基于LBS的个性化旅游线路推荐算法研究
2018-11-08潘禄生
潘禄生
(甘肃畜牧工程职业技术学院,甘肃武威,733006)
关键字:LBS;情感分析模型;协同过滤模型;个性化推荐;旅游线路推荐
1 情感分析模型
1.1 AFINN词典
本文通过使用间接方法进行分类,首先通过对评论信息在情感分类词典中查询,获取该评论的人工情感程度分类,然后通过使用有监督的机器学习实现二次精确分类。为了算法的时间复杂度,本文采用了基于AFINN情感词典的情感分析模型。
AFINN词典是一个情感词汇和短语的评分列表,通过对情感词汇进行分配并进行人工自然语言分析得到的精确情感词汇,该列表将情感类词语转化为[-10,10]的评分区间,是一个相对简单的情感词汇评分工具。在AFINN词典中,词汇的情感计算为:

1.2 评论情感值计算
1.2.1 情感词汇评分值计算
在情感词汇分析过程中,语气副词对情感往往有加成效果,因此在AFINN词典中为每个情感副词增加了语气因子,对于不同的程度的情感副词赋予了不同程度的语气加强因子γ。与此同时,不同的否定副词会对语气有相反的效果,因此为准否定副词和否定负责赋予了语气取反因子ϕ。在对评论语句进行分词过程中,获取到情感词汇以及情感副词,然后通过查新AFINN词典,如果该词汇出现在情感词典中,可查询到对应的语境情感评分,在查询过程中,需要注意该情感词汇是否有相应的情感副词修饰,如果有,需根据该副词的语气状态对情感词汇加强语气状态或者取反语气状态。经过上述计算之后保证该词汇的情感评分值位于[-10,10]的取值区间内。
在正常的情感评论中,评论的情感评价值的计算使用如下的计算方法:
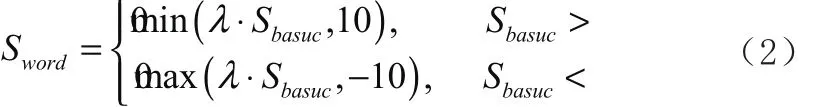
在上述公式中,basucS 表示情感词汇在AFINN词典中词汇的情感查询值,wordS 表示该词汇在该语境中的情感评分值,λ表示该词汇在语气加强程度的语气加强因子。当查询到的词汇情感值大于0后,该词汇的情感值不能大于10,当查询到的词汇情感值小于0后,该词汇的情感值不能小于-10,经过上述计算,wordS 的取值范围在[-10,10]的一个闭区间内。
当评论中出现否定情感副词后,评论的情感评价值的计算使用如下的计算方法:

与公式(2)类似,basucS 表示情感词汇在AFINN词典中词汇的情感查询值,wordS 表示该词汇在该语境中的情感评分值,ϕ表示该词汇在语气加强程度的语气加强因子。当查询到的词汇情感值大于0后,该词汇的情感值不能大于10,当查询到的词汇情感值小于0后,该词汇的情感值不能小于-10,经过上述计算,wordS 的取值范围在[-10,10]的一个闭区间内。
1.2.2 评论语句的情感评分值
首先提取出评论语句中各情感词汇的语境的情感评分值,然后计算出该话题的各维坐标,然后根据整个句子中出现的所有情感词情感评分值计算完毕之后,将所有词汇情感词的权值设为相同,因此评论语句的情感评分值为:

在公式(4)中,s0表示评论语句的初始情感评分,n表示在评论词汇在AFINN词典中词汇的个数,sword-i表示语句中每个情感词汇的情感评分值,且该情感评分值的取值范围在[-10,10]区间内,因此通过公式(4)计算结果的取值区间为[-10,10]。
由于情感评分值[-10,10]距离过大,且数据不够规整,为了方便做推荐系统做输入,采用5档评分制,将区间[-10,10]映射到1,2,3,4,5五档,在本文中,将(np- nN)作为极性分界点,映射方法如下:
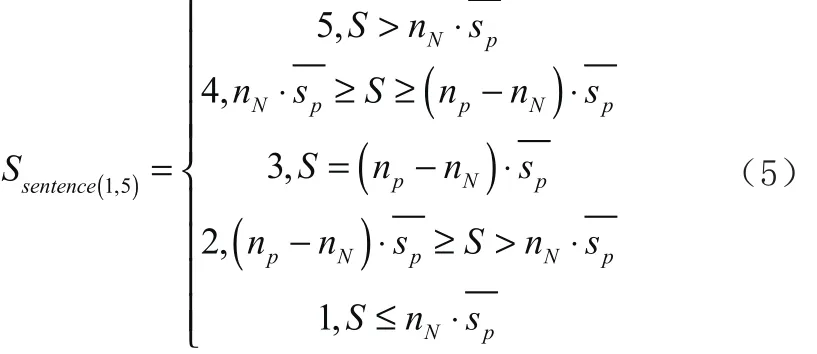
通过上述转换,可以直接将评分值转化为1-5档之间的一个值。
2 基于LBS的个性化推荐模型
2.1 基于用户的协同过滤模型
基于用户的协同过滤推荐的基本原理是,根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“K-邻居”的算法;然后基于这K个邻居的历史偏好信息,为当前用户进行推荐。因此对于个性化旅游推荐来说,可以通过推荐相似性较高用户集合的选择旅游点会有不错的效果。
为了实现基于用户的协同过滤模型,需要经过如下步骤:
(1) 构建用户-景点评分矩阵
在构建用户-景点评分矩阵之前,首先需要通过公式(5)计算每个用户对景点的评论信息,设 ,SijUL表示用户iU对景点jL的评分。因此用户-景点评分矩阵为:
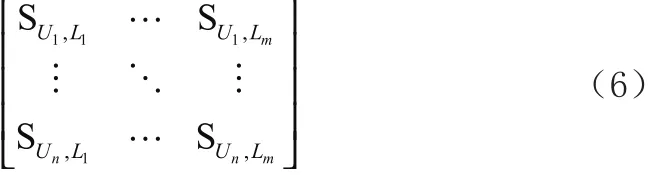
(2) 构建邻接矩阵
使用邻接矩阵来计算两个用户之间的相似度,在计算过程中,本文采用余弦相似度来判断两个用户是否属于相同的类型,计算用户µ,ν之间相似度的方法如下:
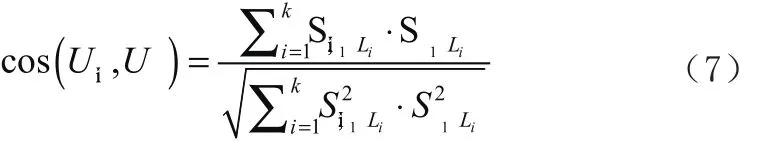
在公式(7)中,ìU和íU分别表示对景点集合的评分,通过上述计算,就可以获得两个用户之间的相似度,由于不同用户之间对景点的评论各不相同,如有些用户没有评论某些景点,可以设置该景点的评分为一个中性值3,结合实际情况找出相似度高于预先设定的阈值,可以将这些用户归为相同的一类。
(3) 预测评分
基于用户协同过滤的思想,通过计算用户的相似近邻,获取该用户对这些景点的评分,然后在计算用户对未知景点的评分过程中,需要参考相似近邻对该景点的评分,然后通过计算该用户的“相似近邻”用户对该景点的评分,然后将推荐用户对该景点的评论与其他用户对该景点的评论做余弦相似度计算,然后计算两者之间的偏差值,通过这个偏差值来预测用户与推荐景点的预测分数。
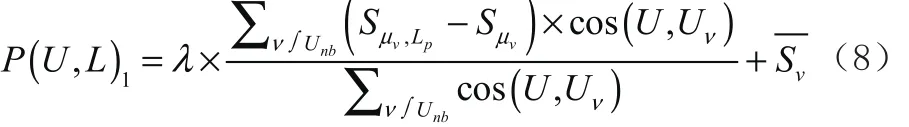
在上公式中λ表示景点的修正参数,Sì,vLp表示对景点的实际评分,表示用户对所有景点评分的平均分数,cos( U ,Uí)表示该用户与其他用户的相似度,表示用户对所有景点的平均评分。计算出来的 P (U ,L),如果改值大于某个预定的阈值,就可以认为该景点适合推荐给用户。通过这种计算,可以找到所有推荐给该用户的景点集合。
在上述计算过程中很容易出现冷启动和数据稀疏性问题,这也直接影响了推荐的有效性,针对此种情况需要将位置信息考虑其中。
2.2 基于地理位置的推荐模型
将用户所访问过的景点都列举出来,并分别计算每个景点与中心点的位置,具体计算方法就是通过画最小直径的圆,该圆包括所有景点,并保证该圆的直径尽可能的小,然后将各景点与圆心平均数座位该用户的活动半径,如果有一个景点明显偏离圆心,需要将该景点删除之后再计算圆心的位置。
通过对Foursquare数据集中所有用户的活动半径来分析,用户喜欢的景点通常具有区域性,一般来说,新景点如果距离用户当前的位置小于活动半径,用户通常会选择该景点,因此基于地理位置的推荐模型就是通过计算新景点与原来活动中心的距离来估计用户对该景点的喜好程度,基于地理位置的推荐模型的具体过程如下:
根据前文理论,景点位置越远,用户的选择意愿越低,因此有如下拟合函数公式:

a,b分别表示两个常数,x表示推荐景点与用户活动中心点的距离,而y表示用户的选择意愿,为了和基于用户协同过滤算法配合,本文也将y的值定为[1,5]的封闭区间内。设定所有的距离阈值为 [d5, d4, d3, d2],可以将用户的选择意愿分为5挡:
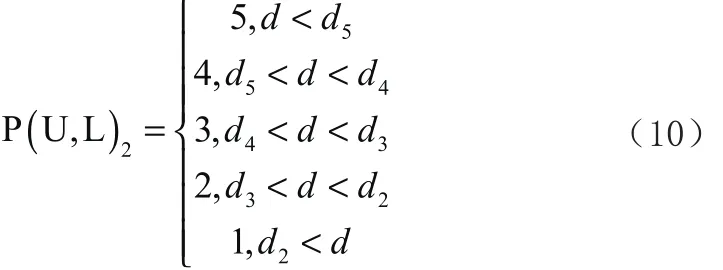
通过公式(10)可以基于地理位置的推荐算法预测用户对推荐点的评分。
2.3 基于LBS的推荐模型的流程
为了避免基于用户协同过滤模型以及基于地理位置模型的缺点,本文将两种模型想结合,将两种模型的预测分数进行加权:

其中 α +β=1,且两个加权的值会随着用户的喜好而调整大小,使用混合推荐模型的旅游线路推荐流程如下:
在图1中,路线规划是在找到所有的推荐旅游景点之后,通过加权dijkstra算法找到最经济的路由线路,从而推荐给用户。
3 结束语
本文针对当前“自由行”比较热门的情况,且普通的用户很容易因为信息过多而不知道如何选择合适的旅游线路的问题,提出了基于LBS的个性化旅游线路推荐算法,首先使用情感分析模型对用户对旅游景点的评论信息进行分析,并实现打分,然后使用基于用户的协同过滤模型和基于地理位置的推荐模型实现对合适的旅游景点进行筛选,预测出用户对各个景点的预测评分,然后选择合适的旅游景点,然后进行路线规划,推荐给最终用户。
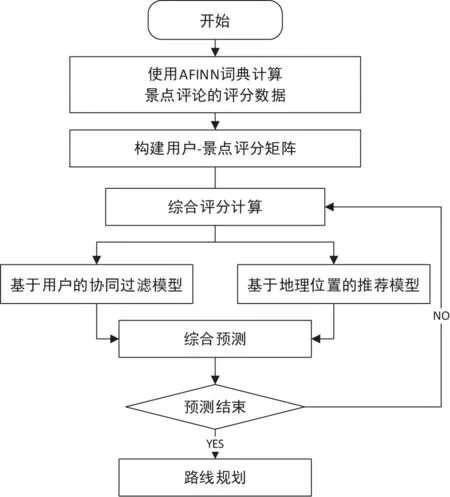
图1 推荐过程流程图
