学术相关通知类邮件处理系统设计
2018-11-08徐傲雪张凌张晶
文/徐傲雪 张凌 张晶
引言
研究背景
在互联网高速发展的时代,网络通讯手段愈加丰富,对比众多网络通信手段,由于电子邮件拥有全球统一公开的通用通信协议,具有长期保存、书面性等特性,因此电子邮件作为互联网应用最广的服务依然保持着其不可替代性。根据电子邮件的办公特性,针对电子邮件开发的邮件服务类工具被广泛应用在企业、高校或机构中,此类工具除了满足基本的通讯需求,更加应该提供给用户优质的事务处理服务,为用户筛选出重要的待处理邮件,并且提供管理邮件资源的方案。
在电子邮件的主要应用场景之一高校、研究机构环境下,学术相关通知类邮件是备受重视的,学术相关通知类邮件主要包含期刊征文通知、相关领域的学术会议召开通知、学术竞赛及论坛讲座类的学术活动的举办通知,此类邮件是高校师生、研究人员会经常收到并且需要及时处理的。然而在现实中存在一些常见的问题,一方面现在网络上垃圾邮件、订阅邮件、广告邮件泛滥,在处理邮件时需要耗费相当多的时间精力去筛选学术相关的通知类邮件;另一方面高校人员会收到大量的征文,会议邀请的邮件,其中大部分并不符合他们的研究领域;另外此类通知邮件中往往有一些不重要的部分,在处理邮件时需要花费时间去定位有效信息。
为解决上面提出的问题,本文提出了一个针对学术相关通知类邮件的处理系统AREP(Academic Related Email Processor),AREP构建了邮件收发的组件,应用基于关键词的方法筛选出学术相关通知类邮件,使用基于SVM的分类方法对学术相关通知类邮件进行领域分类,开发基于规则的后处理模块进行邮件资源的管理。本文提出系统有助于提高科研人员处理邮件的效率,从而激发学术热情,促进学术研究工作。
背景知识及相关工作
重要邮件处理:相较于比较成熟的垃圾邮件过滤技术,对于在非垃圾邮件中区分重要邮件的研究则不那么充分,然而重要邮件的划分能够很好地提高用户的处理效率,具有实用意义。在进行重要邮件分类的研究时,可以采取的方法有个性化的邮件优先级分类,以优先级来划分比起划分重要非重要更加细致[1]。S.Yoo等在2009年提出通过社交网络个人数据挖掘提取特征使用半监督学习方法来实现邮件重要性排序[2],G.Tang等在2013年提出实现多分类和半监督的学习方法来实现邮件分类[3],国内外各个邮件服务器厂商大多提供重要邮件标记的功能,由用户手动标记重要邮件,如Outlook的重要收件箱,网易邮箱的红旗邮件等,这样的标记方法实用性并不强并且发生在用户处理邮件后。Gmail 的重要邮件分类的排序算法为线性逻辑回归算法,主要利用社会,内容,线程,标签四个特征,自动为重要邮件标记[4]。本文主要解决学术相关通知类邮件的划分问题,根据观察,学术相关通知类邮件具有明显区别于普通邮件的关键词特征,因此本文设计了一个学术相关通知类文件的关键词生成方案,通过基于关键词的方法实现学术相关通知类邮件的筛选。
文本分类:文本分类是解决学术相关通知类邮件领域分类问题的一个关键技术,文本分类中的主要研究内容主要有文本表示、分类方法等,文本分类方法自20世纪90年代从传统的知识工程和专家系统逐渐发展出基于机器学习的文本分类方法,逐渐发展成熟,近年来基于深度学习的文本分类方法也为文本分类领域带来了新的活力。文本表示是文本分类方法中一个关键技术,目前最常用的文本表示方法有VSM、基于主题概率模型和词向量模型[5],词向量模型于2003年被首次提出,在2013年Google团队开源的word2vec工具[6]后被推上了研究的高潮,Vintan等在2017年提出了一种使用word embedding扩展VSM 的文本表示方法,通过在传统的VSM 模型中添加词嵌入的信息,虽然实验结果并不理想,但是提出了一种新的突破[7];传统的机器学习算法在文本分类的应用已经研究得非常成熟,许多的分类算法都能在不同的软件直接应用,最常用的算法包括SVM,NB,KNN,IDT等,近年来关于集成学习以及深度学习在文本分类上的应用越发引起重视[8],Lai等提出一种递归卷积神经网络模型用以文本分类,并且分析了递归神经网络,卷积神经网络,循环神经网络等模型在文本分类的应用,并分别在中英文文档上进行实验[9];Zhang等提出字符级卷积神经网络的文本分类方案,对比了词袋模型、n-gram模型等文本表示方法,以及基于词语的CNN模型以及递归神经网络模型[10]。本文提出的AREP采用结合TF-IDF及词向量的文本表示方法,选用SVM作为分类方法解决学术相关通知类邮件的领域分类问题。
系统概述
系统配置
系统在网络环境的设置: AREP实现多邮箱的聚合,支持多种邮件服务器的后处理,实现方法如图1所示 使用DNS服务器配置邮件域的MX记录,将对应的MX指向系统所在服务器的IP地址,使得发往指定邮件域的邮件都会经过本系统。
预训练的离线组件:如图1所示AREP 包含以下一些离线预处理的组件:(1)学术相关通知类消息采集工具:利用网页采集技术从一些公开的会议、期刊网站收集学术相关通知类网页,提取网页的主要内容转换为纯文本的数据,混合从个人邮件中收集的学术相关通知类邮件,构建学术相关通知类文本数据集。(2)关键词规则生成工具:关键词规则生成工具从学术相关通知类文本数据集中生成一组形如(关键词 权值)关键词规则,为AREP中的学术相关通知类邮件筛选模块提供支持。(3)公开的预训练词向量集(4)预训练的SVM分类器:在学术相关通知类文本数据集上训练得到的SVM分类器,为AREP中的学术相关通知类邮件领域分类模块提供支持。
系统设计
本节主要讨论AREP系统在设计时的目标和实现的核心方法。
稳定的邮件服务:AREP 设置在邮件服务器的前方,必须保证在提供稳定的邮件收发服务的基础上执行学术相关通知类邮件的处理,为了不影响邮件的正常传输,,系统设计时采用模块化的设计,并独立各个模块的进程组,通过序列化的数据流及本地消息队列连接各个模块。例如不能允许处理模块的处理时间影响了收取邮件的响应时间,另外分发组件易受到网络故障的影响并且实时性要求不强,因此在完成处理后先将邮件正常发送出去同时通过本地的消息队列通知分发组件所在的进程组有待处理的学术相关通知类邮件。

图1 AREP系统框架
用户个性化设置:AREP 是为了减轻人工处理重要邮件的负担而设计的,需要为不同用户提供个性化的设置,本系统提供基于RESTful架构的接口设计,提供用户交互浏览器端的实现,用户使用浏览器的管理端可监控系统的邮件处理记录,配置邮件处理规则,例如将经系统处理判断为计算机科学领域的学术相关通知类邮件转发到指定邮箱或者归档到个人云盘。
系统组件及工作流程
邮件处理组件:如图1所示AREP 包含以下一些必要的邮件处理组件:(1)邮件接收组件:基于SMTP协议实现邮件接收功能,基于异步事件驱动实现高并发地处理到达邮件,进行频率控制、并发控制,保证本系统具有一定抵御网络攻击的能力。(2)邮件解析组件:解析邮件原件,实现接收的邮件的元数据如发件人、接件人、发送时间等的结构化,实现邮件内容拆分,如分成邮件头、邮件正文、邮件附件。(3)邮件发送组件:基于SMTP协议实现邮件的发送,通过对邮件原件的分析,定位主题,正文,未显示部分等在邮件原件的位置,在指定位置添加系统处理后的标签。
学术相关通知类文本处理组件:如图1所示AREP的核心处理组件主要包含两个部分(1)筛选组件: 使用预训练得到的关键词规则,计算一封邮件的正文中所有命中的关键词规则的分数总和,设置一个分数阈值作为标准,标记普通邮件和学术相关通知类邮件(2)分类组件:使用预训练得到的SVM分类器对邮件正文进行分析实现领域分类,并标记分类。
分发组件:如图1所示AREP的分发组件实现基于规则的后处理,根据用户在管理端配置的规则以及系统学术相关通知类文本处理组件对邮件处理后的标签结果分发邮件,每一条规则形如(规则,操作),规则包括邮件类别的判定,学术相关通知类邮件领域分类等,操作包括丢弃、转发、归档等。
系统的完整处理流程:一封到达系统服务器的邮件通过邮件接收组件接收后通过文件系统递交给邮件解析组件,将解析得到的各部分源文件暂存,将邮件正文内容传输给筛选组件,根据筛选结果,普通邮件直接递交给邮件发送组件发送,将学术相关通知类邮件传输到分类组件,进行领域划分后,标记分类结果,同时通知邮件发送组件和分发组件进行发送和后处理,分发组件检查用户规则库,对每一条命中规则执行对应操作。
具体方案
本节讨论了AEPR 中核心组件的关键实现:基于关键词的筛选组件中关键词规则的生成方法以及基于SVM的分类组件的完整分类方案。
关键词规则生成方法
基于关键词的学术相关通知类邮件筛选组件需要解决的核心问题是如何设计合适的关键词规则,本文参考应用最广泛的垃圾邮件开源解决方案之一SpamAssassin中为关键词规则赋分值的感知器算法[11],设计了一种基于单层感知器的关键词生成方法。本文使用的关键词生成方法主要包括以下几个步骤:
(1)选取学术相关通知类邮件中词频最高的N个词,统计这N个词中每个词Wi在学术相关通知类邮件中出现的次数ARi和在非学术相关通知类邮件中出现的次数NARi,筛选满足公式1的词作为特征候选词,其中N和T的取值通过实验选取较优数值。
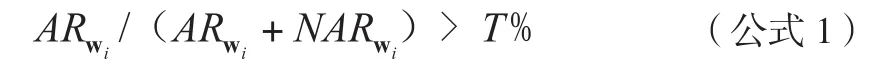
(2)使用上述特征候选词对邮件数据集中的所有邮件进行过滤,得到每条特征候选词规则在学术相关通知类邮件和非学术相关通知类邮件的触发情况,结构化触发情况数据,每封邮件的触发情况为一个n维的数组,n为特征候选词的个数,邮件中包含此特征候选词则数组对应位置值为1否则为0。
(3)将上述触发情况作为输入,使用包含一个转换函数和一个激活函数的单层感知机算法进行训练得到关键词规则的权值,转换函数形如公式2,随机设置初始权值,指该规则在指定邮件中的触发情况。

激活函数形如公式3。

感知器算法使用的误差函数为公式4。
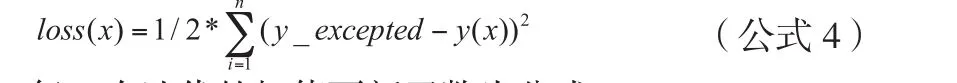
每一次迭代的权值更新函数为公式5。
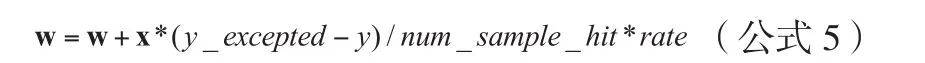
num_sample_hit 表示当前样本触发的规则数量,rate表示权值更新的学习率,通过实验确定表现较优的迭代次数和学习率,训练完成后保存关键词规则权值W,偏差b。
基于SVM的学术相关通知类邮件领域分类
学术相关通知类邮件的领域分类问题,等同于一个文本的多分类问题,在常见的文本分类方法中主要包括如何进行预处理,如何选择特征选择方法,如何选择文本表示方法,如何选择分类方法四个关键的待研究问题。
AREP使用的文本预处理流程包括分词,数据清洗,去停用词,词干提取。
AREP在文本表示方法上,参考唐明等提出的一种基于word2vec的文本表示方法[12],AREP使用结合TF-IDF及在大型语料库上进行预训练的词向量来进行文本表示,文档向量可表示为公式6。

公式6中Di表示第i篇文档,K(t,Di)表示词t在中的TF-IDF值, WVt表示词t的词向量。
在选取分类算法的时候,分类效果是最重要的一个衡量标准,另外还需要考虑系统的计算能力、存储空间限制、响应时延等,虽然基于深度神经网络的分类方法是近年的研究热点,但是考虑到深度神经网络高度的复杂性,不适用于实时性要求较高的邮件处理系统中,而SVM算法在一定程度上可以代表传统机器学习单分类器方法在文本分类上的发展水平,SVM方法的其中一个优点是它在处理高维数据时较为健壮,学习过程几乎独立于特征空间的维度[13],文本数据具有高维稀疏分布和特征不相关的特性,因此本文系统选用SVM作为分类方法。
实验评估
基于关键词规则的筛选效果评估
关键词规则生成所使用的训练数据集为个人真实邮件,经人工筛选标记为学术相关通知类邮件及普通邮件,出于隐私保护,邮件文本内容仅选取邮件体正文部分,不考虑邮件头内容,此邮件数据集共包含学术相关通知类邮件1709封,普通邮件1500封。
文本预处理的过程执行数据清洗:去除标点符号,数字,中文,大小写转换;分词;去停用词:使用nltk语料库的英文停用词表;词干提取。
特征候选词选取过程中相关的设置如下:统计学术相关通知类邮件中总词频最高的500个词,筛选符合的词作为关键词候选词,共获取有效候选词436个,部分候选词如表1所示:
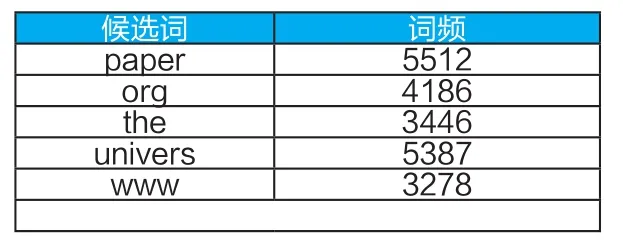
表1 部分关键词候选词展示
关键词候选词权值生成过程中相关设置如 下:(1) 为 了 降 低普通邮件的误过滤率,首先对邮件数据集中的普通邮件进行冗余复制,设置每封普通邮件复制的数量为:num_sample_hit/2+1,num_sample_hit 表示当前样本触发的规则数量,由邮件数据集中的1500封普通邮件生成7576封普通邮件(2)神经网络权值更新过程中的学习率可以控制权值更新速度,学习速率过高会造成训练过程不稳定,一般学习率的设置为[0,1],本次实验设置学习率rate=0.05,将训练结果以每5次迭代为单位记录下来,如图2所示:观察得到算法在迭代次数250次时基本收敛,因此设置迭代次数为300次。
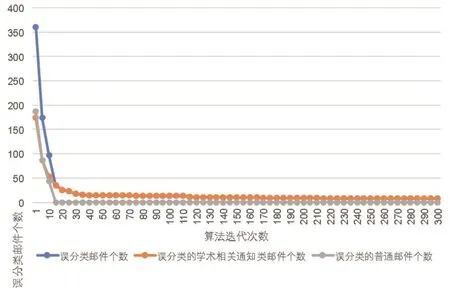
图2
将邮件数据集分成70%训练集和30%的测试集,训练过程中,每5次迭代,使用测试集对得到的关键词候选词规则进行评估,评估标准包括:
(1)accuracy=correct_classified_mail/num_of_mail *100%即正确分类的邮件占总邮件的比例。
(2)arm%=mis_classified_ar/num_of_ar_mail *100%即被误分类的学术相关通知类邮件占所有学术相关通知类邮件的比例。
(3)narm%=mis_classified_nar/num_of_nar_mail *100%即 被 误分类的普通邮件占所有普通邮件的比例。
评估标准中使用的变量定义为:correct_ classified _mail 表示被正确分类的邮件数量,num _ of_mail 表示所有邮件数量,mis_ classified _ar 表示被误分类为普通邮件的学术相关通知类邮件数量,mis_ classified _nar 表示被误分类为学术相关通知类邮件的普通邮件数量,num _ of_ ar_mail 表示学术相关通知类邮件的数量,num _ of _ nar_mail 表示普通邮件的数量。
算法迭代300次后,最终评估结果如表2所示:

表2 关键词规则最终评估结果
根据实验得到的评估效果,基于关键词规则实现学术相关通知类邮件筛选的精确度达到99.75%,并且非学术相关通知类邮件的误分类率为0,证明了学术相关通知类邮件具有区别度很高的关键词特征,因此在AREP中使用基于关键词规则的方法实现筛选功能是可行的。
学术相关通知类邮件领域分类性能评估
训练学术相关通知类邮件领域分类器所用的数据集来自网站world conference calendar[14]公开的会议举办信息,共收集该网站上10个类别38361个会议通知,采集会议通知正文部分的文本内容,详细的领域类别信息如表3所示:
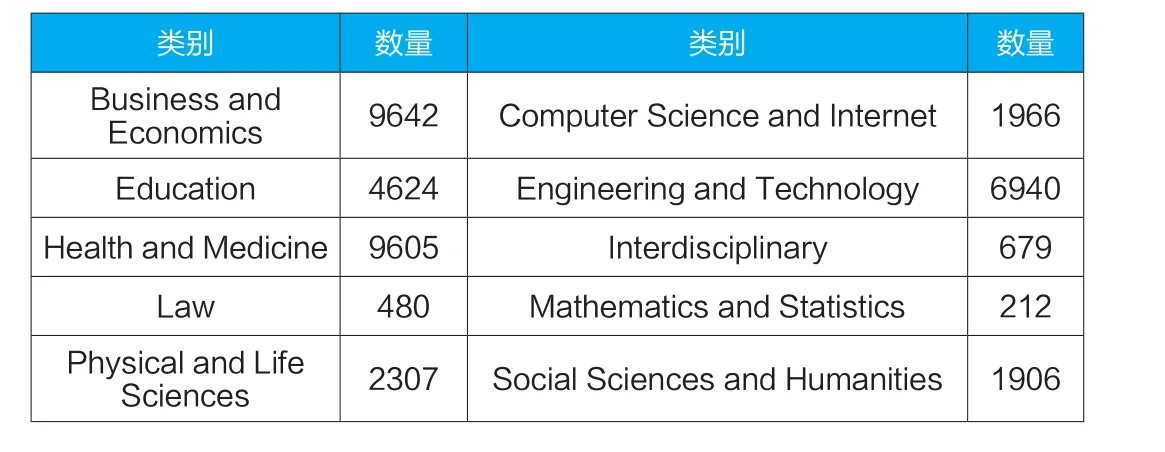
表3 会议通知数据集组成情况详细信息

表4 基于SVM的学术相关通知类邮件领域分类器性能评估结果
本文系统使用的文本表示方法为结合TF-IDF及预训练词向量的方法,文本表示过程中的相关设置如下:(1)计算词的TF-IDF值,经过预处理后的文档构建的词典共包含110543个词,共有38361个文档,统计每个文档中每个词的TF-IDF值,需要生成一个38361*110543大小的数组来存放,超出了一般计算机的内存限制,考虑到词的TF-IDF值是作为领域分类的特征,因此TF-IDF值的统计基于类别文档,将某一类的文档聚合为一个文档(2) 使用的预训练的词向量来自Stanford 公开的在一些大型公开语料库上通过GloVe方法训练得到的词向量集,本文实验选用在Wikipedia 2014 + Gigaword 5语料库训练得到的词向量glove.6B,共有50d, 100d, 200d, 300d四种维度[15]。
使用one-against-one的方法实现SVM的多分类,使用交叉验证的评估方法,以精确度为评估标准,最终得到的评估结果如表4所示,根据表4的评估结果,可以看出选用词向量维度为50时,模型训练与模型预测的耗时最短,分类表现也最优。词向量维度的选择主要受数据集规模影响,高维的词向量虽然能够保留更多信息,但是在规模较小的数据集上容易存在过拟合现象,根据实验结果本文系统使用的词向量为50维。
系统使用情况评估
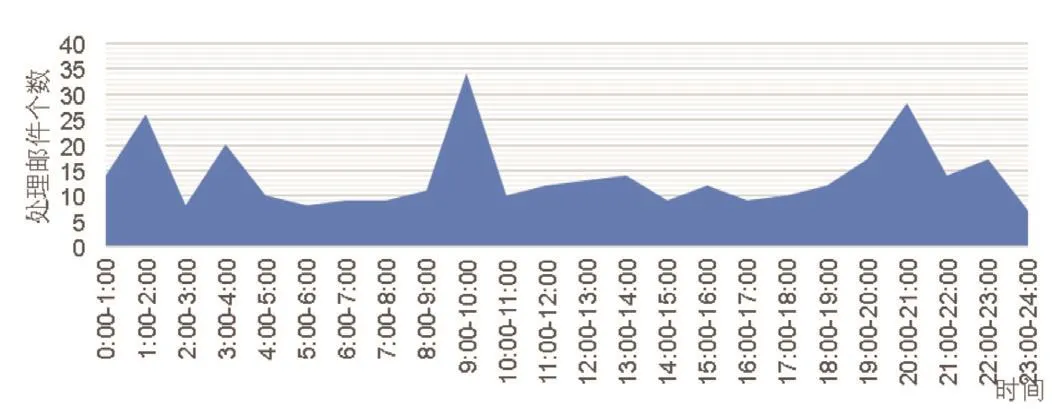
图3 系统记录的2018年07年01日的处理情况

图4 系统运行3个月以来月统计记录
本文设计实现的系统已投入实际使用,并且稳定运行3个月,本节主要介绍系统运行情况,通过将邮件记录可视化管理,可以掌握系统运行的情况,图3为系统记录的2018年07年01日的处理情况,图4为系统运行3个月以来月统计记录,根据处理记录能够证明系统能够较稳定的运行。
考虑到邮件在科研环境的广泛应用,面向科研人员的邮件处理需求,本文提出了一个针对学术相关通知类邮件的处理系统AREP(Academic Related Email Processor),AREP在保证邮件传输要求的基础上,实现了学术相关通知类邮件的核心处理组件:首先通过基于关键词规则的方法筛选出学术相关通知类邮件,其中关键词规则的生成方案包括基于词频、文档频率的特征词选取方法和基于感知器算法的权值计算方法;对于筛选结果为学术相关通知类的邮件应用基于SVM的分类方法进行领域分类,其中文档的表示方法结合TF-IDF和词向量;通过实验证明了邮件筛选方法和领域分类方法具有良好表现,足够应对现实环境的学术相关通知类邮件处理。另外设计了根据处理组件处理的结果进行个性化的后处理的分发组件,提供给用户设置邮件后处理规则的服务,协助用户进行邮件资源的管理,真正减轻人为处理的负担。本文提出的系统已投入实际应用环境,稳定运行3个月以上,具实用意义。
