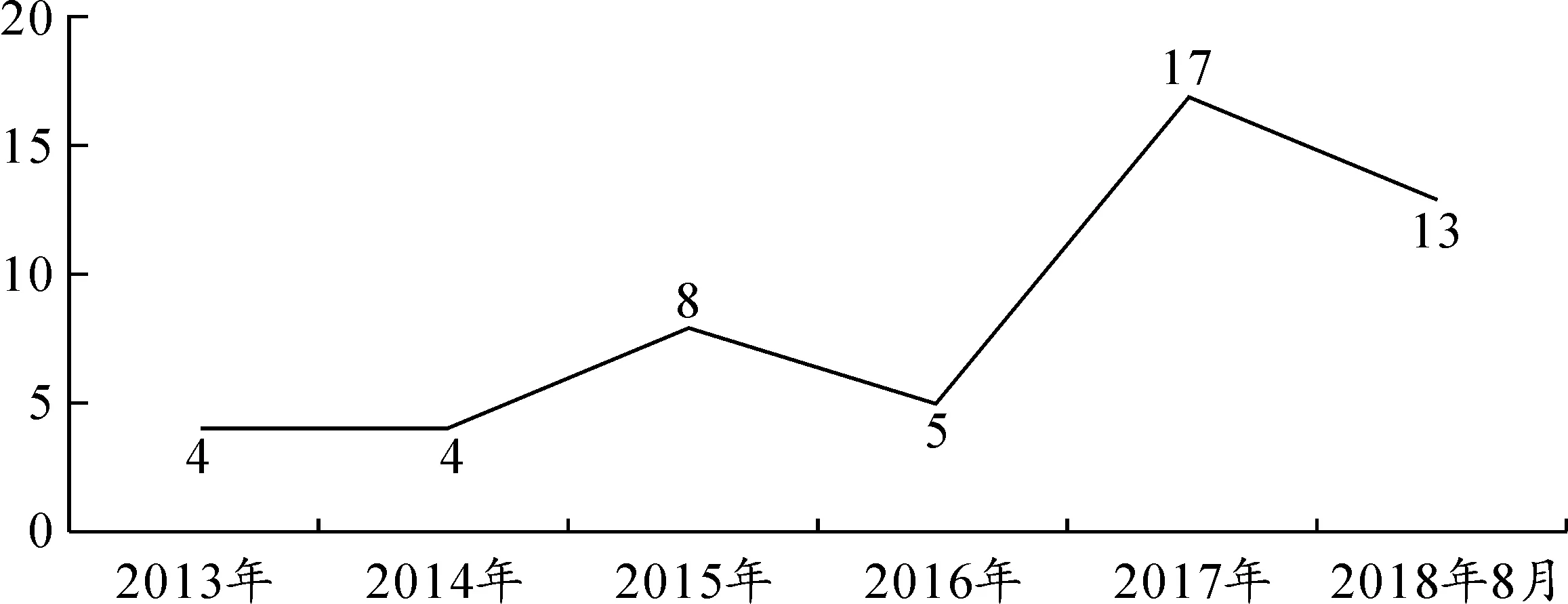
图1 科学知识图谱在新闻传播学中总体采纳趋势
(二)研究议题分布情况
与研究数量的增长态势相比较,5年间研究议题却并未得到实质性扩展。在对51篇文献进行统计后发现,这些文章的研究议题主要集中在10个方面。目前研究最多的议题是关于新媒体的议题(包括社会化媒体等在内),占总数的21%(n=11);其次是关于舆论/舆情的研究占15%(n=8);再次是关于媒体融合的研究占将近10%。健康传播和数字出版为主题的研究各有3篇,跨文化传播、媒介素养、情绪、新闻传播学整体为主题的研究各有2篇,剩下的研究分散在媒介经济、健康传播、媒介与少数民族等领域。见图2。
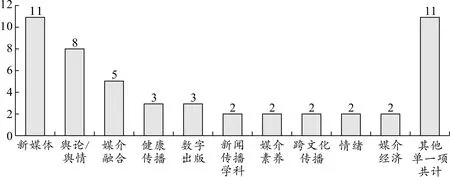
图2 采纳科学知识图谱方法的研究议题分布
(三)研究主体的学科构成
在研究机构的学科分布上,基本上形成了新闻传播学、图书情报学、经济管理学三足鼎立的局面。2015年以前,图书情报学的研究者占据着主导地位,他们凭借专业的文献计量知识率先涉足新闻传播学的交叉议题(如网络舆情),成为本领域开疆拓土的先行者。与此同时,一些经济管理领域的研究者也在社会化媒体等议题上分得一份羮。2015年以后,随着科学知识图谱方法的推广和软件的迭代成熟,越来越多新闻传播学本专业的研究者开始“收复失地”。截至2017年底,新闻传播学研究者占据半数以上的份额(65%,33篇),成为绝对研究主力;图书馆情报学的研究者位居次席,占据了19%份额(10篇);经济管理学领域的研究者则贡献了约12%的文章(6篇)。见图3。

图3 研究主体的学科分布
就具体研究机构而言,中国人民大学新闻学院的师生发表了5篇相关文章,成为发文量最多的机构,暨南大学新闻与传播学院位居次席(n=4),武汉大学新闻与传播学院和对外经贸大学出版社以3篇成果收获探花地位,天津外国语大学国际传媒学院、南京大学信息管理学院、吉林大学管理学院各自贡献了2篇文章,剩下的机构发表了1篇文章。见图4。
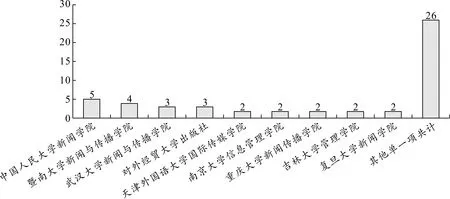
图4 研究机构的分布情况
(四)载文期刊
刊载51篇样本文章的期刊可以分为新闻传播学专业期刊、情报学专业期刊和大学学报三类(详见图5)。这些期刊中有31本CSSCI来源期刊(含拓展版)[注]以文章发表时被CSSCI数据库收录为限。。其中载文数最多的三本期刊分别是《新闻与传播研究》《国际新闻界》和《科技与出版》,三者均刊发了3篇文章。其中《国际新闻界》的3篇文章全部来自2017年第7期的一组组稿。
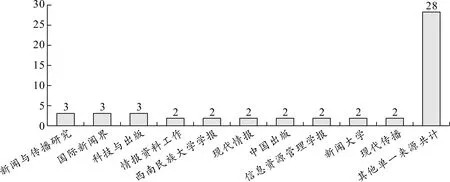
图5 载文期刊的分布情况
(五)著者合作关系
在作者合作情况方面,51篇文章共涌现出了99位作者,平均每篇文章约2名作者。所有文章中,有18篇文章为作者独著,剩下33篇文章均为合作完成。其中作者数目最多的一篇文章出现了6位作者。从合作关系来看,33篇文章中的合作者主要为师生关系和同事关系两类。其中有4篇文章为跨机构的合作,但所有文章并未出现跨学科的合作关系。
(六)分析特征项
本文根据51篇文章归纳了科学知识图谱可以分析的全部特征项,包括总体发文量及年份、国别发文量、学科分布、作者发文量、机构发文量等12项(详见表1)。但在每一篇具体的文章中,各文章分析的特征项数目各不相同,最少的只分析了“关键词”1个特征项,最多做了“关键词共现”“作者共现”“机构共现”“文献共被引”“期刊共被引”等9项分析。51篇文章的特征项均值为4.22。
表1 科学知识图谱的常见分析特征项

分析特征项作用适用数据库备注总体发文量及发表年度识别整体概况CNKI、CSSCI、Web of Science各个数据库本来就有分时段统计量,可以不借助科学知识图谱软件国别发文量识别高产国家Web of Science学科分布识别跨学科研究CNKI、CSSCI、Web of Science各个数据库本来就有学科分类,可以不借助科学知识图谱软件作者发文量及共现关系识别高产作者及合作关系CNKI、CSSCI、Web of Science机构发文量及共现关系识别高产机构及合作关系CNKI、CSSCI、Web of Science基金项目数识别资助基金Web of Science关键词频次及共现分析识别研究热点CNKI、CSSCI、Web of Science关键词突显侦测识别研究前沿CNKI、CSSCI、Web of Science文献被引量识别经典文献CNKI、CSSCI、Web of Science各个数据库本来就有被引量排序,CiteSpace软件无法提供文献共被引分析识别文章主题相似度CSSCI、Web of Science不等于文献“被引量”作者共被引分析识别学者研究方向相似度CSSCI、Web of Science不等于作者“被引量”期刊共被引分析识别核心期刊CSSCI、Web of Science
五、科学知识图谱在新闻传播学科运用中的反思
在对文献基本的外部特征进行整体勾勒后,本研究深入到每一篇文章的内容部分进行详细检视,发现新闻传播学界在采纳科学知识图谱方法及软件中存在的若干问题值得深入探讨。
(一)科学知识图谱方法存在先天不足
从方法论的角度看,知识计量的方式只能从宏观上“勾勒”某一学科领域的整体概貌,却无法实现对该学科知识肌理的微观“深描”。尽管科学计量学的方法具有客观、系统、定量的优势,但其所得结果未免失之粗浅,给人一种知表不知里的感受,长于“描述”而疏于“解释”,使人“只得其形不得要义”。
科学知识图谱主要解决的是“是什么”的问题,即对研究对象的基本状况、主要特征、发展过程等做出系统、客观的描述。而传统文献综述的方式则是为了探究“为什么”的问题,即不但要说明研究对象的发展状况,更要探究隐藏其中的内在规律。实际上,两种路径并不是截然对立的,因为诠释性的研究首先需要对研究对象整体有着清晰的认识和把握,而计量性的统计最后也需要深入的诠释来回答问题产生的原因。因此,只有将两种方法结合起来,才能系统全面地实现学科领域“知识地图”的“绘制”。
(二)我国现有的数据库尚不能完全满足知识计量的需求
这里具体包括三点。首先是导出特征项全面性的问题。目前中国知网(CNKI)只提供了关于“题名”“作者”“机构”“关键词”的文献导出数据,而没有提供参考文献的相关链接,这也导致知识计量中的“作者共被引”分析、“文章共被引”分析和“期刊共被引”分析无法实现。而中国社会科学引文索引(CSSCI)数据库虽然在中国知网的基础上补充了参考文献的链接,但其收录的文献始于1998年,新世纪之前的许多文献都付诸阙如,这对于许多历时性的纵贯研究来说是一个重大的遗憾。
其次是文献收录的覆盖性问题。众所周知,人文社科各领域的普通刊物数量远远大于核心期刊数量,多数研究者的文章都发表在普刊上,能够收录进入CSSCI数据库的文章本身就是百里挑一的。况且在当下的学术生态中,许多青年学者由于职称、年龄、职务等限制,即使文章出类拔萃,囿于僧多粥少的缘故也很难有机会在核心期刊上发表文章。因此仅仅研究CSSCI数据库的文章难免会遮蔽许多有价值的文章。
第三是收录文献构成的完整性问题。即使从被CSSCI收录的文献来看,许多引文数据也有残缺之处。比如《谁在操纵BBC——公众?政府?——透视英国政府关于BBC公共广播改革的“绿皮书”》一文的多篇参考文献都只有标题而没有作者姓名,这直接导致使用软件进行作者共被引分析时出现多处“ANONYMOUS”(匿名,即没有作者的提示)的词频。
(三)许多使用者因为不熟悉知识图谱软件功能而事倍功半
科学知识图谱既可以展示可视化的“图”,也可以呈现频次、中心性等结果的具体参数,然而在实际应用中一些研究者却没有充分利用好软件的各项功能。比如一篇关于媒介素养的研究,作者统计了“机构发文量”的频数,却没有进一步利用软件对机构之间的合作关系进行可视化呈现,因而忽略了对该领域学术合作情况和学术共同体构成的分析。还有一些研究者似乎尚未认识到CiteSpace软件的可视化呈现功能,以至做出一些画蛇添足的举动。比如CiteSpace软件本身具有关键词共现分析、著者共现分析等功能,却有研究者额外采用社会网络分析软件UCINET及其NetDraw绘图工具来绘制作者和关键词的共现图谱。
(四)研究者在尚不熟悉研究对象的情况下“为方法而方法”
科学知识图谱只是一种文献计量的方法,无论在利用该方法进行研究设计之前,还是获得结果后解读研究发现,最根本的还是取决于研究者本人已有的知识储备。因此,对学科/领域基本情况的熟悉程度直接影响研究结论的准确性。在使用科学知识图谱软件进行分析的过程中,一个常见的问题就是“同名替换”问题。比如在研究机构方面,“英国广播公司”和“BBC”实际上为同一个机构,但不同文献中会出现交替使用的情况;又如在文献来源方面,一些研究者引用的是外国原著,一些研究者引用的是中译版本,实际上也是同一来源,但如果在文献计量过程中不进行替换的话就很容易出现统计遗漏的问题。而这些同名替换全都靠研究者本人进行人工识别,如果研究者对个别文献或机构不熟悉,就会闹出笑话。譬如一篇文章在进行机构共现分析后指出,“中国人民大学新闻学院与中国人民大学新闻与社会发展研究中心有合作关系”,实际上就是对本学科基本概况不了解所导致的。又如一篇以研究“新媒体”为主题的论文,在文献检索阶段仅仅将题名限定为“新媒体”,却忽略了“社会化媒体”“数字媒体”“网络媒体”等其他说法,无疑会遗漏大量有用的文献。这些现象都说明,如果对分析对象本身不了解,很大程度上会影响到后续研究结论的准确性和完整性。
另一个典型问题是数据库的选择问题,因为数据库的选择直接制约着结论的指向性。在本学科已有的51篇文献中,既有选择中文数据库作为数据源的,也有选择英文数据库作为数据源的。但无论选择何种数据库,最重要的还是研究议题和数据库的匹配。比如样本中一些研究“国际网络舆情”“国际社会化媒体”的论文都选择了Web of Science数据库,数据库和研究对象就是契合的。然而也有一些研究的数据库选择就值得商榷。以跨文化传播研究为例,姜飞等曾对跨文化传播的三种理论取径进行过详细辨析[39],吴予敏也指出,这是一个起源于西方而学术脉络复杂、学术传统多元的传播学研究分支[40]。然而一篇关于跨文化传播知识图谱的分析选取的却是国内的引文数据库,得出的结论多是关于国家形象、外交政策等“对外传播”的研究议题。相反,陈力丹等采用Web of Science数据库绘制出的跨文化传播知识图谱却显示,国家/民族间的文化差异、跨文化能力塑造、跨文化健康传播和跨文化教育才是国际主流研究的热点。同一个主题因为数据库的选择不同得出了截然不同的研究发现,这说明恰当的研究设计何其重要。
(五)研究者在不熟悉情报学基本概念的情况下贸然追逐新方法
科学知识图谱方法起源于情报科学,因此采用该方法进行知识计量分析的前提在于先掌握情报科学的基本概念和原理。然而遗憾的是,许多文章都误用了一些指标,最典型的是混淆了“被引”和“共被引”的概念。前文已经指出,当两个作者的文献同时被第三个作者的文献引用,则称这两个作者存在共引关系;如果这两位作者共被引频次越高,则说明他们之间的学术关系越密切。[41]因此“作者共被引”(Author Co- citation Analysis,ACA)这个指标本身是用于测量某个领域研究者之间的学术关联度和研究相似度的,而不是用于测量谁是核心作者的指标。然而在实际研究中,大量的文章将“作者共被引”指标用于侦测核心作者,混淆了“被引频次”和“共被引频次”之间的关系。同样,“文献共被引”是反映文献之间联系程度的指标,文献共被引频次越高,只能说明若干篇文献之间的联系越紧密。而当前大量的文章却将“共被引频次”(cited reference)当作“被引频次”来使用,认为“共被引频次”高的文献就是经典文献,这种说法十分值得商榷。
(六)过度依赖软件提供的分析功能而忽略了经典原理
任何一款软件所开发的功能都是基于一定原理来设计的,科学知识图谱软件CiteSpace也不例外。根据软件开发者的论述,CiteSpace的理论基础来源于库恩的科学范式转换理论、普赖斯的科学前沿理论、博特的结构洞理论、科学传播的信息觅食理论(information foraging)和赵红州提出的知识单元离散和重组理论。[42]但这些理论似乎都没有很好地体现传统文献计量学的几大基本定律,因此后续的软件使用者在进行知识计量分析时,反而很少去检验经典文献计量定律在当代的适用性。

(七)深陷方法本身而忽略理论关怀
一些研究者指出,当前我国传播学研究中存在“中心理论贫乏”的现象,“斤斤计较于技术与方法的正确,代价却是概念层次失之松垮”[46]。李金铨也感慨“现在的篇篇文章在技术上精致得无懈可击,却缺乏知识上的兴奋”。他将这种现象称为“毫无用处的精致研究”(elaborate study of nothing)。[47]因此,评价一篇论文的质量,不仅要看“方法的精致程度”,也要考察“理论的关怀程度”。[48]科学知识图谱作为一种知识计量与知识管理的手段,本身是用于探讨学科/领域结构、特征和规律的一种方法。即使对于情报科学本领域的研究者而言,也不是单纯地进行几个指标的数理统计,而是提出了诸如布拉德福定律、齐普夫定律、加菲尔德定律等若干理论。因此,在采用科学知识图谱方法时,如果仅仅停留在对若干指标的输出与呈现上,就难以解释研究对象在分布结构、数量关系、变化趋势等方面的规律。就目前新闻传播学界对这一方法的使用而言,绝大多数的研究者都没有成熟的理论框架作指导,而是一上来就开始对各个指标进行分析,而后对得出的数据进行一番描述后便匆匆结束行文。这样一来整个研究虽人人皆可重复,但失去了理论兴奋和创新价值。不过好在当前已有少数研究者认识到这一问题,张小强指出当前研究“在方法上不够规范,没有体现理论”[49],并在实践中身体力行采用“创新与扩散”理论对新媒体研究议题进行规范的科学知识图谱分析。尽管这些尝试是局部的、零星的,但终究是一种可喜的进步。
六、研究发现小结
过往学界常用的定性文献综述方法由于主观性强的问题屡屡饱受诟病,而传统的文献计量分析,往往需要借助UCINET等软件进行社会网络分析和SPSS软件进行多维尺度分析(multidimensional scaling)[50],不仅数据的录入费时费力,而且软件之间切换也极不方便。自从科学知识图谱方法诞生后,一些学者仿佛发现了新大陆般奉若神明。于是,一股采纳科学知识图谱的热潮正在我国悄然兴起,新闻传播学自然也不例外。
本文研究发现,当前新闻传播学科使用科学知识图谱方法的研究还处于起步阶段,总体而言数量较少但增长势头较好,预计未来将有更多的研究涌现。在研究议题方面,学界聚焦的议题相对集中,但存在明显的追逐流行概念和热点现象——新媒体和舆论/舆情研究成为最主要的关注话题,其他议题则呈长尾分布。研究主体方面,在这个多元学科参与的研究中,新闻传播学者经历了一个从“跟跑”到“领跑”的过程。最初图书情报学和经济管理学研究者抢先涉足新闻传播学议题,而后新闻传播学研究者奋起直追,实现了从回归到超越的转型,成为本学科的研究主力。在研究机构方面,新闻传播学科传统名校和图书情报与档案管理学科的传统名校均占据主导地位。其中中国人民大学新闻学院是发文量最多的机构。在载文期刊方面,70%以上的论文由CSSCI来源期刊(含拓展版)登载,这体现了核心期刊善于接纳新兴事物的敏锐眼光。载文量最多的两本期刊均为新闻传播学专业的核心期刊《新闻与传播研究》和《国际新闻界》,体现了本学科核心期刊引领学术前沿的使命担当。在作者合作关系上,70%以上的论文均为合著完成,但合作关系集中表现为同一机构的师生关系和不同机构相同学科的同事/朋友关系,跨学科的合作付诸阙如,这显然并不利于学科发展和学术创新。
在对全部论文的分析指标(特征项)进行梳理后,本研究构建出一个统摄性的分析菜单。后来的研究者可以参考这一菜单里的内容选择适合研究对象的分析指标(参见上表1)。
每个学科都有自己的研究范式和研究方法,同时也包容和接纳其他的研究范式。然而在引入一种新的研究方法之初,我们有必要清醒地认识到该种方法的历史渊源、适用范围和局限性。从文献回顾中我们看到,早在10多年前科学学领域就对科学计量的方法进行了反思,这场反思中提出的“概念误用”“技术至上”“重复验证”等问题在科学知识图谱这种新兴方法诞生后依然存在,并且渗透到新闻传播学界。这不得不引发我们的高度重视。其实对于研究方法的反思,在新闻传播学界一直都绝非是可有可无的工作。早在2009年,尹韵公就在主编当期的《新闻与传播研究》中引用一位经济学家的说法指出,“有的论文列出一大堆数据,最后得出的竟然是连小学三年级学生都知道的常识,对于这种定量分析已被列为不良学风之一”。作者进而指出,任何方法都有其时代性和局限性,我们应该实事求是地运用。[51]客观来看,科学知识图谱作为一种新兴的研究方法,在探查知识前沿、勾勒知识现状、识别知识节点方面具有一定的优势,但它并不是完美无缺的。比如对于“关键词共现”“作者共被引”“期刊共被引”“文献共被引”等几个常见对象八股化、公式化地套用分析,运用同一种研究套路,只是换不同研究对象的那种万能研究,容易退化为一种纯粹的技术炫耀,并不会为学界贡献智识。因此,如果固守“方法先行”的立场毫无保留地拥抱这种新方法,反而会影响我们对本体问题的发现和判断。
笔者认为,尽管科学图谱的方法为学科/领域知识结构的呈现和发掘提供了一个便捷的途径,但在具体的应用中仍然存在着诸多问题,见图6。

图6 科学知识图谱在新闻传播学科应用中的常见问题
首先,从方法本身的应用取向来说,科学知识图谱最大的优点在于避免了研究的主观性和降低了人工统计成本。但万物都有利有弊,作为一种揭示学科概貌的方法,科学知识图谱固然具有“窥全豹”的全景扫描功能,但其并不擅长提炼研究观点、呈现细节脉络。因此,未来的研究还是需要将科学知识图谱的方法与传统综述的内容分析相结合,才既有助于关照研究对象的全貌,也有助于剖析研究对象的纹理。
其次,在采纳科学知识图谱的配套环境方面,国内的数据库还有许多亟待补齐的短板。目前一个相对可行的权宜之计,是将中国知网(CNKI)数据库和中国社会科学引文索引(CSSCI)数据库结合起来相互补充。针对部分缺失的数据,甚至需要通过查找原文来人工补充引文数据。
第三,科学知识图谱软件的应用,前提条件是研究者必须熟悉软件的各项功能。在利用软件分析出结果后,如何恰当地呈现出可视化效果图,很大程度上取决于每一位研究者的经验和能力。比如在控制面板中对作者、关键词、被引文献等指标的参数进行调节时,具体选择哪几个单位的分析对象,如何根据不同研究对象设置不同阈值等,这些都无章可循,全靠研究者个人的既往经验。如果阈值设置过高,导致分析对象入围数量较少,就难以看出研究对象的全貌;如果阈值设置过低,致使过多的分析对象涌现,反而一团乱麻难以洞察核心实质。因此,软件的可视化呈现最终还是依赖于研究者本人的主观能动性。
第四,热衷于炫耀研究方法而忽略学术积累。科学知识图谱软件的使用有一套相对规范的流程,单从操作上讲,只要掌握这套流程的使用规范就可以对任意一个研究领域进行计量分析。然而软件的计量分析仅仅是揭示学科概况的第一步,解读分析结论比简单的计量统计更重要。面对一大堆计量结果,如何去解释现象、分析原因、总结规律,这些都离不开研究者平日里对该领域的关注和积累。然而现实中有一些人仅凭着对新兴方法的满腔热情就投入到短平快的学术生产中去,从研究设计到结论解读上都有诸多不规范之处。
第五,“数据驱动型”研究需要上升至“理论指导型”层面。科学知识图谱本质上是一种量化研究方法,但并不意味着这种方法就不需要理论指导。传统的定量研究都需经过理论假设——研究假设——研究设计——数据搜集与分析的系统流程,文献计量分析的研究也不例外。文献计量学中早已诞生了布拉德福定律、齐普夫定律、洛特卡定律等经典理论,至今还有不少情报学研究者对这些定律进行检验、修正和完善。而反观新闻传播学的知识计量研究,在科学知识图谱方法诞生后似乎忘却了这些经典定律,反而是之前未使用软件的研究者采用人工统计的方式检验了这些定律[52]。这种现象不得不引人深思。
七、超越科学知识图谱:混合研究路径的设想
陈刚在对广告学研究方法进行反思时指出,从没有研究方法到学习尝试使用方法,是“自觉”阶段;从模仿借鉴研究方法到质疑研究方法,是“反思”阶段;从反思和批判研究方法到调整和创造研究方法,是创新阶段。[53]笔者认为,这项总结不仅适用于广告学研究,而是适用于整个新闻传播学领域。反思之后是创新和超越,对于科学知识图谱存在的种种瑕疵,除了呼吁研究者正确规范地掌握该领域的各个术语及其软件应用之外,从方法本身存在的先天缺陷来看,笔者还倡导一种将传统的定性文献综述与科学知识图谱相结合的混合研究路径。
传统的定性文献综述强调个体在理性认识能力和研究经验的基础上,通过对概念和观点的总结和梳理之后来阐述自己的思想。而科学知识图谱强调对各个分析单元的结构、关系等进行测量和计算,从而探索知识演进的规律和特点。两者都是一种实证研究的取向,都需要对文献信息进行搜集、解释和呈现,只是各自的诠释角度不同罢了。
文献计量的客体是一篇篇文献,科学知识图谱的方法可以将这些文献中的知识单元一一量化展现;文献计量的主体又是作为人的研究者,研究者选择什么研究主题、选择什么分析单元,又是一个主观的价值选择过程。文献计量主观性和客观性的一体两面,正好说明了混合研究路径的可行性。实际上,思辨和定量的路径本身就是从“应然”和“实然”的不同角度对研究问题进行探索。科学知识图谱的定量研究有利于实现文献梳理的客观性和全面性,而思辨的方法有助于审视和反思定量统计的结果,一个是事实呈现,一个是价值判断,而且思辨研究必须以事实为证据,定量研究必须以理论为指导,两者互相补充、相辅相成。
混合研究兼具定量、定性和思辨研究的特点,可以在一个研究中发挥互补的功效,被一些学者称为“第三种研究范式”[54]。而且混合研究路径比单一研究方法得出的结论更合理,提升了研究过程和结果的科学性。[55]对于学科/领域的知识管理和知识评价而言,在运用量化的科学知识图谱方法进行数据搜集和统计分析的同时,运用思辨的方法探索问题的深度和广度,有助于提升整体研究的严谨性和科学性[56]。因此笔者呼吁,未来的治学者在进行知识梳理和总结的过程中,可以尝试将传统的文献综述与科学知识图谱相结合,既保证研究的客观性和全面性,又兼具研究的深刻性和思辨性,从而最大限度地发挥知识管理和知识评价的功效。
最后,无论是对科学知识图谱的批判和反思,还是对混合研究路径的构想,归根到底都昭示着同一个指向,那就是:无论研究对象如何变幻多端,研究方法如何推陈出新,我们始终需要重视研究主体——人的核心地位。
虽然科学知识图谱软件为研究者节省了大量时间精力,但其依然无法替代人在研究中的主体地位。因为软件只是方便人们进行知识管理的工具,而知识管理的主体依然是人类自身。一味依靠软件分析不仅容易导致研究发现流于浅表,而且也会遮蔽许多有价值的信息,甚至会因为操作不当而得出南辕北辙的结论。正如在临床医学领域,影像学和实验室检查虽功能强大,但传统的问诊查体也是必不可少的环节。
当前,我们已经进入到一个拥抱大数据和人工智能的时代;不过科学技术的进步始终都无法取代人类本身的思辨意识和分析能力。在机器算法和人工智能横行的时代,有学者疾呼新闻学是人学,新闻权力应该归于人而不是数据和机器。[57]传播学研究同样如此。在日新月异的科学技术冲击下,虽然研究范式和研究方法发生了变化,但作为研究主体的人的地位始终没有改变。相反,只有把先进的科技成果与传统的人类智慧结合起来,科学研究方能起到洞幽烛微、探骊得珠之效。
