融合人口统计属性的药品推荐算法
2018-11-08周锡玲张莉敏田小路宋强
周锡玲,张莉敏,田小路,宋强
(广东理工学院,广东肇庆,526100)
0 引言
基于协同过滤的推荐是个性化推荐系统中使用最广的技术之一[1]。但协同过滤算法存在数据稀疏性问题。在某种程度上,用户的人口统计属性(年龄,收入等)揭示了用户的喜好。国内外很多学者将用户的人口统计信息与协同过滤进行融合来改善系统的推荐质量。文献[2]提出一种挖掘用户隐含的人口统计信息的方法。该方法能够更准确的为用户产生推荐。文献[3]提出一种基于用户人口统计与专家信任的协同过滤算法。实验表明该方法改善了协同过滤算法的预测准确率。文献[4]提出一种融合人口统计属性的协同过滤算法,该方法能够有效提高推荐精度。文献[5]提出一种混合推荐技术的推荐模型,该方法解决了数据稀疏问题,且提高了系统的推荐质量。
1 融合人口统计属性的药品推荐算法
1.1 药品聚类
根据停用词表去掉药品描述中的停用词将剩下的词汇当作特征词。采用向量空间模型(VSM)将药品映射为多维空间向量。利用K-means算法对药品进行聚类。根据用户的疾病症状找到它所属的聚类,从该类中筛选出符合其病情的药品,然后查找出评价过这些药品的所有用户,形成用户-药品评分矩阵。
1.2 用户相似度计算模型
(1)用户评分相似度计算
本文采用修正的余弦相似性来计算用户之间的评分相似度。用户a跟用户b的评分相似度 s im _ r(a,b)计算公式如(1)所示:
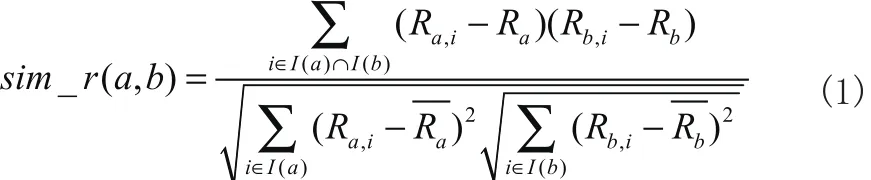
其中,i表示用户a跟用户b的共同评分药品,I(a)和I(b)分别表示用户a与用户b的评分药品集,Ra,i和 Rb,i分别表示用户a和用户b对药品i的评分,和分别表示用户a和用户b对所有药品的平均评分。
(2)人口属性相似度计算
不同年龄段的人使用同种药品得到的疗效有所不同,因此不同年龄段的人对于同种药品给出的评分也不同。本文将年龄分为7个年龄段:18岁以下、18-24岁、25-34岁、35-44岁、45-54岁、55-65岁和65岁以上。因此,年龄属性的向量形式表示为 ( n1,n2, … ,n7)。用户a与用户b的人口统计属性相似度 s im _ a(a,b)计算公式如(2)所示:
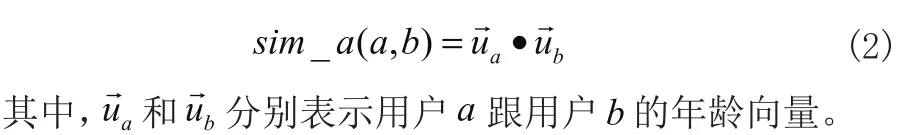
(3)用户相似度计算
本文将评分相似度跟人口属性相似度进行加权线性融合得到用户相似度,用户相似度 s im(a,b)的计算公式如(3)所示:
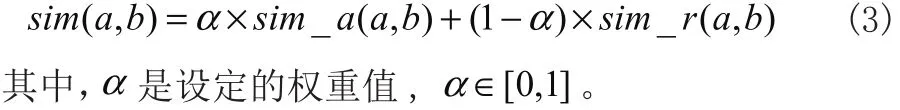
将用户相似度按降序排列,采用KNN算法选出排在最前面的K个用户作为目标用户a的相似邻居集 ()Sa。
1.3 预测评分
根据 ()Sa中用户的评分,目标用户a在药品 j上的预测评分计算公式如(4)所示:
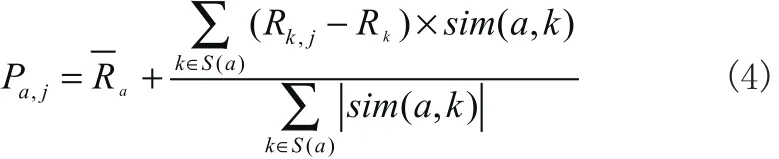
其中,Ra和Rk分别表示目标用户a和用户k的平均评分,Rk,j表示用户k对药品 j的评分。选取目标用户未评分的且预测评分排在最前的N个药品推荐给目标用户。
2 实验结果及分析
2.1 数据集
本文采用的数据集是从http://www.datatang.com/data/46261上下载。选取580个用户对615种药品的21000次评分。实验中,随机选取20%当作测试集,剩下的当作训练集。
2.2 评价指标
采用MAE来评价本文算法的有效性。其计算公式如(5)所示:
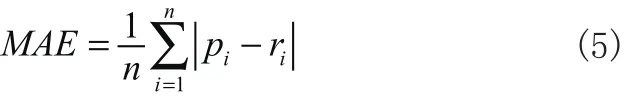
其中n为测试数据的数量,ip为算法的预测评分,ir为实际评分。显然,MAE值越小,推荐质量越好。
2.3 实验结果分析
(1)α的选取
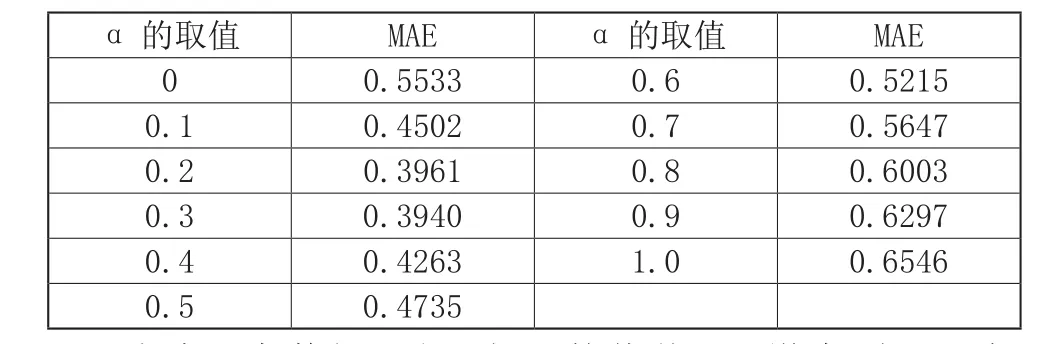
表1 α对MAE的影响
由表1中数据可知,当 的值从0.1增大到0.3时,MAE的值随着α值的增大而减小,且当α=0.3时,MAE值最小,M AE= 0 .3940,由此可以说明在计算用户相似度时将用户评分相似度与人口属性相似度进行融合,可以提高推荐系统的推荐质量。当α从0.4增加到1.0时,MAE值随着α的增大而不断增大。由分析可知,当α=0.3时,MAE值最小,推荐质量最好。
(2)推荐效果比较
为评价本文提出算法的有效性,将本文算法与传统基于用户的协同过滤推荐算法(User-based CF)、采用人口统计属性来计算相似度的协同过滤推荐算法(DAS-based CF)进行比较。比较结果如表2所示。
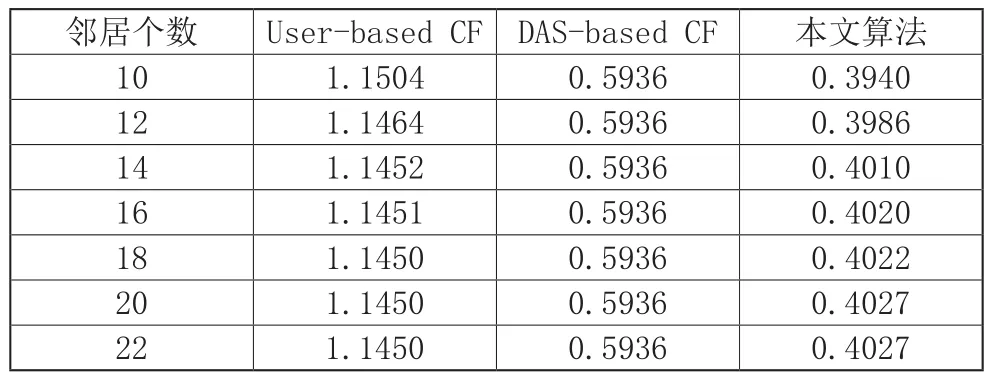
表2 MAE值比较
由表2数据可知,三种算法的MAE值随着邻居个数的增加而趋于稳定,但本文算法的MAE值明显比其它两种算法的MAE值低,说明本文在计算用户相似度时将用户评分相似度与用户人口统计属性相似度进行融合有效地改善了算法的推荐质量。
3 结束语
传统协同过滤仅根据用户-药品评分矩阵来计算用户相似度,由于评分矩阵稀疏,用户相似度计算不准确使得目标用户的相似邻居集合选取不准确,从而导致推荐质量低,因此本文提出融合人口统计属性的药品推荐算法。该方法将药品描述中的词汇去掉停用词后将所有词汇作为特征词,采用VSM将药品映射为多维空间向量。为了降低时间复杂度,离线使用k-means算法进行药品聚类。根据目标用户的疾病症状找到其所属的聚类,从该类中筛选出符合其病情的药品,然后查找出对这些药品进行过评分的所有用户形成用户-药品评分矩阵。在用户评分相似度的基础上,引入了人口属性相似度,将用户评分相似度跟属性相似度进行加权线性融合来得到用户相似度,将用户相似度按降序排列,采用KNN算法选出排在最前面的K个用户作为目标用户a的相似邻居集。仿真结果表明,跟传统协同过滤推荐算法相比,本文提出算法在推荐精度上有显著的提高。
