基于多线程和翻译的网络爬虫鸟类音频数据采集系统设计与实现
2018-11-20刘江刘国玺张雁吕丹桔
刘江,刘国玺,张雁,吕丹桔
(西南林业大学大数据与智能工程学院,昆明 650224)
0 引言
随着信息技术,网络技术的发展,Internet成为汇聚信息的中心载体。如何高效便捷地收集和提取In⁃ternet上的信息,是一项巨大的挑战。网络爬虫是按照一定规则,能够自动地对万维网网页信息进行下载的计算机程序或脚本。聚焦网络爬虫是在网络爬虫的基础上设计的,可以按照用户需求选择性地对网页信息进行提取,极大地节省了资源[1-3]。因为建立鸟类声音样本库和鸟鸣分类识别系统都需要大量的鸟类音频数据作为支撑,通过对鸟类声音爬取关键字信息的搜索,未能搜索到有关鸟类声音爬取的程序或脚本。在考虑实际运用的情况下,本文采用多线程、网络爬虫、翻译等技术设计并实现了鸟类音频数据采集系统。该系统的建立有助于丰富鸟类声音样本库,最终实现花费较少资源能够大量获取关于鸟类音频文件和鸟类信息的目标,解决了人工采集声音效率低、投资大、风险高、质量差,人工对鸟类音频数据搜集、整理速度慢、耗费时间长、工作内容繁琐等问题。
1 系统设计的目标功能
鸟类音频数据采集系统的目标是通过网络爬虫抓取互联网上鸟类的音频数据,构建丰富的鸟类声音样本库。由于鸟类音频数据的数据量比较大,本文在设计鸟类音频数据采集系统的时候综合考虑了相关因素,把采集系统建设分为两个部分:一是数据抓取[4]部分,二是数据下载部分。该系统为了在硬件环境的支持下能够最大限度地提升程序运行速率设计了多线程控制器[5];为了解决获取外文网站信息时使获取的信息能够符合中文的语义表达方式的问题设计了翻译模块[6],对提取的信息进行翻译处理。设计URL[7]管理器对URL进行管理,HTML获取器下载页面,HTML解析器解析下载的页面,存储模块[8]数据库存储资源,下载器下载相关内容。
数据抓取部分在URL入口输入进入URL后开始工作,抓取到与该URL相关的网页信息,解析提取所有URL和所需数据,翻译器对所需内容进行翻译,最后把音频数据的URL和相关信息提取保存到数据库中。数据下载部分通过对数据库信息的读取,URL管理器处理后交给下载器进行下载。
2 系统的流程设计
为了解决鸟类音频文件的数据量较大,爬取页面较多,爬取外文网站信息时不符合中文的语义表达方式等问题设计鸟类音频数据采集系统,其基本流程图如图1所示:

图1 系统基本流程图
本系统分为数据抓取部分和数据下载部分。数据抓取部分包括六个模块:URL管理中心、HTML获取器、HTML解析器、多线程控制器、HTML翻译器和数据库存储,这六个模块共同完成数据抓取并存储于数据库的整个过程。数据下载部分包括四个模块:数据读取、URL管理中心、多线程控制器、文件下载,这四个模块完成数据下载到本地的整个进程。
2.1 数据抓取部分
(1)URL管理中心
为了解决URL指向循环和URL重复等问题设立URL管理中心,URL管理中心的作用是管理待爬取的URL和已经爬取过的URL,每个网页爬取的信息都包含指向其他网页的URL,其他网页同样会包含指向本网页的URL。这样URL的指向就存在循环,严重影响网络抓取数据的速度,当两个URL相互指向形成无限循环,就会导致程序运行出错。设计URL管理中心能够很好的解决这个问题,防止程序运行出错。
(2)HTML获取器
HTML获取器负责把网页中对应的信息下载到本地,这是整个爬虫的核心部分。它从互联网上查询URL对应的网页,将其内容按照HTML的格式下载到本地,便于后续分析处理。
(3)HTML解析器
HTML解析器对HTML获取器下载的页面进行解析,提取出页面中包含的URL和数据。本系统实现的是定向网络爬虫,除了提取页面中待爬取的URL,还提取了很多实验所需数据。
(4)多线程控制器
为了解决程序运行的速率问题,减少运行时间,提高效率,本系统设计多线程控制器。多线程控制器的功能是对爬虫程序的线程数加以控制,根据数据要求和系统性能对程序进行控制,最大限度的提高程序运行速率。
(5)翻译
针对搜集外文网站数据时语言、语义不同且不符合中文的语言表达方式,分析理解这些数据困难等问题设计翻译模块。此模块负责对HTML提取解析后的数据进行翻译、注解。在翻译模块中调用百度翻译的API[9]实现对提取出来的内容进行翻译,翻译之后将数据提交到数据库进行存储。
(6)数据库存储
为了存储和读取数据方便设计数据库模块,数据库是根据实际需求设计,能够对翻译器提交过来的数据进行存储。
2.2 数据下载部分
这部分实现的是对数据库中数据的读取与下载,读取数据库中保存的信息和URL,将读取信息提交给URL管理中心对URL进行管理,多线程控制器对下载程序进行控制,音频文件下载是为了实现对数据库中的URL进行访问,下载鸟类音频文件。
2.3 数据抓取流程
数据抓取部分流程如图2所示,由流程图可知在爬虫程序中,URL管理器用来管理待爬取的URL列表和已经爬取过的URL列表,从URL管理器中取出URL,判断该URL是否被爬取过,如果是未爬取过的URL,则将此URL发送给HTML下载器。HTML下载器对该URL指定的网页进行下载存储在本地服务器中,HTML解析器对下载器下载的页面进行解析,解析出网页内容和URL,解析器把URL提交给URL管理器,只要URL满足程序运行条件程序就一直运行,对网页进行下载、解析、翻译最后保存到数据库,直到程序结束运行。
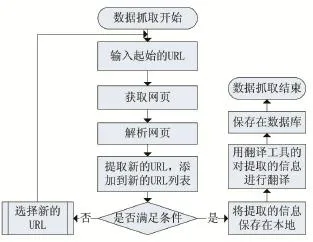
图2 数据抓取流程图
2.4 数据下载流程
数据下载流程如图3所示,由数据下载的流程图可知系统从数据库中提取数据,经URL管理器处理之后,把URL传递给下载器直接访问音频数据的URL对鸟类音频数据进行下载,直到所有数据下载完成结束程序。
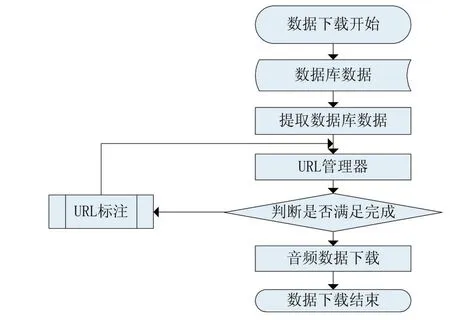
图3 数据下载流程图
3 多线程和翻译的实现
为了提升程序运行的速度,在串行网络爬虫的基础上,设计多线程网络爬虫程序。爬虫程序开始执行后,程序向网页发送访问的请求,程序等待网页做出响应。根据等待的时间来衡量爬虫的效率,等待的时间越长,效率就越低。当程序采用多线程的时候,程序与网页进行通信等待的时间有所降低,提高了数据抓取的和数据下载的效率。
当搜集目标网站的数据信息的语言与系统所需信息的语言不一致时,需要对爬虫收集的数据进行加工处理,使其符合中文的语义表达习惯,但人工对数据进行整理,翻译需要耗费较多的人力、物力,增加实验任务。在网络爬虫程序中增加翻译模块可直接对网页数据进行翻译,使其符合中文的语义表达方式、语义规则。翻译模块的实现是通过调用百度翻译的API对数据进行处理的,通过调用API编译程序代码实现翻译功能,最终满足于实际运用的需求。
4 系统测试
软件测试环境如下:操作系统:Windows 10家庭版;CPU:I5 4700M;内存:8G;网络带宽:100Mb;应用工具:Python 3.6。
在考虑了计算机的硬件配置和数据应用的情况下,测试分为对国内网站爬取和国外网站爬取进行。
4.1 对某国内声音网站的爬取
表1为爬取某国内网站的实验数据,表2是为下载某国内网站的实验数据。

表1 某国内网站数据爬取

表2 某国内网站音频文件下载
4.2 对某国外声音网站的爬取
表3为爬取某国外网站的实验数据,表4是为下载某国外网站的实验数据。

表3 某国外网站数据爬取

表4 某国外网站数据下载
4.3 测试结果分析
本系统分别爬取国内和国外网站数据进行测试实验,经过系统爬取整理之后实验数据满足具体应用需求。实验中耗费较少的时间资源能够爬取到大量的信息,多线程爬取和下载都速率都比较快,耗费资源少。人工对实验结果进行查看,发现爬取外文网站的信息符合中文的表达规范和语义要求,综合来看本次实验结果满足系统建立的需求。实验研究发现当线程数达到一定程度时数据的下载速度与网络带宽有关,受网络带宽[1]的影响。当线程数达到200,下载速度通过360测速工具测试知道速度为8000KB/s,接近当前带宽的最大速率。在调用不用翻译工具对数据进行翻译的对比实验中,我们发现很多专业名词的解释更加符合中文语言规则的是百度翻译工具。
5 总结与展望
鸟类声音样本库的丰富度决定鸟鸣分类识别系统的识别效果,基于多线程翻译网络爬虫的鸟类音频数据采集系统的设计与实现解决了在万维网上获取鸟类音频文件,鸟类知识信息等问题,丰富了鸟类声音样本库。本系统的建立,能够便捷高效地获取鸟类音频数据,满足具体应用需求,解决了人工采集声音效率低、投资大、风险高、质量差,人工对鸟类音频数据搜集、整理速度慢、耗费时间长、工作内容繁琐;人工处理翻译外文数据效率低、耗费资源多等问题。
