一种机器学习方法在湖北定时气温预报中的应用试验
2018-11-06谭江红陈伟亮王珊珊
谭江红 陈伟亮 王珊珊
(1 荆州市气象局,荆州 434020;2 江汉平原生态气象遥感监测技术协同创新中心,荆州 434025;3 武汉中心气象台,武汉 430074)
0 引言
机器学习是人工智能的重要解决方案,包括监督学习和非监督学习[1]。天气预报中的很多问题都可以转化为标签已知的监督学习问题:标签即待预报量,机器学习中的特征即预报因子。机器学习模型具有一定黑盒性,但其使用效果经常出乎意料。
经验表明,代表全球数值模式最高水平的欧洲中期天气预报中心(以下简称“欧洲中心”)在形势预报方面日益进步,达到了非常高的可用水平,预报员在订正形势预报方面操作空间很小,但数值预报的要素误差仍有较大订正空间。随着人工智能浪潮的来临,客观化智能化预报是未来天气预报的发展方向。2017年湖北省气象局开始开展智能网格预报业务。在湖北地区,黄治勇等[2]使用了带海拔高度的距离权重温度插值方法和灰色预测模型来预报湖北温度。另外一些见诸文献的方法还包括卡尔曼滤波订正模式温度预报[3]、神经网络方法中的BP网络[4]、Barnes插值[5]、时效偏差消除[6]、统计降尺度[7]等。
在温度预报中使用的线性方法主要包括多元线性回归、逐步线性回归、最优子集回归,但由于天气演变的非线性特征、预报量与预报因子关系的非线性特征,线性方法的局限性较大。除了神经网络外,非线性方法还包括支持向量机、相似预报理论等[8]。预报员的思维一般是基于历史经验,本质上也是一种相似预报的主观方法,只不过是基于抽象经验,难以通过生物神经系统准确记住海量历史个例,故难以客观量化,而通过机器学习方法进行数据挖掘正是从历史数据中挖掘规律,本质是一种基于历史相似样本的客观定量方法。数据挖掘技术也早已在精细化温度预报中的得到探索[9],前人研究多为BP神经网络、时间序列数据挖掘方法,近年来改进并兴起的树类机器学习方法暂未得到广泛使用。本文探索和引入了数据挖掘中比较年轻的树类集成数据挖掘方法在历史数据集上进行预报应用,并在预报实践中检验其效果。
1 资料与方法
本文使用的资料为2015—2017年湖北89个气象站地面观测温度,时间为每天逐3 h正点观测时间(北京时间20,23,02,05,08,11,14,17,20时),数据来源为自动站数据库,欧洲中心(EC)再分析资料、0~12 h预报场(每天08、20时2次)。最优训练期方案[10-11]证明,样本时间尺度的选择对于温度预报的影响较大。选取的时间尺度足够长,才能优于传统的季节固定期分类,才能更好地衡量不同天气条件下的各类不同情形。通俗地说,机器学习需要“大数据”支持,足够多的样本才能使模型“见多识广”,例如,建模数据不包括台风过程,在预报时段出现台风,模型很可能无法识别罕见低气压的意义,无从知道台风低压会造成何种结果。
LightGBM是微软于2016年开源的一种以决策树作为基学习器的的梯度提升(boosting)机器学习框架,较以往的树类集成学习方法(如随机森林、XGBoost[12])有明显优势,LightGBM算法相关文献[13]有详细介绍。与之前的梯度提升类决策树相比,LightGBM具有更快的训练效率、低内存使用、更高的准确率、支持并行化学习等很多优点,其基学习器决策树[14]的思想本质是一系列if-then条件判断的嵌套集合,与预报员的思路不谋而合:预报员正是基于各种因子(比如灾害性天气的形成的水汽、动力、热力条件)对结果进行分析,从而判断各条件的组合是否会产生特定的天气现象。
由于决策树具有高度非线性的特点,所以可以解决非线性很强的天气预报问题。单一的决策树往往效果一般,但包括随机森林、XGBoost在内的树类集成机器学习方法在结构化数据挖掘方面有非常广泛的应用,特别是近年来,XGBoost、LightGBM在数据挖掘竞赛中应用非常广泛,被誉为冠军选手的“杀器”,同时这些方法在工业预测领域也有了大量相关应用[15-25],应该借鉴到气象预报中。而在预报领域,集合预报与集成预报的思路同样广为应用,已经有大量温度预报客观方法采用了集成MOS方法[3,26-28],随机森林、XGBoost、LightGBM等集成方法正是构建“多棵树”作为基预测器实现集成效果,相当于拥有多个预报成员。
大多数机器学习工具都无法直接支持类别特征作为输入,一般需要进行one-hot码,转换成多维特征。LightGBM增加的针对类别特征的决策规则在处理温度预报时很有用,因为预报实践证明地形气候、观测环境在气象要素预报中是不可忽略的,正是地形因素使模式温度预报在山区经常与站点观测存在较大差异(模式很好地处理了物理过程,而对地形的处理仍有缺陷),因而需要分站点建模以区分局地因子的差异,这里以站号来区分不同站点,作为预报因子输入,使模型自动学习不同站点,相当于考虑了不同站点的预报要素与因子之间的统计关系差异。由于该方法是最新开源的树类机器学习框架,暂未见集成决策树类相关模型在温度预报中应用的中文文献(黎光智[29]在“透过网页内容预测新闻热门程度”研究中使用了LightGBM方法),因此在天气预报领域的应用具有一定示范性。
之所以选取模式0~12 h预报进行建模是由于以下两个原因:1)模式时效越近,模式的预报效果越好,更容易反映大气的真实情况。这本质上是一种更接近PP法的MOS预报方法,回归出的预报关系比较可靠,这样可以尽量避免模式重大的性能调整带来的回归关系误差。2)使用模式要素进行MOS建模,相比PP法,其预报因子更加丰富:模式同化了包括卫星资料在内的大量气象观测资料,弥补了建模的时空分辨率,也有大量二次计算加工的物理量,同时可以更方便地直接利用模式输出资料进行任意时效的预报应用,由于相同的数据格式,无需额外的数据处理,对于一线业务预报非常实用。
2 特征工程
特征工程相当于描述了机器学习模型的内在构成因子,所以特征工程与数据质量决定了机器学习模型效果的上限,此步骤尤为重要,需要确保不丢失重要特征的基础上避免冗余特征、无关特征和维数灾害[1],即选取与待预测量相关性最强的影响因子是必要的,否则无法学习到数据之间的内在客观规律,而选取的因子过多也可能会引起机器的无效学习或陷入过拟合,增加计算开销和学习难度,需要一定理论知识和业务经验。根据天气学原理[30],局地温度的变化主要取决于温度平流(大气内部的热量交换)和非绝热因子(大气与外部的热量交换)。本项目选取的特征如下:风场包括10 m、925 hPa、850 hPa、700 hPa,一定程度上体现了影响某地的天气系统和冷暖空气活动状态(例如吹南风和吹北风的热力性质是不一样的)。实践经验表明,相对湿度越大,水汽凝结倾向越高,相对湿度是否超过80%与该层的云量状况直接相关,例如工作经验表明,模式预报地面相对湿度超过95%时,大概率有雾出现,故选取1000~100hPa(1000,925,850,700,600,500,400,300,200,100 hPa)各层相对湿度,用于体现当地上空的天空状况以衡量辐射因子。温度方面,选取了1000~850 hPa温度,以体现大气的基本冷暖状态,不仅考虑了天气尺度的时空差异,也相当于考虑了季节因素,而已经有研究表明,聚类分析方法进行季节划分可改善极端温度预报效果[11]。这些层次接近地面,与地面温度相关性高。此外还选取了海平面气压以及变压,用于衡量冷空气的强度及其活动。选取模式本身输出的2 m温度作为基准量,选取站号和时间作为分类变量。矢量场分解为u,v分量,共计26个因子。数值预报格点的经纬距分辨率为0.125°~0.25°,取值方式采用站点最邻近格点方式。
该特征工程选取温、压、湿、风等基本气象要素来衡量大气的基本状态(其他派生量实际上也均可通过基本量计算得到),从物理上体现出了影响温度的主要因子,其基本思想是,建立统计机器学习回归模型,用于学习大气不同状态下模式本身的2 m温度预报误差,其本质是基于历史相似数据分布或排列组合进行相似订正从而做出最终预报。通过数据处理,形成了预报因子和实况数据对应的建模样本矩阵数据库。
3 模型建立与评估
本文利用Python进行机器学习建模,为避免过拟合采用5折CV交叉验证,给定参数列表字典通过遗传进化算法进行参数搜索完成机器学习超参数寻优,最终形成了LightGBMRgressor模型,并保存模型用于预测。相关使用方法和原理可参考LightGBM[12]、scikitlearn[31]、tpot[32]等项目文档,最终使用的模型参数见表1。使用scikit-learn随机选取模型1%的样本数进行拟合效果评估,模型的误差见表2,可以看出模式的均方根误差RMSE和平均绝对误差MAE较小,而衡量回归效果的决定系数很高,正负误差样本数基本相同,表明了模型预报能力的平衡性。

表1 模型主要参数Table 1 Main parameters of LightGBM

表2 模型拟合效果评价Table 2 Goodness of fitting using regression
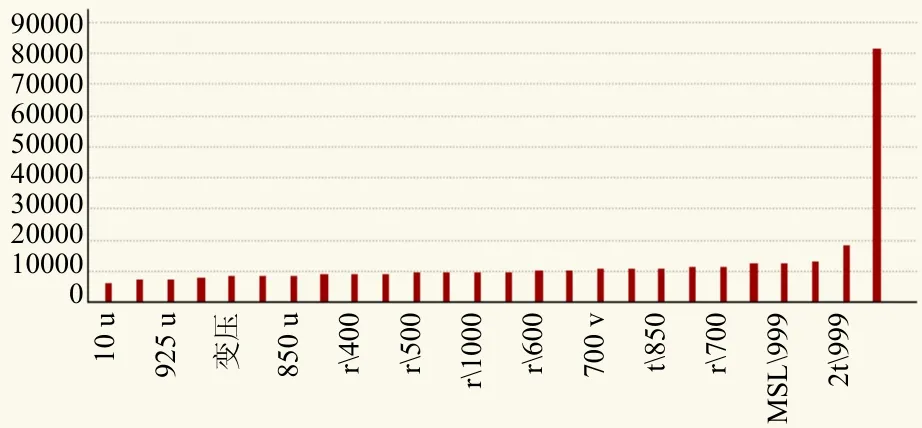
图1 特征重要性排名Fig. 1 The feature importances
图1是模型给出的特征重要性排名,从大到小(图1从右至左)依次为:站点、模式2 m温度、100hPa相对湿度、海平面气压、925 hPa温度、700hPa相对湿度、200 hPa相对湿度、850 hPa温度、时间、700 hPa经向风速v、700 hPa纬向风速u、600hPa相对湿度、850 hPa相对湿度、1000 hPa相对湿度、300 hPa相对湿度、500 hPa相对湿度、1000 hPa温度、400 hPa相对湿度、850 hPav风速、850 hPau风速、925 hPa相对湿度、3 h变压、925 hPav风速、925hPau风速、10 mv风速、10 mu风速。
可见在温度预报方面,站点的因素排位第一,即需首要考虑观测环境不同导致的模式预报误差的不同,充分证明了特征工程设计的合理性。模式2 m温度排名第二,意味着温度预报最重要的参考资料仍然是模式输出的2 m温度,排名第三位的是100 hPa相对湿度,当100 hPa湿度较大的时候,往往意味着云层的伸展高度较高(较厚),这是影响温度的辐射因子的重要体现。排名第四位的是海平面气压,与冷空气的活动相关性很大。可以看出,机器学习的结果与天气学原理和实际预报经验是一致的。排名三位以下的因子的特征重要性在数量级上相差不大,但并不一定意味着这些特征并不重要,因为这是以单一因子进行度量,而实际情况是这些因子排列组合起来的结果,如上所述,各层相对湿度就与云高云厚有对应关系,进而影响光照或长波辐射。
4 预报检验与预报实例
利用2018年独立样本进行预报检验,并与现行智能网格预报结果进行对比,其检验效果如图2。可以看出模型的预报和实况变化趋势一致,经计算其决定系数高达0.97。平均绝对误差1.1 ℃,而相同样本欧洲模式2 m温度预报误差为1.8 ℃。2 ℃以内的预报准确率由欧洲数值预报本身的65.9%提高到86.6%,而同期省台智能网格客观产品12 h以内的定时气温预报准确率约为70.1%。例如,对57453站2018年1月9日08时的预报,欧洲中心数值预报为-12.3 ℃,而模型预报为1.6℃,实况为0.4 ℃,预报绝对误差由欧洲中心的12.7 ℃下降到模型的1.2 ℃。又如表3,相比欧洲中心模式,2018年3月10日05时,LightGBM模型大部分站点预报误差都在2 ℃以内(现行业务准确率评价标准),相比数值预报本身模型降低预报误差的趋势明显,仅仅57256站出现了预报错误。

图2 预报与实况对比检验(a:误差频数分布直方图;b:散点及其密度和趋势图)Fig. 2 Inspection of forecast in contrast to the observed data(a: frequency distribution; b: scatterplot and its density and tend line)

表3 2018年3月10日05时模型预报示例(单位:℃)Table 3 Examples of model forecast at 5:00AM on March 10, 2018 (℃)
本模型现已接入了武汉中心气象台智能网格预报平台进行业务化应用,日常业务一般检验的是最高、最低气温,由于本模型预报的是定时气温,所以初步产品只是简单地从24 h内8个定时气温中挑选出最高、最低温度作为高、低温预报。对2018年2—6月预报产品进行评分(表4),该模型的高、低温预报位居所有客观预报产品前列(其中省台产品是预报员最后主观订正后的产品),特别是24 h低温预报准确率高达91.4%,位居所有预报产品第一位,但分析其平均误差,发现高温预报有系统性偏低,低温预报有系统性偏高,这是不难理解的:由于建模和预报使用的是定时气温,从定时气温中挑选出的最大、最小值实际上仍不能完全代表日极端值,例如,在晴朗天气下,高温常常比14时气温要高,经常出现在15时左右,可以推测,针对日最高、最低气温直接建模应该可以获得更大提升空间,后期可以继续探索,优化模型。
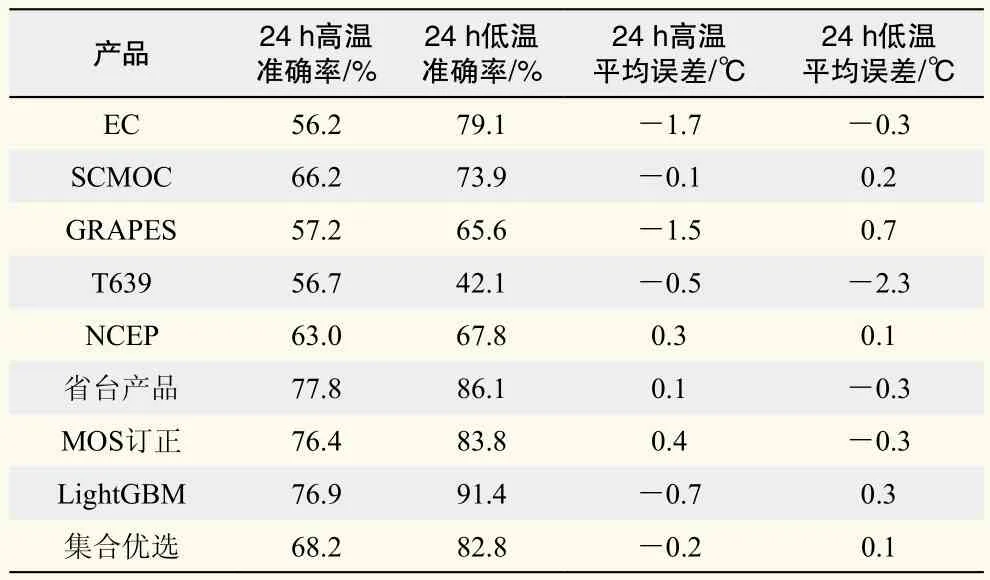
表4 2018年2—6月高、低温预报评分Table 4 Maximum and minimum temperature forecast score from February to June, 2018
5 结论与讨论
1)机器学习模型的决策过程有一定的黑盒性,但使用效果好(0~24 h气温预报模型相比数值模式准确率可提高10%以上),可以将预报员的主观预报经验进行高效地客观定量化,具备广阔的应用前景。
2)由于不同时间辐射状况不同,模式误差不同;不同站点小气候特点(例如海拔)不同,模式误差也不同,需要将相对标准化的模式输出进行系统订正,而LightGBM可以直接处理数值本身没有意义的分类变量,无需离散编码,从而相当于针对不同时次和站点进行建模,效率有很大的进步。
3)由于LightGBMRgressor叶子数、学习率等超参数寻优需要一定的经验,更好的模型效果需要更多的试验,由于超参数寻优的专业性和计算密集型,具备一定的硬软件要求和难度,需要进一步探索和专业硬软件支持。
4)由于不同时效的数据格式相同,业务化简便易行,在模式分析场质量不剧烈变化、模式性能、模式不同时效基本形势的预报没有明显改变,即预报稳定时,该模型不同时效的温度预报能力是相同的。
