网络用户自描述标签向量生成及标签层次体系构建方法*
2018-11-19裘杭萍王沁雪
孙 毅,裘杭萍,王沁雪
(1.中国人民解放军陆军工程大学 指挥控制工程学院,江苏 南京 210000;2.山东省莱芜市实验中学,山东 莱芜 271100)
0 引言
随着信息技术和社交媒体的快速发展,世界已经进入了网络化的大数据时代。面对呈指数级增长的数据,人们需要更加有效的方法对所拥有的数据信息进行快速准确的分类,便捷地提取出实时、精炼、对商业分析有价值的知识,并且做到对网络和信息的安全管理与控制[1],因此网络用户标签(Network User Hashtag)应运而生。
网络用户标签是用户网络资源的描述,一般以词组、短语或短句子的形式出现。其中被描述的网络资源对象大致可分为两种:一是多媒体资源,如文本、视频、音频等;二是实体资源,如人物、网络用户或网络购物商品等。通过用户标签,可以迅速掌握网络资源的情况,更方便地检索出用户需要的内容。
对网络用户标签的研究一直是近几年来国内外信息检索领域的热点,将网络用户标签化来构建用户画像以实现对用户进行内容推荐及个性化服务就是其中一个重要的课题。随着用户自描述标签的普及,越来越多的学者开始对其进行研究。刘列等人基于约263万个微博用户的真实数据,对用户标签的分布进行了研究和分析,发现了基于关注关系的标签预测算法[1];池雪花等人对不同学科领域的用户标签标注行为差异进行了研究[2];刘苏祺提出一种基于社交网络中用户自描述标签的层次分类体系构建方法[3];GONG Y等人提出了用户标签和微博文章主题之间的转换方法来对用户进行推荐[4];刘慧婷等人通过衡量用户好友兴趣相似度和提取用户博文主题来构建用户标签矩阵对用户进行标签的推荐[5]。
目前关于网络用户自定义标签的研究主要集中在基于用户标签的抽取和推荐方面,而对用户自描述标签本身缺乏内在关系的分析和知识层的挖掘。因此,针对在网络用户自定义标签层次分类过程中低频标签利用率低的问题,本文尝试利用低频标签扩展理解的方法,构建网络用户自描述标签的层次分类体系。
1 标签向量生成方法
近几年的研究中,多种词向量方法应用广泛,目前最常用的模型为Word2Vec模型[7]和Glove模型[8],二者都是基于词共现假设的无监督学习方法,可以很好地表征词与词之间的距离关系。词向量的出现带动了句向量和其他粒度层面的文本向量模型的出现,并很好地运用到了文本相似度计算、文本分类和文本情感分类等领域。目前主要的句向量生成方法有4类:简单向量平均、无监督学习方法、有监督学习方法以及多任务学习方案[9-11]。
目前,基于平滑反频率的句向量生成方法在文本相似度计算和文本分类任务上的表现已经超过TF-IDF权值平均和有监督的RNN、LSTM、skip-thought方法[12]。平滑反频率句向量通过权重将词向量加权为句向量,权重计算公式如下:
(1)
其中a为常量参数,可根据任务进行调节;p(w)为单词w经过大量领域文本统计后的频率,即单词w的权重与其频率呈反比。由于用户自描述标签的短文本特性,本文基于平滑反频率句向量生成方法,设计了用户标签向量的生成方法,生成的标签的向量用于之后的标签体系构建。
本节标签向量的生成框架以及其中包含的组件如图1所示。首先通过词频统计将标签组集合分为高频标签和低频标签。高频标签直接使用词向量集中的向量,并将该标签扩充到分词器的词库中。同时将低频标签通过设定的规则转换为高频标签组成的词组,然后通过向量合成的方法生成标签向量。
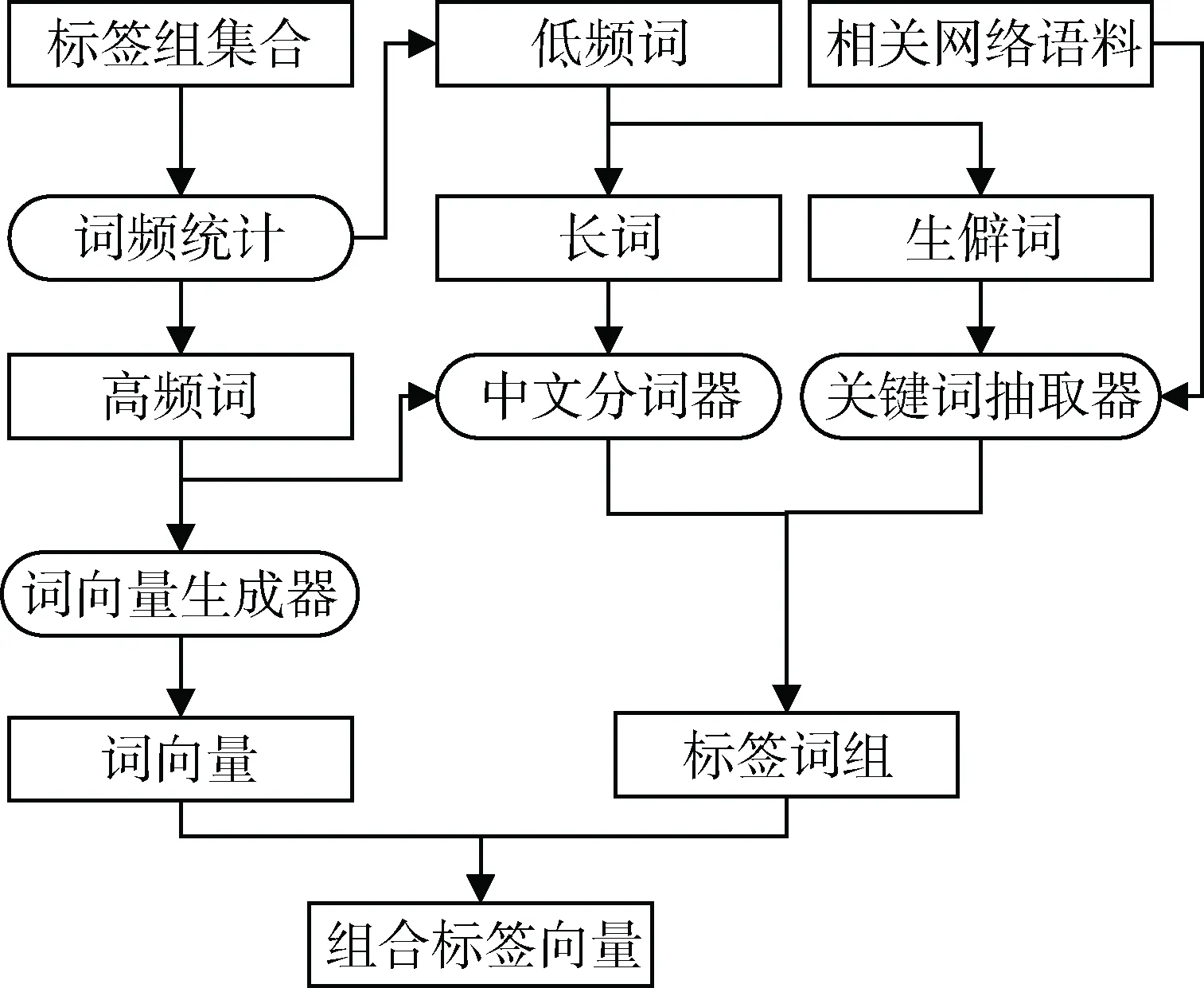
图1 标签向量的生成框架
1.1 数据预处理
通过爬取新浪微博用户的信息数据,得到13万条用户信息,过滤掉没有设置用户标签的用户,得到86 517个标签组。对标签集进行词频统计,得到如图2和图3所示的统计结果。可以看出,出现频率在100次以上的标签仅占总标签数量的0.306%,而仅出现1次的标签占67.700%。由此可见,对于大多数网络用户自定义标签来说,都是“罕见”的,充分反映了用户自定义标签的自由性和语义上独特性。
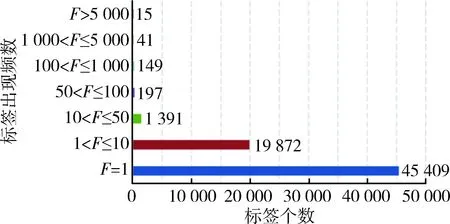
图2 标签频率分布

图3 高频标签频率词云
1.2 词向量生成
本文运用Word2Vec模型对维基百科[12]中的30万篇中文语料进行训练得到包含104万个中文词语的词向量集合,每个词向量的维度为200维。将该词向量集定义为:
WS={W1,W2,…Wi,…Wk}
(2)
式中Wi表示词集中第i个词的词向量。
WVi=|wi,1,…,wi,j,…,wi,200|
(3)
1.3 标签分类
本文将标签划分为高频标签和低频标签。其中高频标签表示在用户标签中出现频率较高的,且和由语料库的词向量集中的词所对应的,即语义较为明确的标签。低频标签又分为组合标签和生僻标签,组合标签是由高频标签组合而来的标签,如“游戏动漫”,这一标签由“游戏”和“动漫”两个高频标签组合而来。生僻标签指在词向量集中没有对应词的标签,即语义上难以理解,一般来说多为网络俚语,或者针对性较强、受众较少的词语,这类词在语料库极少出现甚至不存在,因此得不到很好的训练。
本文给定3类标签的划分依据如下:
依据一:标签tagi在词集中存在对应的词Wi的为高频标签。高频标签集定义为TS_HF={tag1,…,tagk}。
依据二:标签tagi通过分词器进行拆分后的词中存在高频标签的为组合标签。组合标签定义为TS_CB={tagk+1,…,tagl}。
依据三:标签在词集中没有对应的词且拆分的词中不存在高频标签的为生僻标签。生僻标签定义为TS_UC={tagl+1,…,tagm}。
1.4 分词及语料扩充方法
本文的中文分词器采用国内开源的“结巴”中文分词工具对组合词进行分词[11],分词后词语都带有词性标记。对组合词进行分词处理后去除非高频词,再去除停用词,得到由高频词组成的标签组group(tagi)={tag1,…,tagp}。
将低频标签词tagi提交到搜索引擎中,对搜索结果的文本内容进行关键词抽取,抽取算法采用TF-IDF算法。剔除抽取返回的关键词中不存在于词集WS中的词和其本身,取前5个作为该词的扩展词组extended(tagi)={tag1,…,tag5}。
1.5 词组向量
将组合标签的组合词组和生僻标签的扩展词组组合成词组向量,用于词组标签和高频标签之间距离的计算和标签体系的生成。由于用户自定义标签相对较短,绝大数情况下一个标签中的子标签仅会出现一次,因此很难用单个标签中各个子标签的频率来衡量其对父标签的重要程度。本文基于平滑反频率句向量的权重计算思想定义标签向量组合规则如下:
(1)组合标签向量TV_CB
(4)
(5)
(2)生僻标签向量TV_UC
(6)
(7)
其中f(tagi)表示标签在整个数据集中出现的频率;f_e是通过TF-IDF算法得到的关键词的权重,此处对权重进行归一化处理。
参数a根据论文[12]的经验设为10-3。
2 标签分层体系建立方法
标签体系的建立过程包括标签之间上下位关系的确定和标签树的最终生成。
2.1 上下位关系检测
一般意义上词与词的上下位关系是指词与词之间在语义上的从属关系[13]。即词A和词B在语义上满足“B是一种/类/个A”,则称A与B之间有上下位关系,其中A是B的上位观念(hypernym),B是A的下位概念(hyponym),B是A的类别,A是B的实例,“是一种/类/个”等表述方式成为上下位关系的模式。上下位关系抽取是关系抽取的一种,单独抽取上下位关系是一个二分类问题,判断上下位关系关键在于特征的选取。关系抽取的方法主要出发点有2个:一是基于词语间的共现性,另一个是基于词语间的模式。
由于词语间的关系较为复杂,两个词共同出现的原因可能有很多,单纯基于共现关系和距离去判断词语的上下位关系效果并不好。因此,本文通过提取关系模式的方法来进行上下位关系分类。首先,人工选取数量相同的具有上下位关系的(正例)和不具有上下位关系的(反例)标签对,将这些标签对作为关键词提交搜索引擎来获得包含标签对的语料。然后通过均方差选择的方法提取上下位关系的关键模式。通过将带有上下位关系标记和特征向量的标签对交由分类器训练出分类模型。
2.1.1特征向量选取
对于任意标签对TPij={ti,tj},本文选取的特征向量TP_Feature包含3类特征:标签对向量距离、标签对出现的前后位置关系、标签对模式出现频率。TP_Feature=[TP_Dist, TP_Adj, TP_Sep, TP_Mod]
(8)
(1)标签对距离TP_Dis(ti,tj)通过计算标签向量间的余弦距离得到,
TP_Dist(ti,tj)=cos(ti,tj)
(9)
(2)标签对ti和tj出现的前后位置关系包括2种情况:一是两者相连组成词语titj或tjti的情况;二是两者之间存在某类模式组成句式ti…tj或tj…ti的情况。分别定义两种情况下的特征变量
(10)
(11)
其中分子均表示ti在tj前的频率,分母表示tj在ti前的情况,比值用反正切函数归一化。
(6)标签对模式TP_Mod(ti,tj)是由上下位关系中关键模式出现的频率组成的向量,
TP_Mod(ti,tj)={Mod1,…,Modk}
(12)
2.1.2基于均方差选择的模式排序方法
在模式筛选的过程中存在大量的噪声,通过方差选择的方法对这些模式进行排序以提高分类的效果,其方法如下。
对于模式Modi,其出现在正例和反例中的概率分别为P(Modi|Pos)和P(Modi|Neg),则其模式概率均方差为:
(13)
其中X1=P(Modi|Pos),X2=P(Modi|Neg)。
根据均方差的大小对模式进行排序,方差越大的模式对于上下位分类的贡献越大,本文选取前5种模式作为特征向量中的关键模式。
2.2 标签树构建方法
标签树的生成过程中,将标签频率作为标签节点的权重,通过自顶向下、由重到轻的方法将节点插入到树中。
算法1标签树构建
输入:T={tag1,…,tagk},F={f(tag1),…,f(tagk)},TV={tv1,…, tvk},Classifier
输出:Tag_Tree
1:funcion TRAVEL(node,tag)
2: if Classifier(node,tag)=Truethen
3: Flag1←False
4: for child in node.children
5: if Classifier(child,tag)= True then
6: Flag1←True
7: break
8: end if
9: if Classifier(tag,child)= True then
10: add child to tag.children
11: del child from node.children
12: return
13: end if
14: if Flag1=True then travel(child,tag)
15: else add tag to node.children
16: end if
17: else
18: Flag2←False
19: for child in node.children
20: if Classifier(child,tag)= True then
21: Flag2←True
22: travel(child,tag)
23: break
24: end if
25: end for
26: if Flag2=false then
27: node←the nearest node in node.children
28: travle(node,tag)
29: end if
30: end if
31:end function
32:
33:function BUILDTREE(T,F,TV,Classifier)
34: Tag_Tree←?;
35: sortTasFand reverse=True;
//将T按照频率逆序排序
36: whileT≠?
37: tag←T.pop();
38: node←Tag_Tree.root;
39: TRAVEL(node,tag)
40: end while
41:end function
算法1中T表示标签集,F表示标签频率集,Classifier(tag1,tag2)为标签上下位关系分类器,当tag1为tag2的上位标签时返回True,否则返回False,TV表示标签向量集,Tag_Tree表示标签树。
TRAVEL(node,tag)为标签树的遍历和节点插入的递归函数,BUILDTREE(T,F,TV,Classifier)为构造树的主函数。
该算法首先将标签集按照标签频率从大到小排序,然后每次取出频率最大的标签tag,从标签树的根节点Tag_Tree.root开始遍历(第34~40行),在遍历过程中存在4种情况,情况一如图2(a)所示(图中箭头由下位标签指向上位标签),在标签“喜剧”的插入过程中,标签“艺术”为标签“喜剧”的上位标签,且“艺术”的子节点中无“喜剧”的上位标签或下位标签,将“喜剧”加入到“艺术”的子节点中(第15行);情况二如图2(b)所示,在标签“电影”的插入过程中,“艺术”是电影的上位标签,而“喜剧”是“电影”的下位标签,将“电影”插入到“艺术”和“喜剧”之间(第9~13行);情况三如图2(c)所示,在节标签“摇滚”的插入过程中,“艺术”是“摇滚”的上位标签,同时“艺术”的子标签中的“音乐”也同样是“摇滚”的上位标签,算法将递归地遍历节点“音乐”(第3~7,14行);由于标签上下位传递关系不够强,并且分类器在上下位关系识别时可能会出现错误,将无法找节点到上下位关系的情况归为情况四,此时将会继续遍历子节点中与该节点距离最近的一个(第26~28行)。
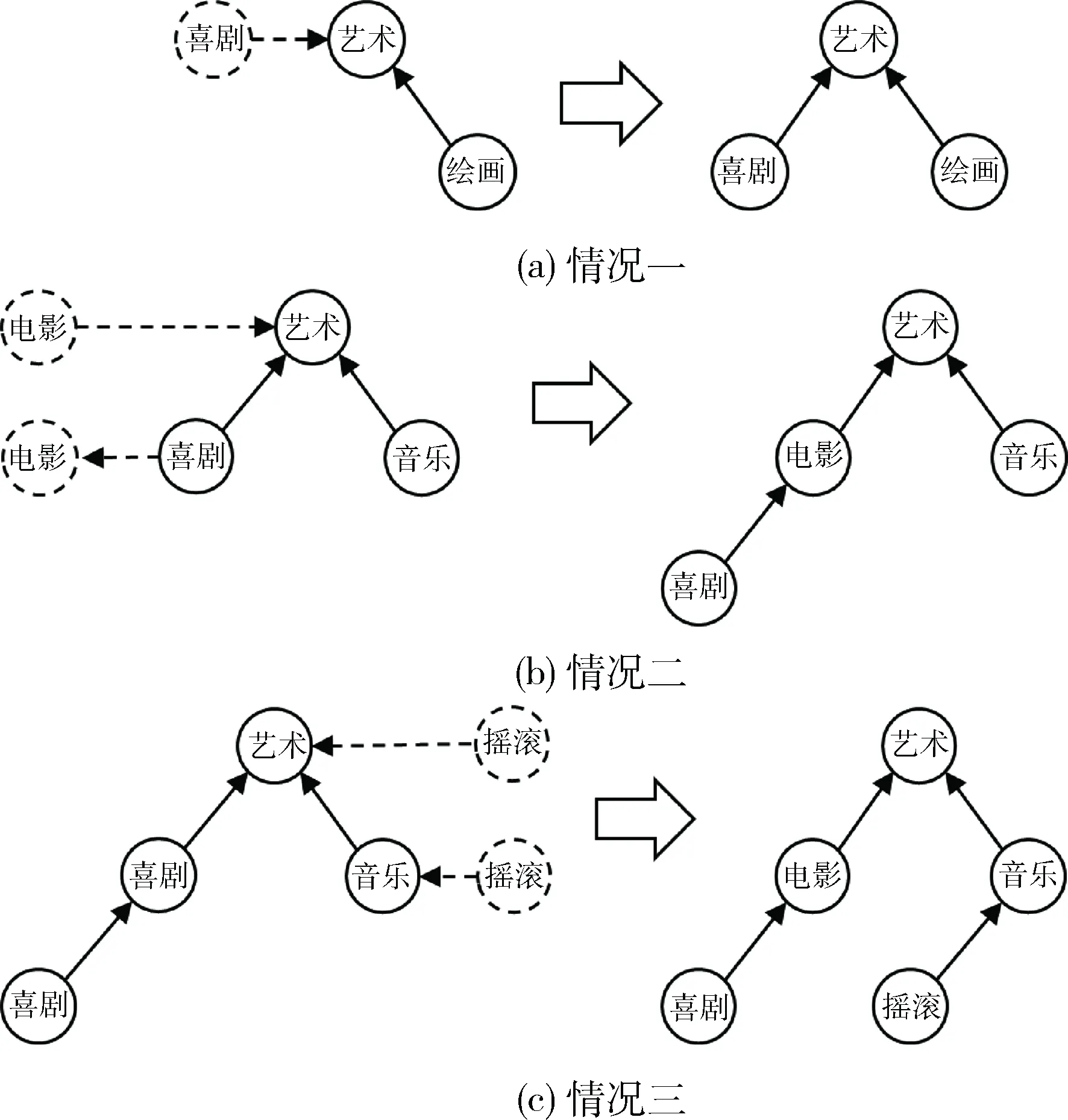
图4 标签树节点插入过程
3 实验结果与分析
3.1 实验数据与预处理
本文的实验数据抽取自网易微博[13],共有标签67 074 个,由于标签对的个数是标签个数的平方,有数十亿个,但在这些标签对中,是上下位关系的标签只占极少一部分,存在严重的类别不平衡问题,因此本文只选出了出现频率较高的200个标签,组成了700个标签对,通过人工标准的方法得到正例165个,反例535个,运用所选标签对进行模式提取。
3.2 实验结果与分析
3.2.1上下位关系特征选择
通过模式提取得到关键模式Key_Model={“的”,“是”,“是一”,“称为”,“是什么”}。
标签对的特征向量为TP_Feature = [TP_Dist,TP_Adj,TP_Sep,Mod1,Mod2,Mod3,Mod4,Mod5],共8项,例如TP_Feature(绘画,艺术) = [0.166,0.999,0.999, 0.169,0.128,0.032,0.010,0.013],TP_Feature(听歌,看书) = [0.204,0.787,0.729,0.010,0.039,0,0,0]。
3.2.2实验设置
本文分别采用支持向量机(SVM)、决策树、随机森林(Random Forest)、极端随机树(Extremely Randomized Trees)和BP神经网络5种方法对标签进行上下位关系的分类。除了BP神经网络采用TensorFlow框架,其余算法均采用Python中的sklearn开发包。
极端随机树、随机森林和决策树均采用回归模型。极端随机树和随机森林参数设置大致相同,最大迭代次数为10,特征的评价标准为均方差MSE,划分时最大特征数为8,不限制最大决策深度,内部节点再划分最小样本数 2,叶节点最小样本数为1,判断阈值设为0.6。决策树的特征的评价标准为均方差MSE,节点分类策略为最好分类,内部节点再划分最小样本数 2,叶节点最小样本数为1,判断阈值设为0.6。
支持向量机采用高斯核函数,核函数系数为6,SVC的惩罚值为1,停止训练误差为10-3,无最大迭代次数限制,决策函数为OVR。
BP神经网络采用全连接的四层结构,2个隐藏层节点均为20个,采用双曲正切函数作为激活函数,学习率为0.1,损失函数为均方误差,输出阈值为0.7。
3.2.3结果分析
实验通过循环Hold-Out检验的方法,每次将数据集随机分为训练集和测试集两部分,分别为70%和30%,共循环100次,统计5种分类器的精确度ACU、查准率Precision、查全率Recall和F1值的平均值,结果如表1所示。其中精确度如图5所示,其他三项指标如图6所示。
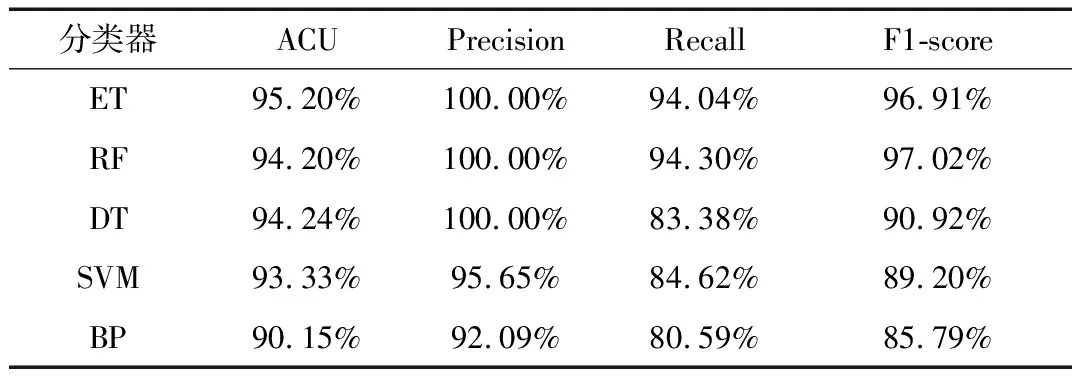
表1 标签上下位关系检测算法效果
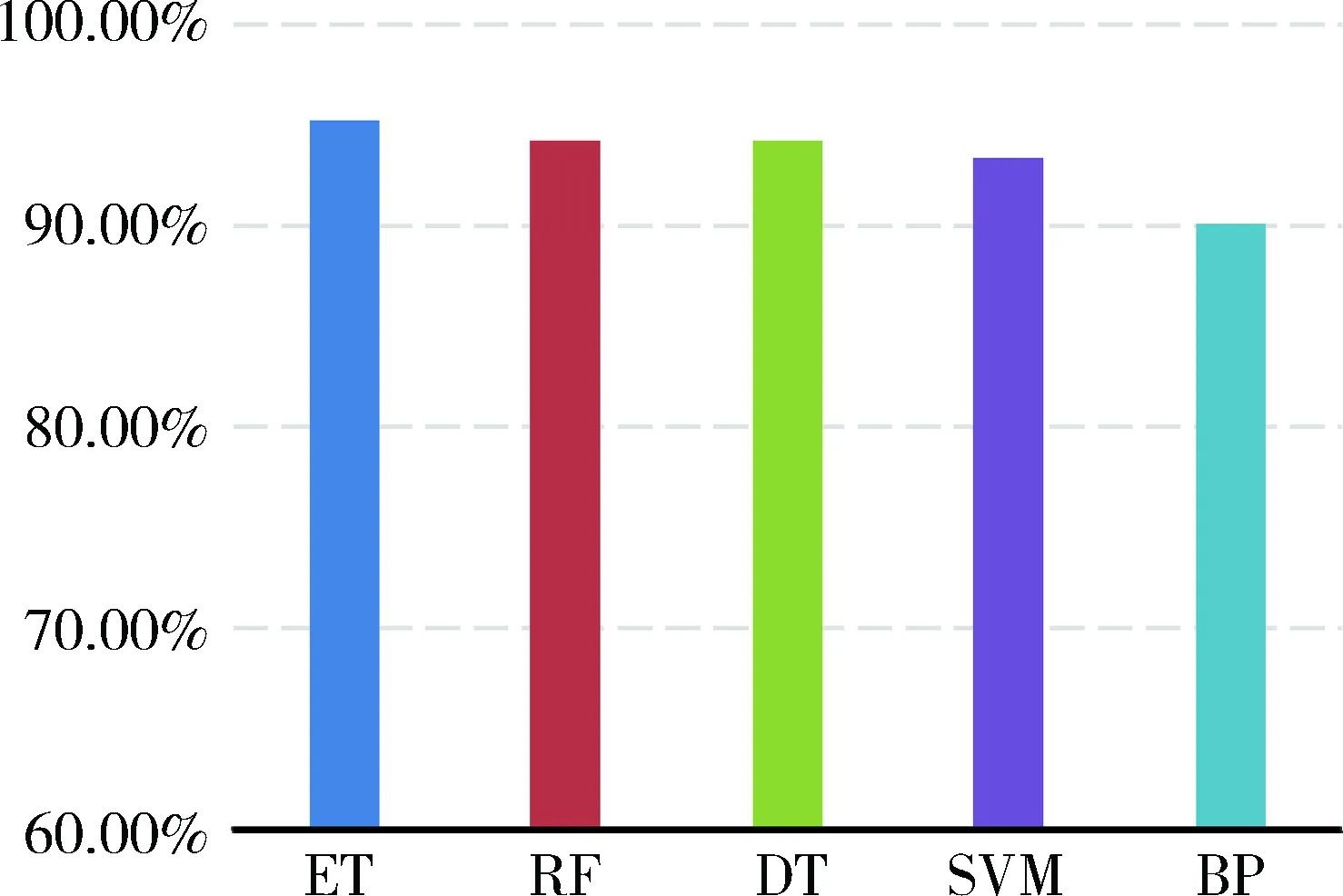
图5 标签上下位关系检测算法精确度
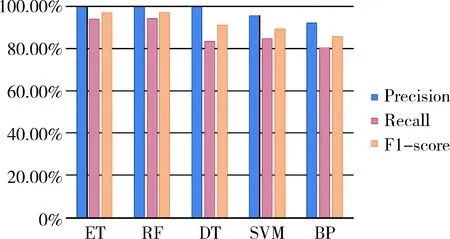
图6 标签上下位关系检测算法3项指标
图5和图6中ET、RF、DT、SVM、BP分别表示极端随机树、随机森林、决策树、支持向量机、BP神经网络。
从结果不难看出,5种分类器的分类效果均令人满意,其中极端随机树和随机森林在4项指标中都有较好的表现,上下位关系检测的查准率较文献[3]中的算法提高了近20%,说明本文所采用的特征提取方法较考虑标签共现的方法有明显的优势。同时,BP神经网络在5种方法中效果最差,且在实验过程中,结果随参数调整波动较大,说明BP神经网络在处理小规模确定特征的分类问题上并不占优势。
本文利用随机森林模型中8项特征对预测函数的贡献率来考察8项特征的重要程度,得到如表2所示的特征贡献率。可以看出模式3(“是一”)和模式5(“是什么”)的贡献率最高,分别为69.49%和10.09%,其他均在10%以下。同时可以看到,标签向量距离对决策函数贡献并不大,再次说明基于词语共现的方法来判断上下位关系效果并不会太好。由于实验受限于数据规模和特征选取的个数,特征项的贡献率只能一定程度上反映各特征的重要程度。
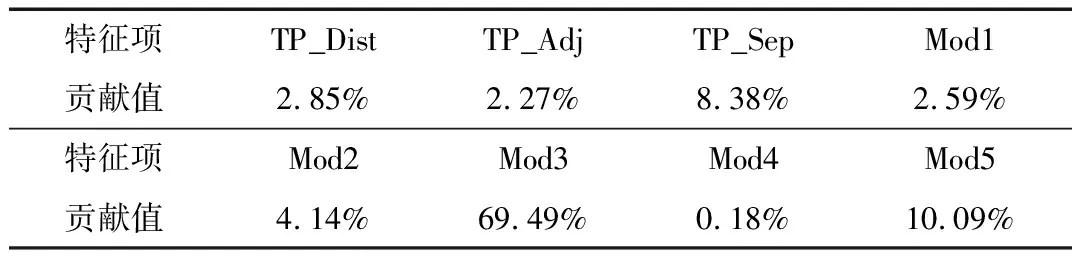
表2 特征贡献率
4 结论
本文提出了一种网络用户自描述标签层次体系构建的方法。其中着重描述了标签向量的生成方法和标签层次体系的构建方法,主要意义有以下两个方面:
(1)通过将用户自描述标签向量化,可以将网络用户抽象为由多个标签向量构成的标签矩阵,可以形象地将标签向量作为“点”,将网络用户定义为由标签组成的“点集”,进而对于用户的相似度计算或聚类等分析过程变为对“点集”的操作,可以高效地计算用户间距离,实现标签推荐等任务。
(2)通过标签层次体系的构建,在用户标签推荐过程中,可以根据标签体系进行推荐,例如对于拥有标签“足球”的用户,可以优先向该用户推荐与“足球”同一分支下的“篮球”等兄弟标签,可以提高推荐的效率和准确性。
