N-Reader: 基于双层Self-attention的机器阅读理解模型
2018-11-16梁小波任飞亮刘永康潘凌峰侯依宁
梁小波,任飞亮,刘永康,潘凌峰,侯依宁,张 熠,李 妍
(东北大学 计算机科学与工程学院,辽宁 沈阳 110169)
0 引言
机器阅读理解是指让机器阅读文本,然后回答和阅读内容相关的问题。目前机器阅读理解任务依据答案的类型可以分为两种: 完形填空型和片段抽取型。完型填空型的机器阅读理解需要找到文档中一个实体作为输入问题的答案,而片段抽取型机器阅读理解则要从输入文档中抽取出一段连续的文本片段作为输入问题的答案。本文方法属于片段抽取型的机器阅读理解任务,在后续的内容介绍中,也主要以此类方法为主。
在机器阅读理解任务中,根据回答一个问题需要处理的文档数量的不同,又进一步可分为单文档型阅读理解和多文档型阅读理解。单文档型阅读理解是指针对一个问题,需从单一的文档中寻找答案;而多文档型阅读理解则是指针对一个问题,需从多个输入文档中寻找答案。显然,与单文档型阅读理解相比,多文档型阅读理解需要处理的信息更复杂,模型的构建难度也更大。百度的DuReader[1]是一个面向中文的多文档机器阅读理解任务数据集,也是一个面向片段抽取型机器阅读理解任务的数据集。表1给出了一个该数据集中的训练样例: 每一个训练样本,都包含一个问题和多个描述文档,并且每一篇文档都是由多个段落组成。相应地,基于此数据集,机器阅读理解系统的任务,就是要从这些输入文档中找出可以回答对应输入问题的文档片段(即答案),并且输出的答案要尽可能的准确。

表1 DuReader数据集中样本示例
为了推动机器阅读理解技术的发展,斯坦福发布了SQuAD[2]数据集,并基于此数据集举办了面向英语的机器阅读理解比赛。该比赛吸引了国内外研究机构的广泛关注。以SQuAD数据集为基础,研究者们提出了大量基于神经网络的机器阅读理解模型。如Wang[3]等提出了Match-LSTM模型,Cui[4]等提出了AoA-Reader模型,微软亚洲研究院[5]提出了R-Net模型,Hu[6]等提出了Mnemonic-Reader模型。这些模型在SQuAD[2]数据集上都取得了很大成功,不断地刷新SQuAD竞赛排行榜上的成绩。最新的SQuAD竞赛排行榜结果显示,当前最好的机器阅读理解模型在EM(Exact Match)和F1这两个评价指标上已经超越了人类。
然而,这些已有的机器阅读理解模型仍存在以下两个问题需要进一步解决。
当前主流的机器阅读理解模型大多是面向英文单文档的模型,并不能直接用来处理面向中文的多文档阅读理解任务。首先,中英文在语言建模上有一定的差异性。例如,英文分词比中文分词容易。同时,英文数据可以使用单词中字符来定义抽象特征[7],并进而捕获未登录词和同义词的潜在特征,而中文在字级别可以使用的特征较少。其次,多文档数据中的每个输入文档都可能包含答案,使得整个建模过程要比单文档任务更复杂。并且,这些输入的多个文档不仅在语言描述上具有相似性,还可能在语义上具有相似性。如表1所示,这五篇关于维生素B2的文档中,不仅在语言描述上包含相同的词语,如“几乎不产生毒性”在文档4和5中均有出现。而且这些文档在语义上也往往具有相似性。如出现在文档4和5中的“几乎不产生毒性”和文档3中“很难引起中毒”都表达了同一种语义。
我们注意到: 在片段抽取型的阅读理解任务中,预测的答案均来源于输入文档,但是原始文档一般比较长,往往不适合全部作为模型输入。这一问题在多文档机器阅读理解任务中更严重。因此,对输入文档进行合适的数据选择,使最终输入模型的文本既保留原始输入的主要语义信息,又消除对最终结果没有帮助的噪音信息,无疑会对整个机器阅读理解任务有很大帮助。而在这一数据选择过程中必须要考虑以下两点。首先,必须考虑选择输入文本的长度: 输入模型的文本长度不能太短,以确保有充足的信息去预测答案;同时,输入模型的文本也不能太长,否则会增加神经网络的训练难度。其次,必须要考虑原始输入各个段落的语义相关性: 相关性段落可以增加数据中的语义特征,而不相关段落对于模型来说则是一种数据噪音。数据选择问题在当前机器阅读理解研究中并没有引起研究者们的足够重视,很少有相关的学术论文对该问题进行讨论。
为解决上面两个问题,本文提出了N-Reader,一个面向中文多文档任务的片段抽取型机器阅读理解模型。在该模型中,我们首先使用多段落补全算法把相关性高的段落抽取出来作为模型输入。接着,采用基于单文档的self-attention和基于多文档的self-attention这一双层attention机制抽取多个输入文档中的相关信息,并利用最终生成的多文档表示来预测答案位置。实验结果显示,N-Reader模型中的补全算法以及双层self-attention机制均可以有效地提高模型性能。基于该模型,我们参加了由中国中文信息学会、中国计算机学会和百度公司联手举办的“2018机器阅读理解技术竞赛”。最终,我们的模型在该任务的数据集上取得了ROUGE-L[8]58.08%和BLEU-4[9]52.49%的成绩。
1 相关工作
近年来,机器阅读理解任务受到了学术界和工业界的广泛关注。得益于各种大规模数据集的发布,研究者们可以训练各种复杂的基于神经网络的机器阅读理解模型。此外,随着attention[10]机制在机器翻译、图像分类等领域取得的巨大成功,该机制同样也被广泛应用在机器阅读理解任务中。本文所提模型的主要贡献点之一在于对attention机制的改进,因此这里我们将主要介绍attention机制在机器阅读理解任务上的相关研究工作。
2015年Hermann[11]等提出了Attentive Reader和Impatient Reader这两种机器阅读理解模型。其中,作者利用attention机制对输入文档和问题进行编码,并得到固定长度的语义编码表示,并以此语义表示进行答案预测。该文的实验结果显示,基于神经网络的机器阅读理解模型要明显优于其他传统模型。AS-Reader[12]模型是另外一个有代表性的机器阅读理解模型。该模型取代了之前将文档编码为向量的做法,将文档中每个词都编码为一个向量,并通过计算每个词作为开始和结束位置的概率来预测答案。
这些早期的机器阅读理解模型大多使用单向的attention机制,并不能很好地获得文档和问题之间的联系。在文档和问题的编码过程中,难免会丢失有效信息。为解决这些缺陷,Xiong[13]等提出了Co-attention机制,对文档和问题进行多次attention计算,然后将计算的多个结果联接起来作为最终的文档表示。采用双向attention机制的另外一个代表工作是Seo[14]等提出的BiDAF模型。在该模型中,作者对文档和问题之间的语义信息进行混合编码,并分别从“问题到文档”、“文档到问题”两个方向进行信息提取,同时保留原始输入的编码信息。这些双向attention机制可以充分融合输入文档和问题的语义特征,在实验中取得了很好的效果。
机器阅读理解不仅需要把问题中的信息融合到文档中,还需要对文档本身的语义信息进行有效编码,目前通常采用LSTM[15]和GRU[16]模型完成这一过程。但这两种神经网络结构很难解决语义的长距离依赖问题。为此,微软亚洲研究院[5]提出了R-Net模型,该模型主要特点是模拟了人类的思考过程。考虑到人在做阅读理解时会反复地阅读文章,并会结合全文的语境,相互推理并反复验证以获得最佳的答案。因此作者使用self-attention机制来增强文档表示,使每个词在进行信息编码时都可以包含上下文的语义信息。实验结果显示,R-Net可以有效地解决语义的长距离依赖问题。
但需要注意的是,在处理多文档的数据集时,单文档的self-attention机制只能编码文档自身的语义信息,并不能关注到多篇文档之间的相似性。而多文档的self-attention机制,则可以将多篇文档进行比较、推理,进而提取出相似性的语义特征信息。在本文中,我们将这两种self-attention机制进行结合并提出了双层的self-attention机制。实验结果证明,我们的方法可以有效地提升机器阅读理解模型的性能。
2 模型
我们的模型主要包括两个模块: 基于多相关段落补全算法的数据处理模块和基于神经网络的机器阅读理解模块。数据处理模块会针对原始文档数据做段落选择。神经网络模块则会对输入的文档和问题进行语义编码,并得到最终的答案输出。
2.1 数据处理
本模块的主要目的是从输入的每个文档中选出一些与答案相关度比较大的段落,并将这些选出的段落作为后续模型输入。
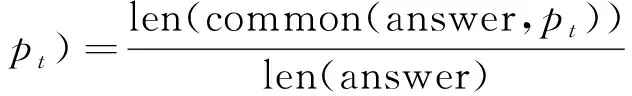
(1)
其中,answer代表标准答案,Pt代表文档中的段落,common(x,y)为求序列x和y的公共词,len(x)为求序列x的长度。该式的基本思想是:如果一个段落包含答案中的词越多,越有可能从该段落中推理出答案,那么应赋与该段落较高的相关度。
在训练过程中,我们先根据式(1)对每篇输入文档中的段落进行打分,再按照分值从高到低对原始文档的段落进行重新排序,并按照此顺序拼接成新的文档。但当前得到的新文档长度不一,直接输入不利于模型的统一处理。为此,我们通过一种段落补全方法将新生成的文档进行统一长度处理,具体如下: 设定一个长度m,从该新文档中选择前m个词(如果不足m个词则进行padding操作)作为此文档有用的信息,其他信息舍弃。紧接着,对选出的这m个词按照其在原始输入文档中的出现顺序再进行重新排序。新排序生成的文本序列将作为下一步神经网络模型的输入。
进行段落补全后每个文档的长度为m,那么多篇文档的总段落长度为k*m,此长度即为输入模型中的文档长度。
在这一过程中,第二次的排序非常必要。因为在数据集中,虽然每个段落的内容都是相对独立的,但是段落之间可能存在语义上的关联,段 落 顺 序 上
也可能存在先后关系。为了保证输入的语义连贯性,需对按公式(1)选出的文本信息按原文顺序再进行排序[注]我们尝试了多种方式,实验证明,采用原文顺序的方法效果最好。。
在测试过程中,由于数据中不包含标准答案,无法利用相关度函数进行打分。所以不对段落进行打分,而是按文档原始顺序抽取前m个词(如果不足m个词则进行padding操作)作为模型输入。
此外,为建模方便,我们将样本中的问题也取固定长度n作为输入,其m,n∈I。
2.2 神经网络模型
在N-Reader模型中,我们采用了双层的self-attention机制来融合上下文语义信息,并利用Pointer-Network[17]对答案的起止位置进行预测,模型结构如图1所示。

图1 N-Reader的神经网络结构
图1中虚线框中的部分为对单文栏的编码。首先,对单个文档进行上下文语义编码;然后,利用双向的attention机制对问题和文档信息进行融合;最后,利用self-attention机制得到单文档的表示。
图1中除了虚线框部分,剩余的为针对多文档的处理。首先,输入的每个文档都要先经过上述的单文档处理流程;然后,将生成的多个单文档表示进行联接形成多文档的表示,再经过self-attention机制得到最终的输入语义表示;最后,根据此表示对答案范围进行预测。
2.2.1 单文档编码
单文档编码分为三部分: 文档和问题的上下文信息编码(对应图1中“上下文编码层”部分)、文档和问题的信息融合(对应图1中“注意力融合层”部分)、文档表示信息的自匹配(对应图1中“自注意力层”部分)。

(2)
2)文档和问题的信息融合。这一过程采用BiDAF的方式来融合文档和问题中的语义信息。
首先,采用式(3)所示的点积相似度方法计算uP和uQ的相似度矩阵S。
S=(uQ)TuP
(3)
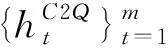
除计算得到的attention信息之外,原始输入的编码信息也会向下一层网络传递。这种方式减少了由于编码而导致的信息流失。
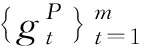
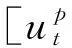
(4)
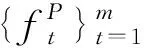
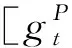
(5)
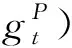
(6)
2.2.2 多文档编码
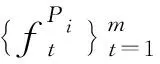
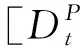
(7)
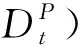
(8)
2.2.3 答案预测
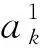
(9)
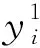
3 实验
3.1 实验数据集
2017年百度发布了面向中文多文档片段抽取型阅读理解任务的DuReader数据集。中国中文信息学会、中国计算机学会和百度公司联手举办的“2018机器阅读理解技术竞赛”也是使用该数据集。
该数据集是一个大规模的开放领域中文阅读理解数据集,来源于百度搜索和百度知道的真实场景。数据集中包含近30万的数据样本,其中27万为训练样本,1万为开发样本,2万为测试样本。在竞赛过程中,测试集并没有提供答案。因此,实验中,我们对训练集和开发集的数据进行随机重组,并随机选择26万作为训练集,1万作为开发集,1万作为测试集。在整个实验过程中,我们没有使用任何外部数据。
我们使用竞赛组织者提供的ROUGE-L和BLEU-4作为评价指标,并以ROUGE-L为主评价指标。后续对比实验中的baseline系统为此次竞赛举办方提供的BiDAF系统。
3.2 实验设置
在实验中,输入的文档长度m设置为500,问题长度n设置为60,答案的最长长度设置为200,词embedding的维度设置为300,GRU的隐藏层的维度d设置为150,batch的大小设置为24。训练中采用了Adam算法进行优化,学习率设置为0.001。整个模型在GeForce GTX TITAN X上训练了24个小时。
3.3 实验结果及讨论
在实验的第一部分,我们以BiDAF模型为基线系统,增量式地对比了GloVe embedding、多相关段落补全算法、单文档self-attention(S self-attention)、多文档self-attention(M self-attention)对整个模型的性能影响。基线系统根据式(1)选取了文档中和答案最相关的段落作为训练数据,没有做数据补全操作。实验结果如表2所示。
从表2可以看出,我们提出的方法在两个指标上均有提高。并且可以看到在使用了数据补全处理和多文档的self-attention之后整体性能涨幅明显。
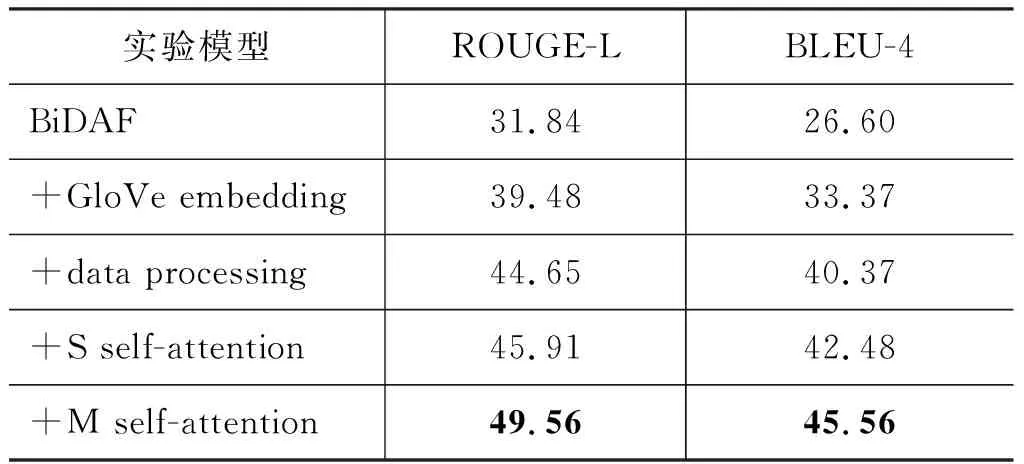
表2 26万数据集,1万测试集,线下测试结果
使用竞赛举办方提供的线上测试系统得到的结果如表3所示。与百度测评委员会给出的基线系统相比,我们的模型在ROUGE-L和BLEU-4这两个评价指标上分别提升了13.51%和12.95%。
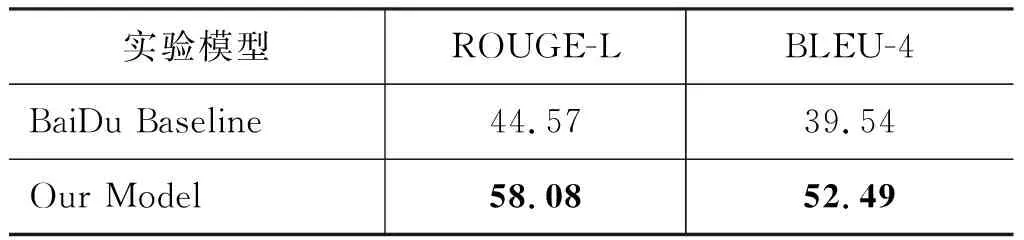
表3 27万数据集,2万测试集,线上测试结果
为了进一步分析实验结果,我们对训练数据进行了统计。表4为在测试集上,使用单个最相关段落作为一个输入文档时对应的长度统计信息。从中可以看出选出的单一段落长度大部分小于200。表5则统计了不同长度的标准答案在测试集上所占的样本数。采用本文提出的多相关段落补全算法后,针对长度不足500的样本进行数据补全。

表4 测试集上使用单个段落作为对应文档时得到的文档长度统计

表5 测试集上标准答案长度的样本分布
基于表4~5的统计结果,我们从标准答案长度和输入文档数据长度这两个角度实验,分析了本文所提出的数据补全算法、双层self-attention机制的有效性,结果如图2~3所示。
从图2~3实验结果可以看出,对于标准答案长度较短的样本,数据补全的影响比较小,但是对于标准答案长度越长的样本,多段落数据补全的优势就越明显。说明了针对于短的答案来说,由于文档中包含的信息足够推理出答案,其文档的长度对于模型的性能影响不大。但随着标准答案的长度增长,太短的文档不足以寻找出关键的线索,文档补全就显得至关重要。由统计数据也可以看出,近三分之一的文档标准答案长度大于100,这些文档在通过多段落补全处理之后,两个指标均有较大的提升。对于不同的输入长度,可以看出输入数据越长,越有利于模型找到答案。我们的补全算法会对输入段落进行补全,这些段落在语义上具有相关性,可以帮助模型抽取到潜在的规律,有利于模型预测答案的范围。
图2~3也对比了在数据处理基础上加入双层self-attention后的实验效果。从中可以看出,在加入了单文档的self-attention之后,性能提升不明显。而在此基础上加入了多文档的self-attention后,两个评价指标提升较为明显。说明了单个文档中的信息并不足以推理出答案,需要用到多篇文档中的信息。如同人类做阅读理解时,在单个文档信息不足时,通过阅读不同来源的多个文档,往往可以找到更加符合问题的答案。这些文档都是同一个问题的描述,并且在语言描述和语义上具有相似性,有利于模型找到关键线索,推理出更加合理的答案。
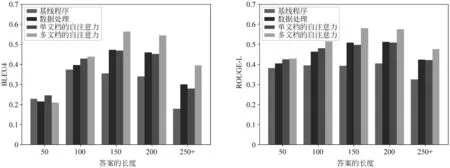
图2 不同的标准答案长度下的BLEU-4和ROUGE-L
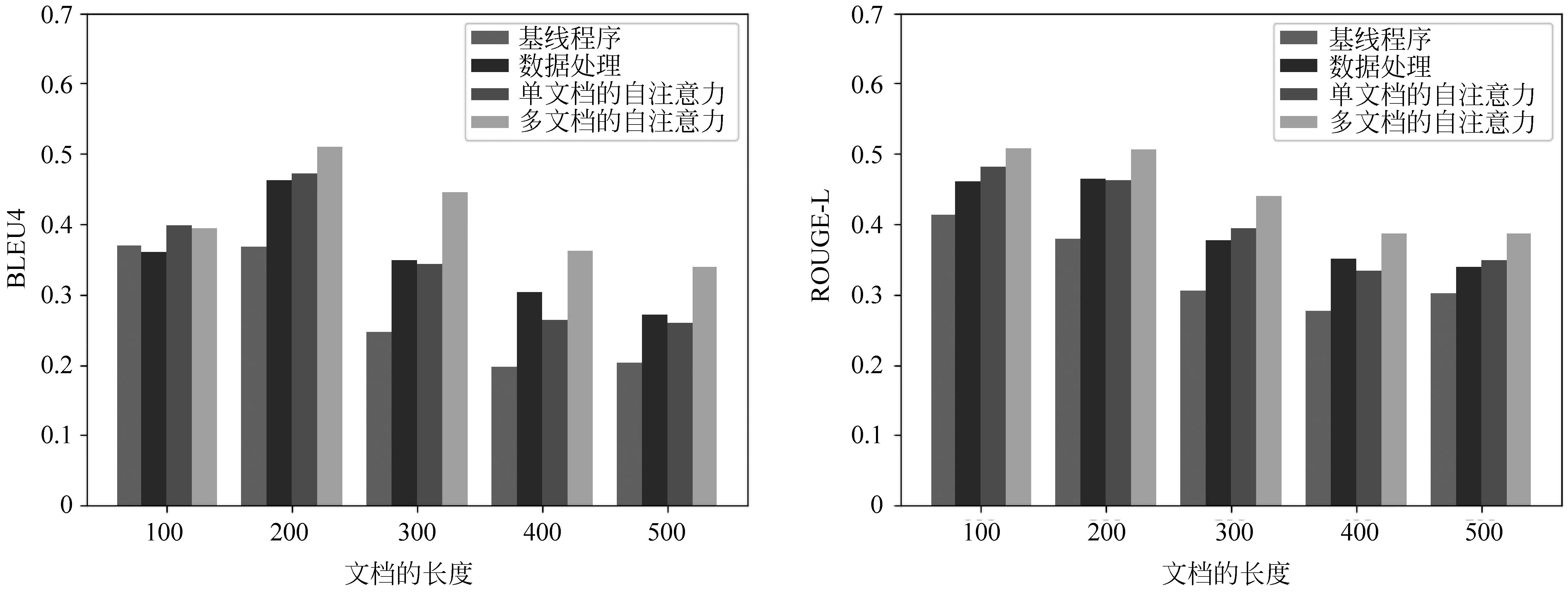
图3 为不同输入长度下的BLEU-4和ROUGE-L
4 总结
本文提出了一种面向中文多文档片段抽取型机器阅读理解任务的N-Reader模型,其主要贡献点列举如下。
首先,我们针对多文档片段抽取型机器阅读理解任务提出了一种多相关段落补全算法。该算法既可以保留原始输入文本中的主要语义信息,又可以消除对最终结果没有帮助的噪音信息。实验结果显示,该算法可以较大幅度地提高机器阅读理解任务的性能。
其次,我们提出了双层的self-attention机制来生成文档和问题的向量表示。首先对单个文档进行编码并利用self-attention机制得到单文档的表示;其次,将单文档表示进行联接形成多文档的表示;最后,经过另外一个self-attention机制得到最终的输入语义表示,并据此表示进行答案范围的预测。实验结果显示,该双层self-attention机制对提升机器阅读理解任务的性能有较大帮助。
最后,使用N-Reader模型,我们参加了由中国中文信息学会、中国计算机学会和百度公司联手举办的“2018机器阅读理解技术竞赛”,获得了第三名的成绩,这一成绩证明了本文模型的有效性。
我们计划在未来的研究中深入地挖掘多文档数据之间的内在联系,以及在模型中引入句法结构信息以增强模型的表示能力。此外,我们还计划设计新的神经网络结构来提高模型的表示和推理能力。
